Im Laufe der letzten Jahre und Jahrzehnte sind einige Smart Home-Standards auf den Markt gekommen. Mit Matter ist nun ein neuer Standard angetreten, welcher den Smart Home-Markt aufrollen möchte.
Doch abseits der für den Endnutzer gedachten Versprechen, welche Vorteile er bringen soll, wird erstaunlich wenig über die technischen Hintergründe gesprochen.
Allerdings helfen diese Hintergründe Matter und seine Möglichkeiten zu verstehen. In diesem Artikel sollen die Hintergründe von Matter beleuchtet und gezeigt werden, wie Matter abseits der Marketingversprechen funktioniert.
Bestehende Standards
Matter ist beileibe nicht der erste Standard, welcher sich mit dem Thema Smart Home beschäftigt. Vor ihm gab und gibt es Standards wie Z-Wave, EnOcean und Zigbee. Letzterer spielt bei Matter organisatorisch eine besondere Rolle.
Je nach Standard werden unterschiedlichste Technologien und Funksysteme genutzt, wie das vermaschte Netzwerk, welches Z-Wave-Geräte untereinander aufbauen.
Das Problem an diesen Systemen ist, dass sie meist zueinander inkompatibel sind. Über Lösungen wie Home Assistant oder Homee können diese unterschiedlichen Systeme zur Zusammenarbeit gebracht werden.
Allerdings wird auch hier in vielen Fällen nur eine begrenzte Anzahl an Hardware unterstützt. Eine allumfassende Lösung stellt dies meist nicht dar.
Auch ins heimische Funknetz eingebundene Geräte werden gerne für die Smart Home-Anwendungen genutzt, welche auch durch ihren günstigen Preis bestechen können.
Aus Sicht von Entwickler sind unterschiedlichste Standards ein Problem. Je nach Firmengröße kann sich nur für einen Standard entschieden werden, da zusätzlich zu unterstützende Standards mehr Entwicklungsaufwand und damit am Ende mehr Kosten bedeuten.
Daneben sind die unterschiedlichen Standards zwar mehr oder weniger gleichwertig, allerdings gibt es eine gewisse Fragmentierung bei den Geräteklassen, so sind Leuchtmittel vorwiegend mit dem Zigbee-Standard verheiratet oder werden über teils obskure Wi-Fi-Lösungen angebunden.
Zwar existieren auch Beleuchtungslösungen für Z-Wave, allerdings sind diese in ihrer Auswahl beschränkt und der Preis ist in vielen Fällen höher als bei den Zigbee-Varianten.
Es gibt es Hersteller, welche mehrere Systeme unterstützen und die gleichen Produkte wie schaltbare Steckdosen in unterschiedlichen Varianten, je nach Smart Home-System, anbieten.
Für den Kunden bedeutet diese Auswahl und die damit verbundenen Probleme wie die Berücksichtigung der Kompatibilität, dass er meist zögerlich zu Smart Home-Produkten greift. Aus Sicht der Hersteller und der Kunden ist dies eine suboptimale Situation: voneinander abgeschirmte Ökosysteme und Geräte, die nur unter Umständen miteinander genutzt werden können.
Smart Home-Markt
Für das Jahr 2022 wird von einem Umsatz im Smart Home-Markt von über einhundert Milliarden Euro ausgegangen.
Allerdings bedingt durch die Fragmentierung des Marktes, entspricht dieser Umsatz nicht dem, der vor einigen Jahren erwartet wurde. So wurde unter anderem von einer höheren Durchdringung des Marktes ausgegangen.
Aktuell nutzen knapp 15 % aller Haushalte, weltweit gesehen, Smart Home-Technik in ihrem Haus oder ihrer Wohnung. Bedingt durch die Vorteile, welche Matter bieten soll und die damit einhergehende Vereinheitlichung, soll dem Smart Home-Markt neues Leben eingehaucht werden.
Das Matter-Versprechen
Matter will die bestehenden Probleme anderer Standards lösen. Der Standard sieht sich als Smart Home-Interoperabilitätsprotokoll und definiert sich als Anwendungsschicht, welche existierende Protokolle wie Thread und Wi-Fi nutzt, um seine Aufgabe, eine Smart Home-Umgebung darzustellen und zu verwalten, zu erfüllen.
Im Grundsatz geht es darum, dass der neue Standard unabhängig von den einzelnen Herstellern sein soll. Auch soll es jedem Hersteller von Hardware möglich sein, den neuen Standard zu implementieren.
Dem Endnutzer wird die Kompatibilität, aller Matter-Geräte untereinander, versprochen. Daneben soll in Zukunft auf proprietäre Bridges und Hubs, welche zur Anbindung bestimmter Systeme genutzt werden, verzichtet werden können.
Eine weitere wichtige Eigenschaft von Matter ist, dass die Steuerung zwar in der Theorie an Cloud-Systeme angebunden werden kann, aber immer lokal funktionieren muss.
Aus Sicht des Datenschutzes und der Betriebssicherheit ist dies eine erfreuliche Entwicklung, da Steuersignale nun nicht mehr die halbe Welt umrunden müssen, bevor sie wieder im eigenen Zuhause ankommen. Auch die Zuverlässigkeit stärkt dies in der Theorie, da auch beim Wegfall der Internetverbindung das eigene Smart Home noch funktioniert.
Für die Einrichtung von Matter-Geräten werden nicht mehr unbedingt die Third-Party-Apps der jeweiligen Hersteller benötigt, sondern diese können zentral über Apps z. B. der Home-App unter iOS hinzugefügt werden.
Connectivity Standards Alliance
Organisatorisch wird der Matter-Standard von der Connectivity Standards Alliance (CSA) betreut. Diese ging aus der Zigbee Alliance, welche 2002 gegründet wurde, hervor, welche sich für den gleichnamigen Zigbee-Standard verantwortlich zeichnet.
Mittlerweile sind über 500 Firmen unter dem Dach der Connectivity Standards Alliance vereint. Dazu gehören Unternehmen wie Amazon, Apple, Comcast, Google, IKEA, Infineon, LG, Nordic Semiconductor und Samsung.
Von der Idee zum Standard
Erste Lebenszeichen des Matter-Standards gab es im Dezember 2019. Damals kündigten unter anderem Amazon, Apple und Samsung sowie die Zigbee Aliance an, dass eine Zusammenarbeit für das Projekt Connected Home over IP beschlossen wurde.
Knapp anderthalb Jahre nach der ersten Ankündigung wurde aus Connected Home over IP schließlich Matter. Im gleichen Zuge wurde durch eine Umbenennung aus der Zigbee Alliance die Connectivity Standards Alliance.
Nach etwa drei Jahren Zeit der Planung und Entwicklung erschien im Oktober 2022 mit der Version 1.0 die erste Iteration des Standards. Hier wurden neben der eigentlichen Standardbeschreibung unterschiedliche Produktkategorien wie Beleuchtungslösungen, Sicherheitssensorik, Thermostate, Türschlösser und einige andere spezifiziert.
Während der Entwicklung gab es bedingt durch Faktoren wie die Coronapandemie und Verzögerungen bei den Gerätetests einige Verschiebungen, welche dann schlussendlich zum Veröffentlichungstermin im Oktober 2022 führten. Im November 2022 wurde Matter offiziell auf einem Launch-Event in Amsterdam vorgestellt.
In der nächsten Iteration des Standards, der Version 2.0, welche im März bzw. April 2024 erscheinen soll, sollen unter anderem die unterstützten Geräte um Klassen wie Staubsauger-Roboter, Rauchmelder, Kameras und einige andere erweitert werden.
Architektur
Aus architektonischer Sicht betrachtet ist Matter ein Applikationsprotokoll, welches auf bestehenden Technologien aufsetzt. Grundlage für das Matter-Protokoll bildet IPv6.
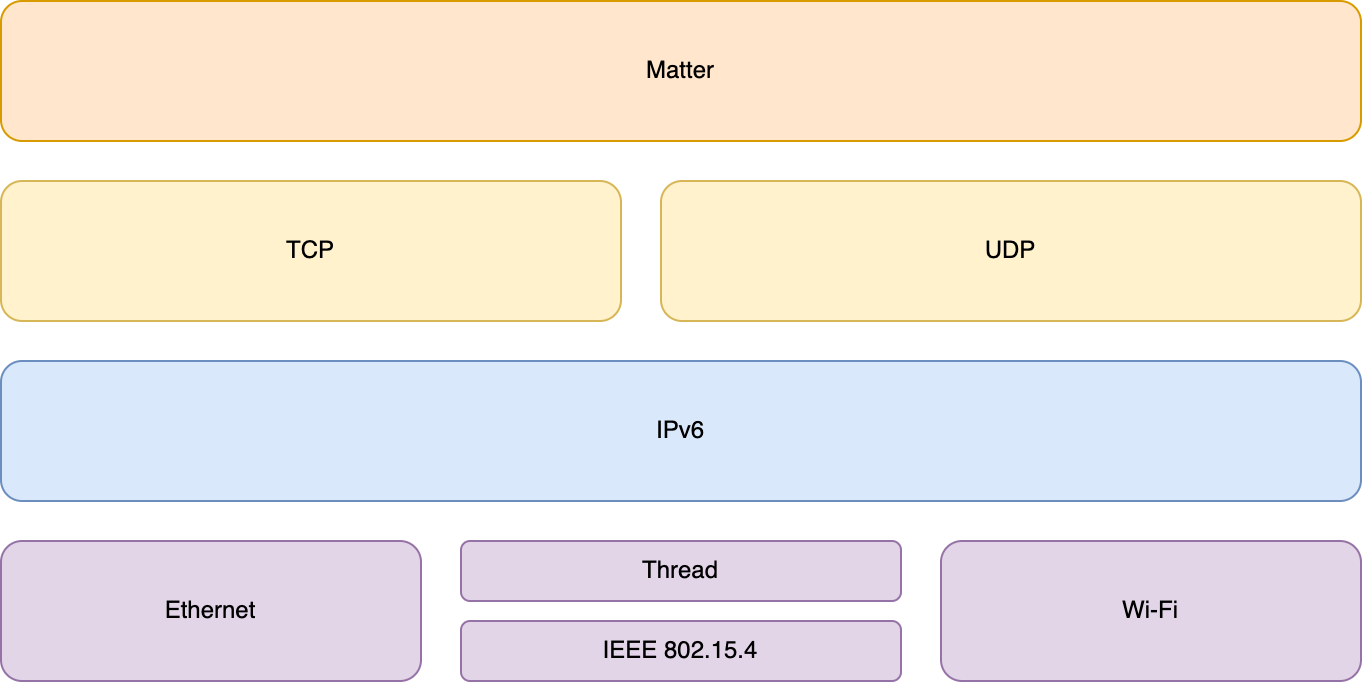
Matter setzt als Applikationsprotokoll auf vorhandenen Technologien auf
Der Matter-Protokollstack selbst besteht aus unterschiedlichsten Schichten, welche jeweils bestimmte fachliche Anforderungen erfüllen.
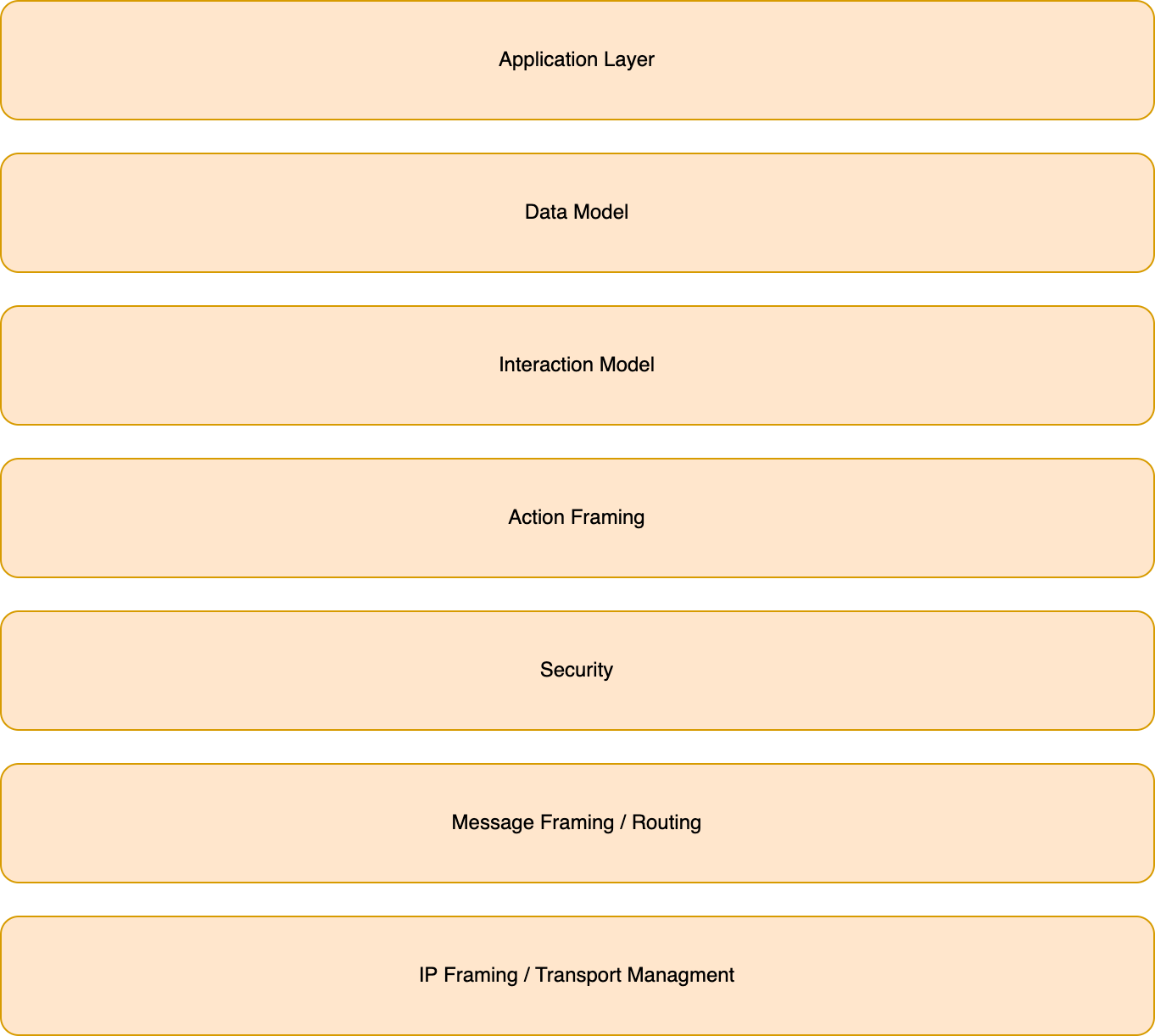
Die Schichten des Matter-Protokollstack
Die Anwendungsschicht (Application Layer) innerhalb des Matter-Protokollstacks implementiert die dem Gerät eigene Businesslogik. Im Falle einer schaltbaren Steckdose wäre dies die Logik, um das Gerät ein- und auszuschalten. Aktionen in der Anwendungsschicht führen zur Änderung im Datenmodell (Data Model).
Im Datenmodell werden die Daten für das entsprechende Gerät gehalten, z. B. ob das Gerät aktuell angeschaltet ist oder bei einem Leuchtmittel, die aktuell ausgewählte Leuchtfarbe.
Für die Interaktion von Außen werden im Interaction Model bestimmte Interaktionen definiert, welche von Außen geschrieben oder gelesen werden können. Eine solche Interaktion löst dann eine Logik in der Anwendungsschicht des Gerätes aus, um die entsprechenden Aktionen auszulösen.
Über das Interaction Modell kann eine Aktion definiert werden und über die Action Framing-Schicht wird sie schließlich in ein binäres Format serialisiert und dieses an die Security-Schicht übergeben.
In dieser wird die Nachricht verschlüsselt und ein Message Authentication Code angehangen. Damit soll sichergestellt werden, dass die Daten sicher und verschlüsselt zwischen den Instanzen bzw. Geräten übertragen werden.
Damit sind die Daten für die Nachricht serialisiert, verschlüsselt und kryptografisch signiert und werden an die Message Framing-Schicht übergeben, in welcher die endgültige Payload, welche schlussendlich über das Netzwerk verschickt wird, erzeugt wird. In Rahmen dieses Prozesses werden Headerfelder ergänzt, welche unter anderem Routing-Informationen enthalten können.
Anschließend wird das Ganze an die Transportschicht übergeben und findet so seinen Weg durch das Netzwerk, bis es beim definierten Empfänger ankommt. Dort angekommen wird der Matter-Protokollstack in umgekehrter Reihenfolge durchlaufen, bis schlussendlich wieder die eigentliche Nachricht in der Anwendungsschicht verarbeitet werden kann.
Fabric, Nodes und Controller
Im Matter-Standard werden einige Begriffe definiert, deren Wissen um die Bedeutung ein Verständnis des Standards erleichtert.
Ein zentraler Begriff im Matter-Standard ist die Fabric. Bei einer Fabric handelt es sich um einen logischen Verbund von Knoten (Nodes), welche eine gemeinsame Vertrauensbasis (Common Root of Trust) und einen gemeinsamen verteilten Konfigurationsstatus besitzen.
Ein Knoten (Node) ist im Matter-Standard definiert als eine Entität, welche den Matter Protokollstack unterstützt und nach der Kommissionierung über eine Operational Node ID und Node Operational Credentials verfügt.

Eine schaltbare Steckdose
Dabei ist ein Node nicht unbedingt gleichzusetzen mit einem Gerät. Ein Gerät, wie eine schaltbare Steckdose kann in der Theorie mehrere Knoten beinhalten, welche wiederum zu mehreren Fabrics gehören können.
Daneben gibt es im Matter-Standard den Begriff des Controllers. Dieser ist definiert als ein Matter-Knoten, welcher die Berechtigung hat einen oder mehrere Knoten zu kontrollieren. Dies kann z. B. das Smart Home-System sein oder ein iPhone mit der entsprechenden Home-App. Matter unterstützt per Design unterschiedlichste Controller in einem Matter-Netzwerk. Dieses Feature wird als Multi-Admin bezeichnet.
Kerntechnologien
Für Matter-Netzwerke, sind einige Kerntechnologien definiert, welche im Rahmen des Standards genutzt werden.
Für die Kommunikation der Geräte untereinander wird Wi-Fi, Ethernet oder Thread benutzt, für die Kommissionierung Bluetooth LE.
Bluetooth LE
Bluetooth LE wird im Matter-Standard genutzt, allerdings nicht für die Kommunikation der Geräte untereinander. Stattdessen wird Bluetooth LE für Kommissionierung (commission, im Matter-Standard) der Geräte genutzt.
Nach der Definition des Matter-Standards wird bei der Kommissionierung ein Node in die Fabric eingebracht, also das Gerät dem Matter-Netzwerk hinzugefügt.
Im Rahmen dessen werden die Zugangsdaten des Netzwerkes und andere für die Kommissionierung benötigten Informationen auf das Gerät übertragen.
Im Anwendungsfall würde dies so aussehen, dass der Nutzer einen QR-Code scannt, welcher die Informationen über das Gerät enthält und anschließend die Kommissionierung mittels Bluetooth LE durchgeführt wird.
Diese Informationen müssen nicht unbedingt als QR-Code geliefert werden. In der Theorie kann auch NFC als Technologie benutzt werden oder die enthaltenen Informationen einfach als kodierte Zeichenkette auf dem Gerät aufgedruckt sein oder dem Handbuch beiliegen.
Dies ermöglicht eine einfache Konfiguration und Einbindung der Geräte aus Sicht des Endbenutzers. Ist die Kommissionierung abgeschlossen und das Gerät damit in das Matter-Netzwerk eingebunden, nutzt das Gerät Bluetooth LE nicht mehr.
Anbindung der Smart Home-Geräte
In den meisten praxisnahen Fällen wird die Anbindung von Geräten meist auf die Anbindung per Thread und Wi-Fi hinauslaufen. Bei Wi-Fi im Heimbereich sind alle Geräte mehrheitlich mit einem Access Point verbunden. Bei Thread hingegen handelt es sich um ein vermaschtes Netz, welche über Border-Router mit dem Rest des Netzwerkes verbunden ist.
Thread
In einem Smart Home sind eine Reihe von Aktoren, wie schaltbare Steckdosen und Ähnliches verbaut. Daneben gibt es dann noch Sensorik, z. B. in Form von Temperatur- und Bewegungssensoren.
Sensoren, wie Temperatur oder Bewegungssensoren, laufen mehrheitlich mit Batteriestrom und eignen sich damit nicht für energieintensive Techniken wie Wi-Fi, um ihre Daten von A nach B zu transportieren.

Ein batteriebetriebener Sensor
Hier kommt das Protokoll Thread ins Spiel. Dieses ist darauf ausgelegt, Geräte miteinander zu verbinden, welche eine geringe Datenrate benötigen und möglichst wenig Energie verbrauchen sollen. Das Protokoll besticht durch sein simples Design und ermöglicht geringe Latenzen.
Das Netzwerkprotokoll Thread versteht sich als selbstheilendes Mesh-Netzwerk. Ein Designziel war es unter anderem, dass es keinen Single Point of Failure in einem solchen Netzwerk geben soll, die Übertragung zuverlässig und die Reichweite durch das Routing innerhalb des Thread-Netzwerkes gegeben ist.
Im Rahmen von Matter sollen hunderte bis tausende Produkte über Thread in einem Netzwerk unterstützt werden.
Entwickelt wird das Protokoll seit 2014 von der Thread Group welcher unter anderem ARM Limited, Nest Labs, Samsung und Qualcomm angehören. Die Entwicklung ist seit dem nicht stehen geblieben und so wurden mit Thread 1.3 Funktionalitäten wie vollumfängliches IP-Routing und Service-Discovery hinzugefügt. Diese Funktionalitäten werden für die Nutzung von Thread im Zusammenhang mit Matter benötigt.
Thread setzt auf IEEE 802.15.4 auf, bei welchem es sich um ein Standard für kabellose Netzwerke mit geringen Datenraten handelt. In IEEE 802.15.4 ist die Bitübertragungsschicht (Physical Layer) und die Data-Link-Schicht definiert.
Neben Thread setzt unter anderem auch Zigbee auf IEEE 802.15.4 auf, was ein Update solcher Geräte, hin zu Thread, perspektivisch möglich macht.
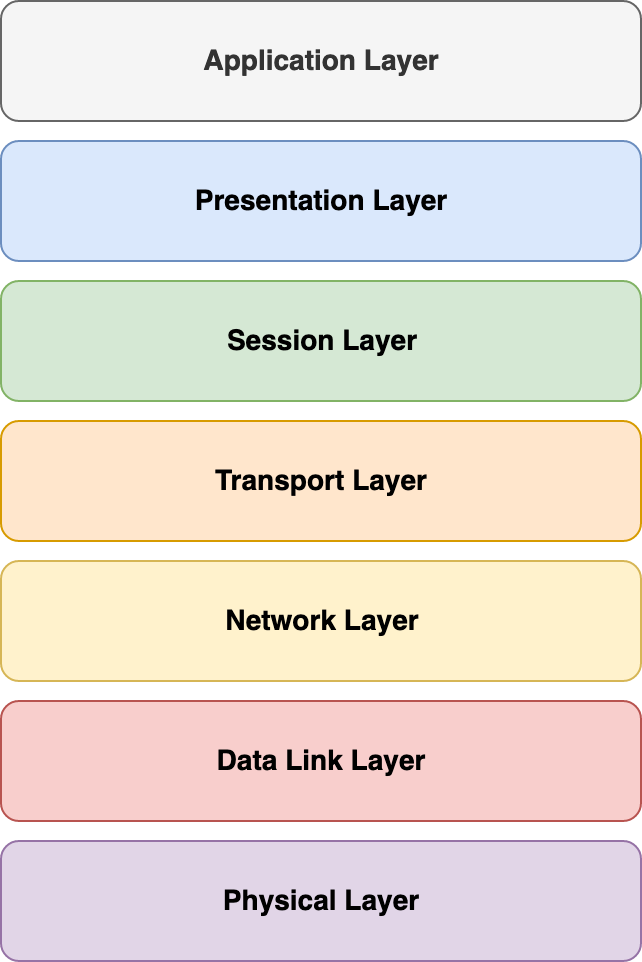
Das OSI-Modell
Darüberliegende Schichten, welche z. B. das Routing übernehmen können, müssen dann von anderen Protokollen übernommen werden. An dieser Stelle setzt Thread ein.
Per Thread angebundene Geräte können per IPv6 adressiert werden. Wichtig ist es festzuhalten, dass es sich bei Thread nicht um Matter handelt, sondern Thread ein eigenständiges Funkprotokoll ist, welches wie Wi-Fi der Anwendungsschicht agnostisch gegenübersteht.
Rollenspiele
Bei Thread kann jedes Gerät unterschiedliche Rollen annehmen. So gibt es in einem Thread-Netzwerk, einen Leader, einen oder mehrere Router und die Rolle des Endgerätes.
Jedem Gerät wird mindestens die Rolle des Endgeräts zugewiesen. Das sind solche Geräte, welche einen Befehl in Form eines Datenpaketes erhalten, um diesen auszuführen.
Ein Leader ist eine Rolle, welche nur einmal vergeben wird. Dieser koordiniert das Thread-Netzwerk. Fällt ein Leader aus, so wird automatisch ein neuer Leader bestimmt. Dazu ist es notwendig, dass jederzeit andere Geräte für den bestehenden Leader einspringen können. Die Zustandsinformationen müssen also im Netzwerk aktuell gehalten werden.
Router, leiten Datenpakete im Thread-Netzwerk weiter. Diese Rolle wird dynamisch von den jeweiligen Geräten aktiviert bzw. wieder deaktiviert, wenn z. B. zu viele Router in der Umgebung unterwegs sind. Daneben bieten die Router Funktionalität, wie Security Services, für andere Geräte, die dem Netzwerk beitreten wollen.
Normalerweise nehmen Thread-Geräte nur die Rolle als Endgerät wahr. Wird mehr Reichweite im Netzwerk benötigt, werden einige dieser Geräte automatisch Router in diesem. Das passiert z. B. dann, wenn ein Endgerät keinen Router findet, aber ein Endgerät in der Theorie eine solche Rolle einnehmen kann.
Auf der anderen Seite funktioniert dies auch, wenn sich zu viele Router in einem Bereich befinden und damit zu viel Redundanz vorhanden ist. In diesem Fall stufen sich Geräte in wieder zurück und geben die Router-Rolle auf. Dies ist z. B. dann der Fall, wenn ein Gerät nur noch mit anderen Geräten verbunden ist, welche ebenfalls die Router-Rolle wahrnehmen.
Damit ist das Routerkonzept, im Gegensatz zu Technologien wie Bluetooth Mesh oder Zigbee dynamisch.
FTDs und MTDs
Thread kennt unterschiedliche Typen von Geräten. Einerseits gibt es sogenannte Full Thread Devices (FTD) und sogenannte Minimal Thread Devices (MTD).
Bei den FTDs handelt es sich um autonome Geräte im Thread-Netzwerk, welche Rollen, jenseits der Endgeräte-Rolle, wahrnehmen. Im Normalfall haben diese Geräte entsprechende Hardwareressourcen, wie genügend Speicher et cetera. Im Gegensatz zu den MTDs sind FTDs immer mit dem Thread-Netzwerk verbunden. Infolgedessen sind FTDs meist solche Geräte, welche direkt am Stromnetz angeschlossen sind.
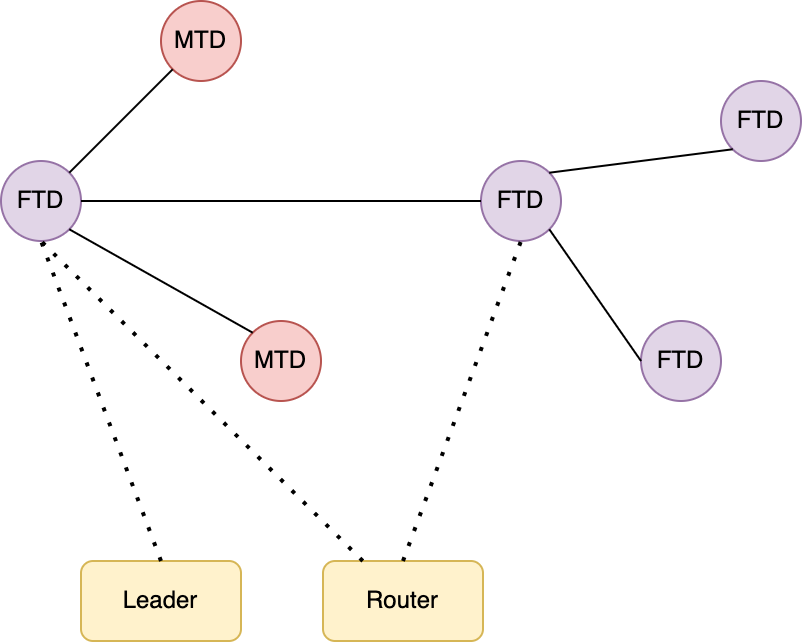
Ein einfaches Thread-Netzwerk
MTDs hingegen sind für solche Geräte gedacht, welche größtenteils über eine Batterie betrieben werden. In diese Kategorien fallen Geräte wie Sensoren und Ähnliche. Diese müssen mit ihren Ressourcen entsprechend haushalten. Sie treten deswegen nur sporadisch mit dem Thread-Netzwerk in Kontakt und befinden sich den Großteil ihrer Betriebszeit im Schlafmodus.
MTDs senden alle ihre Nachrichten zu einem sogenannten Parent-Device und nehmen nur die Rolle als Endgerät im Thread-Netzwerk wahr.
Border-Router
Da im Rahmen von Matter Informationen aus dem Thread-Netzwerk heraus in den Rest des Netzwerkes gelangen müssen, werden hier wieder Router, sogenannte Border-Router benötigt. Diese routen die Informationen aus und in das Thread-Netzwerk.
Im Gegensatz zu anderen Systemen unterstützt Thread mehrere Border-Router, um auch hier wieder einen Single Point of Failure zu vermeiden. Die Funktionalität solcher Border-Router wird und kann von unterschiedlichsten Geräten wahrgenommen werden. Beispiele für solche Geräte sind z. B. Alexa-Geräte oder der HomePod mini von Apple.
Während bei Bridges eine Übersetzung der jeweiligen Daten vorgenommen wird, damit sie vom anderen System verstanden werden, werden bei den Border-Routern nur die entsprechenden Daten vom Thread-Netzwerk in das andere Netzwerk geroutet. Eine Übersetzung derselben findet nicht statt.
Wi-Fi
Neben Thread können Geräte im Matter-Standard auch über Wi-Fi eingebunden werden. Als Übertragungstechnik bietet sich Wi-Fi für Smart Home-Geräte an, welche eine höhere Bandbreite benötigen und meist auch über ein entsprechendes Energiebudget verfügen und zumeist direkt an das Stromnetz angeschlossen sind.
In diese Kategorie fallen unter anderem Videokameras und Türklingeln mit Videoverbindung. Allerdings ist Wi-Fi bzw. ein einzelner Access Point nicht unbedingt dafür gedacht, eine große Menge an Geräten gleichzeitig zu bedienen.
Mit Wi-Fi 6 sind Verbesserungen eingeflossen, um mehr Geräten in einem Netzwerk entsprechende Daten simultan senden zu können, sodass die Nutzung für Smart Home-Geräte auch hier in Zukunft sinnvoller ist.
Distributed Compliance Ledger
Ein interessantes Detail an Matter ist der Distributed Compliance Ledger. In dieser verteilten Datenbank bzw. Blockchain befinden sich kryptografisch abgesicherte Daten über die Geräteherkunft, den Status der Zertifizierung sowie wichtige Einrichtungs- und Betriebsparameter.
Eingesehen werden kann die Datenbank unter anderem über eine entsprechende Weboberfläche. Die verwendete Software dafür kann auf GitHub ebenfalls eingesehen werden.
Gelesen werden kann die Datenbank von jedermann während Schreibzugriffe nur Herstellern im Rahmen ihrer Produkte gestattet sind.
In dieser Datenbank, können Hersteller von Produkten Informationen über diese hinterlegen, damit sie von jedermann gelesen werden können. Auch die Ergebnisse von Compliance Tests werden in diese Datenbank geschrieben. Dasselbe gilt für die Compliance Confirmation der CSA.
Für den Nutzer wird der Distributed Compliance Ledger interessant, um zu erfahren, ob ein Gerät als mit dem Standard konform zertifiziert wurde oder um Modellinformationen wie Firmware- und Hardware-Versionen auszulesen. Auch Zertifikate können über die Datenbank bezogen werden, um lokale Zertifikate zu überprüfen.

Die Netzwerktopologie des Distributed Compliance Ledger
Im Kontext des Ledgers existieren unterschiedliche Knoten. Einer dieser Knoten sind Validator-Knoten welche eine komplette Kopie der Datenbank vorhalten. Nicht jeder Knoten kann ein Validator-Knoten sein, er benötigt hierfür eine Erlaubnis. Auch die Anzahl der Validator-Knoten sollte beschränkt sein.
Ein weiterer Knoten ist der Observer-Knoten. Auch dieser enthält eine komplette Kopie der Datenbank und jeder darf einen solchen Observer-Knoten aufsetzen. Daneben existieren noch andere Knoten wie Sentry-Knoten, welche vor Validator-Knoten stehen können und ein Weg des DDoS-Schutzes sind.
Der Client kann sich nun mit einem dieser Knoten verbinden und die benötigten Informationen erfragen. Die Responses sind kryptografisch abgesichert, sodass es keine Rolle spielt, ob sie von einem Observer– oder einem Validator-Knoten kommen.
Technisch setzt das System auf Tendermint bzw. dem Cosmos SDK auf, welches ein Framework für Blockchains zur Verfügung stellt.
Unterstützung
Matter an sich ist noch ein relativ junger Standard und im Moment ist es noch schwierig kompatible Geräte zu finden, auch wenn teilweise schon Updates und Geräte ausgeliefert worden sind. Dies betrifft z. B. einige Geräte von Eve Systems oder Produkte von Nanoleaf mit Matter-Unterstützung.
Interessant ist die Unterstützung auch vonseiten der Betriebssystemanbieter für mobile Systeme, wie iOS und Android. Mit iOS 16.1 lieferte Apple die Unterstützung für Matter aus. Bei Android lieferte Android 13 die ersten Integrationen für Matter.
Auch Smart Speaker wie die Alexa-Serie von Amazon unterstützen mittlerweile Matter, so wurden bereits Updates für einige Modelle ausgerollt, weitere Modelle sollen Anfang 2023 folgen. Einige Geräte fungieren dann auch als Thread-Border-Router und ermöglichen so die Integration von Smart Home-Geräten. Das Gleiche gilt für HomePod minis und den Apple TV 4K, welche ebenfalls Thread unterstützten.
Auch auf Produktseite fangen immer mehr Hersteller an Support für Matter in ihre Produkte einzubauen, so können Entwickler z. B. mit den Philips Hue-Hubs und Geräten in Verbindung mit Matter erste Tests durchführen.
Lizenz
Wer sich Matter anschauen möchte, kann sich die Spezifikation herunterladen, nachdem einige Daten bei CSA hinterlegt worden sind. Ein frei verfügbarer Download existiert nicht.
Ähnlich sieht es auch beim Thread-Standard aus. Hier werden auch entsprechende Hinweise in der E-Mail gegeben:
Please also note, as per the Thread 1.1 Specification EULA, you are prohibited from sharing the document.
Grundsätzlich handelt es sich bei Matter um einen proprietären Standard, der genutzt werden kann, nachdem eine Zertifizierung durchgeführt und die Mitgliedsgebühren für die Connectivity Standards Alliance gezahlt wurden. Offizieller Quellcode rund um Matter ist auf GitHub zu finden und unter der Apache-Lizenz lizenziert.
Problematisch wird das Lizenzierungsmodell des Matter-Standards für GPL-Software, bedingt durch die jährlich zu leistenden Zahlungen an die Connectivity Standards Alliance, welche mit der GPL nicht vereinbar sind.
Migration auf Matter
Interessant wird es auch, wenn ein bestehendes Smart Home auf Matter umgerüstet werden soll. In einem solchen Fall sind bereits Systeme wie Zigbee oder Z-Wave installiert und die Frage stellt sich, wie diese Systeme umgestellt werden können.
Der einfachste Weg wäre es natürlich alle bestehenden Altgeräte auszubauen und anschließend neue kompatible Matter-Geräte einzubauen. Dies wird, ist den meisten Fällen aus Kostengründen und mangels fehlender Praktikabilität kein Weg sein, der gegangen werden kann.
Im Matter-Standard selbst sind für diesen Fall Bridges vorgesehen, mit welchen diese „Altsysteme“ angebunden werden können. Ein Bridge definiert sich im Matter-Standard dadurch, dass sie ein Matter-Knoten darstellen, welcher eines oder mehrere Nicht-Matter-Geräte darstellt.
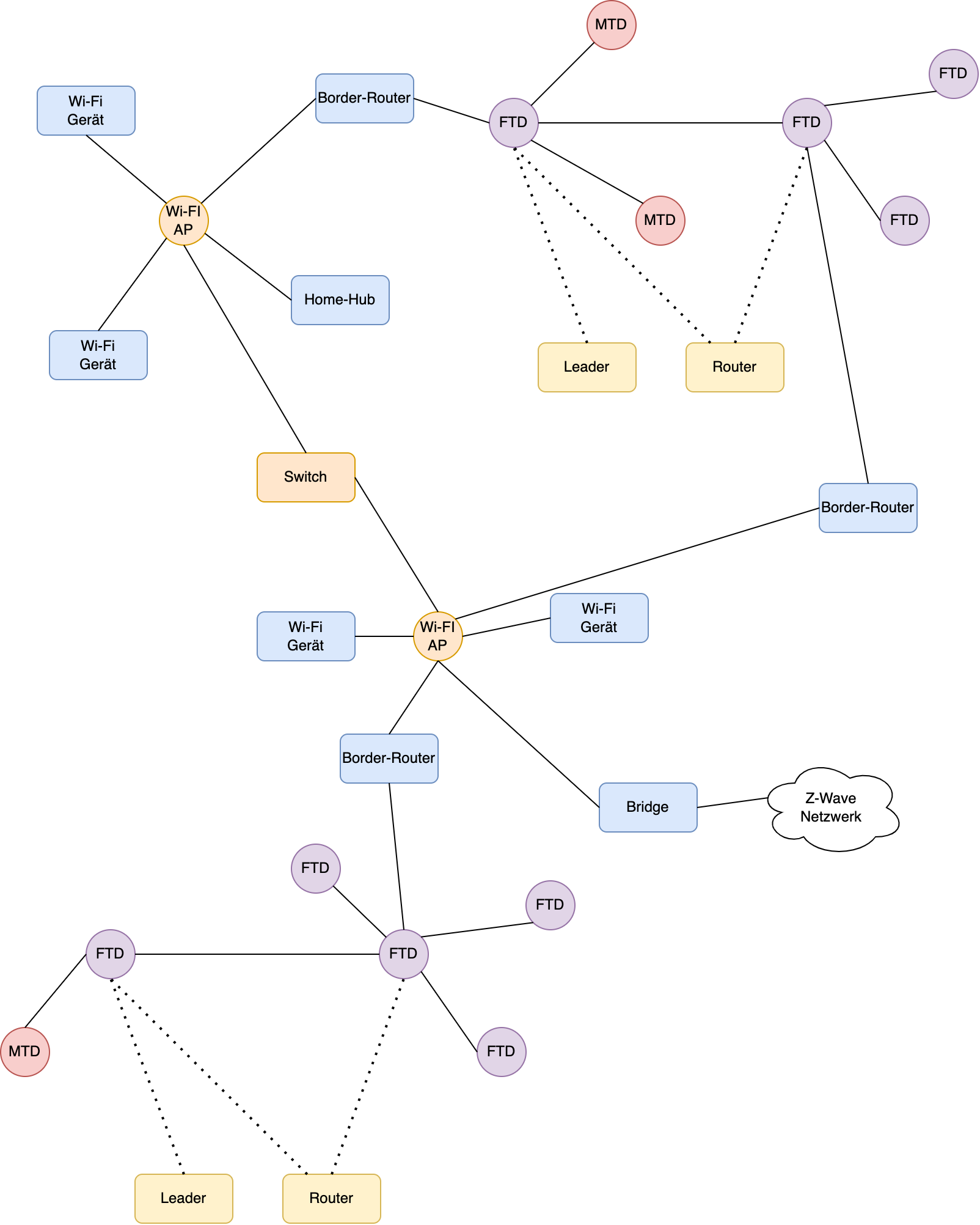
Ein komplexes Matter-Netzwerk
Über solche Bridges können schlussendlich bestehende Netzwerke eingebunden werden. Daneben lassen sich einige Produkte, welche z. B. Hardware nach dem 802.15.4-Standard verbaut haben oder aber bereits Thread unterstützen per Softwareupdate so upgraden, dass sie mit dem Matter-Netzwerk kompatibel werden.
Problematisch an solchen Bridge-Lösungen ist, dass die Geräte nicht direkt integriert sind und somit unter Umständen parallele Mesh-Systeme im Smart Home existieren. Aber über solche Bridge-Lösungen ist möglich, Stück für Stück in die neue Matter-Welt zu migrieren und so den Migrations-Big-Bang zu vermeiden.
Ausblick und Fazit
Matter hat sich als neuer Standard aufgestellt, um den Smart Home-Markt aufzurollen. Dass mit neuen Standards die alten Standards nicht unbedingt obsolet werden, hatte schon XKCD in einem seiner bekannteren Comics gezeigt.
Doch wie könnte die Zukunft von Matter aussehen? Da sich praktisch jeder größere Smart Home-Anbieter und andere Firmen wie Apple, Amazon, Google und Samsung an Matter beteiligen, könnte Matter das Potenzial haben, den Markt aufzurollen.
Schlussendlich stellt sich hier die Frage nach den Produkten, die mit Matter-Unterstützung auf den Markt gebracht werden und ob diese die Kundenwünsche erfüllen können.
Auch muss der Standard, der in der Theorie übergreifend unterstützt wird und dessen Geräte unabhängig vom Hersteller genutzt werden können, dies noch in der Praxis beweisen. Im schlimmsten Fall ist der Kunde hier wieder der Leidtragende, weil er kleine und größere Inkompatibilitäten ertragen muss.
Im besten Fall führt der neue Standard zu einer Migration alter Lösungen in Richtung Matter. Der Zigbee-Standard ist praktisch ein Legacy-Standard geworden und Z-Wave wird im schlimmsten Fall einen langsamen Tod sterben, da viele Nutzer zu Matter abwandern werden und Z-Wave es schwer haben wird, gegen diesen Standard zu bestehen.
Auch wenn Z-Wave aufgrund der genutzten Funkfrequenzen kleinere technische Vorteile hat, sind dies wahrscheinlich keine Faktoren, welche sich auf Kundenseite auswirken werden. Auch wenn dies in der Z-Wave Alliance anders gesehen wird:
Matter is bringing a lot of attention to the smart home. This makes it easy to overlook Z-Wave as the most established, trusted, and secure smart home protocol, that also happens to have the largest certified interoperable ecosystem in the market. We firmly expect that Z-Wave will play a key role in connecting devices and delivering the experience users really want.
Im Rahmen des Artikels wurde einige Hintergründe von Matter erläutert, trotzdem wurde Matter nur angerissen, da der Standard auf über achthundert Seiten, viele Details definiert und unterschiedlichste Verfahren im Detail erläutert.
Wenn Matter seine Versprechen halten kann und die Nutzung für den Kunden einfacher ist, könnte es ein Standard sein, der ein Großteil der Nutzer und Hersteller in Zukunft hinter sich vereinen könnte.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.