Einen Entwicklungszweig anlegen oder doch lieber nicht? Wann geht es zum Test? Workflows im Entwicklungsumfeld sind vielschichtig und sollten zum jeweiligen Projekt passen.
Wer Software entwickelt, der kann dies klassisch bewerkstelligen und seine Software einfach in einem Ordner auf der Festplatte entwickeln und gelegentlich eine Kopie des Ordners erstellen. So finden sich am Ende unzählige Versionen der Software verteilt über verschiedene Verzeichnisse auf der Festplatte.
Auch wenn nicht ausgeschlossen werden kann, dass so in der einen oder anderen Firma entwickelt wird, so werden heutzutage meist Versionskontrollsysteme genutzt und mithilfe dieser ein Arbeitsablauf abgebildet. Kombiniert werden die Versionskontrollsysteme dabei größtenteils mit einem Ticketsystem und entsprechenden Wikis.
Im Rahmen des Artikels wird hierbei besonders auf das Versionskontrollsystem Git Bezug genommen. Git legt den Nutzer nicht auf einen Arbeitsablauf fest, sondern gibt dem Nutzer die Möglichkeit einen gewünschten Arbeitsablauf zu implementieren, ohne dass Git dem Nutzer eine bestimmte Arbeitsweise aufzwingt.
Anforderungen
In den meisten Fällen wird Software anhand von Anforderungen entwickelt. Eine Anforderung entsteht, entweder beim Kunden oder innerhalb der Firma. Diese Anforderung wird definiert und nachdem sie (hoffentlich) ausdefiniert wurde, dem Entwickler vorgelegt.
Während Tickets die Anforderungen festhalten und die Kommunikation zur Anforderung über diese läuft und festgehalten wird, dienen Wikis vorwiegend als Wissensbasis.
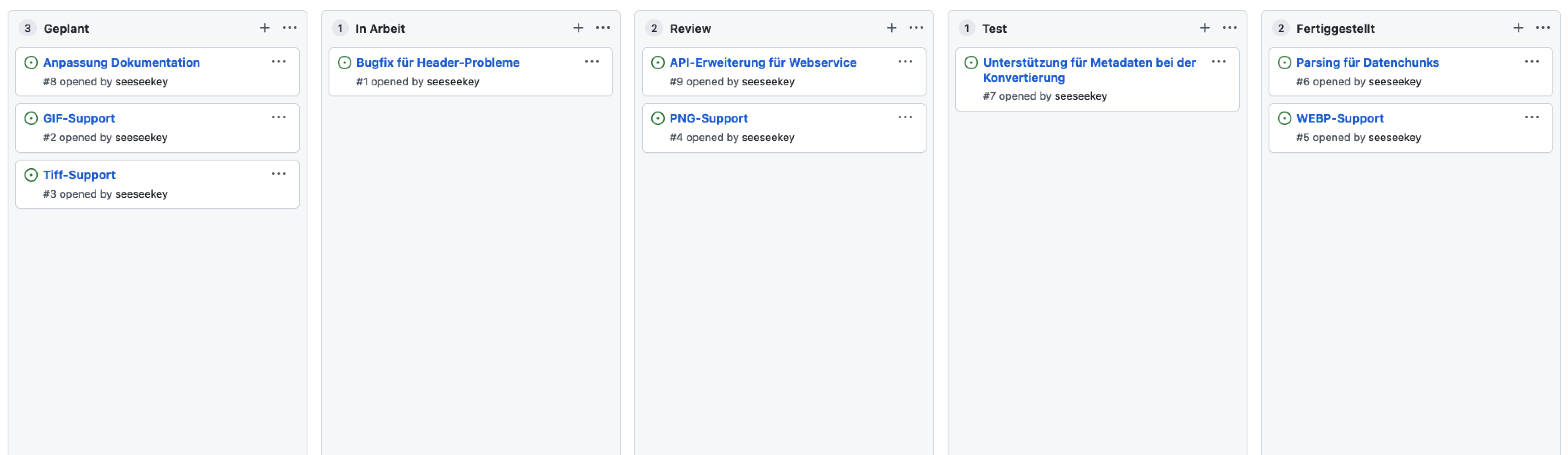
Im Entwicklungsalltag ermöglicht die Kombination dieser Systeme unterschiedlichste Arbeitsabläufe, welche dann auch über entsprechende Tickets abgebildet werden können. Auch die Arbeit mit Boards und ähnlichen Hilfsmitteln hilft es den Arbeitsablauf sinnvoll zu visualisieren.
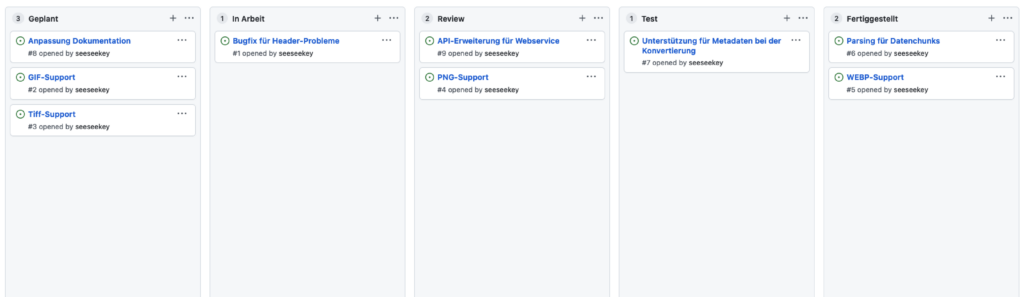
Ein entsprechendes Board
Dabei kann mit unterschiedlichen Spalten wie Geplant, In Arbeit, Review, Test und Fertiggestellt gearbeitet werden. Eine Vertiefung würde an dieser Stelle den Rahmen des Artikels sprengen, da sie auf den Zusammenhang der Arbeitsabläufe mit dem Versionskontrollsystem konzentriert werden soll.
Versionskontrollsysteme
Versionskontrollsysteme bieten für die Entwicklung von Software unterschiedlichste Vorteile. Wie in der Einleitung kurz angerissen, kann die Entwicklung ohne solche Systeme in einer Mischung aus Chaos und Redundanz ausarten. Änderungen können verloren gehen und die Frage, was wurde von Stand A zu Stand B geändert kann nur schwer beantwortet werden.
Im Grunde definieren sich Versionskontrollsysteme über einige Eigenschaften: Protokollierung, Wiederherstellung, Archivierung, Koordinierung sowie die Bereitstellung von Entwicklungszweigen.
Aus Sicht der Arbeitsabläufe in einem Unternehmen ist die Eigenschaft der Koordinierung wichtig. Softwareentwicklung ist in den meisten Fällen Teamwork. Und so muss der Zugriff unterschiedlicher Personen auf den gleichen Quelltext gemanagt werden und entsprechende Methodiken zur Zusammenführung unterschiedlicher Arbeitsstände müssen bereitgestellt werden.
Natürlich kann auch in einem solchen Fall mit Ordnern und einem Netzlaufwerk gearbeitet werden, allerdings wird dies früher oder später zu Problemen führen. So könnten Mitglieder des Teams versuchen, die gleiche Datei des Projektes zu bearbeiten und somit eine Änderung eines Kollegen die Arbeit eines Anderen überschreiben.
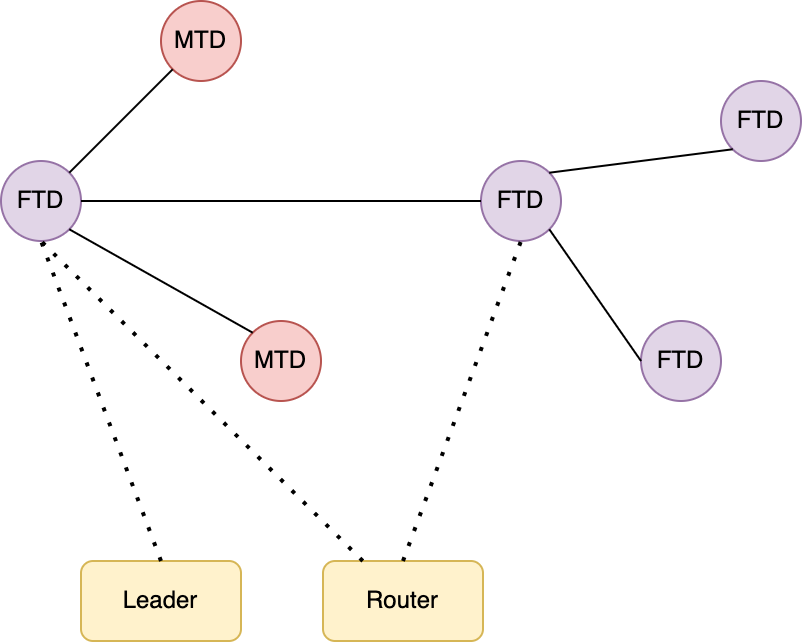
Neben der Koordinierung ist die Bereitstellung von Entwicklungszweigen eine der wesentlichen Funktionalitäten von modernen Versionskontrollsystemen. Das bedeutet, dass es nicht nur eine Variante des Quellcodes existiert, sondern ein Repository, mit seinen Entwicklungszweigen, Branches genannt, eine Baumstruktur darstellt.
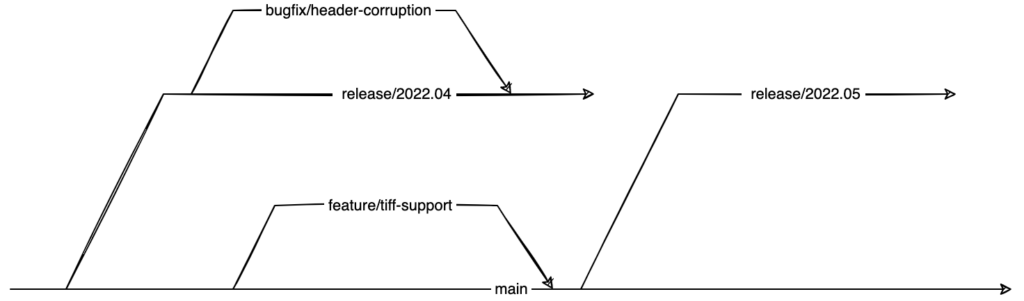
Unterschiedliche Branches in einem Repository bilden eine Baumstruktur
Mithilfe solcher Entwicklungszweige können z. B. Features entwickelt werden, ohne den aktuellen Hauptentwicklungszweig zu stören oder entsprechende Release- und Bugfix-Zweige verwaltet werden.
Branchen und Mergen
Heutige Versionskontrollsysteme kommen ohne einen zentralen Server aus und verfügen meist über einfachen Mechanismus zur Erstellung und der Zusammenführung von Entwicklungszweigen.
Dies sollte nicht als Kleinigkeit abgetan werden. Während dies bei althergebrachten Systemen wie Subversion und CVS zwar technisch möglich war, wurde dieses Feature dort praktisch nicht genutzt.
Bei Systemen wie Git gehören diese Features zu den Grundlagen, während es bei CVS, Subversion und Co. eher als Expertentätigkeit verstanden wurde. Damit wurde die Erstellung und Zusammenführung von Entwicklungszweigen etwas Natürliches. Niemand musste mehr, vor unauflösbaren Konflikten bei der Zusammenführung von Entwicklungszweigen, Angst haben.
Erst dadurch konnten bestimmte Arbeitsabläufe, welche intensiv von Entwicklungszweigen Gebrauch machten, in unsere heutige Entwicklungslandschaft einziehen.
Branches, Branches, Branches
Während der Entwicklung existiert meist ein main– bzw. master-Branch, welcher eine stabile Version enthält und der develop-Branch in welchem sich die Entwicklungsversion befindet.
Mithilfe von Entwicklungszweigen können unterschiedlichste Entwicklungsmodelle realisiert und Features relativ unabhängig voneinander entwickelt werden. Auch die Pflege unterschiedlicher Releases, welche mit Support bedacht werden müssen, ist mithilfe von Entwicklungszweigen möglich.
Neben Entwicklungszweigen existieren in Versionskontrollsystemen sogenannte Tags. Mit diesen können unter anderem Release-Versionen markiert werden und im späteren Verlauf schnell gefunden oder aber Entwicklungszweige vom entsprechenden Tag abgeleitet werden. Dies ist z. B. dann der Fall, wenn ein Bugfix auf einer älteren Release-Version entwickelt werden soll, für welche kein Release-Branch existiert.
Aus Sicht des Entwicklers ermöglichen Entwicklungszweige daneben das, was unter dem Begriff Commit early and often bekannt ist. In einem separaten Feature-Branch können Änderungen schnell festgeschrieben werden, ohne Rücksicht darauf nehmen zu müssen, ob die Änderung das Release in dieser Phase stören würden.
Namensgebung
Bei der Benennung von Entwicklungszweigen sollte nach einem festgelegten Schema gearbeitet werden, welches für den entsprechenden Arbeitsablauf definiert werden sollte.
Wird mit Ticketsystemen gearbeitet, so sollte die Ticketnummer im Branch enthalten sein. Bei Commits gilt das Gleiche für die entsprechende Nachricht, welche dem Commit beigefügt wird. Ticketsysteme nutzen diese Informationen, um zugehörige Entwicklungszweige und Commits direkt am Ticket anzuzeigen.
Je nach gewähltem Arbeitsablauf kann die Benennung aber auch einfach nur der Fachlichkeit geschuldet sein und muss auf keinerlei Ticket verweisen.
Bei der Benennung von Release-Entwicklungszweigen kann mit Zeitangaben oder Versionsangaben, je nach Erfordernis und Struktur der Releases gewählt werden. Ein solcher Entwicklungszweig könnte z. B. den Namen release/2022.04 tragen.
Feature- und Bugfix-Entwicklungszweige können entsprechend benannt werden. Ein Feature könnte dann z. B. so aussehen: feature/tiff-support oder wenn ein Ticket mit im Namen des Entwicklungszweiges kodiert werden soll: feature/id-1234-tiff-support. Bei Bugfixes kann genauso vorgegangen werden, z. B. bugfix/id-1235-header-corruption.
Pull Requests
Wünschenswert bei der Arbeit mit Ticketsystemen in Verbindung mit Versionskontrollsystemen ist die Verknüpfung miteinander. So können am entsprechenden Ticket bereits der zugeordnete Entwicklungszweig, die entsprechenden Commits sowie offene Pull Requests angezeigt werden.
Daneben bieten die Systeme die Möglichkeit, Entwicklungszweige über das Ticket anzulegen und Pull Requests zu erstellen und somit das Entwicklungsergebnis etwas effizienter zu gestalten.
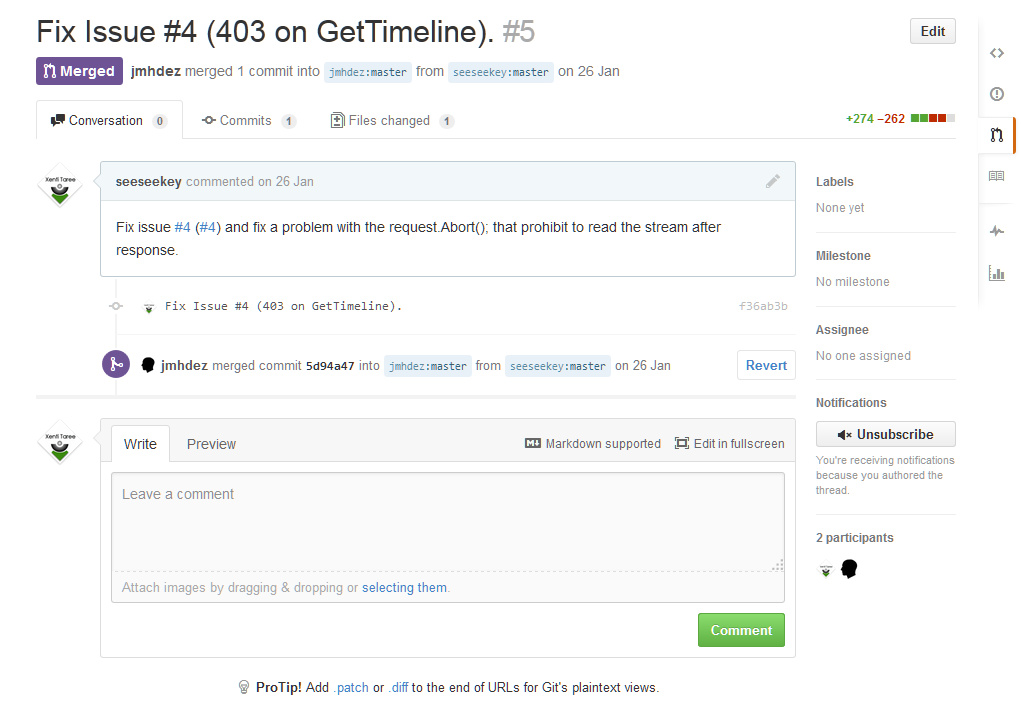
Ein solcher Pull Request (auch als Merge Request bekannt) war ursprünglich eine Mail mit einem angehängten Patch und der Bitte um Integration. Der Entwickler mit einem Zugriff auf das Repository konnten diesen Pull Request dann akzeptieren und den entsprechenden Code zu integrieren.
Teilweise wird dies auch heutzutage noch so gehandhabt, wie bei der Entwicklung der Linux-Kernels.
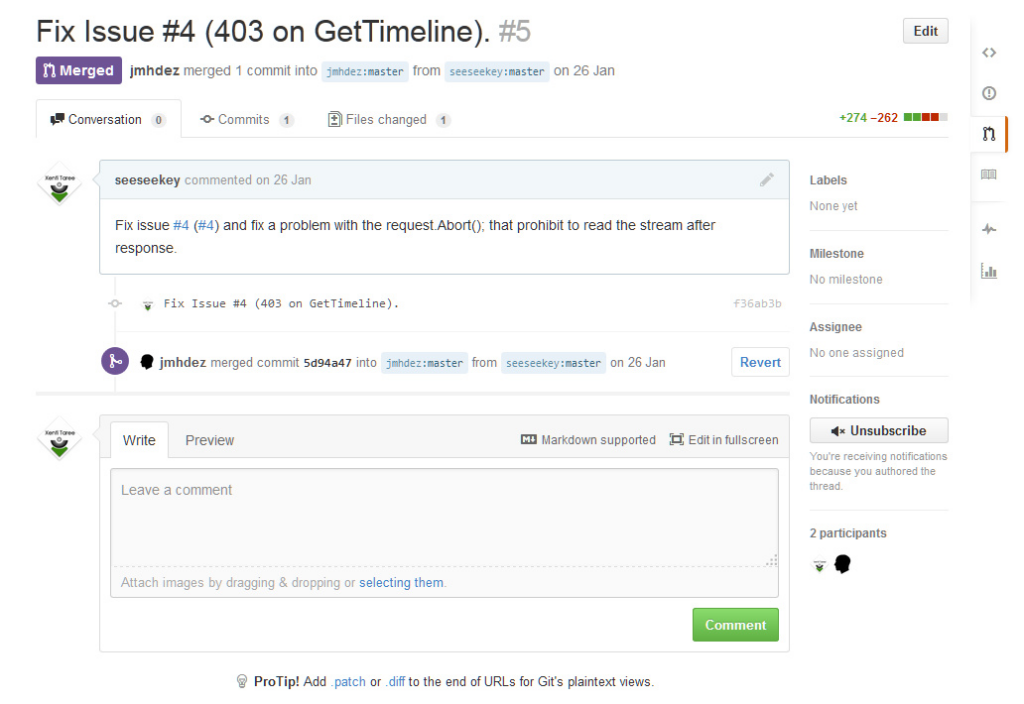
Ein Pull Request unter GitHub
Im Rahmen der Arbeitsabläufe sind Pull Request, wie sie von den unterschiedlichen Systemen wie GitHub oder Bitbucket angeboten werden, ein probates Mittel Änderungen zu reviewen, Feedback zu geben und die Änderungen schlussendlich zusammenzuführen.
Daneben existieren Systeme wie Gerrit, welche komplexere Prozesse für die Integration des Quellcodes in das Repository ermöglichen. Hier können Änderungen kommentiert, diskutiert und abgestimmt werden.
Review und Test?
Einige Entwickler halten Review und Tests für optional. Das sollten sie allerdings niemals sein und dementsprechend auch in keinem Arbeitsablauf fehlen.
Es gibt unterschiedliche Gründe für die jeweiligen Verfahren. Beim Review geht es einmal darum, den Quellcode auf offensichtliche Schwachstellen und Fehler abzuklopfen. Macht der Quellcode das, was die fachliche Anforderung definiert? Werden Coding Guidelines eingehalten und gibt es entsprechende Unit-Test?
Neben den offensichtlichen Vorteilen durch das Review hat der Prozess noch anderen entscheidenden Vorteil. Er trägt zum Knowledge Sharing bei. Nach einem Review wurde eine Stelle im Quellcode bzw. eine Funktionalität nicht nur von einem, sondern von mindestens zwei Entwicklern gesehen und verstanden.
Innerhalb des Arbeitsablaufs lässt sich das Review beliebig gestalten. So kann es z. B. erforderlich sein, bei komplexen Änderungen mehrere Entwickler mit dem Review zu betrauen. In manchen Firmen wird eine Entwicklung im Pair Programming automatisch als gereviewter Code gesehen.
Auch der Test ist wichtig, um die Funktionalität abzusichern und eventuelle Fehler vor der Auslieferung abstellen zu können. Hier stellt sich natürlich die Frage, an welcher Stelle der entsprechende Test eingebaut werden kann und sollte.
Workflows
Nach diesen Vorbetrachtungen der meist technischen und organisatorischen Gegebenheiten können sich nun einzelne Arbeitsabläufe im Detail angeschaut werden.
Dabei wird im Grunde mehr oder weniger zwischen zwei Arten der Softwareentwicklung unterschieden. Einmal zwischen releasebasierten Arbeitsabläufen, bei denen auf ein Release hinaus entwickelt wird und einmal die kontinuierliche Entwicklung, bei der an einer Applikation entwickelt wird, welche keine klassischen Releases mehr kennt. Ein Beispiel für letzteres wäre eine Webapplikation, welche praktisch immer in der aktuellen Version ausgeliefert wird.
Diese Fragen entscheiden am Ende darüber, wie der jeweilige Workflow für das Team respektive das Produkt am Ende aussieht.
One branch to rule them all
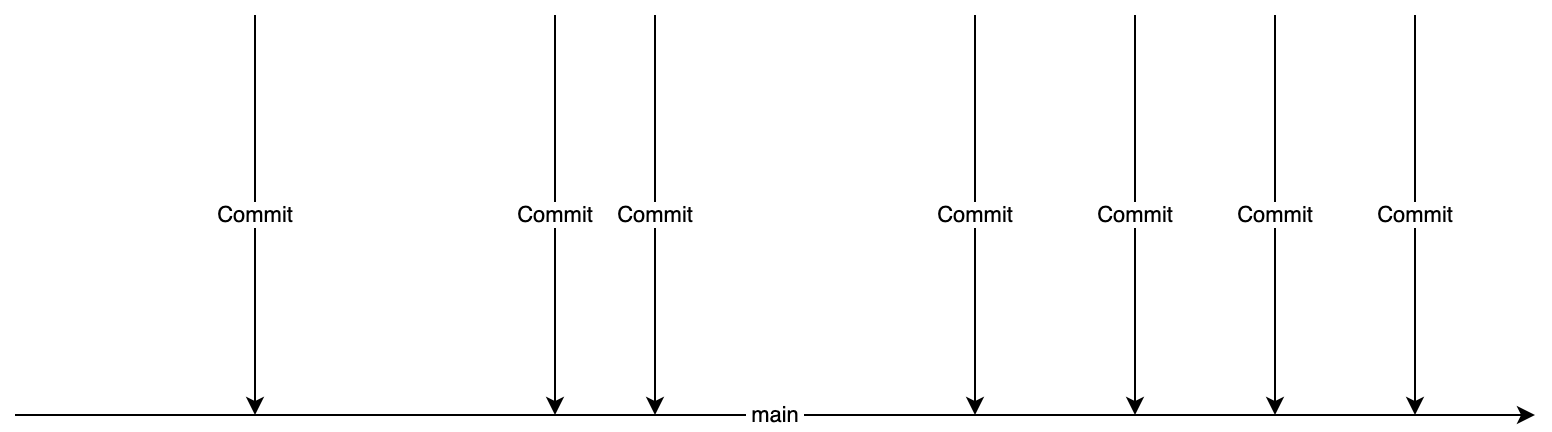
Der einfachste Arbeitsablauf besteht sicherlich darin, einfach die entsprechenden Commits im main-Branch seines Projektes zu erstellen.
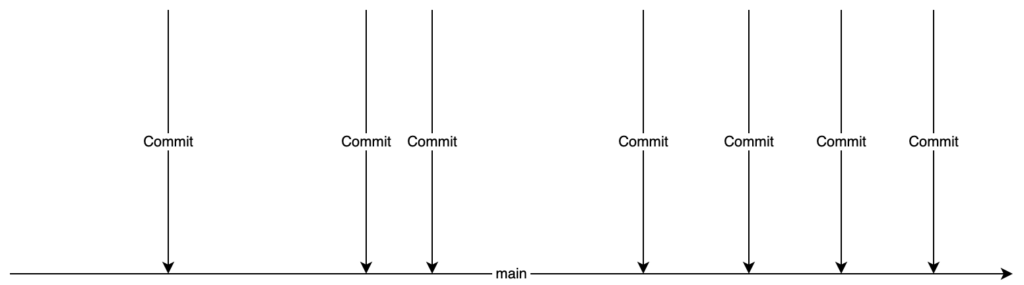
Alle Commits landen direkt im main-Branch
Bei diesem Arbeitsablauf mischen sich die Implementierungen unterschiedlicher Features und andere Dinge im schlimmsten Fall zu einem instabilen Gemisch. Features landen Stück für Stück im main-Branch und experimentelle Entwicklungen sind ebenfalls schwierig in diesem Model unterzubringen.
Auch ein Review und ein Test sind nur nachträglich möglich, wenn das Kind bereits in den Brunnen gefallen ist. Daneben stellt sich die Frage, wie definiert wird, dass der main-Branch stabil ist und ein entsprechendes Release erstellt werden kann.
Eine Aufgabe: ein Branch
Ein simpler Arbeitsablauf könnte nun so aussehen, dass für jede Änderung, sei es ein Feature, ein Bugfix oder etwas anderes ein Entwicklungszweig angelegt wird und dieser, wenn die Entwicklung abgeschlossen wurde, wieder mit dem Hauptzweig zusammengeführt wird.
Ein solcher Entwicklungszweig wird meist Ticket-Branch, Feature-Branch oder auch Topic-Branch genannt.
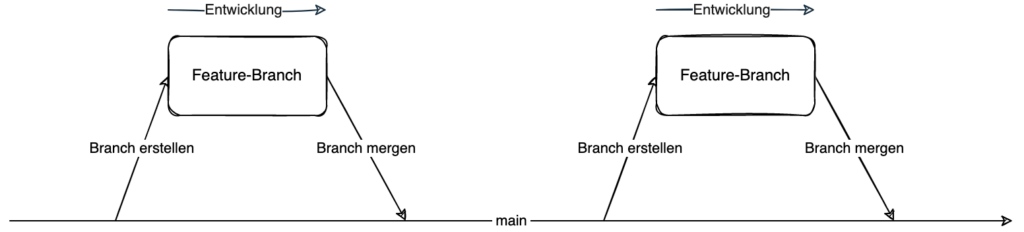
Jede Entwicklung findet in einem separaten Branch statt
Im Detail sind bei dieser Variante allerdings einige Fragen ungeklärt. Wann findet das Review statt, wann der Test? Wer gibt den Merge in den Hauptentwicklungszweig frei? Wann ist der main-Branch als stabil anzusehen?
Aus diesem simpleren Arbeitsablauf, bzw. der Idee des Branchings für einzelne Anforderungen ergeben sich in der Realität unterschiedlichste Arbeitsabläufe, von deinen einige im Detail vorgestellt werden sollen.
Entwicklungs- und stabile Linien
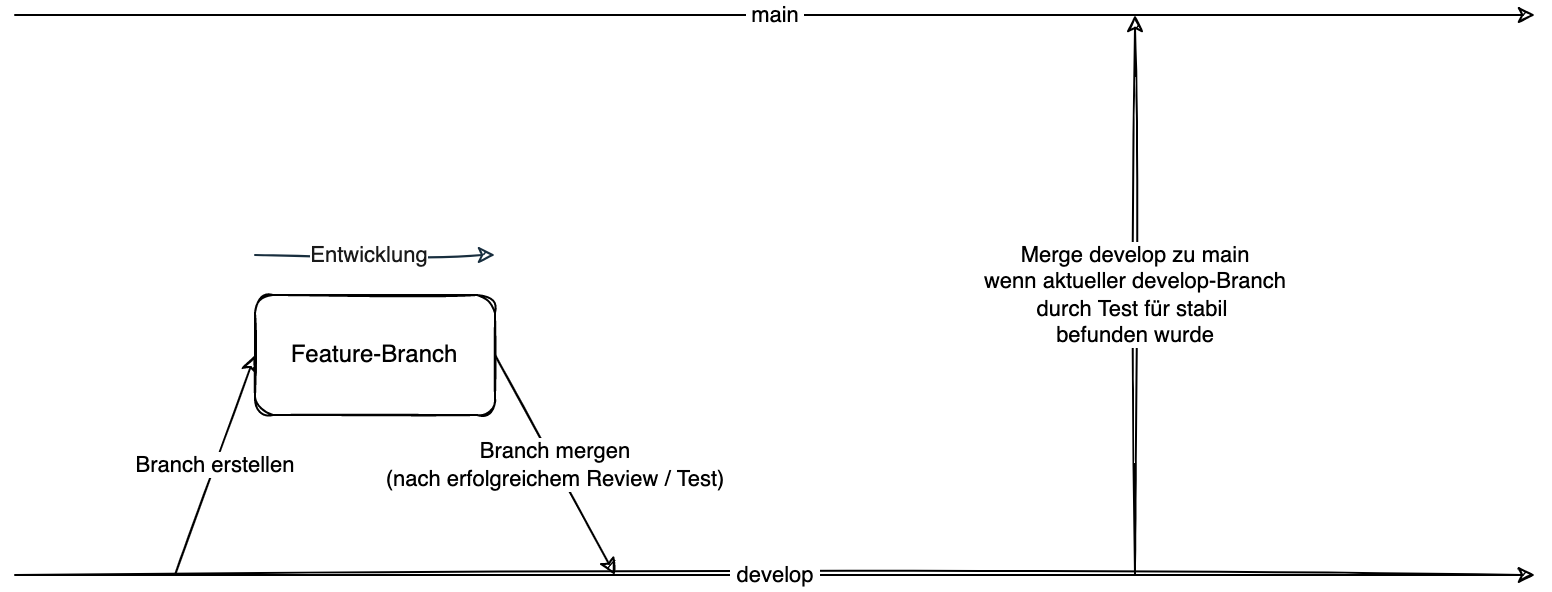
Bei diesem Arbeitsablauf wird mit zwei Entwicklungszweigen gearbeitet, einmal dem main-Branch und einmal dem develop-Branch. Soll eine neue Entwicklung stattfinden, so wird ein Entwicklungszweig basierend auf dem develop-Branch erstellt und auf diesem das entsprechende Feature entwickelt.
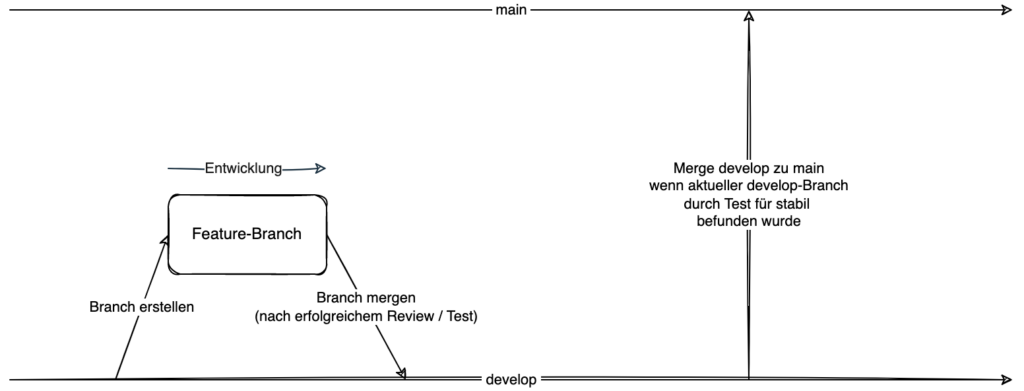
Der main-Branch enthält die stabile Variante der Software dar
Ist die Entwicklung abgeschlossen, kann ein Pull Request erstellt werden, welcher als Ziel den develop-Branch trägt. Im Rahmen des Pull Requests kann der Reviewer den Quellcode reviewen und entsprechende Anmerkungen antragen. Der Entwickler kann entsprechende Änderungen, welche sich aus dem Review ergeben, im Feature-Branch vornehmen.
Ist das Review erfolgreich abgeschlossen, so könnte die Änderung vor der Zusammenführung der Entwicklungszweige oder danach getestet werden. Wird im Feature-Branch getestet, so sollte anschließend auch im develop-Branch getestet werden, um die erfolgreiche Integration des Features sicherzustellen. Hier bietet sich ein Modell an, nur besonders kritische Änderungen vor und nach dem Merge zu testen, während gewöhnliche Änderungen nur nach der Zusammenführung der Entwicklungszweige getestet werden.
Im Falle von Fehlern, welche im Test gefunden werden, sollten diese im Feature-Branch behoben werden und anschließend wieder ein Pull Request erstellt werden.
Der develop-Branch wird regelmäßig, immer dann, wenn er für stabil befunden wird, in den main-Branch gemergt, sodass dieser in der Theorie eine stabile Version der Software enthält.
Natürlich kann nicht wirklich sichergestellt werden, dass die entsprechende Version stabil ist und auch das Arbeiten mit mehreren Releases ist mit einem solchen Workflow nicht praktikabel möglich.
Der Vorteil, der sich aus dieser Vorgehensweise ergibt, ist, dass der main-Branch immer relativ stabil bleibt, da nur getestete Änderungen in ihn wandern. Außerdem können mehrere Features parallel entwickelt werden.
Auch können Tags hier wieder genutzt werden, um Releases zu definieren und für spätere Änderungen verfügbar zu halten.
Releases aus dem main-Branch
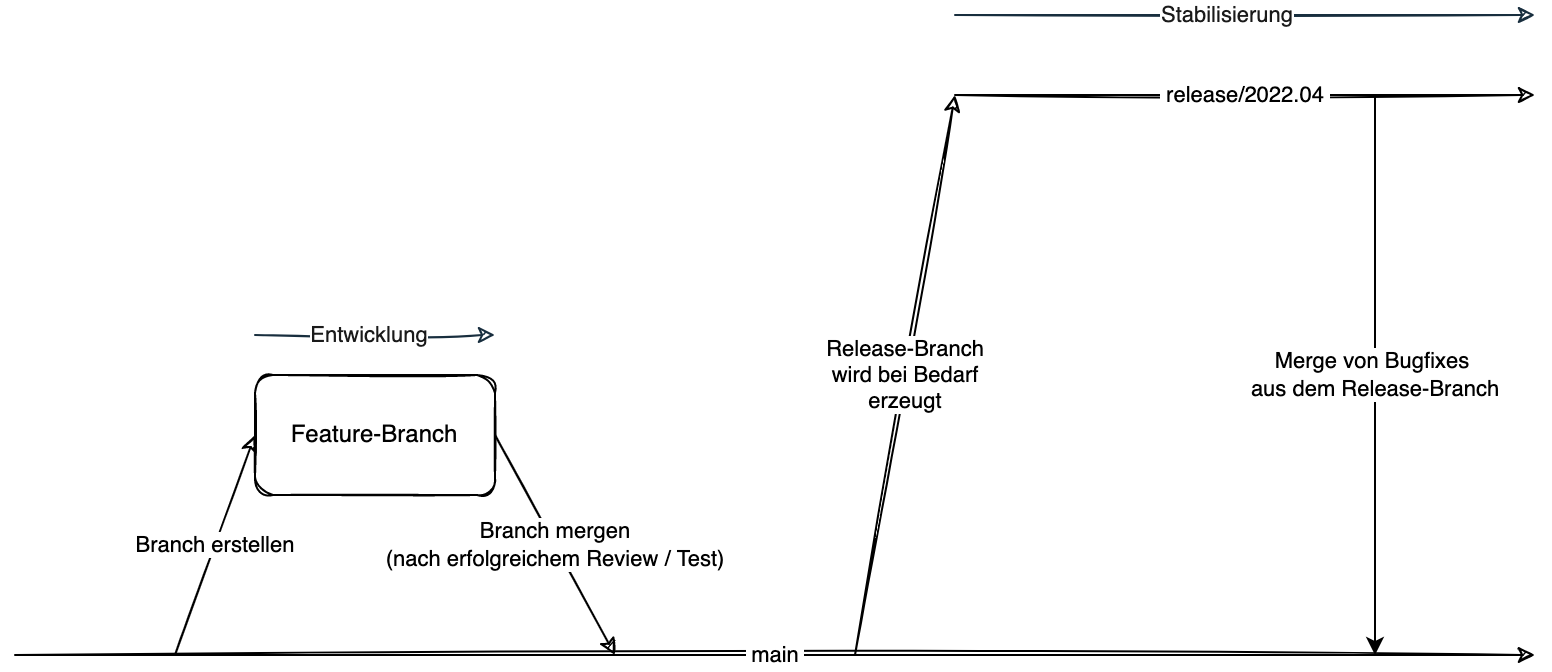
Eine andere Variante ist es, direkt auf dem main-Branch zu arbeiten. Hier kann optional mit Feature-Branches gearbeitet werden.
Für ein nahendes Release wird nun vom main-Branch ein Release-Branch angelegt und dieser entsprechend stabilisiert; bis das Release schlussendlich ausgeliefert werden kann.
Nachteilig ist hier, dass nicht wirklich mit parallel mit Releases gearbeitet werden kann. Auch die Sicherstellung, dass ein bestimmtes Feature in einem bestimmten Release landet, ist nur mit größerem Aufwand zu realisieren.
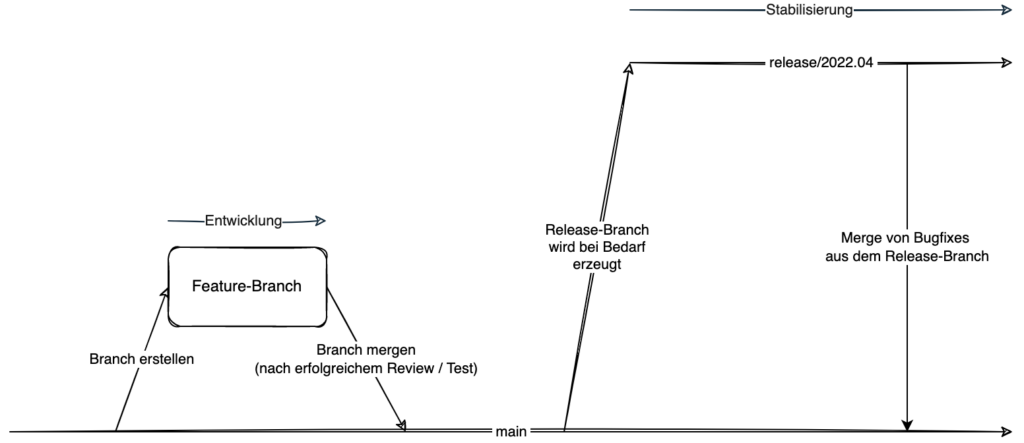
Neue Releases werden aus dem main-Branch abgeleitet
Während der Stabilisierungsphase im Release besteht, daneben das Problem, dass entsprechende Bugfixes auch in den main-Branch übernommen werden müssen und dies einen zusätzlichen Aufwand bedeutet. Daneben nehmen die Stabilisierungsphasen größere Zeiträume ein und verhindern somit die eigentliche Weiterentwicklung der Software.
Von Release zu Release
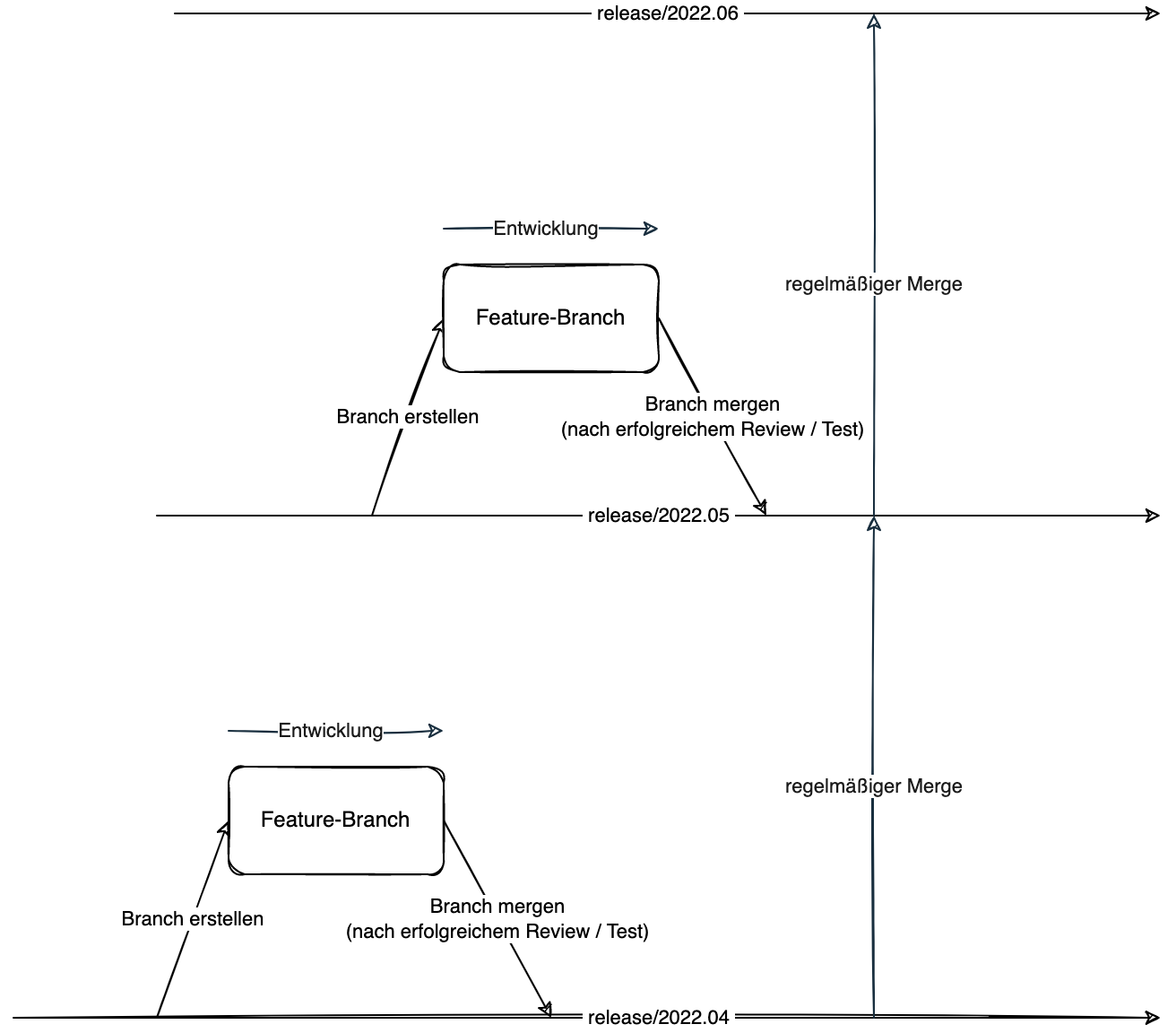
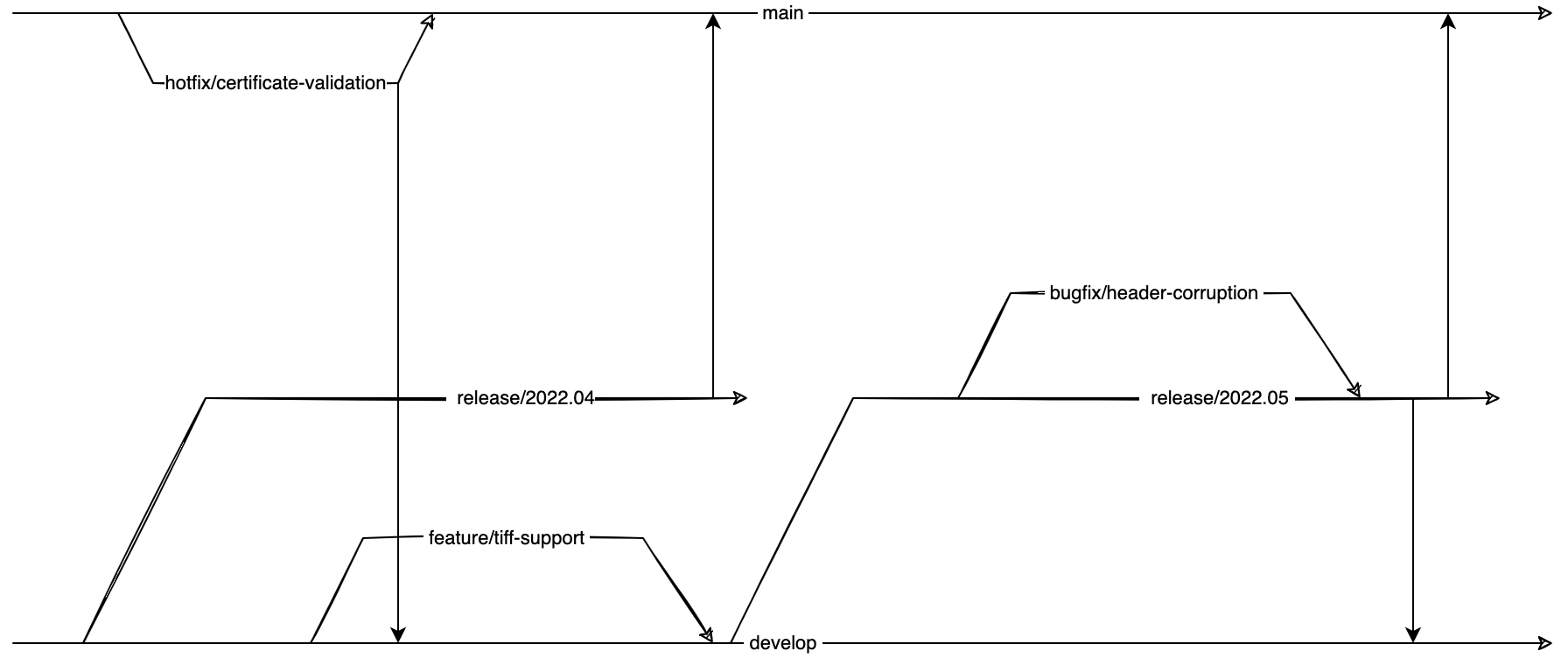
Soll mit mehreren Releases gearbeitet werden, so kann ein Arbeitsablauf gewählt werden, welcher unabhängig vom main-Branch ist und stattdessen nur noch aus Release-Branches besteht.
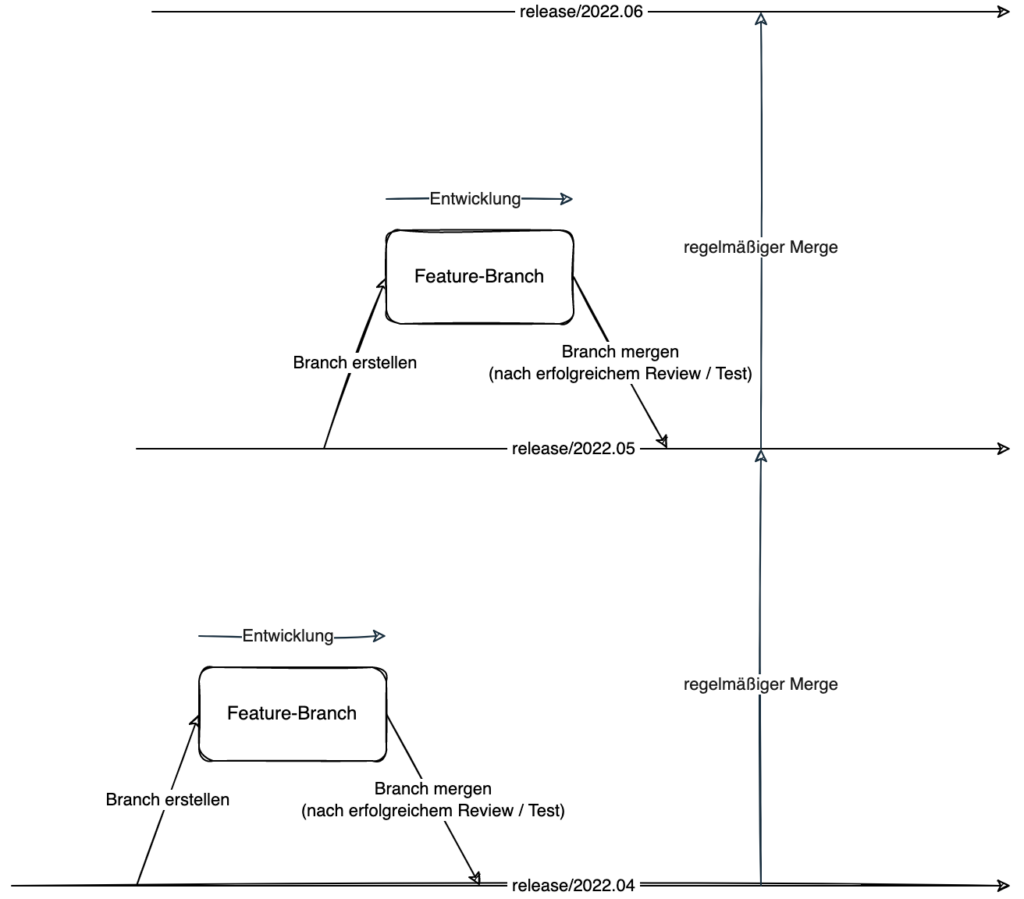
Release-Branches werden nach oben gemergt
In diesem Modell wird für jedes Release ein Entwicklungszweig angelegt. Wenn die Software z. B. monatlich deployt wird, könnten die entsprechenden Branches wie folgt aussehen: release/2022.04, release/2022.05, release/2022.06 usw.
Jede Anforderung wird nun einem Release zugeordnet. Wird ein Feature entwickelt, so wird ein Feature-Branch vom entsprechenden Release-Branch gezogen und auf diesem Feature-Branch die Entwicklung durchgeführt.
Wird das Feature rechtzeitig zum Release fertig entwickelt, wird es im Rahmen des Prozesses (Review, Test) mit dem Release-Branch zusammengeführt.
Kann ein Feature nicht zum zugeordneten Release fertiggestellt werden, wird das zugeordnete Release im Ticket geändert und der Feature-Branch auf Basis der neuen Release-Version fertiggestellt.
Hierzu wird der neu zugeordnete Release-Branch in den Feature-Branch gemergt und anschließend mit der Entwicklung fortgefahren.
Der Feature-Branch kann auch zwischenzeitlich mit dem zugeordneten Release-Branch aktualisiert werden, sodass die eventuellen Änderungen des Release-Branches sich auch im Feature-Branch niederschlagen.
Die Release-Branches selber werden regelmäßig bzw. automatisch von den älteren zu den neueren Branches gemergt. Damit sind Änderungen, welche einem älteren Release zugeordnet waren, automatisch in den neueren Releases enthalten.
Vorteilig an diesem Entwicklungsmodell ist, dass parallel an mehreren Releases gearbeitet werden kann und Verschiebungen von Features im Rahmen der Entwicklung aus technischer Sicht kein Problem darstellen.
Auch können alte Releases bei diesem Arbeitsablauf problemlos über einen längeren Zeitraum betreut werden und mit Bugfixes versehen werden. Diese Bugfixes landen durch den Merge-Prozess der Release-Branches untereinander immer wieder in den neueren Releases.
Bei der Arbeit mit den einzelnen Releases kann die Arbeit noch in Entwicklungs- und Stabilisierungsphasen unterteilt werden, um möglichst stabile und getestete Releases abzuliefern.
Dabei werden neue Features nur innerhalb der Entwicklungsphase in den entsprechenden Release-Branch gemergt. Ist diese Phase ausgelaufen, wird das zugeordnete Release in der Anforderung respektive dem Ticket auf das nächste Release verschoben.
In der Stabilisierungsphase werden nur noch Bugfixes durchgeführt, welche zur Stabilisierung des Releases beitragen.
Git Flow
Ein weiteres relativ beliebtes Modell ist der Arbeitsablauf Git Flow, welcher von Vincent Driessen erdacht wurde und sich neben der guten Skalierbarkeit auch durch seine Vorteile in der Zusammenarbeit auszeichnet.
Git Flow zielt hauptsächlich auf Software ab, bei welcher mehrere Versionen parallel unterstützt werden müssen und sollte nicht als Allheilmittel betrachtet werden, wie der Entwickler selbst schreibt:
This model was conceived in 2010 […] In those 10 years, git-flow […] has become hugely popular in many a software team to the point where people have started treating it like a standard of sorts — but unfortunately also as a dogma or panacea.
This is not the class of software that I had in mind when I wrote the blog post 10 years ago. If your team is doing continuous delivery of software, I would suggest to adopt a much simpler workflow (like GitHub flow) instead of trying to shoehorn git-flow into your team.
Das Regelwerk, welches hinter diesem Arbeitsablauf steht, wirkt auf den ersten Blick wesentlich komplizierter als das anderer Arbeitsabläufe. Das beginnt damit, dass mit unterschiedlichsten Entwicklungszweigen gearbeitet wird. So existieren in diesem Flow die Branches main, develop und separate Branches für Features, Hotfixes und Releases.
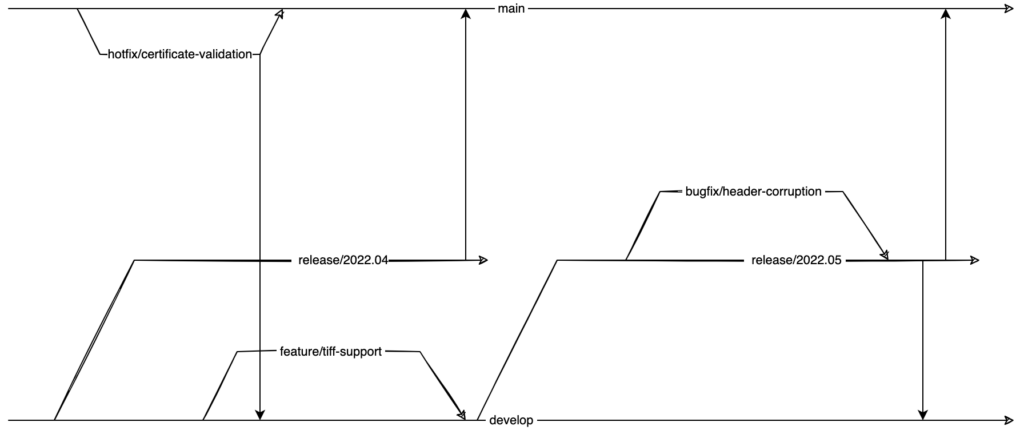
Bei Git Flow existieren eine Reihe von Branchtypen
Im Rahmen des Arbeitsablaufs ist geregelt, aus welchen Entwicklungszweigen weitere Entwicklungszweige erstellt werden sollen und wie und in welche Richtung die jeweiligen Zweige zusammengeführt werden dürfen.
Auch wird in diesem Modell gewünscht, dass Feature-Branches nur lokal beim Entwickler liegen und nicht zum zentralen Server hochgeladen werden.
Grundsätzlich wird bei Git Flow mit Feature-Branches gearbeitet, welche auf dem develop-Branch basieren. Aus diesem Branch wiederum werden entsprechende Release-Branches gezogen.
Ist ein Release veröffentlicht, werden eventuelle Bugfixes, über entsprechende Bugfix-Branches basierend auf dem Release-Branch erstellt und dort der Bugfix entwickelt.
Release-Branches werden in den main-Branch gemergt und im Falle von Änderungen des Release-Branches auch in den develop-Branch.
Sollte ein Hotfix notwendig sein, so wird dieses auf Basis des main-Branches in einem Hotfix-Branch entwickelt und anschließend wieder in den main-Branch und in den develop-Branch eingepflegt.
GitHub Flow
Ein weiterer bekannter Arbeitsablauf ist der GitHub Flow. Bei diesem wird davon ausgegangen, dass der main-Branch grundsätzlich immer deploybar ist.
Bei einer neuen Entwicklung wird ein Entwicklungszweig basierend auf dem main-Branch erstellt und ein entsprechender beschreibender Name benutzt, z. B. tiff-support und auf diesem Entwicklungszweig entwickelt.
Ist die Entwicklung so weit abgeschlossen, dass der Entwicklungszweig in den main-Branch eingepflegt werden kann, wird ein Pull Request erstellt und der Reviewer kann sich diesen anschauen und anschließend den Merge durchführen.
Daneben dienen Pull Requests in diesem Arbeitsablauf der allgemeinen Klärung, so können Pull Requests auch erstellt werden, wenn Feedback oder andere Hilfe benötigt wird.
Damit ist das Verfahren ähnlich dem Arbeitsablauf, bei welchem für jede Entwicklung ein eigener Entwicklungszweig erstellt und dieser wieder eingepflegt wird. Im Gegensatz zum obigen Arbeitsablauf definiert der GitHub Flow einige Rahmenbedingungen genauer und sieht weitere Schritte nach dem einpflegen des Zweiges vor.
Hier fordert der Arbeitsablauf ein, dass nach der Zusammenführung der Entwicklungszweige der aktuelle Stand des main-Branches sogleich deployt wird. Hintergrund ist hier, dass damit das Verständnis geschaffen wird, dass wenn die eigenen Code-Änderungen nicht stabil sind, das System bricht. Und aus diesem Grund die Entwickler besondere Sorgfalt darauf legen (sollten) wirklich stabile Änderungen einzubringen.
Trunk Flows
Neben diesen branchbasierten Workflows werden in letzter Zeit vermehrt sogenannte trunk-basierte Flows genutzt.
Bei diesem Arbeitsablauf soll möglichst darauf verzichtet werden, langlebige Entwicklungszweige zu halten. Damit sollen unter anderem mögliche Merge-Konflikte verhindert werden. Stattdessen sollen Commits hier direkt im trunk; im Fall von Git also im main-Branch, erstellt werden.
Die Commits sind bei diesem Verfahren erfahrungsgemäß eher klein. Außerdem hat der Entwickler sicherzustellen, dass der Build ordnungsgemäß funktioniert, bevor er den Commit zum Server hochlädt.
Für Reviews können kurzlebige Entwicklungszweige angelegt werden und entsprechend für Pull Requests und das anschließende einpflegen in den main-Branch genutzt werden.
Schleicht sich dennoch ein Fehler ein, so wird der Commit auf dem main-Branch zurückgerollt.
Continuous Integration-Systeme spielen in diesem Prozess eine wichtige Rolle, indem sie bei Änderungen sofort entsprechende Tests durchführen und den Entwickler informieren, wenn der Build nicht den Anforderungen an die geforderte Qualität entspricht.
Je nach Konfiguration rollen die Continuous Integration-Systeme die problematischen Commits automatisch zurück.
Diese durchgeführten automatisierten Tests, sowie Code-Reviews sollen sicherstellen, dass der main-Branch immer deploybar ist; vergleichbar zu dem GitHub Flow.
Wenn der Test fehlschlägt
Egal in welchem Arbeitsablauf, stellt sich immer die Frage, wie mit Features umgegangen wird, die sich bereits im main-, develop– oder release-Branch befinden und Fehler festgestellt wurden.
Grundsätzlich sollte hier die Entwicklung wieder aufgenommen und der Fehler beseitigt werden. Je nach Arbeitsablauf kann diese Entwicklung im Feature-Branch erfolgen oder z. B. direkt im main-Branch gearbeitet werden.
Problematisch wird es an der Stelle, wenn das Feature bereits gemergt ist, es zeitlich aber nicht mehr realistisch ist, etwaige Fehler bis zum Release zu beseitigen.
In einem solchen Fall existieren unterschiedliche Möglichkeiten. So kann unter anderem mit Feature-Flags gearbeitet werden, welche es ermöglichen das entsprechende Feature abzuschalten.
Je nach verwendeter Programmiersprache können hier Möglichkeiten der jeweiligen Sprache bzw. des jeweiligen Toolings benutzt werden. Unter Rust könnte z. B. über Cargo ein entsprechendes Feature definiert sein und dieses im Fehlerfall wieder abgeschaltet werden.
Feature-Flags werden auch bei trunk-basierenden Workflows als Ergänzung gesehen, um das Feature langsam zu entwickeln. Allerdings stellt sich hierbei die Frage nach der Testbarkeit solange das Feature-Flag noch nicht aktiv ist.
In der Praxis ist es nicht immer möglich, mit solchen Feature-Flags zu arbeiten. In einem solchen Fall können die entsprechenden Commits rückgängig gemacht werden und somit aus dem entsprechenden Branch, welcher zum Release führt, entfernt werden.
Einfacher ist ein solcher Revert, wenn die Änderungen aus einem Feature-Branch per Squash zu einem einzelnen Commit zusammengeführt werden und erst dann gemergt werden.
Damit tauchen die kompletten Änderungen eines solches Feature-Branches nur noch als ein einzelner Commit, im Branch in den die Änderung eingepflegt wird, auf. Positiv wirkt sich dies auch auf die Übersichtlichkeit in diesem Branch aus. Allerdings bedeutet es je nach Automatisierungsgrad des Arbeitsablaufs zusätzlichen Aufwand.
Merge-Hölle?
Bei vielen der oben beschriebenen Arbeitsabläufe wird mit Entwicklungszweigen gearbeitet. Damit mit diesen gearbeitet werden kann, müssen sie schlussendlich in ihre Zielzweige eingepflegt werden.
Bei der Zusammenführung zweier Entwicklungszweige können entsprechende Probleme auftreten, dass zwei Änderungen nicht mehr zusammenpassen. Ein solcher Merge-Konflikt muss behoben werden, um die entsprechende Zusammenführung der Entwicklungszweige erfolgreich abzuschließen.
Meist ist die Behebung solcher Konflikte trivial. Um die Gefahr für solche Konflikte zu verhindert, hilft es Anforderungen und damit verbundene Code-Änderungen klein zuhalten.
Auch Coding Guidelines helfen solche Probleme zu minimieren, da sie dafür sorgen, dass die Formatierungen über das Projekt und die beteiligten Entwickler identisch sind. Damit können entsprechende Probleme wegen unterschiedlichen Einzugsbreiten und Ähnlichem gar nicht erst auftreten.
Merges sind nichts, wovor Entwickler Angst haben sollten. Sie gehören zum Tagesgeschäft dazu und verlaufen in einem Großteil der Fälle problemlos ab und Konflikte können auch dank des Toolings schnell gelöst werden.
Fazit
Arbeitsabläufe gibt es viele und im Grunde hängt der genutzte Arbeitsablauf vom Team, dem Projekt und den damit verbundenen Anforderungen ab. Den einen richtigen Arbeitsablauf gibt es nicht.
Vor allem im agilen Kontext, sollte jedes Team für sich entscheiden, mit welchem Arbeitsablauf es arbeitet und diesen an die eigenen Gegebenheiten und Besonderheiten anpassen.
Wichtig ist, dass die Arbeitsabläufe die Entwicklung nicht behindern oder erschweren, sondern ein Gerüst bieten, damit die Anforderungen der Entwickler, Produktmanager und Kunden schnell abgebildet und sinnvoll umgesetzt werden können und ein stabiles Produkt ausgeliefert werden kann.
Aus Sicht des Autors bietet sich der Release zu Release-Workflow in den meisten Fällen eines releasebasierten Produktes an, da er viele Vorteile bietet; bei relativ geringem Aufwand.
Zudem hängt viel davon ab, was für ein Produkt entwickelt wird und wie die Release-Zyklen aussehen. So ist es auch nicht ungewöhnlich Services regelmäßig z. B. täglich oder sogar mehrmals täglich zu deployen. In solchen Fällen sind Arbeitsabläufe wie der Github Flow sinnvoller zu nutzen.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.