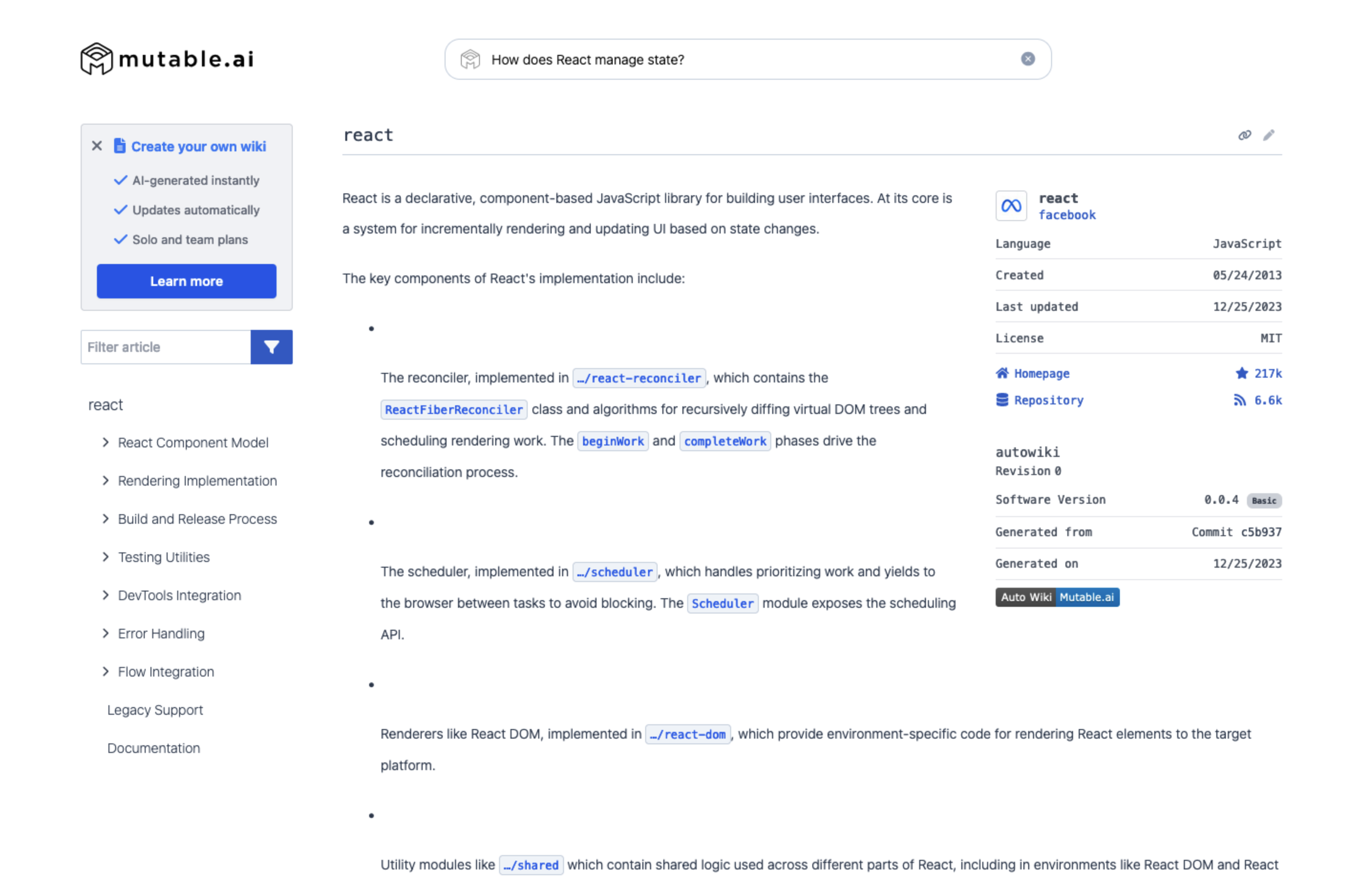
Wer sich mit sozialen Netzwerken wie Mastodon beschäftigt, wird den Begriff des Fediverse bereits gehört haben. Das Kofferwort, bestehend aus Federation und Universe, bezeichnet ein Netzwerk verschiedener sozialer Plattformen, die nicht von einem einzigen Anbieter betrieben werden, sondern auf vielen unabhängigen Servern laufen und mittels offener Protokolle miteinander verbunden sind.
Anders als in den klassischen Walled Gardens à la X, Facebook oder YouTube, wo jede Plattform ein geschlossenes System darstellt, können im Fediverse Nutzer plattformübergreifend miteinander interagieren. Oft genügt bereits ein einziger Account, um Inhalten über verschiedene Dienste hinweg zu folgen und zu kommentieren, z. B. um über Mastodon einem Pixelfed-Account zu folgen.
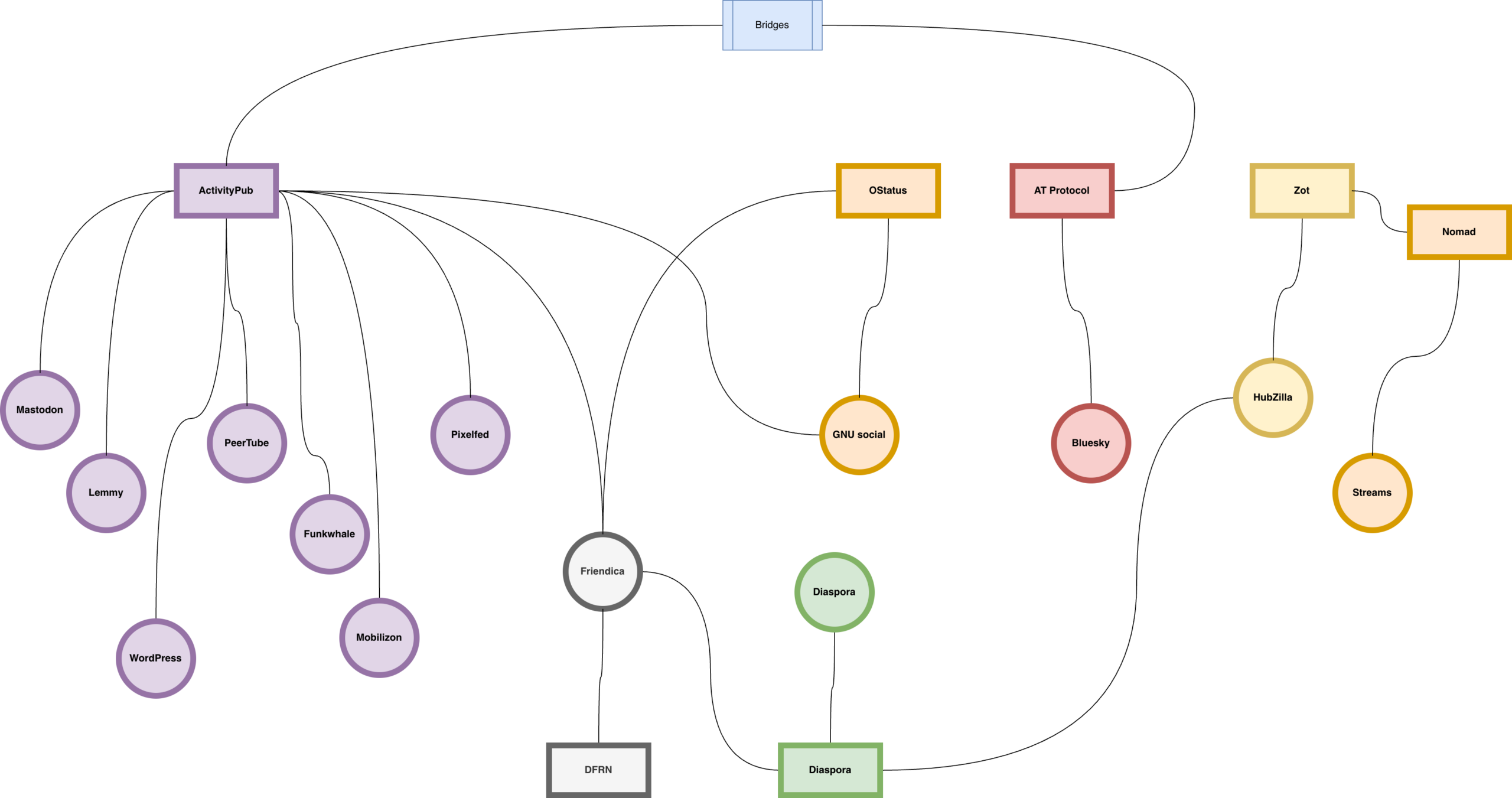
Ein Ausschnitt des Fediverse
Ein großer Vorteil der Föderation ist die Robustheit. Es gibt keinen Single Point of Failure. Fällt eine Instanz aus oder wird abgeschaltet, betrifft das nur dessen Nutzer, nicht aber das gesamte Netzwerk.
Spezial-Communitys können eigene Instanzen mit spezifischen Moderationsregeln oder Features betreiben, die auf ihre Bedürfnisse zugeschnitten sind. Nutzer haben die Wahl, sich einer Instanz anzuschließen, deren Ausrichtung und Richtlinien ihnen zusagen, oder selbst einen Server aufzusetzen.
Andererseits bedeutet die dezentrale Föderation auch, dass kein einzelner Akteur vollständige Kontrolle über Inhalte und Abläufe hat. Zentralisierte Netzwerke können schneller agieren, einheitliche Richtlinien durchsetzen und technisch einfacher skalieren, da alle Daten an einem Ort liegen.
Im Fediverse müssen sich die Betreiber der einzelnen Instanzen abstimmen, um z. B. Spam oder Missbrauch einzudämmen. Jede Instanz moderiert primär für sich. Auch sind föderierte Systeme komplexer. Der ständige Austausch zwischen Instanzen erfordert robuste Protokolle und kann die Infrastruktur bei hohen Aktivitätspeaks erheblich beanspruchen.
Im Rahmen des Artikels soll vorrangig auf den Teil des Fediverse eingegangen werden, der die ActivityPub-Spezifikation nutzt. Andere Mitglieder des Fediverse im weiteren Sinne, wie Bluesky als Nutzer des AT-Protokolls oder Diaspora mit dem gleichnamigen Protokoll, werden nur angerissen.
Geschichte
Der Grundgedanke von Dezentralität war schon früh im Internet verankert; das E-Mail-System ist bis heute ein anschauliches Beispiel für ein föderiertes Netzwerk. Jeder kann E-Mail-Server aufsetzen und in der Theorie ohne Probleme mit anderen E-Mail-Servern kommunizieren. Auch wenn es im E-Mail-System in den vergangenen Jahrzehnten zu enormen Zentralisierungen gekommen ist, ist es im Kern immer noch ein dezentrales System.
Mit dem Web der späten 90er und beginnenden 2000er Jahre entstanden persönliche Websites, Webringe, RSS/Atom-Feeds und frühe Blogging-Ökosysteme. Technisch dominierten zwar zentralisierte Plattformen wie Blogger.com, aber gleichzeitig gab es einen starken Drang zur Selbsthostbarkeit.
Besonders RSS und Atom können als gedankliche Vorläufer des Fediverse gelten, da sie schon früh das automatische Abonnieren von Inhalten über verschiedene Server hinweg ermöglichten.
OStatus
Sozial wurde Föderation im Web Ende 2008. Das damals von Evan Prodromou entwickelte Protokoll OpenMicroBlogging, ab 2010 OStatus genannt, kombinierte mehrere offene Standards, namentlich Atom, PubSubHubbub, Salmon und WebFinger, um Follower-Beziehungen, Status-Updates und Interaktionen serverübergreifend möglich zu machen.
Allerdings war OStatus technisch fragmentiert, schwer erweiterbar und bot keine echte Möglichkeit, komplexere Interaktionen standardisiert abzubilden.
Mit Identi.ca, welches 2008 gestartet wurde, und dem zugrunde liegenden Software-Stack StatusNet entstand das erste große föderierte Microblogging-Netzwerk. Später nutzten auch GNU social und Friendica Varianten des OStatus-Stacks.
Zeitgleich entwickelte sich mit Diaspora ab 2010 eine weitere föderierte Plattform, die auf einem eigenen Protokoll basierte, aber das Prinzip dezentraler, selbstverwalteter Instanzen ebenfalls konsequent umsetzte.
2013 wurde die Plattform Identi.ca auf pump.io migriert, woraufhin StatusNet faktisch eingestellt wurde. Auch wenn die pump.io-Plattform mittlerweile Geschichte ist, legte sie einige technische Grundlagen für das spätere ActivityPub.
Die im Juli 2014 gegründete W3C Federated Social Web Working Group entwickelte einen neuen Standard, welcher besagte Vorarbeit nutzte, um ActivityPub zu spezifizieren und zu standardisieren. Evan Prodromou fungierte hierbei als Mitautor. 2018 wurde ActivityPub schlussendlich als Webstandard verabschiedet.
ActivityPub erleichterte die Entwicklung dezentraler Plattformen erheblich. Mastodon, das anfangs noch OStatus unterstützte, setzte früh auf ActivityPub und wurde dadurch zum wichtigsten Motor des modernen Fediverse.
Wachstumsschmerzen
Neben der Vergrößerung des Fediverse durch neue Instanzen und Plattformen haben auch kommerzielle Anbieter das Fediverse für sich entdeckt.
So sorgte Meta für Schlagzeilen, als es mit Threads einen eigenen Microblogging-Dienst à la Twitter bzw. X startete und ankündigte, diesen mit ActivityPub kompatibel zu machen.
Die Reaktionen darauf waren im Fediverse gemischt. Einerseits sehen viele darin eine Stärkung der offenen Standards. Dennoch gibt es Bedenken, ob ein großer Player die Kultur des Fediverse verändert oder gar dominiert. Einige Mastodon-Instanzen kündigten prophylaktisch an, Threads gegebenenfalls zu blockieren, falls Meta versucht, zu viele Daten abzugreifen oder eigene Regeln zu diktieren.
Matt Mullenweg zeigte sich begeistert über das Fediverse und sieht darin eine Renaissance des offenen Webs. WordPress selbst kann nun per Plugin zu einem Fediverse-Teilnehmer gemacht werden, wenn auch mit Einschränkungen.
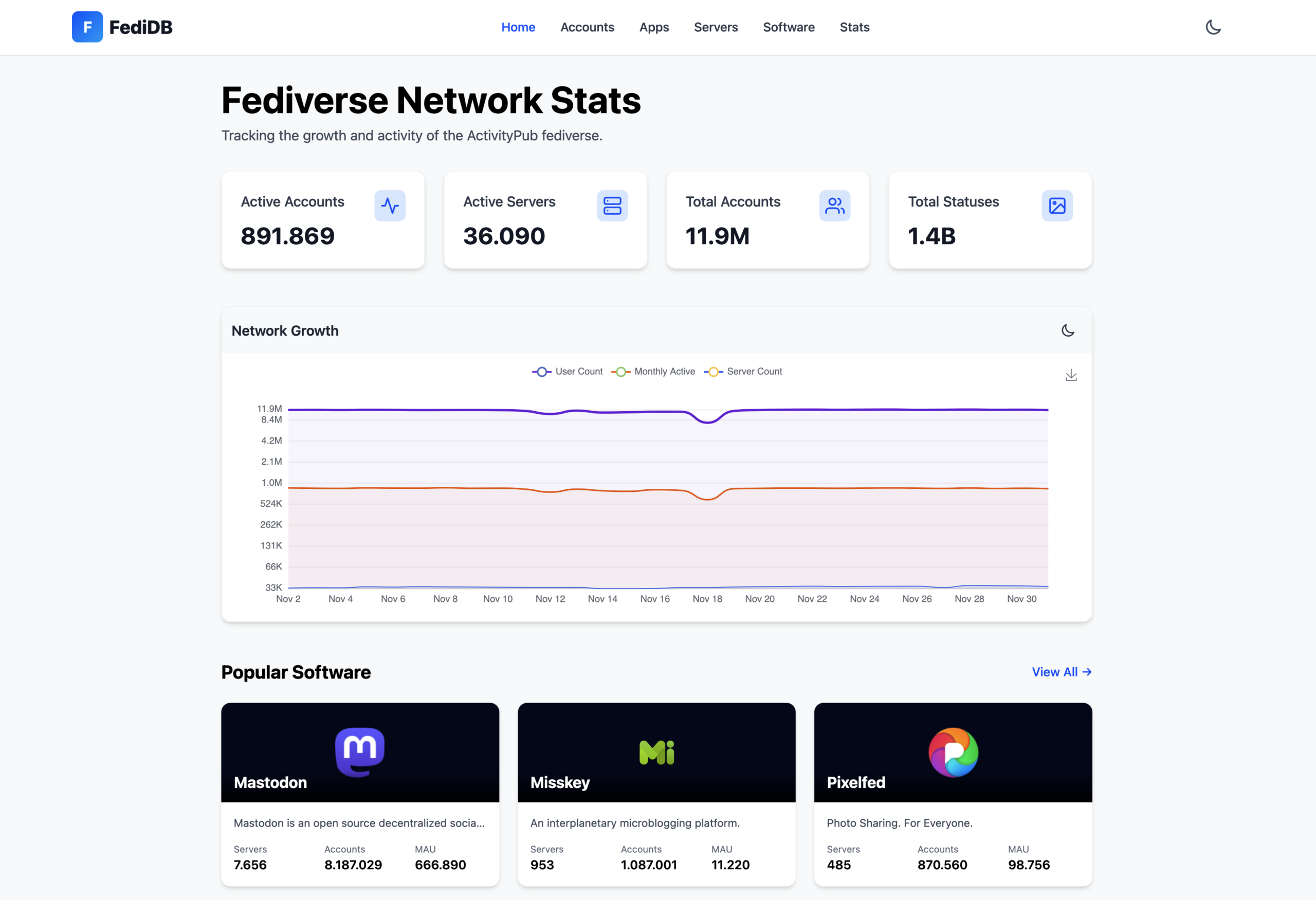
FediDB zeigt das Fediverse in Zahlen
Mittlerweile verfügt das Fediverse (laut FediDB, Stand Dezember 2025) über 12 Millionen registrierte Nutzer, davon sind etwa 890.000 Accounts aktiv, bei insgesamt 1,4 Milliarden Statusmeldungen und über 35.000 Instanzen bzw. Servern.
ActivityPub im Detail
Technisch betrachtet besteht die heutige Föderation aus zwei eng verzahnten Bausteinen. ActivityPub definiert die Mechanik der Kommunikation, also wie Clients Inhalte an einen Server senden und wie Server Aktivitäten an andere Instanzen verteilen.
Was dabei übertragen wird, legt ein zweiter Standard mit dem Namen ActivityStreams 2.0 fest. Dieses JSON-basierte Vokabular beschreibt die semantische Ebene, also welche Objekt- und Aktivitätstypen es gibt; von Note über Image bis zu Create, Like oder Follow.
Erst im Zusammenspiel beider Standards entsteht ein interoperables soziales Netzwerk. ActivityStreams liefert die Bedeutung, während ActivityPub den Transport, Zustellung und die Föderation übernimmt.
ActivityPub definiert zwei APIs. Zum einen eine Client-zu-Server-API (C2S), über die Nutzerinhalte auf dem eigenen Server erstellt, abgerufen oder gelöscht werden können. Zum anderen wird eine Server-zu-Server-API (S2S) definiert, über die föderierte Kommunikation zwischen verschiedenen Servern bzw. Instanzen erfolgt.
Während die C2S-API in der Theorie von den Clients, wie einer App oder einem Webinterface genutzt wird, wird die S2S-API für die Kommunikation zwischen den Servern genutzt.
Interessanterweise müssen nicht beide APIs implementiert werden. So implementiert z. B. Mastodon nur die S2S-API und nutzt stattdessen eine eigene Client-API.
Dies hängt damit zusammen, dass die Implementierung beider APIs optional ist und Mastodons eigene Client-API deutlich älter als ActivityPub ist. Dazu heißt es in der Spezifikation:
ActivityPub implementations can implement just one of these things or both of them.
Die Client-zu-Server-Seite von ActivityPub ist zwar spezifiziert, wird in der Praxis jedoch nur sehr begrenzt genutzt.
Die Energie floss bei den meisten Plattformen in das föderierte Server-zu-Server-Protokoll, dass die Dienste des Fediverse tatsächlich miteinander verbindet.
Actors
Nutzer in ActivityPub werden von einem sogenannten Actor repräsentiert und besitzen jeweils eine eindeutige Adresse, bestehend aus einem Nutzernamen und der Domain der Heim-Instanz.
Wichtig ist hierbei, dass zwischen dem Fediverse-Handle z. B. @ und der eigentlichen Adresse (https://fedi.example/users/alice) unterschieden wird. Das Handle wird hierbei mehrheitlich mittels Webfinger zur URL aufgelöst. Technisch betrachtet werden Handles nicht in der ActivityPub-Spezifikation behandelt, da dort nur Actor-URLs erwähnt werden.
Ein Nutzer kann im Kontext von ActivityPub z. B. eine Person, eine Applikation, eine Gruppe, ein Service oder eine Organisation sein. Dazu heißt es in der Spezifikation:
ActivityPub does not dictate a specific relationship between „users“ and Actors; many configurations are possible. There may be multiple human users or organizations controlling an Actor, or likewise one human or organization may control multiple Actors. Similarly, an Actor may represent a piece of software, like a bot, or an automated process. More detailed „user“ modelling, for example linking together of Actors which are controlled by the same entity, or allowing one Actor to be presented through multiple alternate profiles or aspects, are at the discretion of the implementation.
In- und Outboxen
Jeder Actor verfügt über eine In- und eine Outbox. Die Inbox enthält die Nachrichten, die von außerhalb empfangen wurden, während die Outbox die zu sendenden Nachrichten enthält.
Wenn ein Nutzer einen neuen Beitrag absendet, landet dieser zunächst in der Outbox. Der Server sendet diese zu den Inboxen der Follower-Server.
Umgekehrt kommen eingehende Nachrichten anderer Instanzen in der Inbox des Nutzers an.
Follow und Accept
Damit ein Actor allerdings überhaupt entsprechende Nachrichten erhält, muss er mindestens einem anderen Actor folgen. Dies geschieht, indem er eine Follow-Activity an einen anderen Actor sendet. Der Remote-Server antwortet mit einer Accept-Activity, wenn er den Follow erlaubt.
Erst wenn der Ablauf erfolgreich abgeschlossen ist, gilt auf Protokollebene eine lokale Follow-Beziehung als etabliert. Nur dann beginnt der Server des Actors, neue Aktivitäten aus seiner Outbox an die Inbox des Followers zu pushen.
ActivityPub im Beispiel
Doch wie sehen die Operationen auf Protokollebene aus? Für den Fall, dass ein Nutzer einem anderen Nutzer folgen möchte, sendet seine Instanz eine Follow-Activity an die Inbox des Remote-Actors. In diesem Fall möchte Bob dem Nutzer Alice folgen:
POST https://fedi.example/users/alice/inbox
Content-Type: application/activity+json
{
"@context": "https://www.w3.org/ns/activitystreams",
"id": "https://social.example/users/bob/activities/follow-123",
"type": "Follow",
"actor": "https://social.example/users/bob",
"object": "https://fedi.example/users/alice"
}
Was im Request nicht aufgeführt ist, aber faktisch zum Fediverse dazugehört, ist eine Signatur im Header:
Signature: keyId="https://social.example/users/bob#main-key",algorithm="rsa-sha256",headers="(request-target) host date digest",signature="..."
Unsignierte Requests werden von den meisten Plattformen grundsätzlich abgelehnt.
Mit der Follow-Activity ist allerdings noch keine Follow-Beziehung etabliert. Der Remote-Server entscheidet, ob die Anfrage genehmigt wird. Wenn ja, sendet er eine Accept-Activity zurück. Erst mit diesem Accept ist die Follow-Beziehung etabliert. In diesem Fall bestätigt Alice die Anfrage von Bob:
POST https://social.example/users/bob/inbox
Content-Type: application/activity+json
{
"@context": "https://www.w3.org/ns/activitystreams",
"id": "https://fedi.example/activities/accept-follow-123",
"type": "Accept",
"actor": "https://fedi.example/users/alice",
"object": {
"id": "https://social.example/users/bob/activities/follow-123",
"type": "Follow",
"actor": "https://social.example/users/bob",
"object": "https://fedi.example/users/alice"
}
}
Wenn der Nutzer nun einen Beitrag schreiben möchte, so erstellt er eine Create-Activity, die in die Outbox seiner Instanz gestellt wird. Von dort wird sie automatisch an die Follower verteilt. Im Beispiel setzt Alice einen Post ab:
POST https://fedi.example/users/alice/outbox
Content-Type: application/activity+json
{
"@context": "https://www.w3.org/ns/activitystreams",
"type": "Create",
"actor": "https://fedi.example/users/alice",
"object": {
"type": "Note",
"content": "Hello, world!",
"to": ["https://www.w3.org/ns/activitystreams#Public"]
}
}
Der Remote-Follower empfängt die Nachricht in seiner Inbox:
POST https://social.example/users/bob/inbox
Content-Type: application/activity+json
{
"@context": "https://www.w3.org/ns/activitystreams",
"id": "https://fedi.example/users/alice/activities/create-123",
"type": "Create",
"actor": "https://fedi.example/users/alice",
"object": {
"id": "https://fedi.example/users/alice/posts/123",
"type": "Note",
"content": "Hello, world!",
"to": ["https://www.w3.org/ns/activitystreams#Public"]
}
}
Daneben sind natürlich auch andere Interaktionen, wie Likes im Rahmen der Kommunikation, möglich.
Protokoll-Fragmentierung
Auf dem Papier wirkt ActivityPub wie der gemeinsame Nenner des Fediverse. Ein Datenmodell, ein Protokoll und damit die Aussicht auf echte Interoperabilität.
In der Praxis zeigt sich jedoch ein paradoxes Bild. Trotz des gleichen Protokolls sprechen viele Plattformen unterschiedliche Dialekte. Es entsteht kein kohärentes Gesamtnetzwerk, sondern mehrere nur locker miteinander gekoppelte Subsysteme.
Ein Kernproblem liegt in der Architektur des Standards selbst. ActivityPub basiert auf ActivityStreams 2.0, und dieses Format ist absichtlich sehr flexibel und erweiterbar gestaltet. Viele Felder sind optional, Semantiken bleiben offen und unbekannte Eigenschaften müssen laut Spezifikation ignoriert werden. Required-Attribute werden stattdessen nur sehr sparsam eingesetzt.
So können zwei Plattformen vollkommen korrekt behaupten, ActivityPub zu unterstützen, und dennoch kaum sinnvoll miteinander kommunizieren. Eine Plattform sendet Objekte mit Mastodon-Erweiterungen, eine andere erwartet strikteres JSON-LD, eine dritte ignoriert Felder, die für eine andere Plattform essenziell sind.
Besonders sichtbar wird das am Beispiel Mastodon. Die Plattform ist mit Abstand die größte ActivityPub-Implementierung und gleichzeitig eine, die den Standard nur teilweise umsetzt.
Die Client-to-Server-API fehlt weitgehend, mehrere Activity-Typen werden nicht unterstützt und bei der Account-Migration setzt Mastodon auf ein eigenes Verfahren. Umgekehrt verlangt Mastodon Dinge, die ActivityPub selbst nicht vorschreibt. Dazu gehören HTTP Signatures für alle Server-zu-Server-Anfragen, bestimmte JSON-LD-Kontexte und diverse Mastodon-spezifische Felder.
Mitglieder des Fediverse
Im Fediverse existieren zahlreiche Dienste mit unterschiedlichen Schwerpunkten. Viele davon sind bewusst als Alternative zu bekannten zentralen Plattformen konzipiert. Einige dieser Plattformen werden im Folgenden vorgestellt.
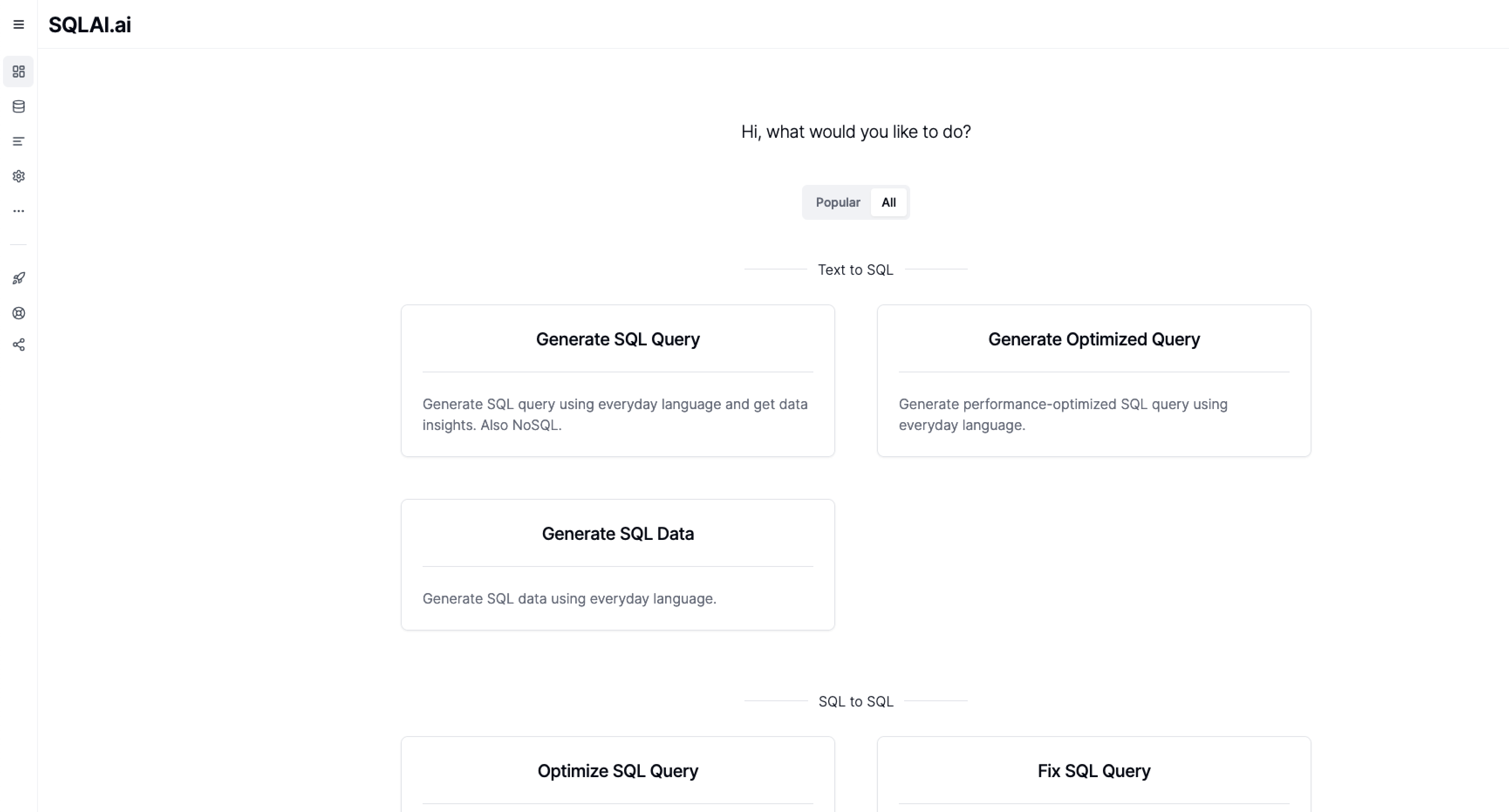
Mastodon
Mastodon ist die bekannteste und mit Abstand größte Plattform im Fediverse. Es handelt sich um einen freien Microblogging-Dienst, der Twitter bzw. X ähnelt. Nutzer können kurze Texte mit Bildern, Umfragen usw. veröffentlichen und anderen Nutzern folgen.
Mastodon wurde 2016 vom deutschen Entwickler Eugen Rochko gestartet und hat insbesondere nach der Übernahme von Twitter durch Elon Musk massiven Zulauf erhalten. So stieg die registrierte Nutzerzahl innerhalb weniger Wochen sprunghaft an.
Mastodon im Browser
Für den Nutzer bietet Mastodon drei Feed-Spalten: die Home-Timeline (Beiträge der Accounts, denen man folgt), eine lokale Timeline (alles, was auf der eigenen Instanz gepostet wird) und die föderierte Timeline, die öffentliche Posts aus allen verbundenen Instanzen zeigt.
Mastodon selbst ist quelloffene Software unter der AGPLv3 und wird mittlerweile von der Mastodon gGmbH weiterentwickelt, finanziert u. a. durch Spenden. Technisch basiert die Plattform auf Ruby on Rails und React.
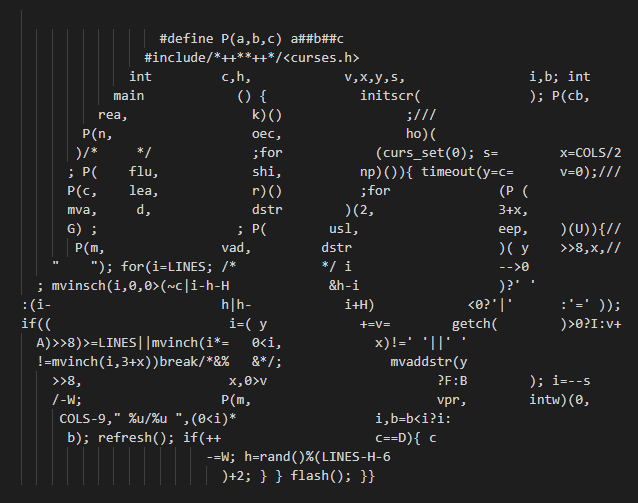
Lemmy
Für textbasierte Diskussionen, Linksharing und Community-Foren gibt es im Fediverse Lemmy. Dieses Projekt startete 2019 und ist ein freies, selbsthostbares Foren- und Link-Aggregator-System, das bewusst als Alternative zu Reddit entworfen wurde.
Eine Lemmy-Instanz
Inhalte werden in thematischen Unterforen, sogenannten Communitys, eingestellt. Andere Nutzer können Beiträge und Kommentare hoch- oder runterstimmen, und es gibt Diskussionsthreads.
Lemmy hat durch die Reddit-Turbulenzen einen Schub an Nutzern erfahren. Während es Anfang 2023 noch unter hundert Lemmy-Instanzen gab, wuchs die Zahl bis Juli 2023 auf über 1.500 an, mit rund 66.000 aktiven Nutzern pro Monat.
Manche großen Reddit-Communities haben Lemmy-Ableger gegründet, um eine zensurresistente, gemeinschaftskontrollierte Alternative in der Hinterhand zu haben. Trotz dieses Wachstums steht Lemmy noch am Anfang. Die in Rust geschriebene Software wird aktiv weiterentwickelt und ist unter der AGPL lizenziert.
Pixelfed
Pixelfed ist konzeptionell eine dezentrale Alternative zu Instagram. Die Plattform ging Ende 2018 an den Start und ermöglicht das Teilen von Fotos, Alben und Storys.
Pixelfed erinnert in seiner Oberfläche stark an Instagram. Es gibt einen Feed mit den Beiträgen der verfolgten Accounts, Bilder können gelikt, Hashtags genutzt, Fotos mit Ortsangaben versehen und Storys gepostet werden.
Pixelfed ist ebenfalls quelloffen und unter der AGPL lizenziert und wird vom Entwickler Daniel Supernault verantwortet. Technisch basiert es auf PHP und Laravel.
PeerTube
PeerTube ist das Fediverse-Pendant zu YouTube. Es wurde ab 2017 vom französischen Non-Profit-Verein Framasoft entwickelt, um eine Alternative zu zentralisierten Videoportalen wie YouTube, Vimeo oder Dailymotion zu bieten.
Die PeerTube-Instanz der Blender Foundation
Technisch setzt PeerTube auf ActivityPub und ergänzt es um Peer-to-Peer-Technologie, um die Belastung einzelner Server bei populären Videos zu reduzieren.
Es erfreut sich insbesondere in Europa zunehmender Beliebtheit bei öffentlichen Einrichtungen und der Open-Source-Community. Daneben nutzen einige Content Creator PeerTube als werbefreie, datenschutzfreundliche Ergänzung zu YouTube.
PeerTube hat auch institutionelle Adoption erreicht. Der Europäische Datenschutzbeauftragte betrieb das Portal EU Video auf PeerTube-Basis im Rahmen einer Pilotphase, nach deren Ende der Betrieb erst einmal nicht fortgesetzt wurde.
PeerTube ist freie Software und unter der AGPL lizenziert. Technisch setzt PeerTube auf TypeScript, mit einem Node.js-Backend und einem Angular-Frontend.
Mobilizon
Bei Mobilizon handelt es sich um eine Plattform für die Organisation von Veranstaltungen und Gruppen und stellt damit das Fediverse-Pendant zu Facebook Events oder Meetup.com dar.
Mobilizon wurde ebenfalls von Framasoft initiiert und im Oktober 2020 in Version 1.0 veröffentlicht. Die Idee dahinter war, zivilgesellschaftlichen Gruppen, Vereinen oder einfach Freundeskreisen ein Werkzeug zu geben, um Veranstaltungen zu erstellen, Teilnehmer einzuladen und sich zu koordinieren.
Die Software ist in der Programmiersprache Elixir geschrieben und nutzt als Frontend das JavaScript-Framework Vue.js. Es ist unter der AGPL lizenziert und damit freie Software.
Friendica
Friendica gehört zu den ältesten Föderations-Plattformen und besticht durch eine breite Protokollunterstützung im Fediverse. Gestartet bereits 2010 unter dem Namen Mistpark, war Friendica lange vor ActivityPub verfügbar und unterstützt bis heute mehrere Protokolle parallel.
Friendica kann als eine Art föderiertes soziales Netzwerk à la Facebook betrachtet werden. Es bietet klassische Social-Media-Funktionen, einen Nachrichtenstream, Freunde/Follow-System, Kommentare, Gruppen, Direktnachrichten und Fotoalben.
Friendica-Server können sich einerseits untereinander verbinden, andererseits aber auch Inhalte und Kontakte von externen Netzwerken einbinden. So lassen sich in einem Friendica-Account Kontakte von Diaspora, GNU social und seit einiger Zeit auch ActivityPub-Diensten wie Mastodon oder Pixelfed integrieren.
Friendica ist ebenfalls freie Software unter der AGPL und wird von einer Community entwickelt. Als selbst gehostete Lösung ist es relativ anspruchslos und kann auch auf kleinen Webservern betrieben werden.
Sonstige Dienste
Neben den bekannten Schwergewichten existiert im Fediverse eine ganze Reihe weiterer Dienste, die jeweils eigene Nischen adressieren.
So sieht sich Funkwhale etwa als föderiertes Pendant zu SoundCloud, Castopod als moderne Podcast-Hosting-Plattform, WriteFreely als Blogging-Plattform oder BookWyrm als soziale Heimat für Leser, vergleichbar mit Goodreads.
Fediverse in der Praxis
In der praktischen Nutzung des Fediverse stößt der Nutzer auf eine Reihe von Eigenheiten und Mechanismen, die sich von klassischen, zentralisierten Plattformen unterscheiden und daher besondere Aufmerksamkeit verdienen.
Instanzauswahl
Die Wahl einer Instanz wirkt auf den ersten Blick wie die Entscheidung für einen E-Mail-Provider. So sorgt die Föderation schließlich dafür, dass Dienste miteinander sprechen können. Doch in der Praxis hängt die Nutzung stark davon ab, wo man sich niederlässt.
Jede Instanz bringt ihre eigene Kultur, Moderationsregeln und technischen Rahmenbedingungen mit. Diese Unterschiede prägen den Alltag deutlicher als neue Nutzer es oft erwarten.
Besonders relevant ist der Fokus auf die Community. Ob Microblogging, Fotoplattform, Wissenschaft, Gaming oder Bücher. Praktisch für jeden sozialen Mikrokosmos existiert eine passende Instanz im Fediverse.
Die Instanzgröße verändert das Nutzungserlebnis spürbar. Kleine Knoten liefern Nähe und kurze Wege zur Moderation, mittlere Instanzen eine gute Balance, große Instanzen hohe Aktivität, aber auch mehr Rauschen.
Auch die technischen Parameter bestimmen die Alltagstauglichkeit. Von Uptime, Serverlast über Softwarestand und der Frage, welche externen Instanzen blockiert oder eingeschränkt werden. All das bestimmt, welche Inhalte sichtbar werden und welche außen vor bleiben.
Ein oft unterschätzter Punkt ist die finanzielle und organisatorische Nachhaltigkeit. Viele Instanzen werden ehrenamtlich betrieben; wenn Administratoren aussteigen oder Kosten steigen, kann ein Server verschwinden. Verschwindet die Instanz, auf der der eigene Account liegt, gehen sämtliche Daten verloren und sind nicht mehr abrufbar.
Hier sind in der Theorie Protokolle wie Zot bzw. Nomad im Vorteil, die nomadische Identitäten ermöglichen und nicht an eine einzelne Instanz gebunden sind.
Praktische Helfer, wie Fedi.Garden, Instances.social oder die Join-Fediverse-Guides z. B. joinfediverse.wiki erleichtern die Orientierung, ersetzen aber nicht den Blick auf Community, Governance und technische Basis einer Instanz.
Account-Migration
Je nach Plattform gestaltet sich die Account-Migration auf den Fediverse-Plattformen schwierig. So sind bestimmte Dinge semi-automatisiert, wie die Followerübertragung bei Mastodon, während Inhalte wie Posts nicht automatisch übertragen werden.
Die zentrale Limitierung bleibt die providergebundene Identität. ActivityPub verankert Identitäten in URIs, die den jeweiligen Server-Hostnamen enthalten. Damit sind Identitäten praktisch nicht portabel.
Bei einem Serverwechsel bleiben die historischen Post-URLs an die alte Instanz gebunden. Externe Links und Einbettungen verweisen weiterhin auf den alten Host und werden unbrauchbar, sobald dieser verschwindet. Modelle wie Bring-Your-Own-Domain oder W3C-DIDs könnten dieses Problem theoretisch lösen, existieren aber praktisch in keiner größeren Implementierung.
Fazit
Das Fediverse ist längst kein experimentelles Nischenprojekt mehr, sondern die bislang reifste Alternative zu zentralisierten Social-Media-Plattformen.
Die Stärken sind funktionierende Dezentralisierung, Community-Governance, Open-Source-Innovation und ein Rückzugsort jenseits kommerzieller Plattformlogiken.
Gleichzeitig bleiben die offenen Fragen erheblich. Finanzielle Nachhaltigkeit, Skalierbarkeit, moderationsfähige Strukturen bei Wachstum und echte Widerstandsfähigkeit gegenüber kommerzieller Vereinnahmung.
Aktuelle Forschung zeigt zudem nüchtern, dass die Idealvorstellung radikaler Dezentralität in der Praxis stark relativiert wird. Die Mehrheit der aktiven Nutzer konzentriert sich auf wenige große Instanzen, und mit Threads drängt erneut ein Player mit deutlicher Dominanz ins offene Ökosystem.
Auch klassische Lock-ins bestehen fort, etwa die fehlende Post-Migration oder eingeschränkte Interoperabilität zwischen Implementierungen.
Ob das Fediverse sich langfristig etabliert, hängt von einigen Faktoren ab: belastbare öffentliche Förderung, institutionelle Adoption durch Verwaltungen, Medien und Wissenschaft, Skalierung und Verschlüsselung sowie Governance-Modelle, die Koordination ermöglichen, ohne zentrale Kontrolle.
Ebenso zentral ist eine gesunde, einladende Community-Kultur, die bei weiterem Wachstum nicht verloren gehen darf.
Letztlich bleibt das Fediverse eine der spannendsten Entwicklungen des modernen Webs. Es erinnert an die frühen Ideale des Internets; offen, föderiert, interoperabel und zeigt, dass Alternativen zu den klassischen Monopolplattformen tatsächlich funktionieren können.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.