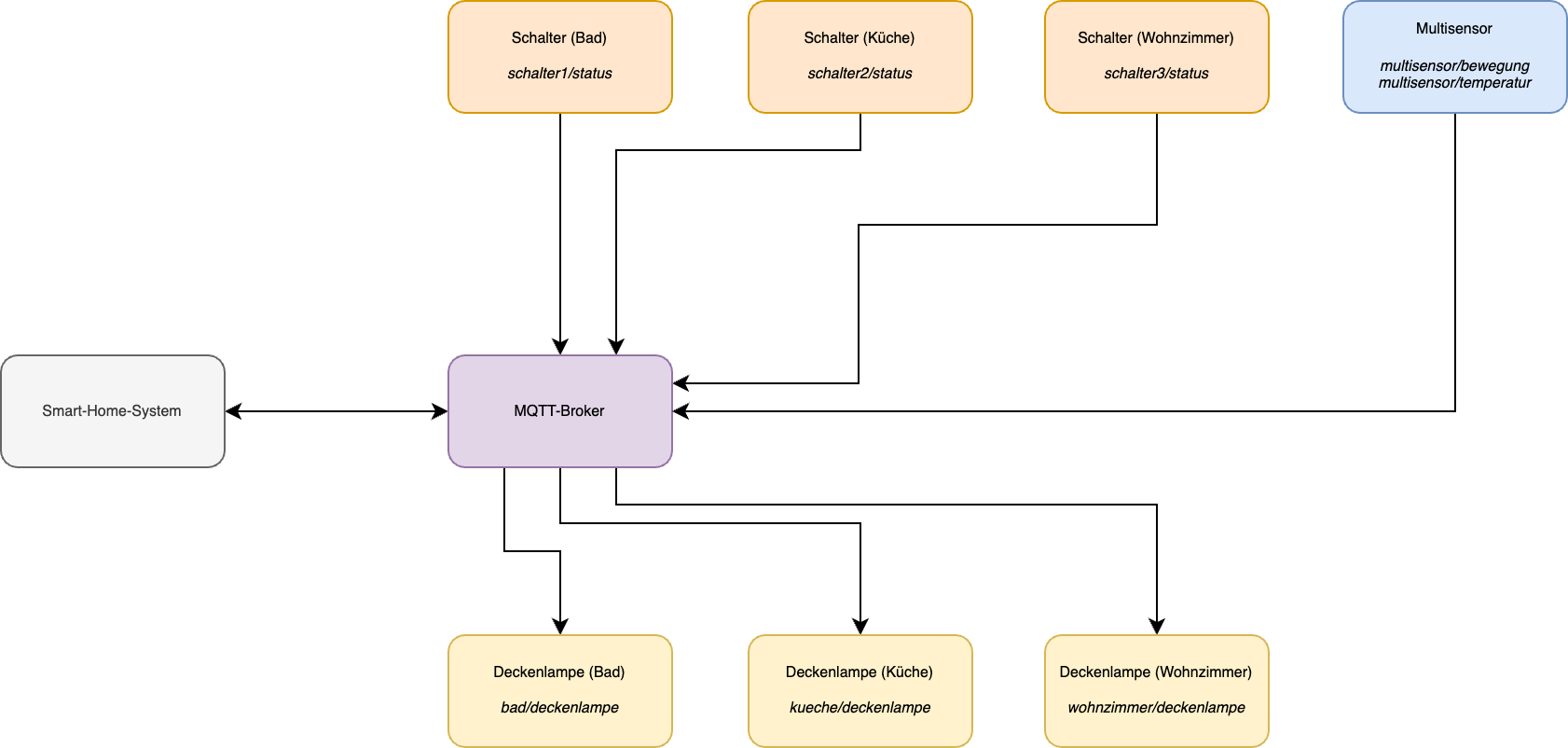
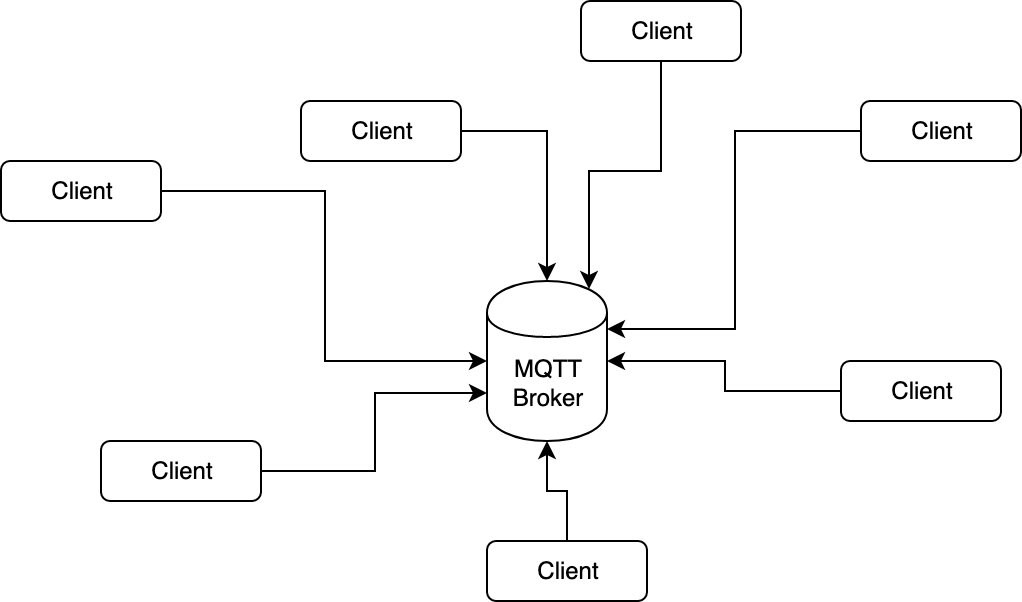
In der Softwareentwicklung existierten schon immer Werkzeuge und Vereinfachungen wie Autocompletion oder Syntax-Highlighting, die den Entwicklungsprozess effizienter und weniger fehleranfällig machen sollten. Diese Werkzeuge haben es Entwicklern ermöglicht, sich stärker auf die Logik und Funktionalität ihres Quellcodes zu konzentrieren, anstatt sich mit den Details der Syntax oder der Strukturierung von Quellcode herumzuschlagen.
In den vergangenen Jahren hat sich die Landschaft der Softwareentwicklung weiterentwickelt und neue Technologien und Methoden haben Einzug gehalten. Beispielsweise haben Versionskontrollsysteme wie Git die Zusammenarbeit in Teams wesentlich verbessert und Continuous-Integration-/Continuous-Deployment-Pipelines ermöglichen es, Änderungen effizienter in Produktionsumgebungen zu bringen.

KI-Werkzeuge sollen die Entwicklungsarbeit vereinfachen
Aktuell finden immer mehr Werkzeuge, die mit maschinellem Lernen oder großen Sprachmodellen (Large Language Models) arbeiten, ihren Weg in die Praxis. Assistenten wie GitHub Copilot oder Tabnine nutzen hierbei große Mengen an Trainingsdaten, um Entwicklern kontextbezogene Vorschläge anzubieten, die weit über einfache Autocompletion hinausgehen. So können komplexere Code-Snippets vorgeschlagen oder ganze Methoden und Funktionen auf Basis kurzer Beschreibungen generiert werden.
Im Idealfall soll dies die Produktivität erhöhen, auch wenn das letzte Wort hierbei noch nicht gesprochen ist. Doch welche Werkzeuge existieren? Im Rahmen des Artikels soll ein Blick auf spezialisiertere Lösungen zur Entwicklung abseits von ChatGPT und Co. geworfen werden.
Arten von Werkzeugen
Auf dem Markt der KI-Werkzeuge zur Softwareentwicklung existieren Werkzeuge unterschiedlicher Couleur. Neben Integrationen für eine Anzahl von IDEs, existieren Standalone-Tools und auch webbasierte Tools. Viele KI-Werkzeuge sind als Plugins oder Erweiterungen für IDEs wie Visual Studio Code oder IntelliJ IDEA verfügbar. Diese Integrationen ermöglichen es, KI-gestützte Funktionen direkt in der gewohnten Entwicklungsumgebung zu nutzen, was den Arbeitsablauf verbessert.
Einige dieser Werkzeuge bieten spezialisierte Funktionen, die auf bestimmte Aspekte der Softwareentwicklung abzielen, wie Code-Generierung, Fehlererkennung, Optimierung, Review oder Testautomatisierung.
Code-Assistenten
Einer der häufigsten neuen Werkzeug-Typen sind Code-Assistenten, welche es ermöglichen Quellcode zu generieren und diese Fähigkeit in einer Entwicklungsumgebung einzusetzen. Daneben können Fragen zum Quellcode gestellt, Dokumentationen erzeugt, oder Vorschläge für ein Refactoring erzeugt werden.
Bei diesen Code-Assistenten finden sich etliche Schwergewichte der IT, wie Amazon oder Microsoft wieder.
Amazon Q
Als Antwort auf GitHub Copilot stellte Amazon CodeWhisperer vor. Mittlerweile ist dieses Werkzeug in Amazon Q aufgegangen.
Für Entwickler dürfte das Teilprodukt Amazon Q Developer interessant sein. Für dieses sind unter anderem Integrationen für die JetBrains IDEs, VS-Code und Visual Studio verfügbar. Auch eine Version für die Kommandozeile wird geboten.
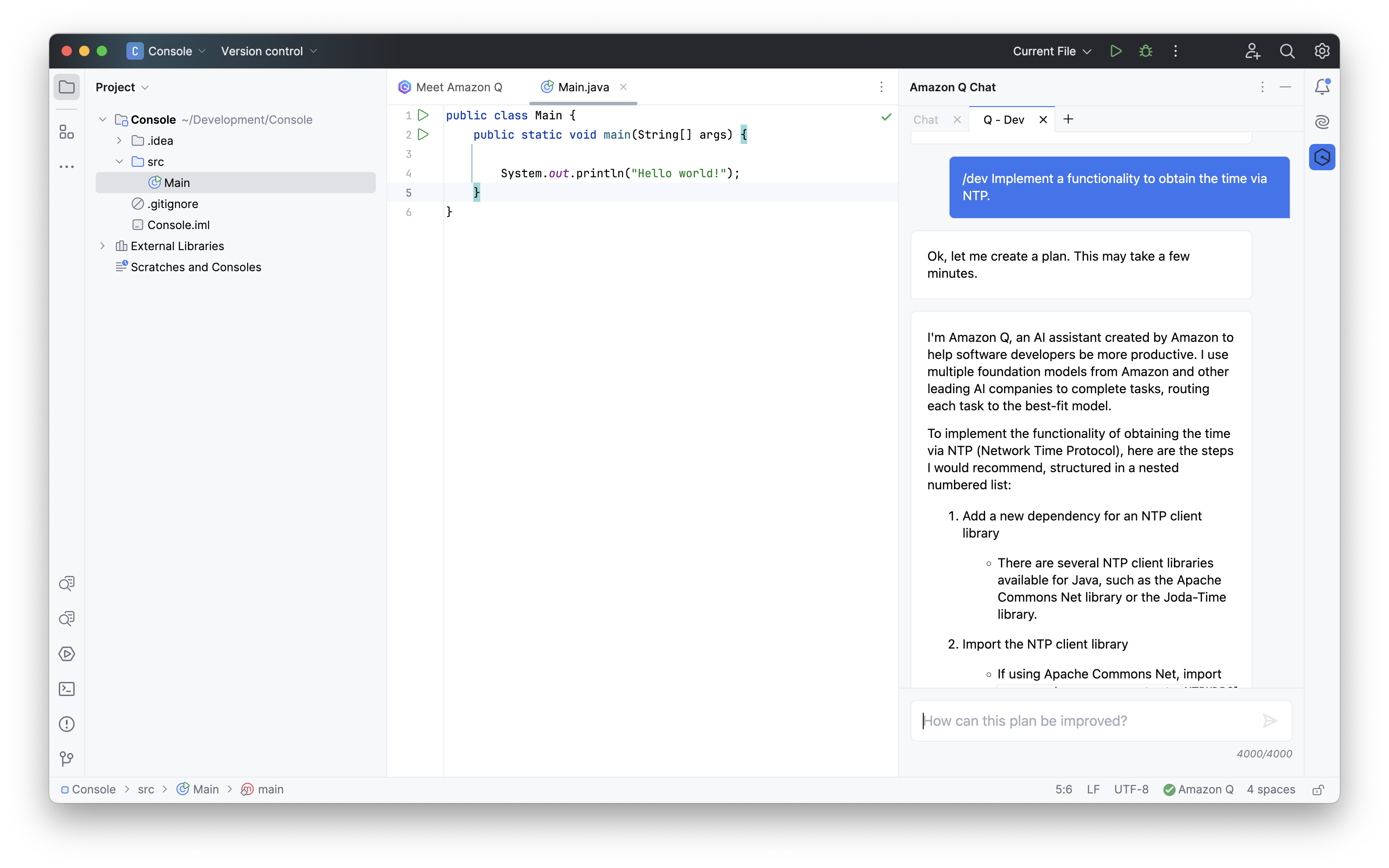
Amazon Q in einer Jetbrains IDE
Für den Assistenten wird eine AWS Builder ID benötigt. Im begrenztem Rahmen kann der Assistent, damit kostenlos ausprobiert werden.
Sinnvolle Ergebnisse liefert der Assistenz nur bei Anfragen in englischer Sprache. Interessant ist die Möglichkeit, Quelltext zu generieren, der über mehrere Dateien reicht. Hier haben andere Assistenten meist ihre Probleme und erzeugen nur Quellcode an einem Stück.
Gesteuert wird der Assistent über Befehle wie /dev mit einem darauffolgenden Prompt. Angeboten wird neben der kostenlosen Variante, ein Business Lite und ein Business Pro Abonnement.
Insgesamt fühlt sich Amazon Q als generisches KI-Werkzeug zur Entwicklung unzureichend an, allerdings könnte es anders aussehen, wenn eine engere Verzahnung mit AWS und die Nutzung eigener Geschäftsdaten gewünscht wird.
Codeium
Codeium ist ebenfalls ein Code-Assistent, welcher sich in unterschiedlichste IDEs integriert.
Codeium unterstützt eine Reihe von IDEs
Das Plugin verfügt über eine Chat-Funktionalität, welche es ermöglicht Anforderungen bzw. Prompts zu definieren. Negativ fällt auf, dass hier die aktuell genutzte Programmiersprache nicht automatisch erkannt wird, sondern explizit angegeben werden muss.
Auch das Antworten auf bereits erzeugte Nachrichten muss separat erledigt werden. Wird stattdessen direkt im Chatfenster geantwortet, wird eine neue unabhängige Konversation gestartet. Soll auf einen vorherigen Chat Bezug genommen werden, so muss der Continue this chat-Button genutzt werden.
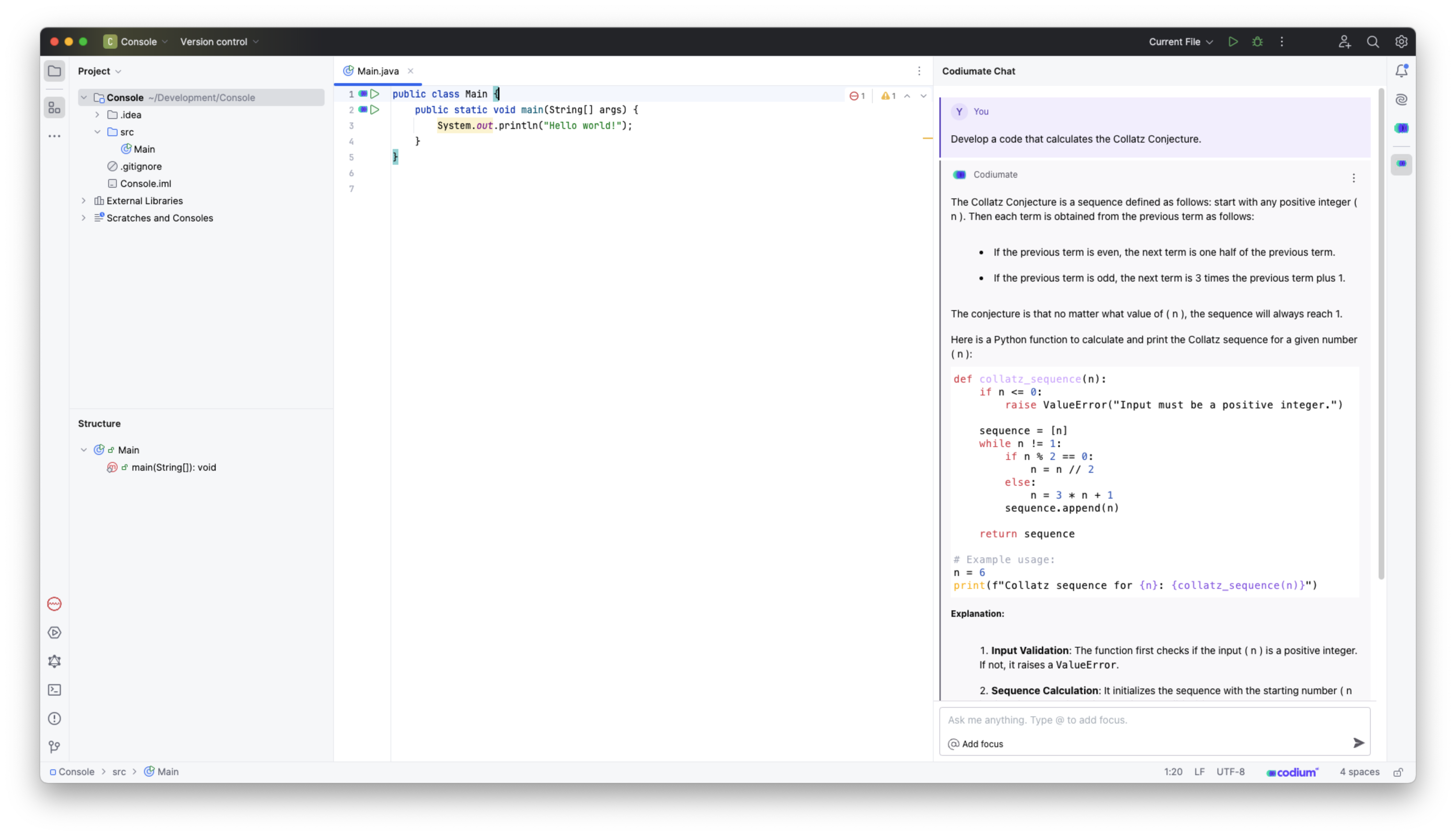
Die Chat-Funktionalität nutzt die falsche Programmiersprache
Interessanter ist die Möglichkeit, relativ unkompliziert Unit-Tests für ausgewählte Methoden zu generieren. Hierfür wird eine Methode ausgewählt und entsprechende Testfälle werden ermittelt und anschließend in Code umgesetzt.
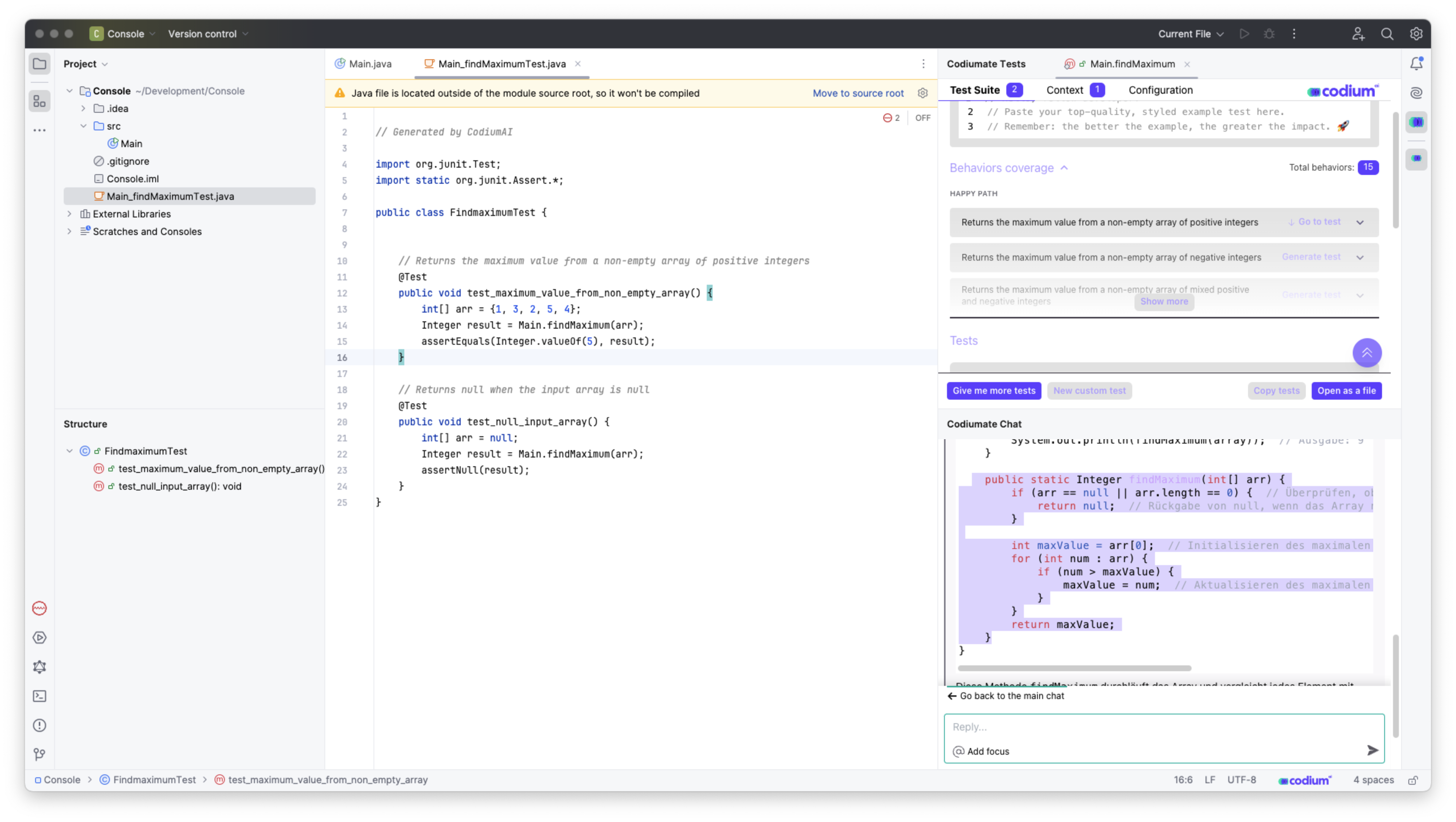
Codium erzeugt Testfälle
Anschließend können die Testfälle in eine Datei übernommen werden. Auch hier fehlt wieder der Kontext, da die Datei standardmäßig einfach im Hauptverzeichnis des Projektes abgelegt wird, zumindest bei der JetBrains-IDE-Integration.
Genutzt werden für Codium die OpenAI-Modelle der GPT-3 und GPT-4 Reihe. Interessant ist Codium für Plattformen, bei denen sonst keine IDE-Integration vorliegt, da Codium hier mit Vielfalt glänzt.
Neben dem Codeassistenten bietet Codium mit Forge auch eine Lösung für das Review von Quellcode an.
Cody
Mit Cody existiert ein KI-gestützter Assistent zur Softwareentwicklung. Nicht verwechselt werden sollte der Assistent mit Cody AI, das sich mehr als KI-unterstützte Suche auf Basis einer Firmen-Wissensbasis versteht.
Neben der Webvariante von Cody werden primär die Entwicklungsumgebungen VS Code und die JetBrains-IDEs unterstützt. Daneben existiert eine experimentelle Unterstützung für Neovim. Andere IDEs wie Eclipse und Emacs sollen in Zukunft folgen.
In der JetBrains-Variante wirkt die Integration ausgereift. So ist nicht nur ein Fenster verfügbar, in dem ein Chat angezeigt wird, sondern es existiert auch eine Integration im Code-Editor.
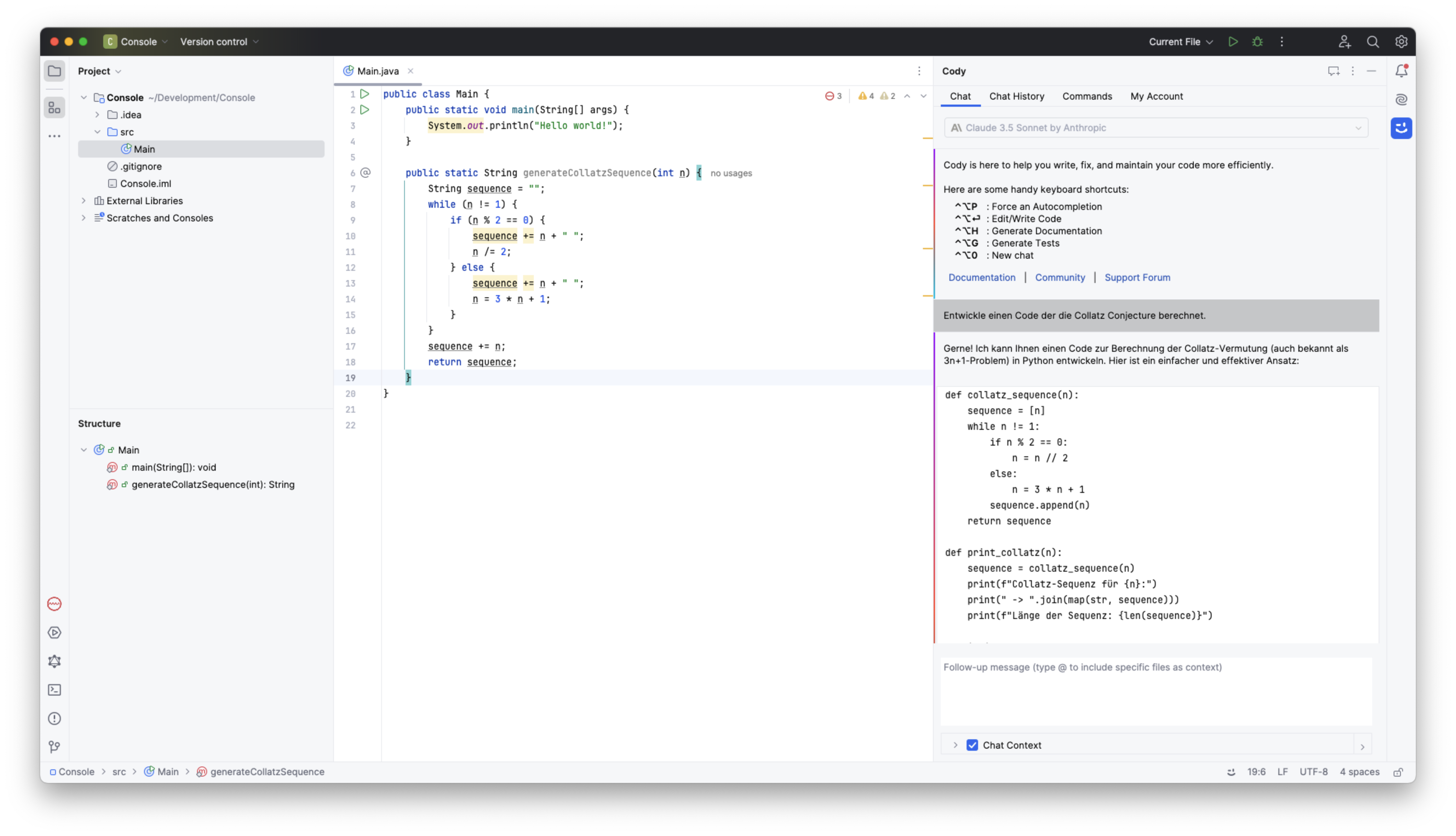
Anhand des Methodennamens wurde der Inhalt der Methode generiert
Während im Chatfenster der Kontext, wie die aktuell verwendete Programmiersprache nicht erkannt wird, sieht dies im Code-Editor anders aus. Hier wird der Code in der verwendeten Sprache generiert.
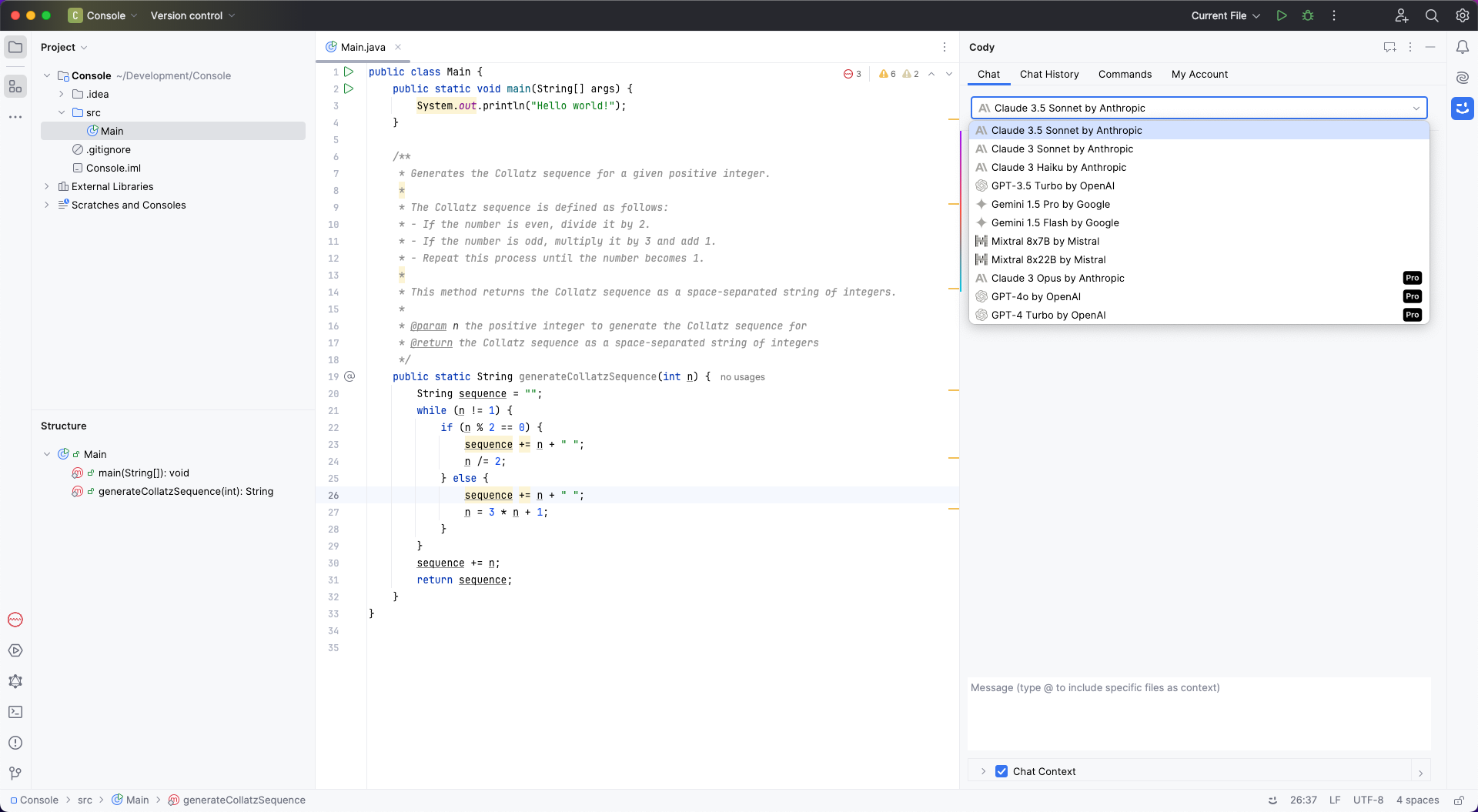
Die Modellauswahl im Chat-Fenster
Ein Merkmal, mit dem sich Cody von anderen KI-Assistenten unterscheidet, ist die transparente Auswahl der genutzten Modelle. Das passende Modell kann hierbei einfach ausgewählt werden.
Neben den Möglichkeiten zur Codegenerierung bietet Cody auch die Möglichkeit vorgefertigte Kommandos zu nutzen und mit diesen das Dokumentieren von Quellcode oder Unit-Test zu automatisieren.
CodeSquire
CodeSquire ist eine spezialisierte KI-Assistent-Lösung in Form einer Erweiterung für den Browser Chrome. CodeSquire ist ein Tool für Datenwissenschaftler, das Kommentare in Code umwandelt, SQL-Anfragen aus natürlicher Sprache erstellt, intelligente Codevervollständigung bietet und komplexe Funktionen generiert.
Unterstützt werden aktuell Plattformen wie Google Colab, BigQuery und JupyterLab.
Diese Plattformen zählen zu IDEs, die meist speziell für interaktive Datenanalyse und wissenschaftliches Rechnen genutzt werden. Diese speziellen IDEs kombinieren viele Funktionen, die in traditionellen IDEs zu finden sind, wie Code-Editoren, Terminals und Dateibrowser, mit speziellen Werkzeugen für die Arbeit mit Daten und interaktiven Notebooks.
CodeWP
Ebenfalls zu den spezialisierten Lösungen zählt CodeWP, welches einen Assistenten darstellt, welcher auf WordPress spezialisiert ist.
CodeWP
Die dahinterliegenden Modelle sind darauf trainiert, Code in PHP und JavaScript im Kontext von WordPress zu generieren. So kann mit einem einzelnen Prompt ein einfaches Plugin generiert werden.
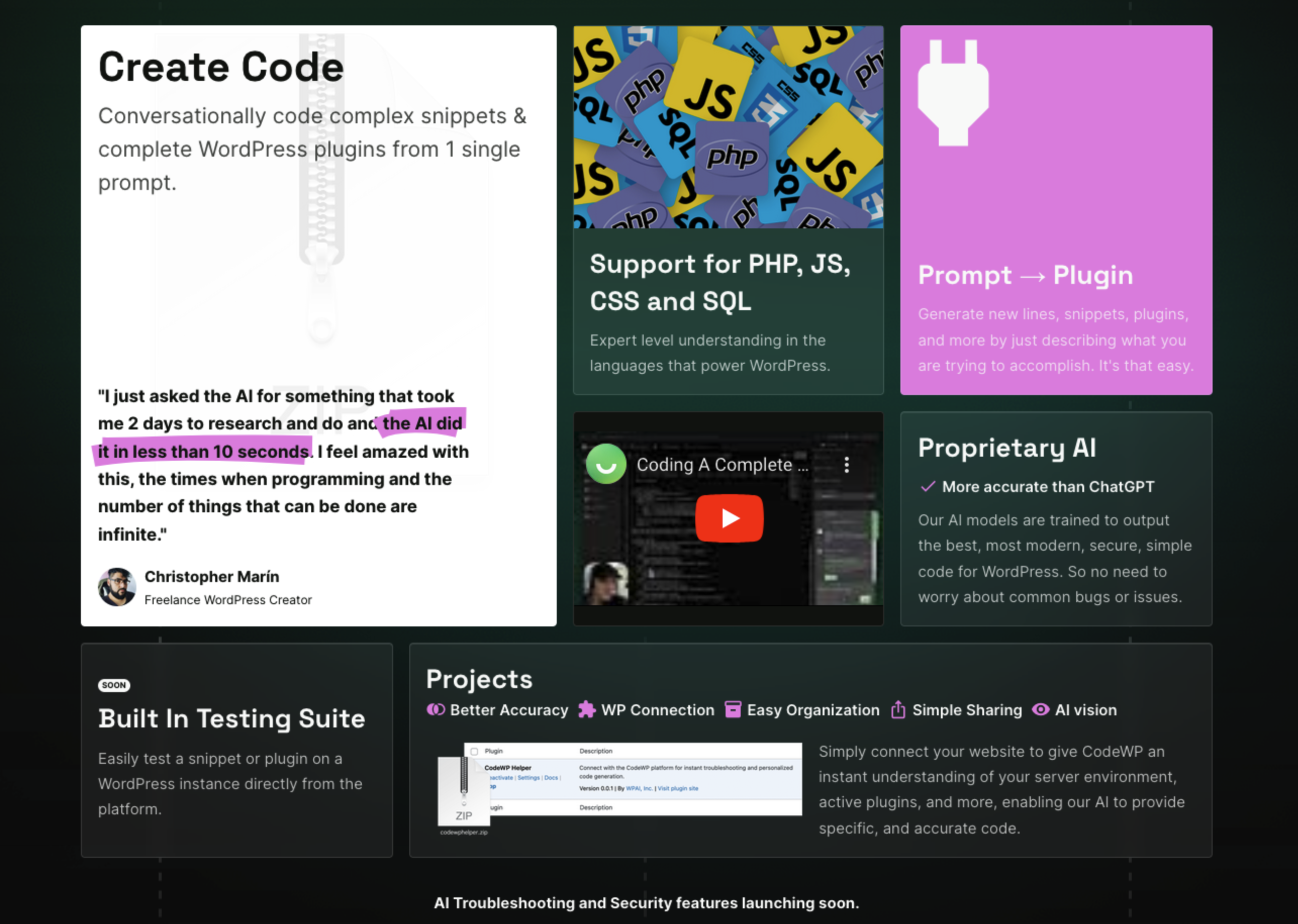
Die CodeWP-Website
CodeWP erweckt mit Aussagen wie Proprietary AI und More accurate than ChatGPT sowie der Aussage:
Our Al models are trained to output the best, most modern, secure, simple code for WordPress. So no need to worry about common bugs or issues.
den Eindruck, dass ein eigenes Sprachmodel verwendet wird, ohne auf Mitbewerber wie OpenAI angewiesen zu sein.
Cursor
Cursor versteht sich, im Gegensatz zu den bisher vorgestellten Assistenten, als dedizierte IDE mit einer KI-basierten Unterstützung für Entwicklung.
Technisch handelt es sich um einen Fork von VS Code. Der Grund hierfür, ist nach Aussage des Herstellers, in der besseren Anpassbarkeit der IDE zu finden.
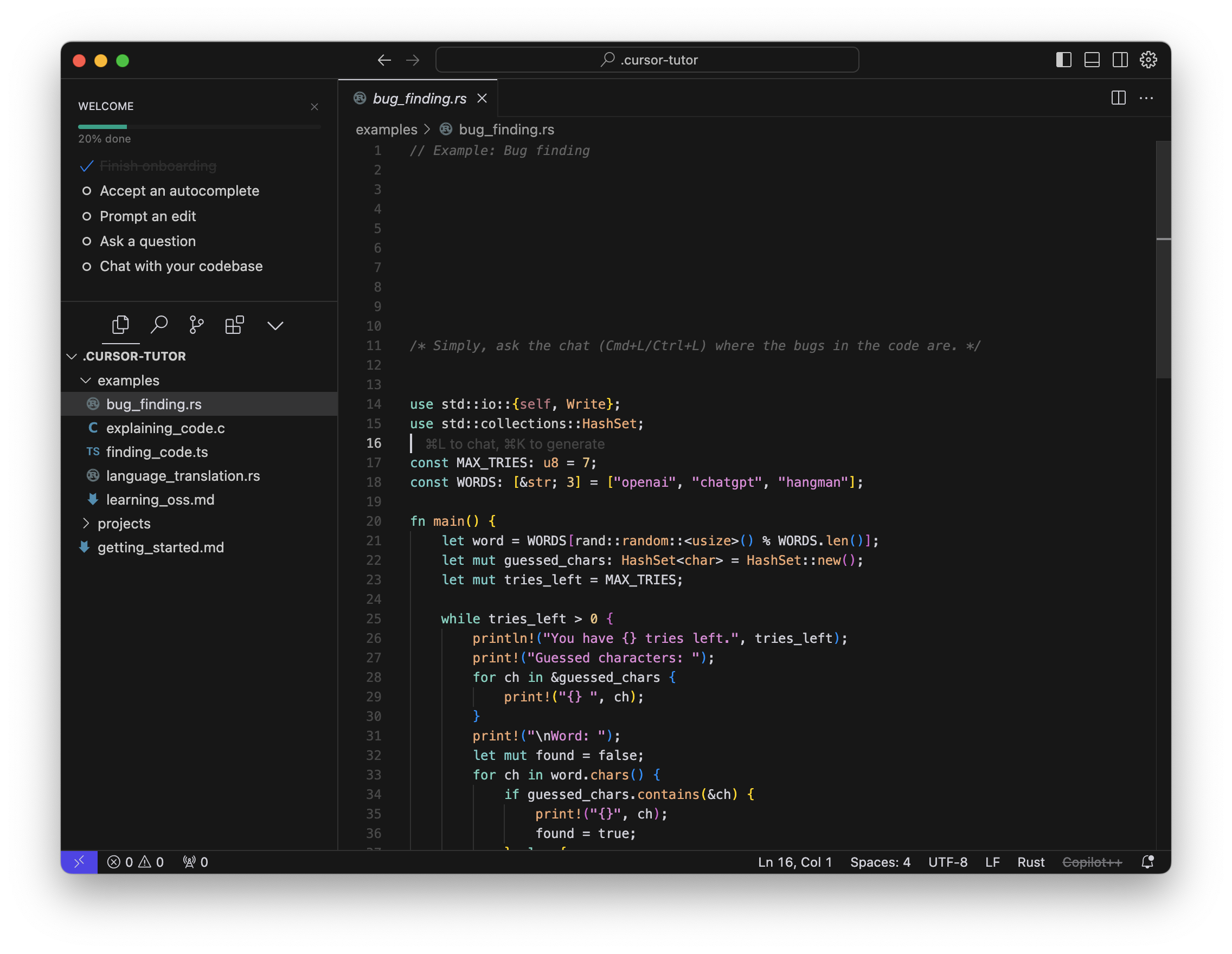
Der Onboarding-Prozess von Cursor
Nach der Installation wird der Nutzer durch einen kleinen Onboarding-Prozess geführt. Dieser führt in die Möglichkeiten ein, Bugs zu identifizieren, spezifische Codestellen zu lokalisieren oder Code von einer Programmiersprache in eine andere zu übersetzen.
Cursor kann natürliche Sprache verstehen und darauf reagieren, was es erleichtern soll, direkt im Code-Editor mit der KI zu interagieren. So können Fragen zu Codebasis gestellt werden, Vervollständigungen angefordert werden oder Code-Snippets generieren werden.
Die Freemium-Version unterliegt einigen Einschränkungen, welche in den kostenpflichtigen Tarifen aufgehoben werden.
Fraglich ist, ob hierfür eine neue IDE benötigt, und warum nicht auf Integrationen für bestehende Systeme gesetzt wurde. In den meisten Fällen werden Entwickler doch meist auf ihre angestammten Werkzeuge setzen wollen.
GitHub Copilot
Zu den bekannteren Lösungen auf dem Markt zählt sicherlich GitHub Copilot. Dieses Werkzeug ist in allen Varianten (bis auf die Trial-Version) kostenpflichtig.
Neben der Nutzung über die Kommandozeile, existieren eine Reihe von IDE-Integrationen, insbesondere für Visual Studio, VS Code und die JetBrains IDEs. Daneben werden Vim und Neovim, sowie Azure Data Studio unterstützt.
GitHub Copilot in einer JetBrains-IDE
Positiv fällt die Autovervollständigung bzw. die Geschwindigkeit derselben auf. Allerdings ist sie in einigen Fällen auch relativ nervig, da sie bei der Entwicklung zu unnötiger Ablenkung führen kann.
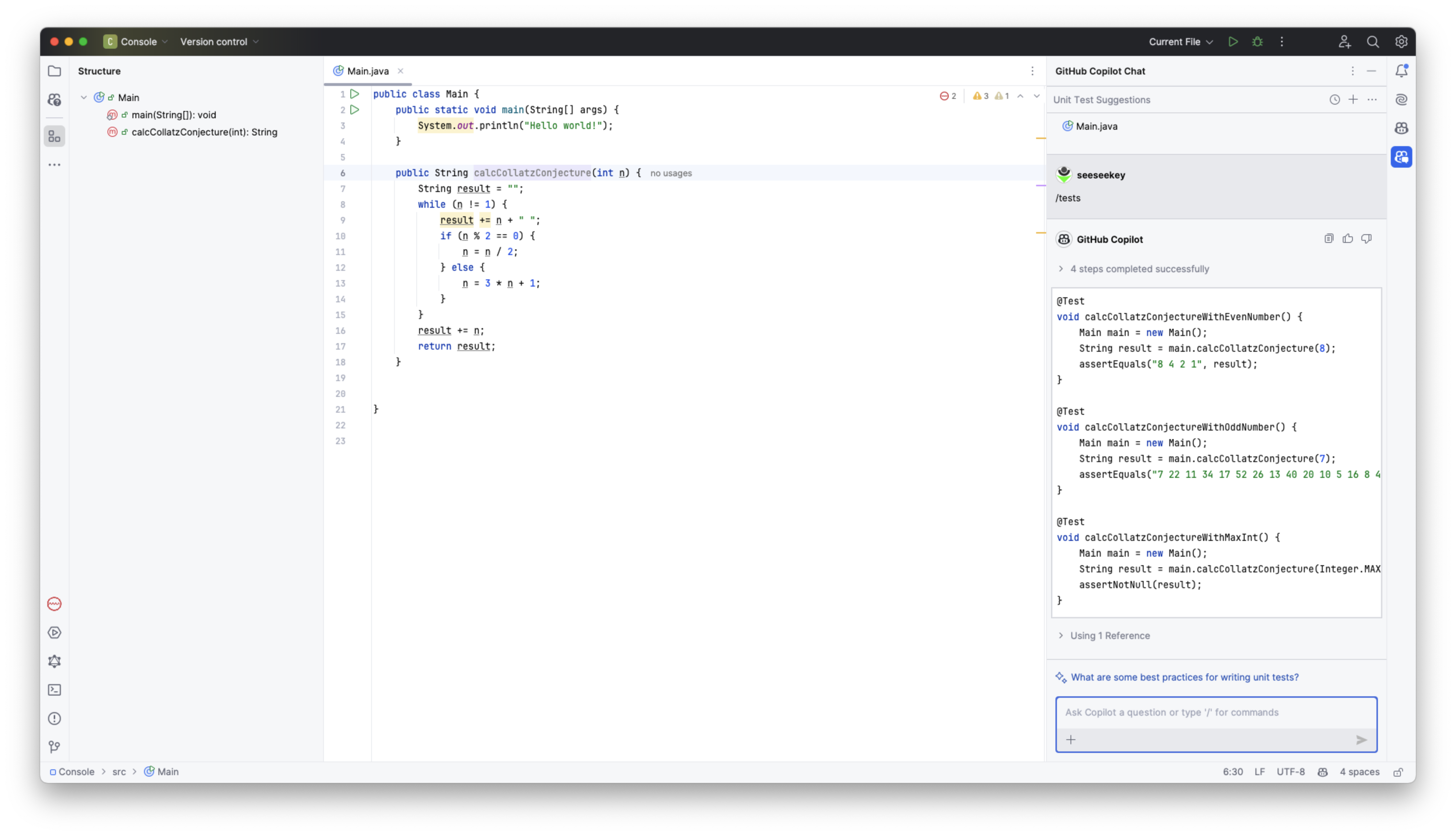
Eine Methode wird generiert
Zumindest in den JetBrains-IDEs gibt es keine Integration über die Quick-Fixes-Funktionalität. Dafür stehen eine Reihe von Kommandos wie /tests, /simplify, /fix oder /explain zur Verfügung.
Diese können in der eingebauten Chat-Funktionalität genutzt werden. Die Ergebnisse werden im Chat angezeigt, können allerdings nicht automatisch ins Projekt übernommen werden, sondern müssen kopiert und wieder eingefügt werden. Besonders nervig ist dies bei der Generierung von Dokumentation für Methoden, wie sich im Vergleich zum Assistenten JetBrains AI zeigt.
Positiv hervorzuheben ist die automatische Übernahme des Kontexts, wenn Themen im Chat angesprochen und genutzt werden.
JetBrains AI
Das tschechische Unternehmen JetBrains ist primär für seine unterschiedlichen IDEs bekannt und bietet mit JetBrains AI einen Assistenten für KI-unterstütze Entwicklung. Auch JetBrains AI muss über ein Abonnement freigeschaltet werden. Wenig verwunderlich ist die Integration von JetBrains AI in die jeweiligen IDEs der Firma sehr gelungen.
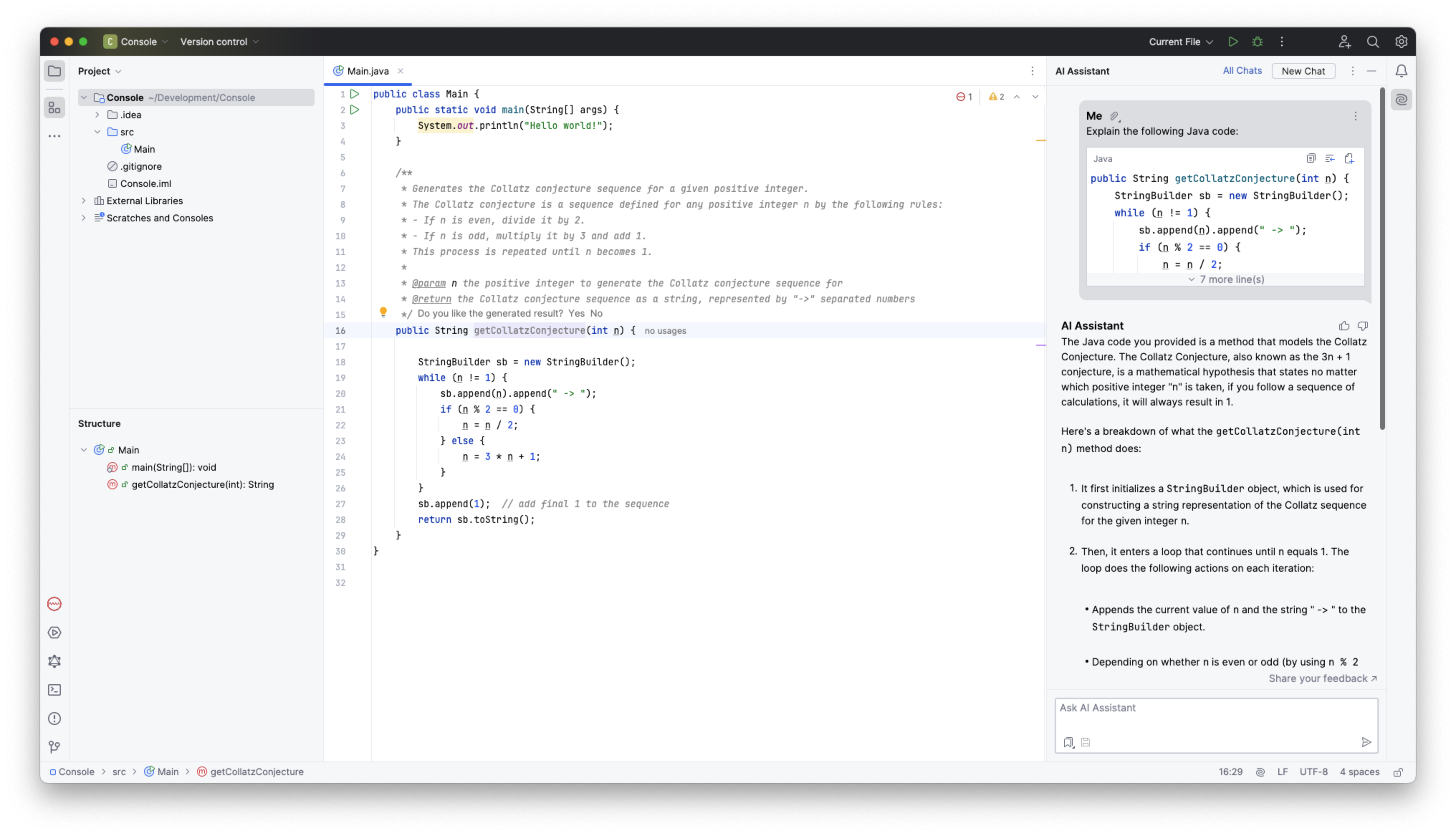
Entwicklung mit der JetBrains AI
Neben der bei vielen KI-Assistenten gegebenen Möglichkeiten des Chats mit dem Sprachmodell, bietet JetBrains AI die Möglichkeit von Quick-Fixes in Form von AI Actions, welche unter anderem das Schreiben von Dokumentation oder das Generieren von Unit-Tests vereinfachen sollen.
Neben den vorgefertigten Prompts können eigene Prompts hinterlegt und diese dann ebenfalls über die AI Actions genutzt werden. Angenehm an JetBrains AI ist die Möglichkeit Dokumentation wie Javadoc automatisch für eine Methode generieren und antragen zu können.
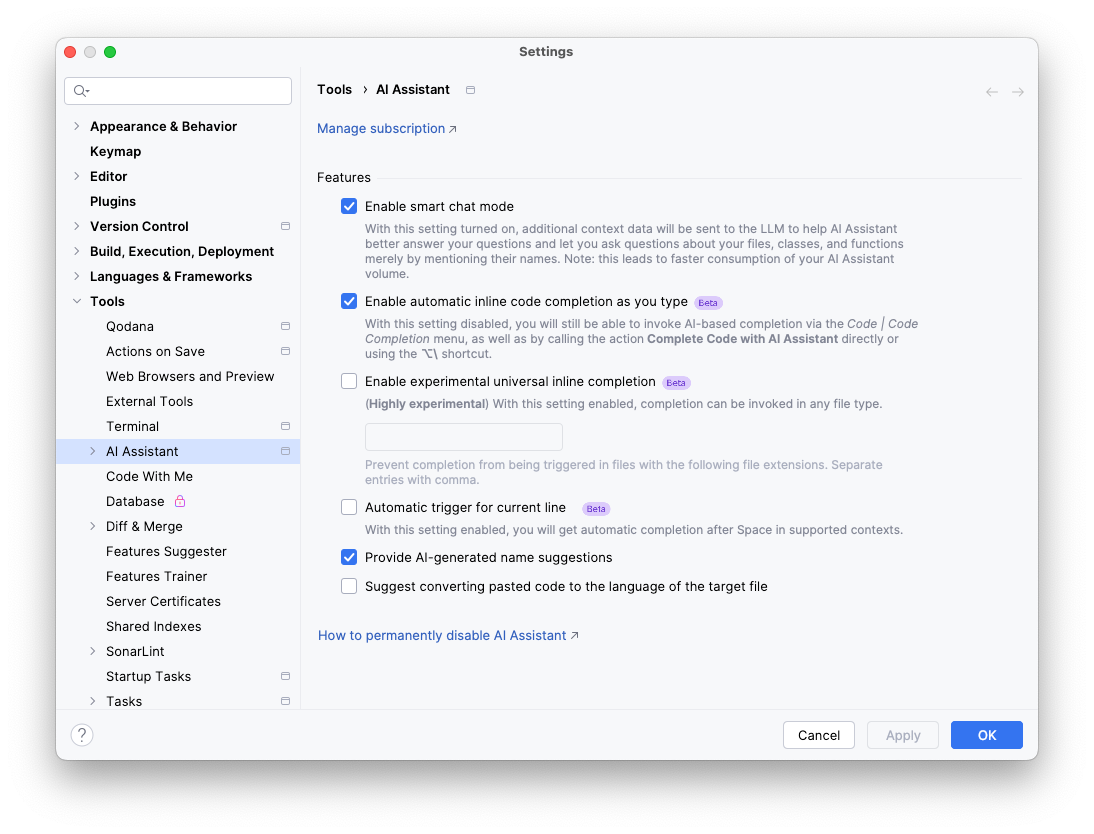
Die Einstellungen für JetBrains AI
Automatische Codevorschläge während der Entwicklung sind so gestaltet, dass sie nicht unnötig ablenken und können über die Einstellungen konfiguriert werden.
Daneben findet sich der KI-Assistent noch in anderen Integrationen wieder, wie bei der Umbenennung bzw. der Namensfindung, hier werden neben den klassischen Vorschlägen auch KI-Vorschläge angezeigt.
Durch ein kleines Symbol wird transparent gezeigt, welche Vorschläge von der KI stammen und welche nicht. Grundsätzlich zieht sich diese Transparenz durch JetBrains AI bzw. dessen Implementation.
Auch Fragen zu bestimmten Teilen des Quellcodes können schnell und bequem gestellt werden, indem an der gewünschten Stelle über eine Quick-Action ein KI-Chat zum aktuellen Quellcode gestartet wird.
Weitere Kleinigkeiten sind die Generierung von Commit-Nachrichten, welche ebenfalls von JetBrains AI bereitgestellt werden.
Während im Standard-Abonnement von JetBrains AI nicht gewählt werden kann, welche Sprachmodelle verwendet werden, soll dies später in den Enterprise-Varianten auswählbar sein. Je nach genutzter Funktionalität scheinen im Moment unterschiedliche Modelle genutzt werden.
Neben JetBrains AI, verfügen einige IDEs wie IntelliJ IDEA Ultimate mittlerweile auch über Möglichkeiten zur Codevervollständigung über ein lokales Sprachmodell, welches ohne externe Zugriffe auskommt.
Die IDE-Integration von JetBrains AI wirkt insgesamt sehr ausgereift, insbesondere im Vergleich zu anderen KI-basierten Assistenten. Dafür steht JetBrains AI nur für die entsprechenden IDEs der Firma zur Verfügung.
Tabnine
Die Firma hinter Tabnine existiert schon länger als der aktuelle KI-Hype und hat seit längerem Code-Assistenten zur Unterstützung in der Entwicklung angeboten.
Ursprünglich bekannt als Codota, hat sich das Unternehmen auf die Entwicklung von KI-basierten Werkzeugen für Entwickler spezialisiert. Im Gegensatz zu vielen anderen Lösungen wird bei Tabnine, über Tabnine Enterprise, auch das Selbst-Hosting angeboten.
Interessant ist bei Tabnine die Wahl der Modelle zur Verarbeitung der Anfragen. Hier werden Modelle wie Tabnine Protected angeboten, welche nur mit Quellcodes trainiert wurden, welche eine entsprechende Lizenz besitzen und somit idealerweise z. B. keine Codeschnipsel unter GPL replizieren.
Auch werden je nach Modell gewisse Garantien gegeben, was Themen wie Datenschutz und die Weiterverwendung der Prompts angeht. Daneben werden die Modelle über Tags sinnvoll kategorisiert, sodass die Wahl des passenden Modells aufgrund dieser getätigt werden kann.
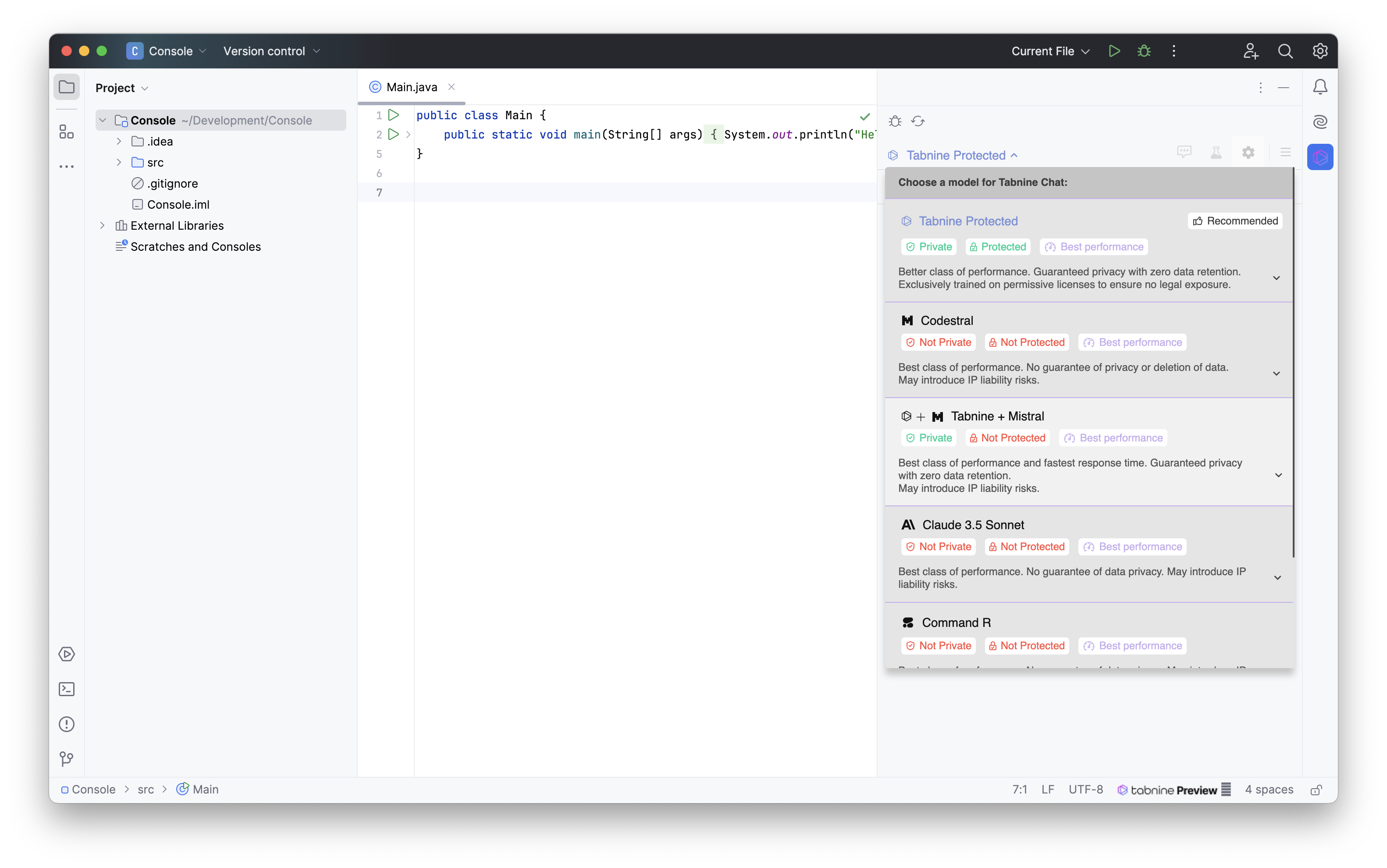
Die Auswahl der Modelle
Bei den IDEs unterstützt Tabnine eine Reihe von IDEs, angefangen bei VS Code über die JetBrains-IDEs, bis hin zu Neovim.
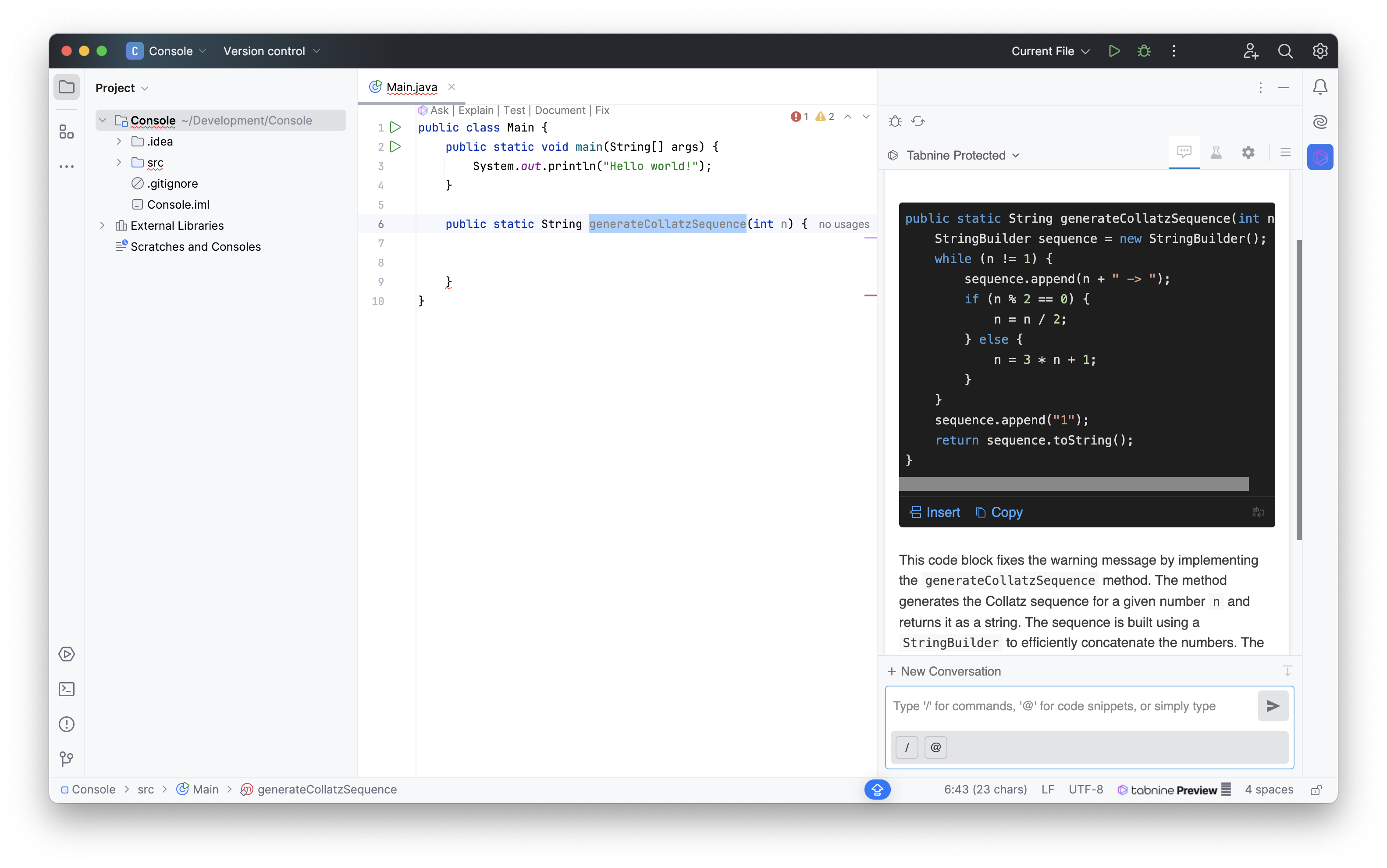
Die Fix-Funktionalität von Tabnine
In Bezug auf die IDE-Integration wirkt Tabnine in JetBrains-IDEs recht gut integriert. Dadurch können kontextbasierte Operationen wie das Beheben von Fehlern oder das Dokumentieren von Quellcode effizient durchgeführt werden.
Im Tabnine-Chat wird dabei eine Antwort generiert und dessen Ergebnis kann mit in den Quellcode übernommen werden.
Das manuelle Einfügen fühlt sich allerdings immer etwas umständlich an und aktiviert oft die automatische Codeformatierung nicht, was im schlechtesten Fall immer einen zusätzlichen Bearbeitungsschritt bedeutet.
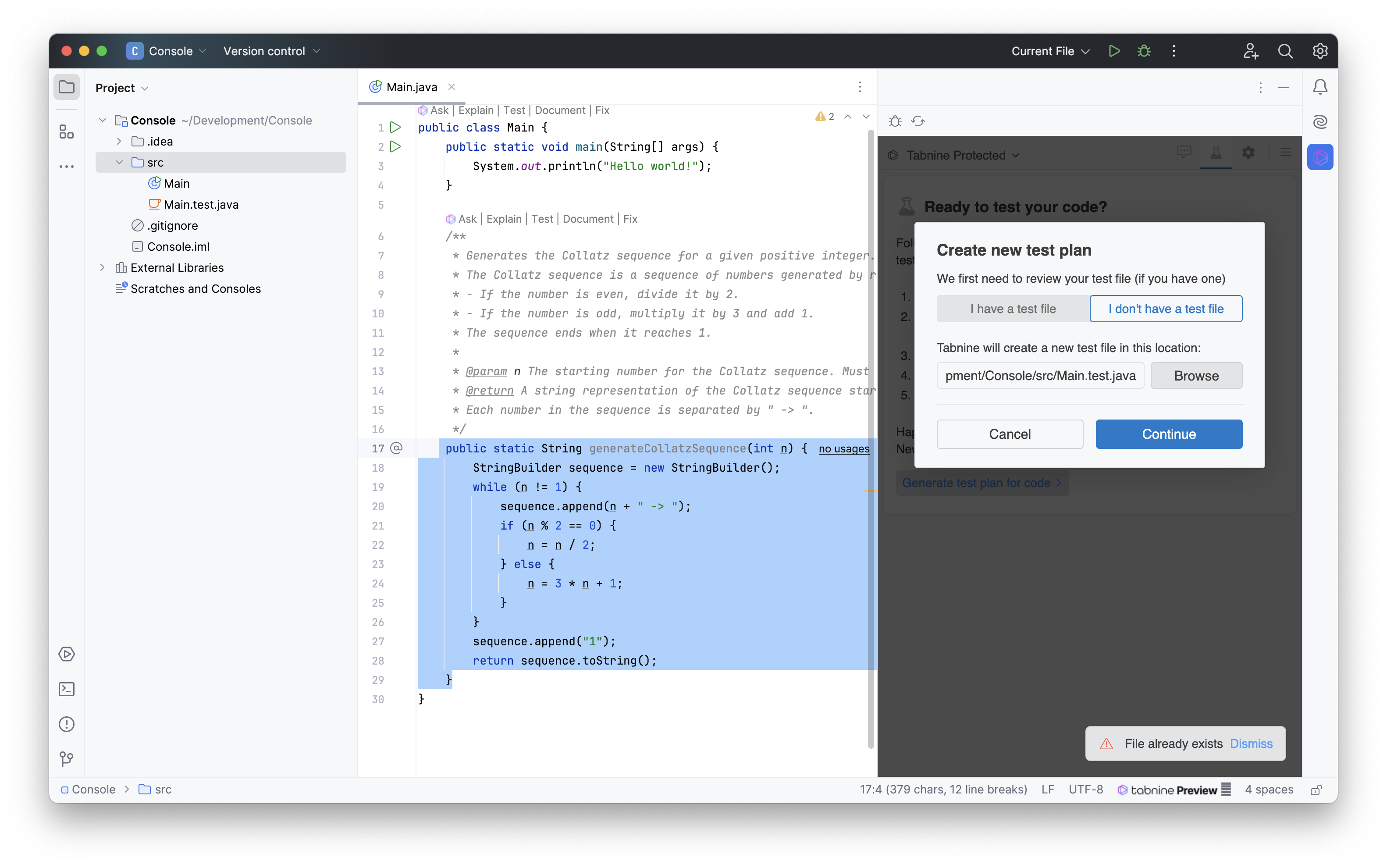
Die Generation eines Tests schlägt fehl
Andere Operationen, wie die Erstellung eines Testplans, können unter Umständen scheitern, da eine vom Plugin generierte Datei möglicherweise nicht befüllt werden kann, was auf einen Bug hinzudeuten scheint.
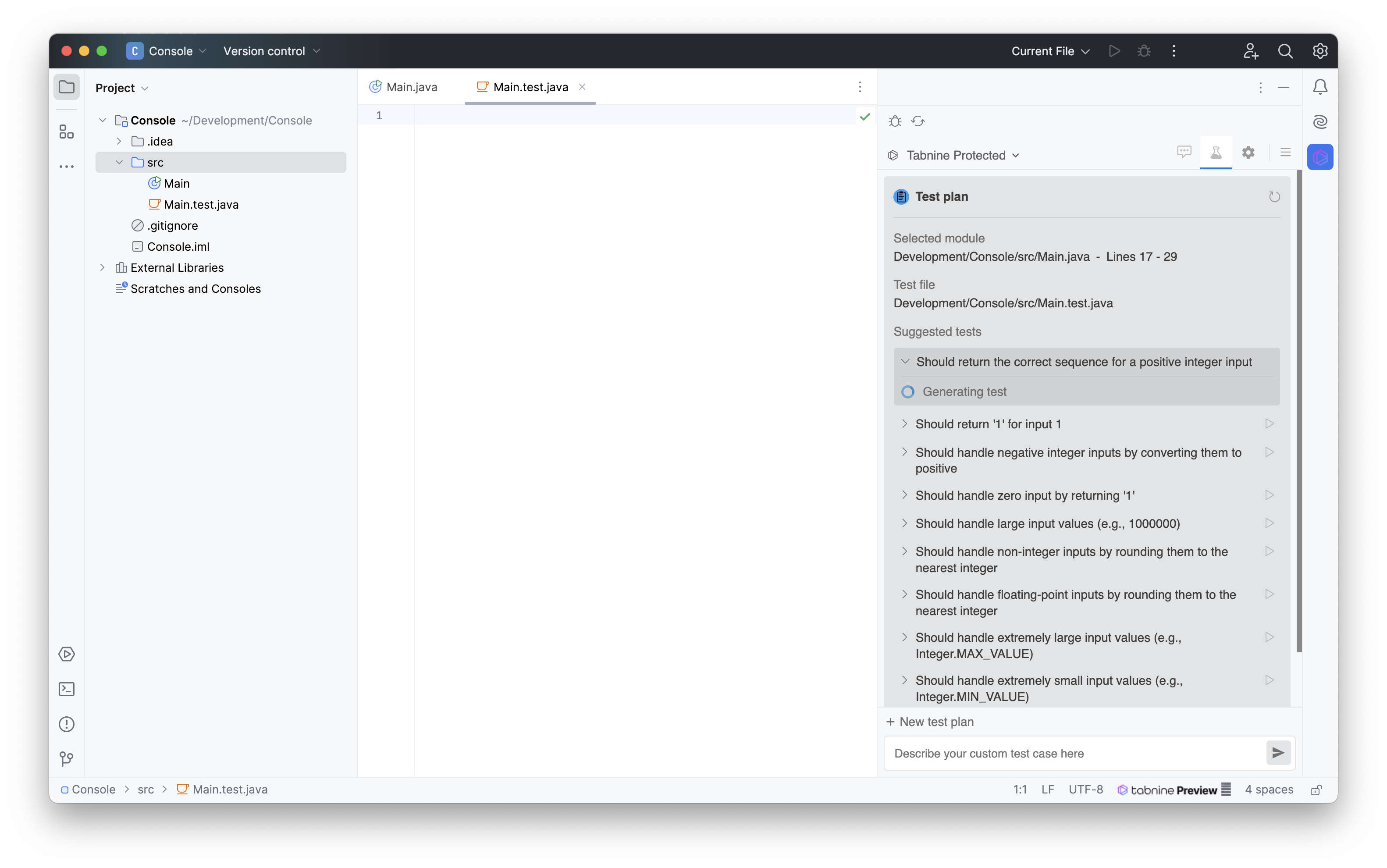
Die Testplan-Ideen von Tabnine
Auch wenn die Ideen für den Testplan von Tabnine interessant sind, fühlt sich hier die Integration durch das manuelle Einfügen komplex und fehleranfällig an.
Analyse-Werkzeuge
Neben den allgemeinen Code-Assistenten existieren einige Werkzeuge, welche sich auf die Analyse von Quellcode spezialisiert haben, z. B. für das Review von Quellcode bzw. Pull Requests.
Amazon CodeGuru
Ein von Amazon angebotenes Analyse-Werkzeug ist Amazon CodeGuru. Dieses Werkzeug versteht sich als Scanner, um Sicherheitslücken und Schwachstellen im Code zu finden. Daneben werden auch Vorschläge erstellt wie Anwendungen optimiert bzw. beschleunigt werden können.
Gedacht ist dieses Werkzeug nicht für die direkte Nutzung, sondern eher für die Integration in entsprechende Pipelines.
Neben der Nutzung in AWS CodeCommit (das demnächst eingestellt wird) wird auch die Nutzung von BitBucket- und GitHub-Repositories unterstützt.
Sourcery AI
Sourcery AI versteht sich als Werkzeug für automatisches Reviewing. Verknüpft werden kann dieses Werkzeug unter anderem mit GitHub oder GitLab. Wenn gewünscht, wird so bei jedem Pull-Request ein entsprechender Kommentar hinterlassen.
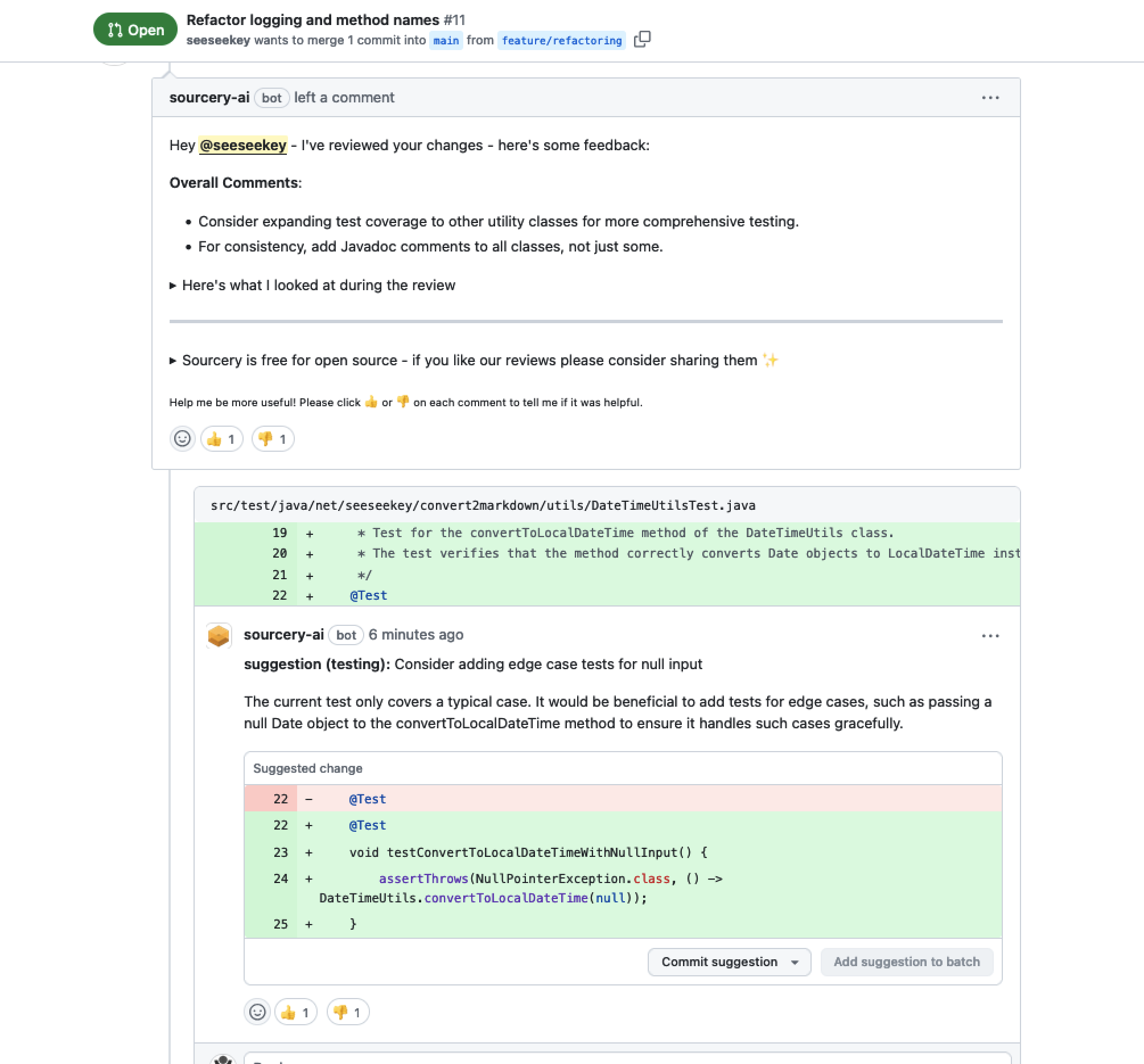
Sourcery AI erstellt Kommentare zu einem Pull Request
Während die Nutzung für kommerzielle Projekte mit einem Abonnement verbunden ist, können Open-Source-Projekte Sourcery AI ohne weitere Kosten einsetzen.
Neben der Kommentierung des Pull-Requests werden auch Hinweise für den Reviewer und eine Zusammenfassung erstellt.
Snyk
Neben Werkzeugen, die sich auf normale Entwicklungsarbeiten konzentrierten, existiert mit Snyk ein Analyse-Werkzeug, welches Verwundbarkeiten und Sicherheitsprobleme im Code aufdecken soll.
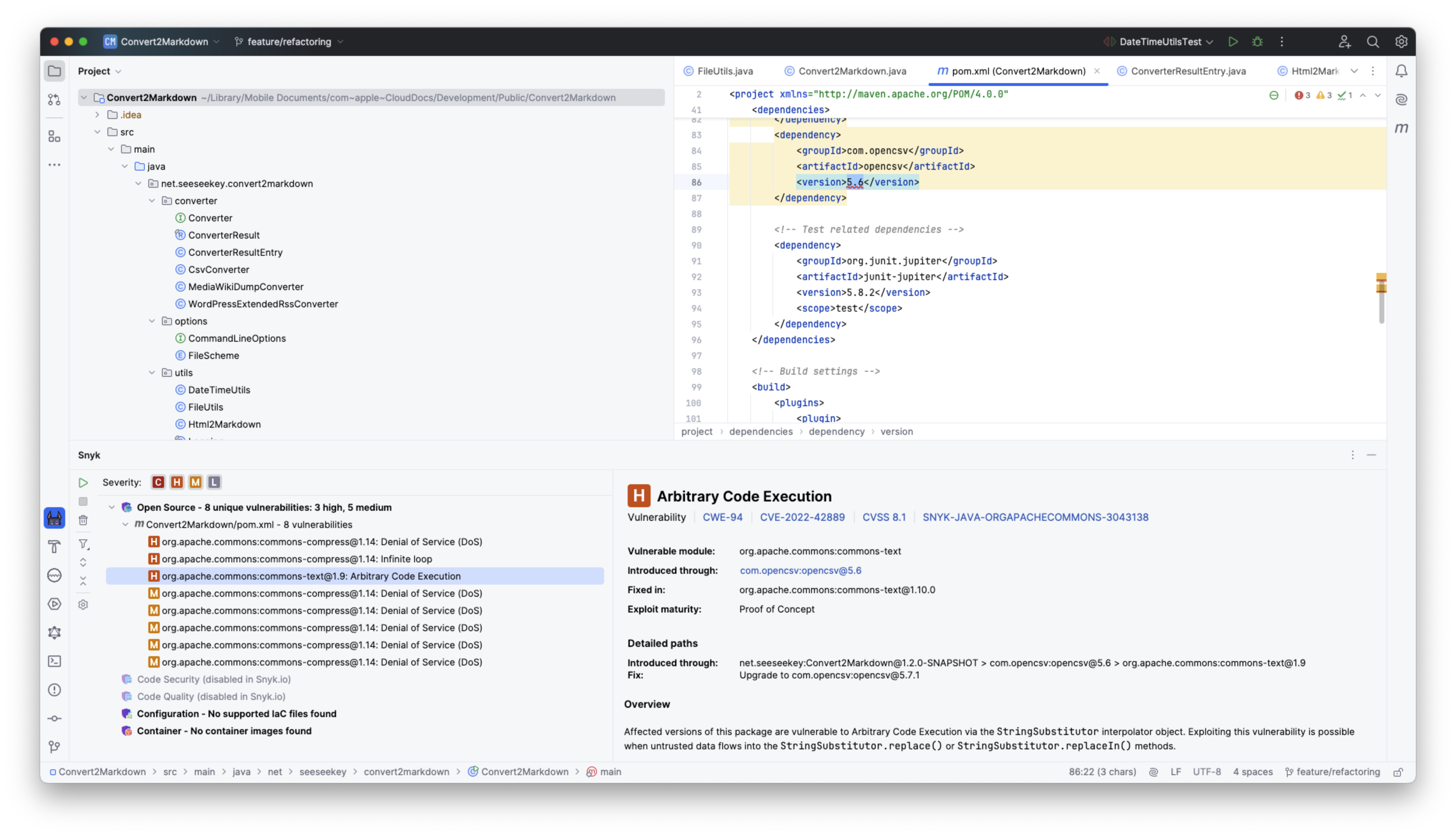
Snyk in einer JetBrains IDE
Snyk positioniert sich als Werkzeug, das durch den Einsatz von maschinellem Lernen sowie dynamischen und statischen Analysen den Quellcode auf diese Problemklasse hin untersucht.
Dabei werden eine Reihe von Produkten angeboten, welche diese Technologie zur Anwendung bringen soll.
WhatTheDiff
Ähnlich wie Sourcery AI ist auch WhatTheDiff ein Werkzeug für automatisierte Code-Reviews.
Im Gegensatz zu Sourcery AI muss die GitHub-Integration vor der Nutzung konfiguriert und aktiviert werden.
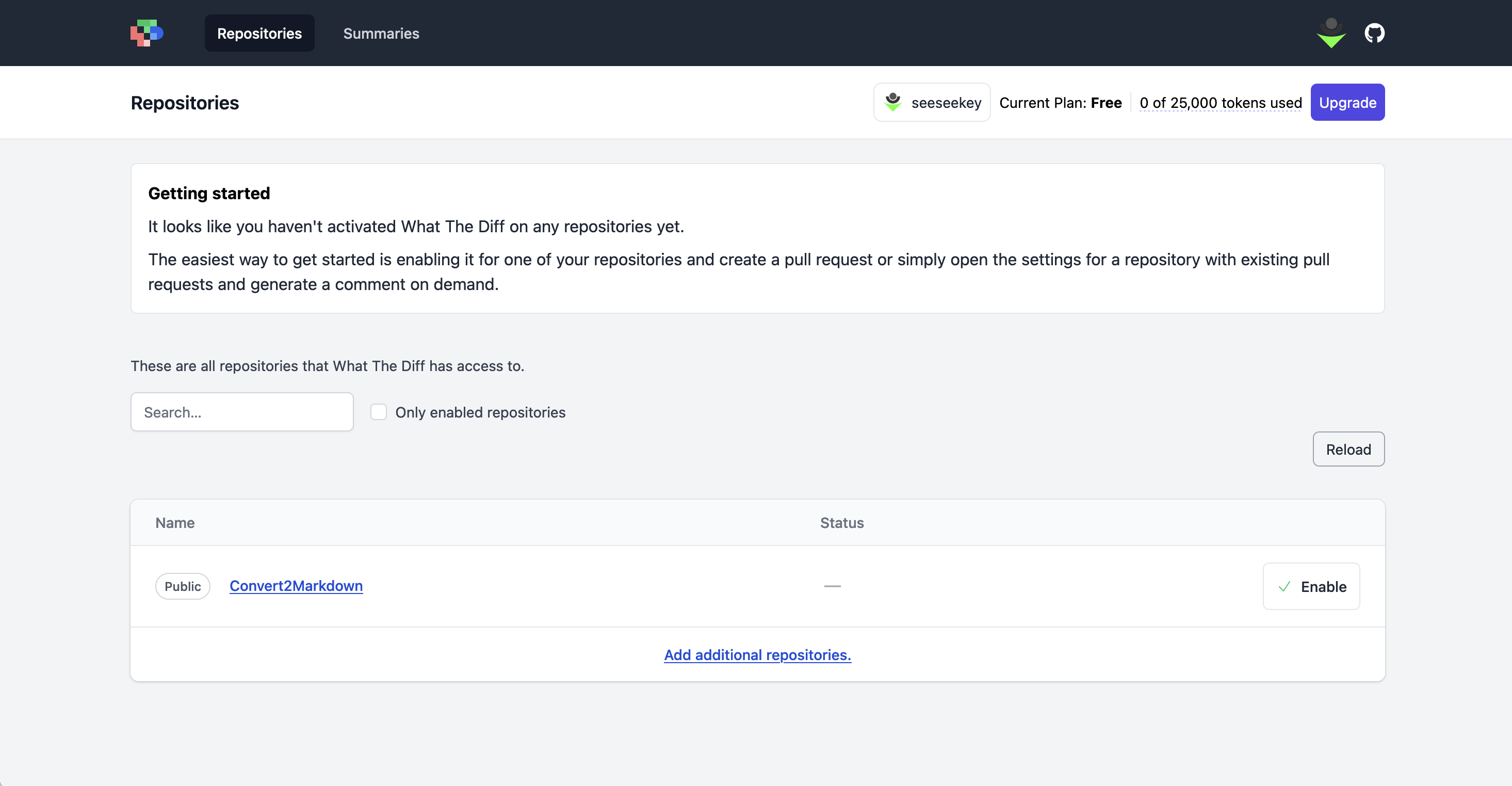
Die Repositories müssen aktiviert werden
Nach der Aktivierung werden für Pull Requests automatisch Kommentare erzeugt.
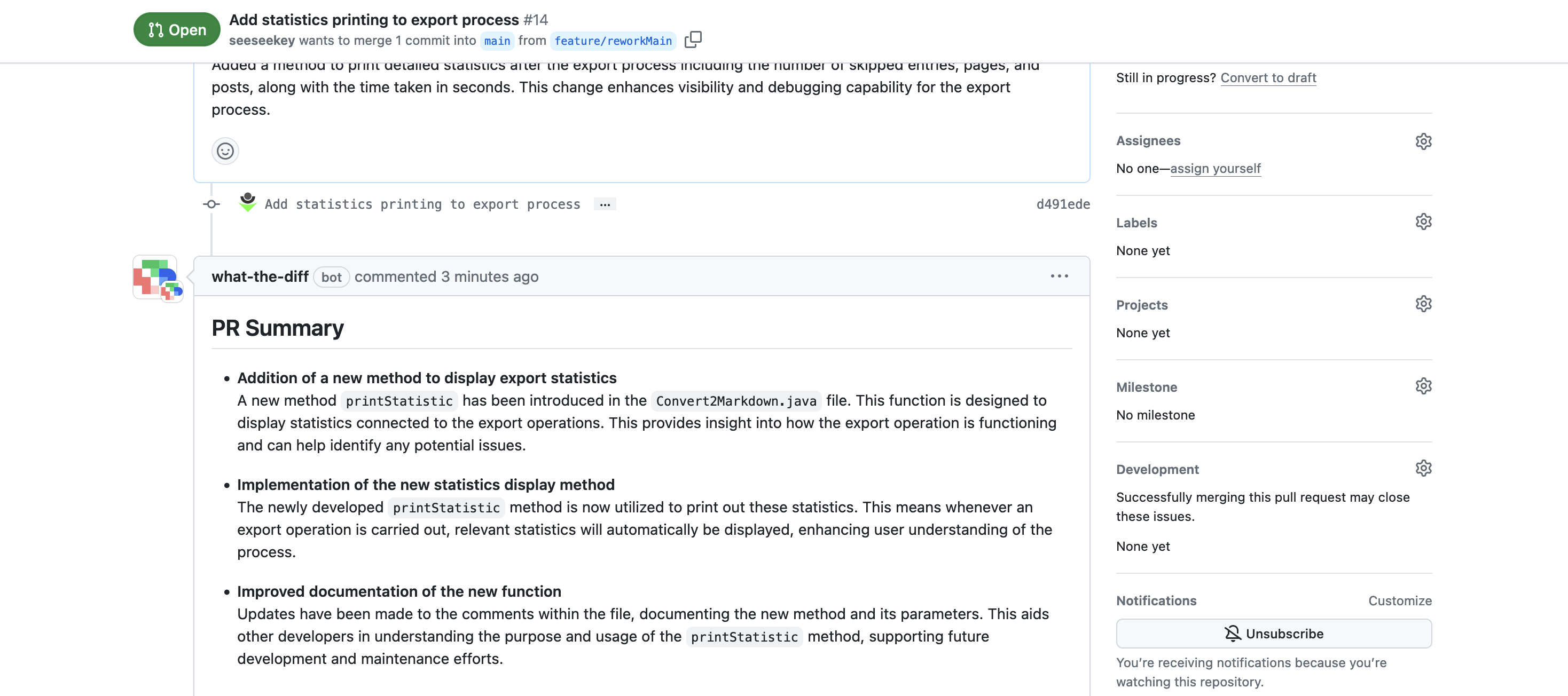
What The Diff erzeugt automatisch Kommentare zu den Pull Requests
Wie bei Sourcery AI werden hier auch Kommentare zur Zusammenfassung und Review-Kommentare am Pull Request erstellt, welche dann bearbeitet werden können.
Weitere Werkzeuge
Neben den größeren Klassen wie Code-Assistenten und Analysewerkzeuge, existieren weitere Werkzeuge, welche KI-basiert einen Mehrwert in der Entwicklung bringen können.
bloop.ai
Unter bloop.ai werden verschiedene Services rund um KI-gestützte Codegenerierung und Nutzung angeboten.
So wird ein Dienst angeboten, welcher COBOL-Programme in lesbare Java-Applikationen umwandeln soll. Ein weiterer Dienst befasst sich mit einem Sprachmodell, welches direkt COBOL-Quellcode schreiben kann.
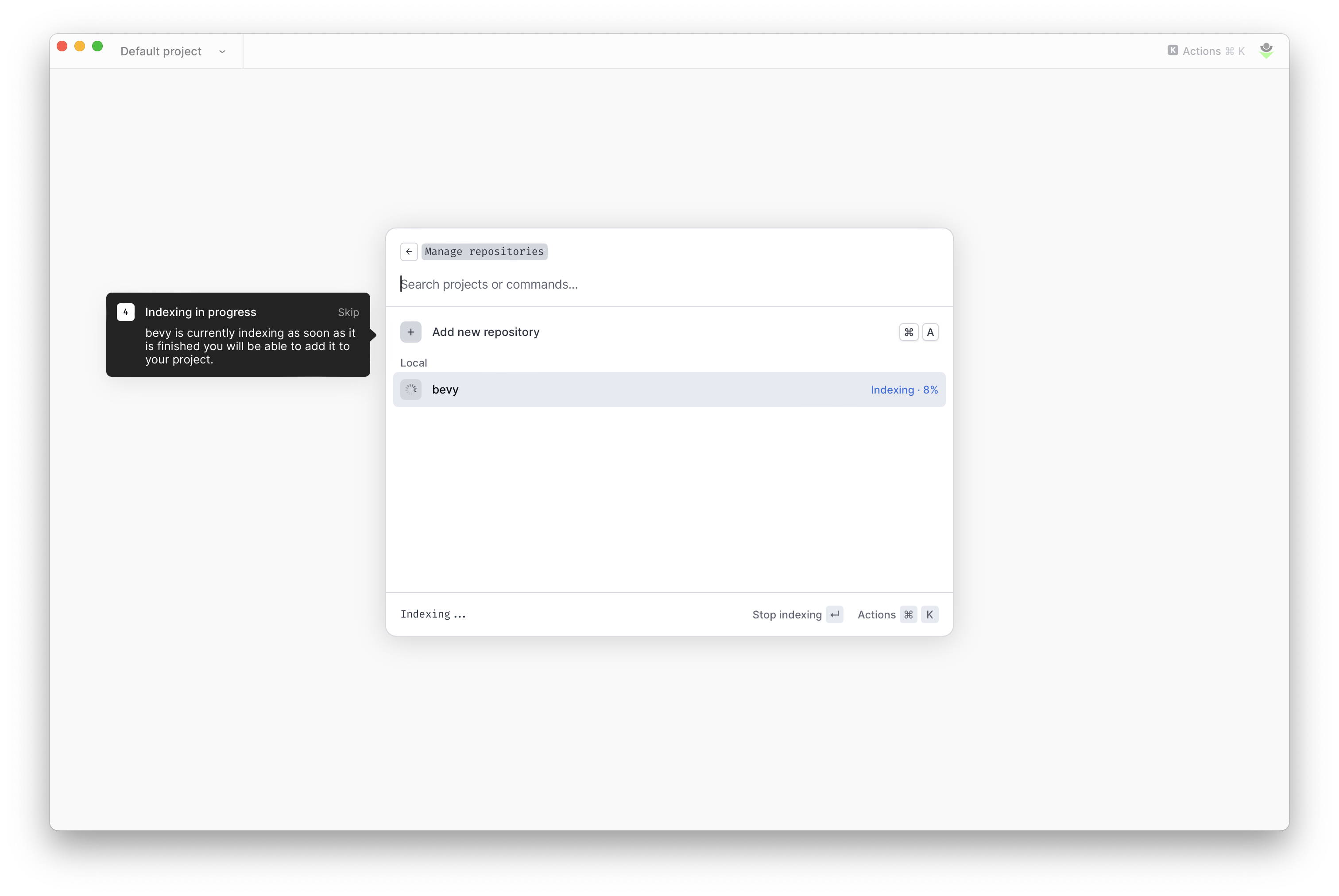
bloop indiziert ein Repository
Für den alltäglichen Gebrauch interessanter war die Understand-Funktionalität, die es ermöglicht, Repositories zu laden und anhand dieser Repositories Fragen zum Quellcode zu stellen.
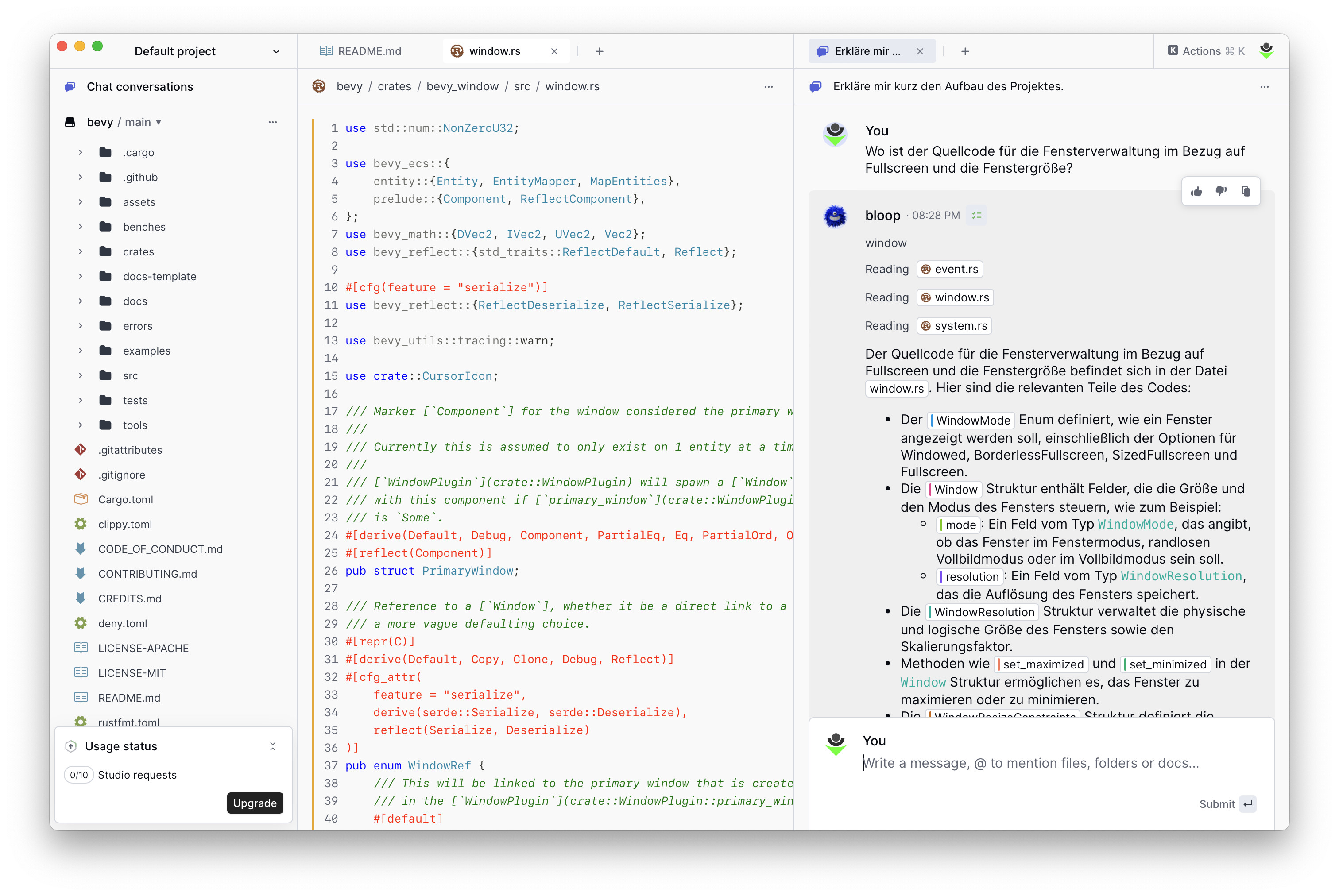
Bloop wird zum Bevy-Projekt befragt
Diese existierte in einer freien Variante sowie in einer kostenpflichtigen Personal-Variante. In der kostenpflichtigen Variante wurde unter anderem die Indizierung mehrerer Branches ermöglicht.
Nach der kürzlich erfolgten Einstellung steht nur noch die freie Variante dieser Funktionalität zur Verfügung. Für den alltäglichen Gebrauch, vorwiegend mit unbekannteren Codebasen, kann dieses Werkzeug eine wertvolle Ergänzung sein.
GitFluence
Wer in der Softwareentwicklung arbeitet, wird oft auch mit Versionskontrollsystemen wie Git arbeiten. Auch hier existieren mittlerweile KI-Tools, welche unterstützen sollen.

GitFluence
Eines dieser Werkzeuge ist GitFluence, das unter der Haube mit der OpenAI-API arbeitet. Gedacht ist das Werkzeug für den Fall, dass eine Git-Aktion beschrieben wird und automatisch ein Git-Kommando dafür erstellt wird.
Dies wirkt allerdings in einigen Fällen eher unausgegoren und lieferte unbrauchbare Ergebnisse, während es sporadisch sinnvolle Antworten liefert.
Grit.io
Der Dienst Grit.io spezialisiert sich auf Code-Migration und automatische Dependency Upgrades. Aktuell ist er nur über eine Warteliste verfügbar, sodass hier eine genauere Beurteilung schwerfällt.
Eines der Beispiele von der Grit.io-Seite
Durch die automatische Aktualisierung von Abhängigkeiten und die Durchführung größerer Migrationen soll eine allgemeine Verbesserung der Codequalität stattfinden.
Mutable AI
Neben Code-Assistenten, die sich auf die Entwicklung spezialisieren, existieren auch solche Assistenten, die sich der Dokumentation und Schaffung einer Wissensbasis zur entwickelten Software verschrieben haben. Zu diesen Diensten gehört Mutable AI.
Eine Mutable AI-Wiki
Nach Abschluss eines Abonnements ist es möglich zu einem Repository ein automatisches Wiki zur Dokumentation zu erstellen. Neben dieser Art der Dokumentation kann die Codebasis auch über einen KI-Assistenten befragt werden.
Die Dokumentation wird automatisch bei Änderungen des Repositories aktualisiert.
SQLAI.ai
Für die Arbeit mit SQL und Datenbanken existieren eine Reihe von KI-Werkzeugen wie SQLAI.ai. Mithilfe dieser Werkzeuge können Abfragen erzeugt, überprüft und auf Fehler untersucht werden.
SQLAI
Im Wesentlichen generieren die meisten dieser Werkzeuge, häufig unter Einbeziehung zusätzlicher Informationen wie des Datenbankschemas, passende Eingaben für das verwendete Sprachmodell. Zusätzliche Metainformationen wie das Datenbankschema, helfen hierbei sinnvolle Ausgaben für die eigenen Projekte zu erzeugen.
Ein ähnliches Werkzeug ist AI Query, das ebenfalls über Werkzeuge zur SQL-Prüfung und Bearbeitung verfügt. Daneben existieren eine Vielzahl anderer Werkzeuge dieser Art wie TEXT2SQL oder AI2sql.
Über den Tellerrand
Neben all diesen Werkzeugen existieren weitere Ansätze und Möglichkeiten, welche die Entwicklung und Prozesse der Softwareentwicklung vereinfachen sollen.
So existiert mit Stepsize AI ein Werkzeug, welches Sprint Reports im Kontext der agieren Softwareentwicklung erzeugen soll oder mit Bugasura ein Bug-Tracker mit KI-Unterstützung.
Neben kommerziellen Lösungen, welche auf entsprechende Modelle von OpenAI und Co. setzen, existieren auch freie Modelle zur Entwicklung von Software.
Eines dieser Modelle ist PolyCoder, welches auf Basis von GPT-2, mit einem Korpus von über zwölf Programmiersprachen trainiert wurde. Ähnliches vermag CodeGeeX zu leisten, welches aus dem asiatischen Raum stammt.
Allerdings lassen sich diese Systeme nicht so einfach nutzen wie die vorkonfektionierten Angebote, kommerzieller Anbieter. Es muss ein entsprechender Setup-Aufwand geleistet werden, bevor die Modelle genutzt werden können. Darüber hinaus ist die Performanz lokal ausgeführter Modelle, aufgrund der genutzten Hardware, oft unzureichend.
Fazit
Sprachmodelle konnten für die Entwicklung bereits genutzt werden, bevor es spezielle Integrationen dafür gab. Dafür musste der Entwickler Prompts definieren und diese mit dem Quelltext in das Modell geben.
Viele Integrationen nehmen dem Entwickler das Schreiben des Prompts in vielen Fällen ab und ermöglichen so eine schnellere Nutzung der Modelle. Bedingt durch die zugrundeliegenden Sprachmodelle werden viele Programmiersprachen auch von den vorgestellten Werkzeugen unterstützt.
Damit können in der Theorie viele Standardaufgaben, wie die Dokumentation, Unit-Tests oder auch komplexere Dinge wie die Konvertierung zwischen zwei Programmiersprachen mehr oder weniger vereinfacht werden. Allerdings sollten die Ergebnisse dieser KI-basierten Assistenzfunktionen immer bewertet und analysiert werden und nicht einfach ungeprüft übernommen werden. Spätestens bei komplexeren Problemen, welche ein umfassenderes Verständnis über die Codebasis benötigen, versagen die KI-Assistenten in vielen Fällen.
Aktuell existieren auf dem Markt eine unzählige Anzahl von KI-Werkzeugen und jeden Tag werden es mehr. Einige dieser Werkzeuge werden wieder verschwinden, während andere Werkzeuge erhalten bleiben. Auch in Zukunft sollen KI-Assistenten weiter integriert werden, wie in XCode von Apple.
Für Code-Assistenten sowie zahlreiche andere Werkzeuge gilt, dass sie im Wesentlichen auf ähnliche Weise funktionieren: Ein beliebiger Prompt wird erstellt, an ein Sprachmodell übermittelt und von diesem verarbeitet.
Hier stechen am Ende nur Lösungen hervor, welche eine gute Integration bieten und es somit dem Entwickler nicht unnötig schwer machen, die Assistenzfunktionen im Arbeitsalltag anzuwenden.
Positiv haben neben der Integration der JetBrains AI die Codesuche über Bloop überrascht, bei welcher zu einer Codebasis Fragen gestellt werden können und diese Codebasis damit genauer und schneller kennengelernt werden kann.
Neben den praktischen Aspekten sollte auch beachtetet werden, dass ein Großteil der aktuellen KI-Lösungen kostenpflichtig sind und ihren Gegenwert einspielen müssen.
Abgesehen von den monetären Aspekten gilt es auch den Datenschutz zu beachten, schließlich werden in vielen Fällen vertrauliche Daten an Drittservices gesendet und dort verarbeitet.
Daneben ist die Datenbasis prinzipbedingt immer leicht veraltet. So können Informationen zu neuen Versionen einer Software z. B. zur Game Engine Bevy über viele Sprachmodelle nicht bezogen werden, da ihr Trainingsdatum vor dem Erscheinungsdatum der neuen Softwareversion liegt.
Ob sich die Technologie in Zukunft einen wirklichen Mehrwert in der Entwicklung bringt, wird sich zeigen. Gegenwärtig scheint es so, dass sich ein Teil der KI-Werkzeuge sich dem Plateau der Produktivität im Hype-Zyklus nähert.
Bei einer guten und niederschwelligen Integration kann damit vielleicht das ein oder andere KI-basierte Werkzeug seinen Weg in den Werkzeugkasten der Softwareentwicklung finden.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.