Der Smarthome-Standard Matter ist gekommen, um den Markt aufzurollen. Doch wie sieht es mit der Umsetzung aus und kann der Standard seinem Versprechen gerecht werden?
Nachdem der Standard, knapp drei Jahre in der Entwicklung war, wurde er schlussendlich im November 2022 offiziell auf einem Launch-Event in Amsterdam vorgestellt.
Bereits damals kündigten viele Hersteller ihre Unterstützung an. In der sich für den Matter-Standard zuständig zeichnenden Connectivity Standards Alliance (CSA), finden sich über 500 Firmen, die unter dem Dach der Organisation vereint sind.
Darunter sind klingende Namen, wie Amazon, Apple, Google, Nordic Semiconductor, NXP Semiconductors, Samsung, Silicon Labs und viele mehr. Doch wie sieht es aus mit der Unterstützung des Standards?
Android und iOS
Matter unterstützt sogenannte Multi-Admin-Funktionalität. Dies bedeutet, dass eine Matter-Installation von unterschiedlichsten Geräten gesteuert werden kann. Für diese Steuerung wurde in unterschiedlichste Betriebssysteme mittlerweile entsprechende Unterstützung eingebaut. Diese wird meist im Rahmen der jeweiligen Smarthome-Strategie der Hersteller ausgestaltet.
So ist die Matter-Unterstützung unter iOS in die Home-App integriert. Eingeführt wurde diese Unterstützung mit der Version 16.1 von iOS. Mit diesen Updates im Oktober 2022, wurden auch andere Systeme wie watchOS mit einer Matter-Unterstützung versehen.
Unter Android wurde die Unterstützung für Matter ab Version 8.1 eingeführt, sofern die Play-Dienste ab Version 22.48.14 installiert sind. Auch hier kann das Smarthome unter Nutzung des Matter-Standards über die Home-App genutzt werden.
Smarthome-Ökosysteme
Interessant ist auch die Unterstützung der jeweiligen Home-App von Google und Apple auf dem Konkurrenzsystem. So sind die Home-Apps von Apple und Google auch auf Android respektive iOS verfügbar und unterstützen dort ebenfalls den Matter-Standard.
Andere Ökosysteme für Smarthomes sind mittlerweile ebenfalls auf den Matter-Standard angepasst. So unterstützt SmartThings von Samsung seit einiger Zeit Matter unter iOS und Android. Allerdings ist diese Unterstützung nicht komplett. So werden unter anderem Bridges, welche im Matter-Standard vorgesehen sind, durch die App noch nicht unterstützt.
Bridges dienen zur Anbindung von nicht direkt kompatiblen Systemen, an ein Matter kompatibles System. Ein solche definiert sich im Standard dadurch, dass sie ein Matter-Knoten darstellt, welcher ein oder mehrere Nicht-Matter-Geräte darstellt.
Die Alexa-App unterstützt, analog zu den anderen Systemen, seit einiger Zeit den Matter-Standard. Dies ging einher mit der Aktualisierung vieler Alexa-Echo-Geräte, insbesondere in den neuen Generationen der Gerätereihe. Mit Home Assistant verfügen Open Source-Lösungen mittlerweile auch über Unterstützung für Matter.
Border-Router und Controller
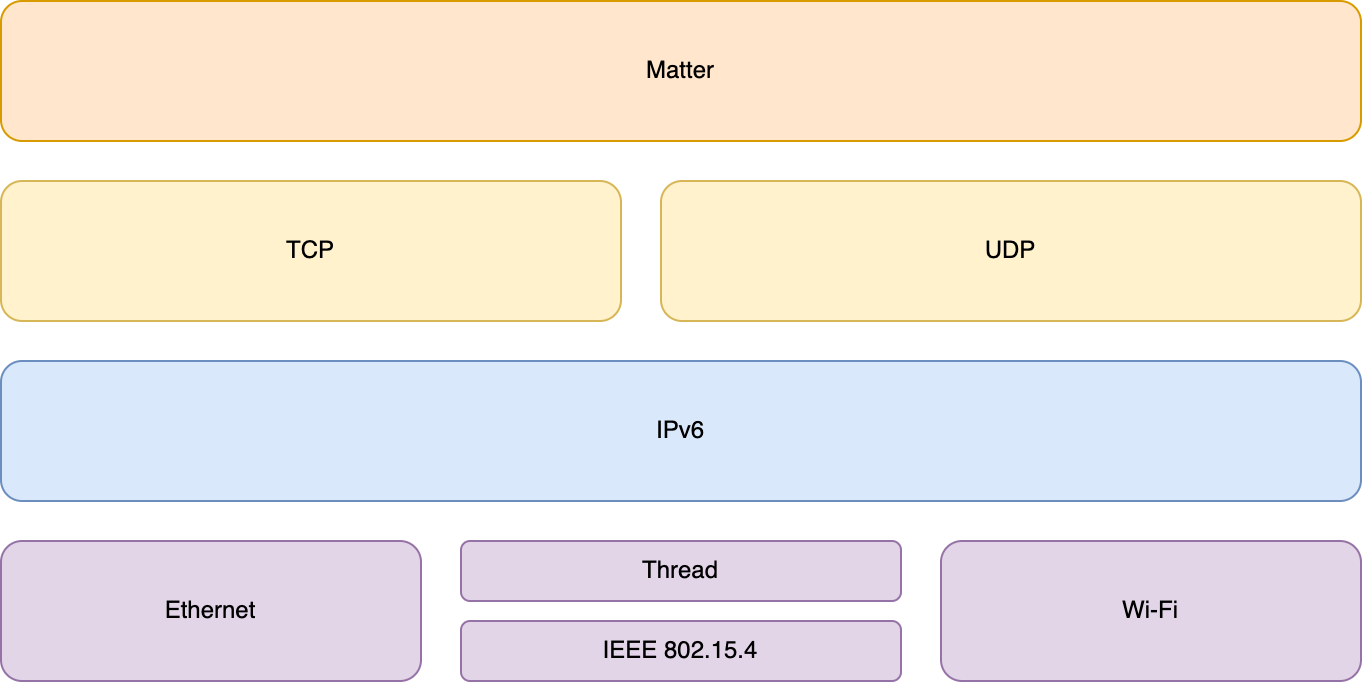
Bei Matter wird für die Kommunikation der Geräte untereinander Wi-Fi, Ethernet oder Thread benutzt; für die Kommissionierung Bluetooth LE. Näheres dazu findet sich im entsprechenden Hintergrundartikel.
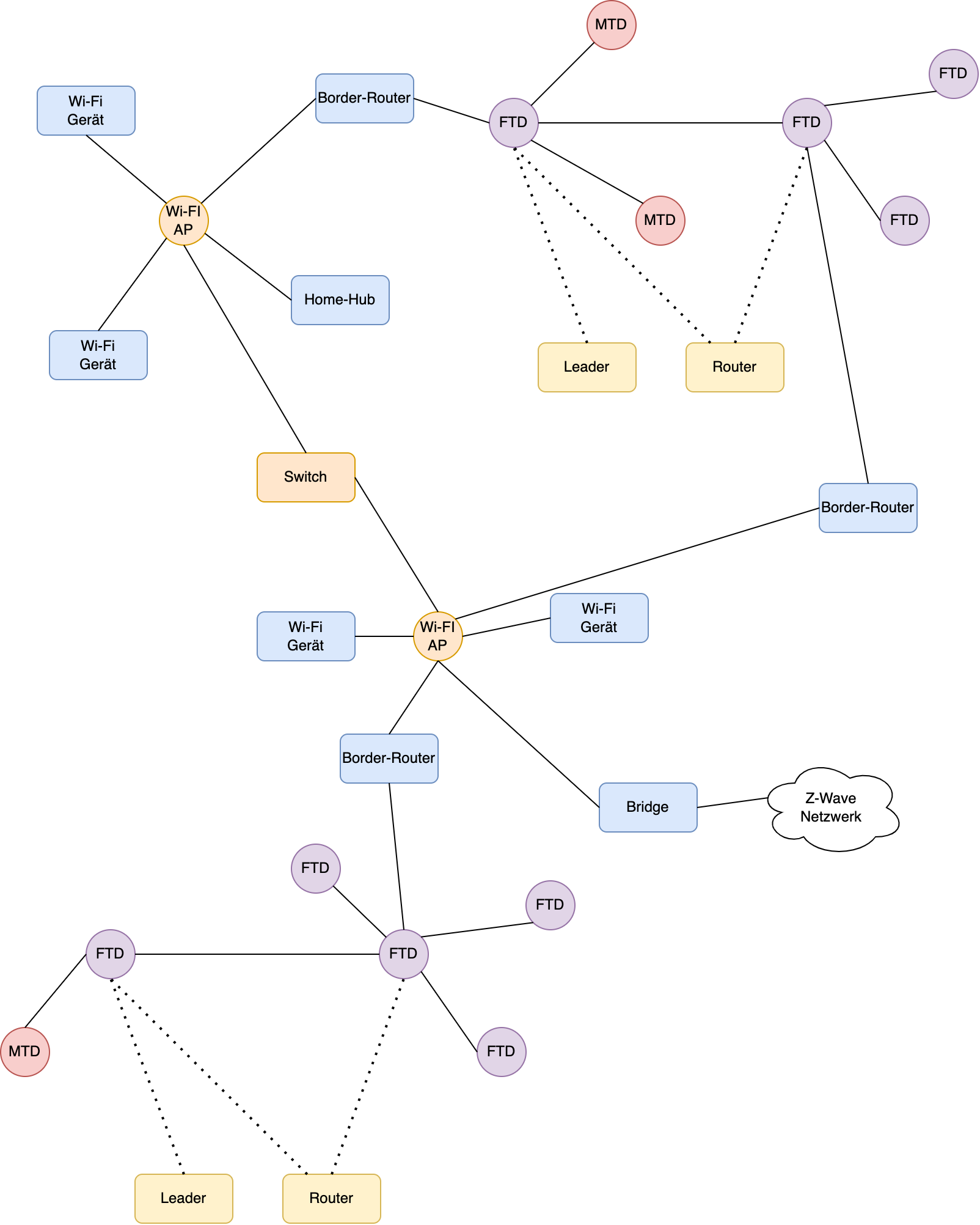
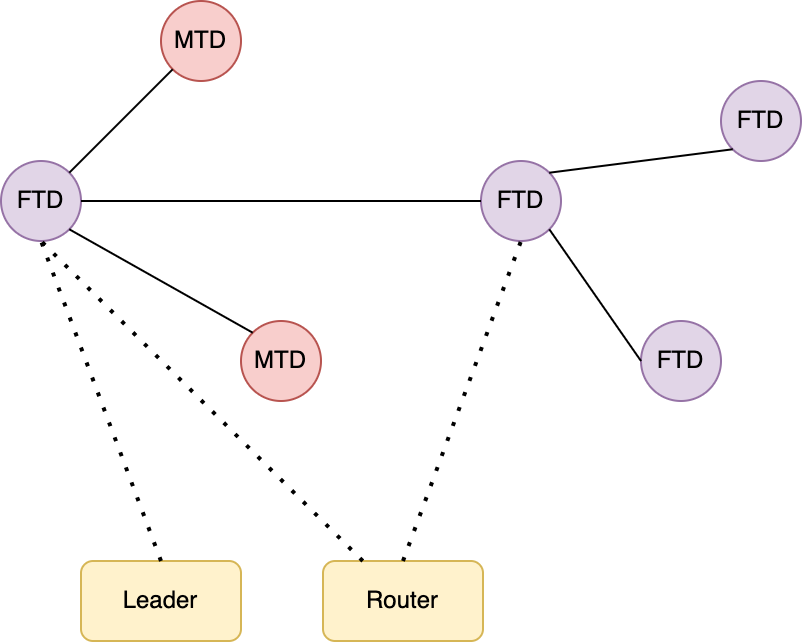
Ein komplexes Matter-Netzwerk
Thread versteht sich als selbstheilendes Mesh-Netzwerk. Es ist darauf ausgelegt, Geräte miteinander zu verbinden, welche eine geringe Datenrate benötigen und möglichst wenig Energie verbrauchen sollen. Das Protokoll besticht durch sein simples Design und ermöglicht niedrige Latenzen.
Basierend auf IPv6 wird somit bei Matter ein Netz gebildet, über welches die unterschiedlichen Geräte miteinander kommunizieren. Zur Anbindung eines Thread-Netzwerks an das Matter-Ökosystem werden Border-Router benötigt, welche die Verbindung zum hauseigenen LAN herstellt.
In vielen Haushalten müssen diese allerdings nicht extra angeschafft werden, da bestehende Geräte, wie einige Smart-Speaker von Amazon, per Update zu solchen Border-Routern aktualisiert werden konnten.
Hintergrund hierfür ist, dass Thread auf IEEE 802.15.4 aufsetzt, bei welchem es sich um einen Standard für kabellose Netzwerke mit geringen Datenraten handelt. In IEEE 802.15.4 ist die Bitübertragungsschicht (Physical Layer) und die Data-Link-Schicht definiert.
Neben Thread setzt unter anderem auch ZigBee, ebenfalls ein Mesh-Protokoll, auf IEEE 802.15.4 auf, was eine Aktualisierung solcher Geräte, hin zu Thread, perspektivisch möglich macht. Damit sind viele Funkchips welche ZigBee unterstützen in der Theorie für Thread geeignet.
Apple hat die Unterstützung für Matter mit der HomePod-Version 16.1 implementiert. Auch der Apple TV kann in bestimmten Generationen als Border-Router verwendet werden. Aktuell werden der Apple TV 4K in der zweiten und dritten Generation neben dem HomePod Mini und dem HomePod in der zweiten Generation unterstützt.
Bei Amazon wurde mittlerweile eine kleine Armada an Geräten mit einer Matter-Unterstützung ausgestattet. So unterstützt der Echo der vierten Generation die Thread-Funktechnik und kann als Border-Router verwendet werden. Daneben können die Geräte Echo, Echo Plus und die Echo Dot-Serie als Matter-Controller verwendet werden. Hier wird gewöhnlich ab der zweiten und dritten Generation der Geräte eine Unterstützung geliefert.
Die eero-Router, hergestellt von einer Tochterfirma von Amazon, können als Border-Router genutzt werden. Hier findet sich eine entsprechende Unterstützung in den Modellen eero 6, eero 6+, eero Pro, eero Pro 6E und eero Pro 6.
Google verfügt über eine Reihe von Geräten, welche mittlerweile Matter unterstützen und als Border-Router genutzt werden können. So werden die Smart-Speaker Google Home, Google Home Mini, Nest Mini, Nest Audio und die Displays Nest Hub (1. Generation), Nest Hub (2. Generation) und der Nest Hub Max unterstützt. Auch der Nest Wifi Pro (Wi-Fi 6E) Router verfügt über eine entsprechende Unterstützung.
Neben den Geräten von Big Tech, finden sich in vielen Haushalten, Router der Firma AVM, namentlich die FRITZ!Box. Die neuen Modelle 5690 XGS & 5690 Pro, welche noch in diesem Jahr erscheinen sollen, verfügen neben dem von AVM bevorzugten DECT ULE auch über Unterstützung für ZigBee. Basierend auf dieser Möglichkeit, soll eine spätere Matter-Unterstützung Einzug halten. Das FRITZ!Smart Gateway soll in Zukunft ebenfalls Unterstützung für Matter erhalten.
Daneben finden sich einige andere Hersteller, welche mittlerweile entsprechende Unterstützung bzw. Border-Router liefern, namentlich der Aeotec Smart Home Hub, einige Geräte der Nanoleaf-Produktpalette und der Samsung SmartThings Hub in Version 3.
Bei anderen Geräten, wie dem Dirigera-Hub von Ikea, fehlt eine angekündigte Unterstützung immer noch.
Hardware
Doch wie sieht es bei den Herstellern der eigentlichen Smarthome-Geräte aus? Erst durch sie wird das Smarthome steuer- und erfahrbar. Neben den Konzernen Apple, Amazon und Google, welche sich in vielen Fällen mit entsprechender Software-Unterstützung und dem Bau von Border-Routern und Controllern beschäftigen, existieren auch die Firmen, welche Sensoren und Aktoren liefern.
In diesem Feld sind unter anderem Aeotec, Eve Systems, Signify und einige andere Anbieter unterwegs. Dagegen haben Hersteller, wie Belkin, ihre Unterstützung für Matter mittlerweile zurückgezogen.

Ein Sensor von Fibaro
Firmen wie Fibaro, haben sich trotz einer großen Auswahl an Smarthome-Produkten bisher nicht zu Matter geäußert. Doch wie sieht es bei den Herstellern im Einzelnen aus?
Aeotec
Aeotec, hervorgegangen aus den Aeon Labs, ist mittlerweile eine Firma mit Hauptsitz in Hamburg. Bekannt geworden ist die Firma primär durch Smarthome-Geräte, welche den Z-Wave-Standard unterstützten.
Mit dem Aeotec Smart Home Hub liefert Aeotec einen zu Matter und dem Thread-Funkstandard kompatiblen Hub. Der ZigBee-Stick, mit dem Namen Zi-Stick, soll in Zukunft, per Update, auch das Thread-Protokoll unterstützen.
Ansonsten setzen die Aktoren und Sensoren von Aeotec nicht auf Matter, sondern auf das Z-Wave-Protokoll und die entsprechende Funktechnik auf.
Eltako
Im professionellen Bereich bietet die Firma Eltako mittlerweile Matter zertifizierte Geräte an. Hier handelt es sich unter anderem um Beschattungsaktoren, ein Stromstoß-Schaltrelais und Dimmaktoren.
Damit ist es möglich, bestehende Installationen über Matter einzubinden. Neben der Matter-Integration verfügen sie unter anderem über eine REST-API, sowie eine Apple Home-Integration.
Eve Systems
Eve Systems, früher als Elgato Systems bekannt, bietet Smarthome-Geräte für unterschiedlichste Bereiche an. Mittlerweile werden von der Firma auch erste Matter-Geräte angeboten.

Der Bewegungssensor Eve Motion
Darunter fallen die schaltbare Steckdose Eve Energy, die Kontaktsenoren Eve Door & Window und der Bewegungssensor Eve Motion. Teilweise agieren die Geräte als Matter-Controller sowie als Border-Router für das Thread-Protokoll.
Die Produkte Eve Shutter Switch und Eve Flare unterstützen bereits das Thread-Protokoll und sollen mit einem späteren Update, entsprechende Matter-Unterstützung erhalten. Das Gleiche soll auch für die Produkte Eve MotionBlinds, Eve Thermo, Eve Light Switch, Eve Weather und Eve Room gelten. Für diese Geräte war eine entsprechende Unterstützung bis Ende 2022 angekündigt, wurde allerdings bisher noch nicht ausgeliefert.
Govee
Govee ist seit 2017 im Smarthome-Bereich tätig und hat unterschiedlichste Produkte wie LED-Streifen und Sensoren im Angebot. Bekannt geworden sind sie auch durch eine kurzzeitige Auslistung bei Amazon, was wohl auf das Verpackungsdesign einiger Produkte zurückzuführen war. Diese besaßen eine auffällige Ähnlichkeit mit den Philips Hue-Produkten von Signify.
Mit dem Govee RGBIC LED Strip M1 hat Govee mittlerweile sein erstes Matter fähiges Produkt auf den Markt gebracht.
Leviton
Der nordamerikanische Hersteller Leviton, ist in Europa, aufgrund seines Zuschnitts auf den amerikanischen Markt, eher weniger bekannt. Dafür liefert er in seiner Heimat entsprechende Hardware mit Matter-Unterstützung.
Zu dieser gehört ein Smart Switch, eine schaltbare Steckdose und einige Dimmer. Konkret sind dies die Geräte Smart Wi-Fi 2nd Gen D26HD Dimmer, D215S Switch, D215P Mini Plug-In Switch und der D23LP Mini Plug-In Dimmer, welche über ein entsprechendes Firmware-Update aktualisiert werden können.
Andere Geräte von Leviton, sollen in Zukunft per Update in den Genuss einer Matter-Unterstützung kommen.
Nanoleaf
Nanoleaf wurde 2012 gegründet und finanzierte erste Produkte über Kickstarter. Mittlerweile liefern sie eine Reihe von ausgefallenen Beleuchtungslösungen.

Nanoleaf stellt ungewöhnliche Beleuchtungslösungen her
Neue Produkte, wie der Essentials Matter Lightstrip und die Essentials Matter Smart Bulb, sind von Werk aus mit einer Matter-Unterstützung versehen und können in entsprechende Ökosysteme eingebunden werden.
Bestehende Produkte der Essentials-Reihe können nicht per Update auf den Matter-Standard gehoben werden, da dies seitens der Hardware nicht unterstützt wird. Ob die Produktreihen Elements, Lines und Shapes eine entsprechende Aktualisierung auf Matter erhalten ist zurzeit noch unklar. Angebunden werden diese Systeme per WLAN. Daneben arbeiten diese Geräte bereits heute als Thread-Border-Router.
Signify
Das unter der Marke Philips vertriebene Lichtsystem Hue, ist bereits seit 2012 auf dem Markt. Entwickelt und vertrieben wird es von dem mittlerweile unabhängigen Unternehmen Signify, welches früher unter dem Namen Philips Lighting firmierte.
Das System, welches auf ZigBee basiert, ist so zumindest funktechnisch unter Umständen auf Thread aktualisierbar. Die Leuchtmittel sollen allerdings nach Aussage von George Yianni, seines Zeichens Head of Technology Philips Hue bei Signify nicht auf Thread aktualisiert werden.
Hier wird seitens Signify die Strategie gefahren, nur den Hue Hub mit einer Matter-Unterstützung zu versehen. In der FAQ wird dies wie folgt beschrieben:
Alle Philips Hue Lampen und intelligentes Zubehör wie der Hue Dimmschalter und Hue Smart Button funktionieren mit Matter, wenn sie über die Philips Hue Bridge verbunden sind. Die einzigen Ausnahmen sind die Philips Hue Play HDMI-Sync Box und der Tap Dial Switch.
Auch dieses Update lässt allerdings noch auf sich warten, bzw. findet sich in einer Beta-Version, welche für Entwickler freigegeben wurde.
Der Hintergrund für diese Herangehensweise ist, dass die Hue-Bridge nicht nur als einfache Verbindung zwischen dem WLAN und den angeschlossenen ZigBee-Geräten gesehen wird, sondern als Zentrale für Abläufe und Automatisierungen.
Solche Funktionalitäten sollen nicht direkt in die Leuchtmittel eingebaut werden. Es wird befürchtet, damit die Komplexität des Systems zu erhöhen. Auch die Entscheidung, die Geräte mittelfristig nicht auf Thread umzurüsten, wird entsprechend begründet. Hier wird argumentiert, dass das entsprechende Mesh-Netzwerk über ZigBee im Laufe der Jahre produktionsreif gemacht wurde. Bei Thread steht die Befürchtung im Raum, dass hier noch viele Kinderkrankheiten und Inkompatibilitäten zu beheben sind, bis ein vergleichbarer Stand, wie mit der aktuellen Implementierung erreicht werden kann.
Mittlerweile ebenfalls zu Signify gehörend ist das ehemalige Start-up Wiz, welches auch Beleuchtungslösungen anbietet. Diese werden per WLAN angebunden und arbeiten ohne Bridge.
Bei Wiz wird Matter bei Leuchtmitteln und Smart Plugs, welche ab dem zweiten Quartal 2021 produziert worden sind, unterstützt. Die entsprechenden Updates für die meisten Bestandsgeräte sind hierbei mittlerweile erschienen.
SwitchBot
Die 2016 gegründete Firma befasst sich mit der Entwicklung von Smarthome-Geräten, wie Schlössern, Kameras und Schaltern.
Mit dem SwitchBot Hub 2 brachte sie ihr erstes Matter fähiges Produkt auf den Markt. Über diesen können andere Geräte wie SwitchBot Curtain ebenfalls per Matter angebunden werden.
Weitere Produkte sollen folgen, sind aber im Moment noch in Entwicklung. Hier sind Erscheinungstermine für das dritte und vierte Quartal 2023 anvisiert.
TP-Link
Neben Netzwerkprodukten bietet der chinesische Hersteller TP-Link mittlerweile auch eine Palette von Smarthome-Produkten an. Diese firmieren unter den Marken bzw. Unternehmen Tapo und Kasa.
Anfang des Jahres wurde mit dem Tapo P125M, einer schaltbaren Steckdose, ein Matter fähiges Produkt aus dieser Produktreihe vorgestellt.
In Zukunft sollen Matter-Updates für weitere Steckdosen, Schalter, Leuchtmittel und Thermostate erscheinen.
Tridonic
Tridonic, eine zur Zumtobel Group gehörende Firma, ist vorwiegend im professionellen Bereich bekannt. Auch hier wird an Matter-Lösungen gearbeitet, bzw. solche werden angeboten.

Die Matter-Produkte von Tridonic
Hierbei werden ein Wireless Matter Treiber, mit 24 V Konstantspannung, erhältlich in 35 W, 60 W, 100 W, 150 W, sowie ein Wireless Matter to DALI Passivmodul und ein Wireless Matter to DALI SR Modul angeboten. Über die Wireless-Module können bestehende Systeme nachgerüstet und somit Beleuchtungen Matter fähig gemacht werden.
Angebunden sind die Module per Thread. Für diese Module wurden Updates angekündigt, welche unter anderem die Änderung der Farbtemperatur möglich machen sollen, sobald dies vom Matter-Standard unterstützt wird.
Xiaomi
Unter der Marke bzw. der Tochterfirma Aqara bietet Xiaomi mittlerweile ebenfalls Matter kompatible Geräte an.
So unterstützt der Hub M2, ab der Firmware Version 4.0.0 Matter in einer Betaversion. Dabei dient dieser dann auch als Bridge, für Nicht-Matter-Geräte, wie die angeschlossenen ZigBee-Geräte. Das Update dient der Einbindung des Hubs in Matter-Umgebungen, ändert allerdings nichts am verwendeten Funkstandard im Hub selbst. Auch der Hub M1S wurde mittlerweile mit einem entsprechenden Update versehen, welches die Matter-Unterstützung im Beta-Stadium nachrüstet.
Neben diesen Hubs existieren im Portfolio von Aqara einige andere Hubs, wie der Hub E1 oder die Camera Hub-Serie. Auch diese sollen perspektivisch Updates für Matter erhalten. Angekündigt waren diese Updates für den Lauf des Jahres 2023.
Allterco
Während die Firma Allterco den wenigsten ein Begriff ist, sieht es bei der Marke Shelly anders aus. Unter dieser werden günstige Smarthome-Komponenten wie schaltbare Steckdosen, Unterputzschalter, Sensoren und einige andere Produkte angeboten.

Der Shelly Plug S
Angesteuert werden die Geräte meist per WLAN oder Bluetooth. Für die Produkte der Plus- und Pro-Reihe wurde Unterstützung für Matter für das zweite Quartal 2023 angekündigt. Allerdings wurde die Veröffentlichung zu diesem Zeitpunkt wieder abgesagt und auf die Zukunft verschoben. Damit ist unklar, wann mit ersten Matter-Geräten unter der Marke Shelly zu rechnen ist.
Bosch
Die Firma Bosch mischt beim Smarthome mit dem System Bosch Smart Home mit. Anfang des Jahres wurde angekündigt, dass das System kompatibel mit dem Matter-Standard sein wird.
So wurde mitgeteilt, dass unter anderem der Smart Home Controller II Matter unterstützen wird. Aktuell wird allerdings nur beschrieben, dass die Geräte auf den Standard vorbereitet sind. Ein kostenloses Update soll später folgen.
Ikea
Der schwedische Möbelproduzent wollte mit dem Dirigera einen Hub mit Matter-Unterstützung auf den Markt bringen. Während der Hub seit Ende 2022 erworben werden kann, sieht es mit dem entsprechenden Update bisher weniger erfreulich aus.
Dieses sollte im ersten Halbjahr des Jahres 2023 erscheinen. Andere Smarthome-Geräte aus dem IKEA-Bestand unterstützen gegenwärtig kein Matter. Auch entsprechende Ankündigungen sind bisher nicht erfolgt.
Da die IKEA Produkte auf ZigBee aufsetzen, wäre, wenn die entsprechenden Funkcontroller dies zulassen, ein Update auf Thread im Rahmen der Matter-Unterstützung denkbar.
Nuki
Die Firma Nuki ist vorwiegend für ihre Türschlösser bekannt. Die Kommunikation der Schlösser läuft über das Bluetooth Low Energy-Protokoll, welche auch über die Nuki Bridge eingebunden werden können und damit indirekt per WLAN ansteuerbar sind.

Eines der Smart Locks von Nuki
Auch wenn die Firma bisher keine Matter-Produkte anbietet, wurde bereits an ersten Prototypen gearbeitet. Eine Aktualisierung bestehender Produkte auf den Matter Standard ist hierbei nicht geplant.
Schneider Electric
Der französische Konzern Schneider Electric hat seine Pläne für Matter mittlerweile verkündet. So sollen die neuste Generation der Wiser Gateways mit Matter kompatibel sein. Dieses dient als Bridge für die angeschlossenen ZigBee-Geräte. Auch die Wiser Home-App soll in Zukunft mit einer entsprechenden Unterstützung versehen werden.
Die ersten Produkte, welche Matter unterstützen sollten, sind das Wiser Gateway und der Wiser Smart Plug. Allerdings ist dies bisher aus den Spezifikationen der Produkte nicht ersichtlich.
Shortcut Labs
Shortcut Labs, eine schwedische Firma, entwickelt und vertreibt mit Flic einen smarten Bluetooth-Taster und dem Flic Hub eine zentrale Steuerungsmöglichkeit für Smarthome-Geräte.
Zur Matter-Unterstützung hat sich Shortcut Labs vor etlichen Monaten geäußert. Diese ist für das Jahr 2023 anvisiert und soll sich auf sämtliche Produkte der Hub-Serie erstrecken. Bisher sind allerdings noch keinerlei Updates für diese Produkte verfügbar.
Weitere Hersteller
Neben den besprochenen Hersteller existieren noch andere Hersteller, welche das eine oder andere Matter fähige Produkt in ihrem Portfolio haben oder solche angekündigt haben. Zu diesen gehören unter anderem Mediola, Netatmo, Sonnof und Ubisys.
Interessant ist auch die angekündigte Unterstützung von Smart-TVs der Hersteller LG und Samsung. Diese sollen in Zukunft über Matter-Unterstützung verfügen und sich so zur Steuerung von Matter-Geräten eignen.
Fazit
Nach einigen Startschwierigkeiten, finden sich nun die ersten Hersteller, welche fertige Produkte für den neuen Standard ausliefern.
Allerdings scheint es auch, dass viele Hersteller die Komplexität von Matter unterschätzt haben und hier auf einen späteren Einstieg in den Markt hinarbeiten. Hier hat Matter bis zu einer entsprechenden Durchdringung des Marktes noch einiges vor sich.
Gemeinsam haben die Ankündigungen, dass sich die Matter-Unterstützung meist verspätet und gar ganz abgekündigt werden.
Ob hier die Komplexität, des doch recht umfangreichen Standards, unterschätzt wurde, darüber kann nur spekuliert werden. Daneben bedeutet eine Unterstützung für Matter nicht automatisch volle Kompatibilität. So wird auf den Echo-Geräten, in den ersten Iterationen, nur eine Handvoll Produktkategorien des Standards unterstützt. Namentlich sind dies Lampen, Schalter und Steckdosen.
Dies führt z. B. zu dem Problem, dass Matter-Bridges im Amazon-Kontext aktuell nicht genutzt werden können. Das Gleiche gilt für SmartThings von Samsung.
So fühlt sich der Matter-Start in vielen Fällen holprig an und kommt nur Stück für Stück voran. Es bleibt abzuwarten, ob hier in Zukunft, nachdem der Standard etabliert ist, Besserung kommt.
Die Einfachheit, welche dem Endbenutzer versprochen wurde, erstreckt sich leider nicht auf die Implementation seitens der Hersteller. Dies zeigt, wie herausfordernd es ist, einen neuen Standard in einem bereits etablierten Markt zu implementieren. Trotz der Versprechen von einfacher Handhabung und nahtloser Kompatibilität ist die Realität oft eine andere. Die Implementierung von Matter erfordert eine genaue Planung und sorgfältige Ausführung. Viele Hersteller scheinen sich noch in der Anfangsphase dieses Prozesses zu befinden.
Allerdings sollte berücksichtigt werden, dass diese anfänglichen Herausforderungen nicht unbedingt auf langfristige Probleme hindeuten. Sie könnten viel mehr als Wachstumsschmerzen betrachtet werden, die oft mit der Einführung neuer Technologien einhergehen.
Ein bedeutsamer Aspekt, der im Kontext von Smarthome-Installationen hervorgehoben werden sollte, ist die Langlebigkeit einer solchen. Sie ist nicht auf einen kurzen Zeitraum von wenigen Jahren ausgelegt, sondern soll teilweise Jahrzehnte genutzt werden. Hier muss der Matter-Standard sich ein entsprechendes Vertrauen erarbeiten und die Hersteller eine langfristige Unterstützung bereitstellen.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.