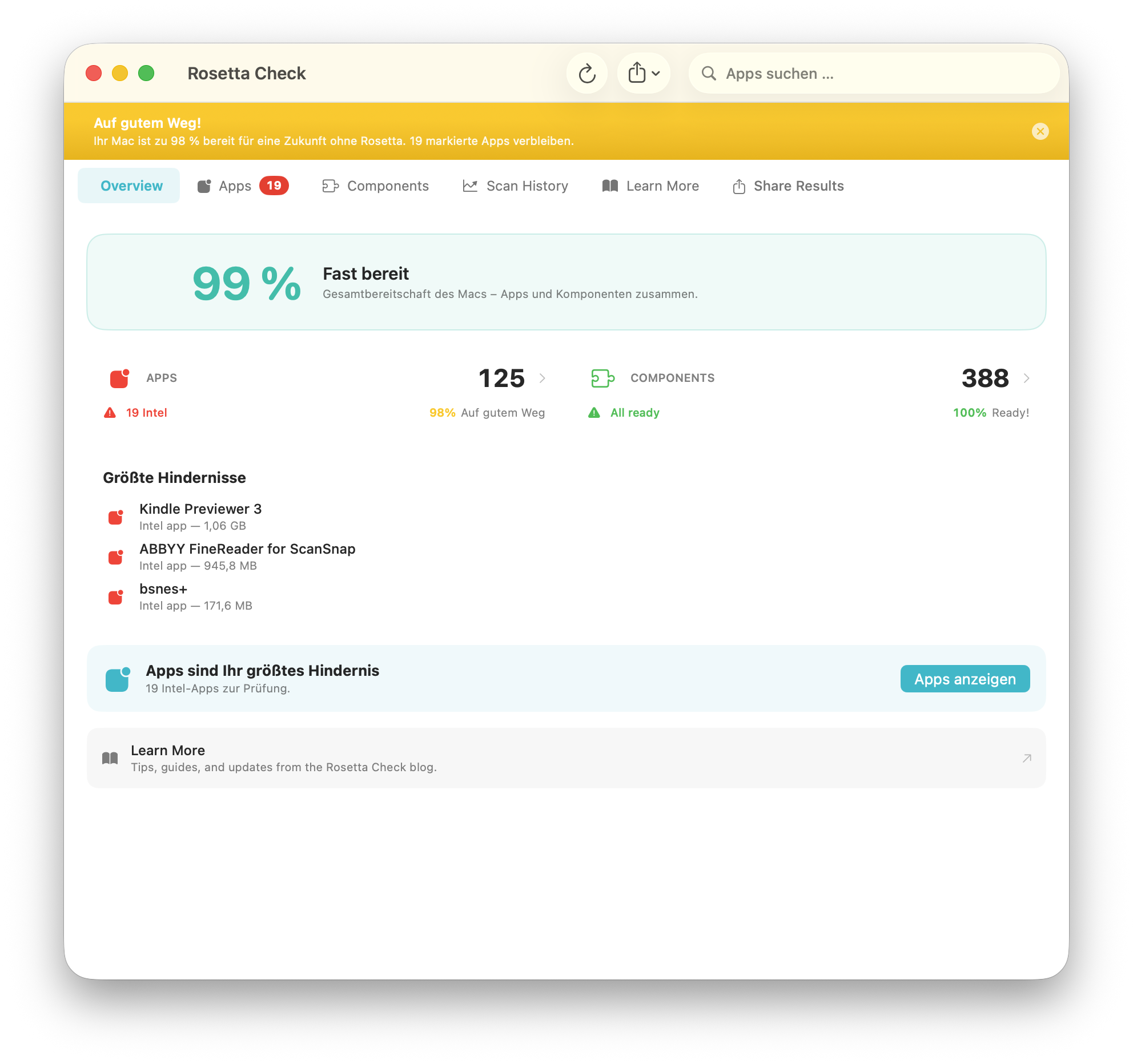
Mit dem bevorstehenden Ende von Rosetta 2 wird für viele macOS-Nutzer sichtbar, welche Anwendungen noch immer auf Intel-Code basieren. Wird eine solche Anwendung gestartet, erscheint eine Warnmeldung. Um sich ein Überblick über alle Anwendungen zu erhalten, eignet sich die App RosettaCheck.
Rosetta Check in Aktion
RosettaCheck ist ein Werkzeug für macOS, das Anwendungen auf ihre Prozessorarchitektur untersucht und erkennt, ob sie weiterhin Rosetta 2 benötigen. Die Software durchsucht installierte Programme und identifiziert Intel-Anwendungen, die noch nicht als native Apple-Silicon-Version vorliegen.

Darüber hinaus werden von der Community gepflegte Informationen zu Alternativen und Migrationsmöglichkeiten bereitgestellt. RosettaCheck kann über den App Store bezogen werden.
