In der Softwareentwicklung stellt sich manchmal das Gefühl ein, von Buzzwörtern umgeben zu sein. Auch Self Healing Code könnte ein solches sein. Doch trägt das Konzept einige interessante Eigenschaften mit sich und sollte nicht vorschnell verworfen werden.
Die grobe Idee hinter diesem Konzept ist es, dass die Anwendung Fehler erkennen und diese im Idealfall auch beheben kann. Dieser Prozess soll ohne menschliches Eingreifen stattfinden.
Neben der einzelnen Applikation kann, sich ein solches Verhalten auf komplexere Systeme und deren Zusammenspiel beziehen. Neben der Fehlerbehebung, während der Laufzeit einer solchen Software, wird der Begriff des Self Healing Code in letzter Zeit auch im Zusammenhang mit generativer KI genutzt.
Definition
Im Bereich der Softwareentwicklung ist Self Healing Code so definiert, dass ein Programm in der Lage ist, Fehler zu erkennen und zu korrigieren. Verwandt damit ist der Begriff der selbstheilenden Systeme, denen die Fähigkeit inhärent ist, aus einem defekten Zustand wieder in einen funktionalen Zustand zu wechseln.

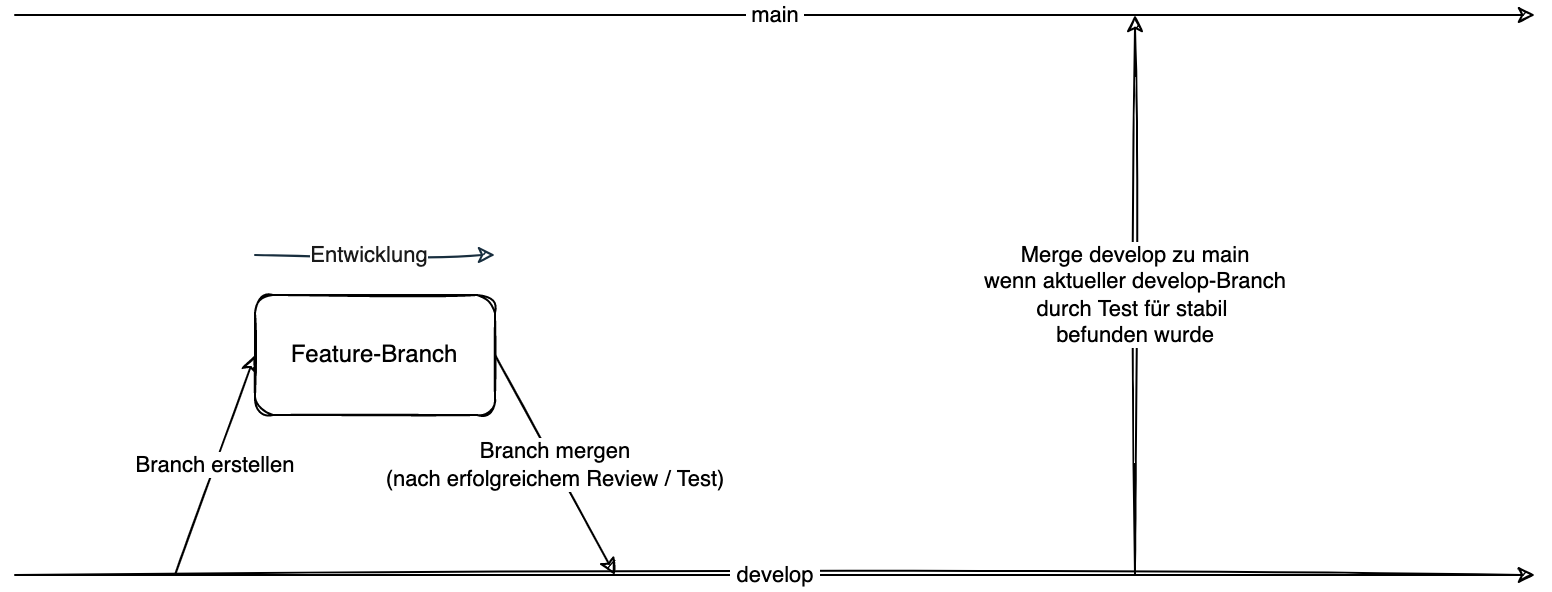
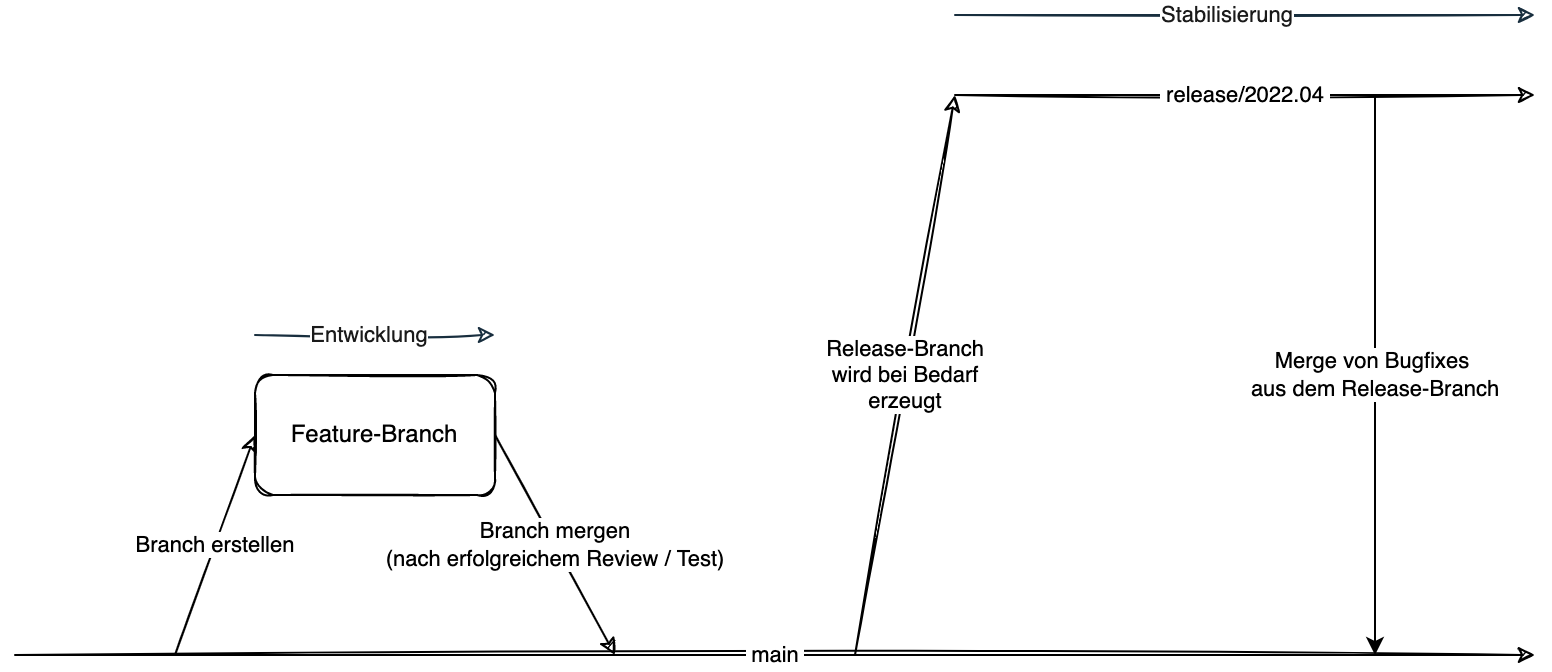
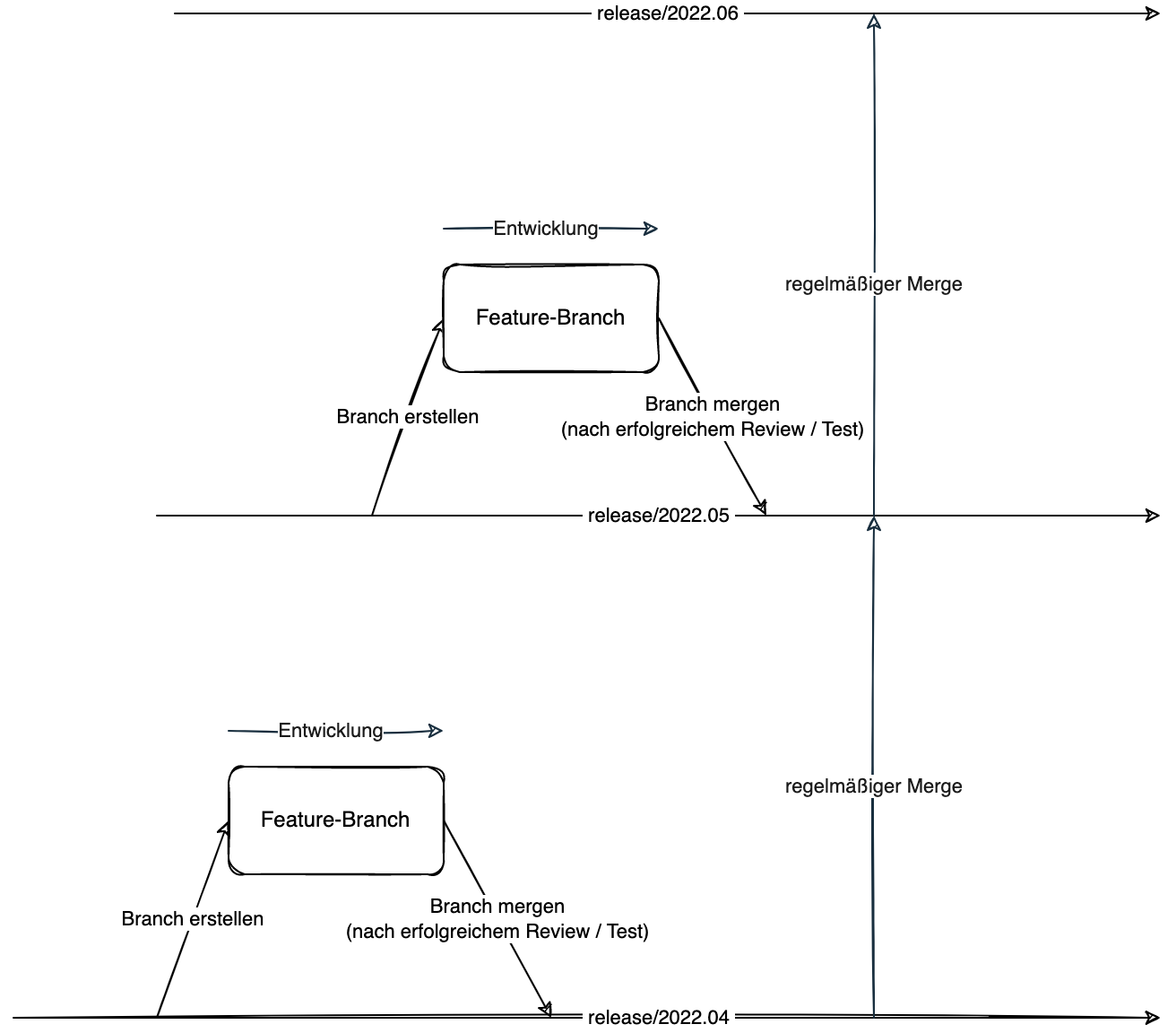
Ein einfaches Model von Self Healing Code
Das Ziel des selbstheilenden Codes ist es, die Notwendigkeit menschlicher Eingriffe zu minimieren und die Betriebszeit und Effizienz der Software zu maximieren. Dies kann durch die Implementierung von Überwachungs- und Diagnosefunktionen erreicht werden, die auf Anomalien oder Fehler hin überprüfen. Sobald ein Problem erkannt wird, wird versucht darauf zu reagieren, indem entweder eine Korrekturmaßnahme ausgeführt oder auf einen vorherigen stabilen Zustand zurückkehrt wird.
Defensive Programmierung
Eng verwandt mit Self Healing Code ist defensive Programmierung. Beides sind Praktiken, die dazu dienen, die Robustheit und Zuverlässigkeit von Software zu verbessern, aber sie tun dies auf unterschiedliche Weisen.
Defensive Programmierung ist eine Methode, bei der der Entwickler davon ausgeht, dass Probleme auftreten werden und daher Vorkehrungen trifft, um diese zu bewältigen. Dies kann beinhalten, dass überprüft wird, ob Eingaben gültig sind, bevor sie verwendet werden, Ausnahmen ordnungsgemäß behandelt werden und der Code so geschrieben wird, dass er leicht zu verstehen und zu warten ist.
Das Ziel der defensiven Programmierung ist es, die Anzahl der Fehler zu reduzieren und sicherzustellen, dass die Anwendung auch bei unerwarteten Eingaben oder Bedingungen korrekt funktioniert.
Selbstheilender Code hingegen geht einen Schritt weiter. Anstatt nur zu versuchen, Fehler zu vermeiden, versucht er, Fehler zu erkennen und zu beheben, wenn sie auftreten.
Bei der Betrachtung von Self Healing Code sollte auch defensive Programmierung Berücksichtigung finden. Diese kann dazu beitragen, die Anzahl der Fehler zu reduzieren, die auftreten können. Self Healing Code kann anschließend dazu beitragen, die Auswirkungen der Fehler zu minimieren, die trotzdem auftraten.
Implementation
Natürlich muss die gewünschte Funktionsweise der Selbstheilung bei der Entwicklung und dem Design einer Applikation und entsprechender Systeme berücksichtigt und implementiert werden.
Der erste Schritt ist die Fehlererkennung. Das bedeutet, dass die Applikation in der Lage sein muss, eventuelle Fehler und Probleme selbstständig zu erkennen. Hier können Applikationslogiken, Logs oder auch Überwachungssysteme genutzt werden.
Wird eine Anwendung oder ein Teil eines Softwaresystems überwacht, so müssen Schwellwerte definiert werden, welche definieren, ab wann die Services sich in einem kritischen Zustand befinden, damit darauf basierend Maßnahmen ergriffen werden können.
Präventiv und reaktiv
Die Fähigkeit der Selbstheilung kann in präventives und reaktives Handeln unterschieden werden. Beim präventiven Handeln werden gewisse Schlüsselindikatoren von der Applikation ausgewertet und darauf basierend eine Handlung ausgelöst.
So könnte eine Server-Applikation keine neuen Verbindungen mehr zulassen, wenn die CPU-Auslastung auf dem eigenen System zu hoch ist und somit einer Überlastung vorbeugen.
Reaktives Handeln ist vonseiten der Applikation immer dann notwendig, nachdem es zu einem Fehler gekommen ist. In diesem Fall muss die Applikation reagieren, um wieder einen funktionsfähigen Ablauf herstellen zu können.
Fehlerbeseitigung
Wurde ein Fehler erkannt, sollte er im nächsten Schritt behoben werden. Hier sind unterschiedliche Möglichkeiten denkbar, wie der Neustart eines Services oder das Ausweichen auf andere Datenquellen.
Dieser Prozess der Erkennung und Beseitigung von Fehlern und Problemen sollte ebenfalls automatisiert sein, sodass er ohne menschliche Einwirkung auskommt. Wird der Mechanismus aktiv, sollte ein Logging vorgenommen werden, damit dies später nachvollzogen werden kann.
Test und Dokumentation
Neben der Implementierung sollten selbstheilende Funktionalitäten auch regelmäßig getestet und gut dokumentiert werden, um bei Bedarf eine schnelle und effiziente Fehleranalyse zu ermöglichen.
Auch auf Sicherheitsaspekte sollte achtgegeben werden. Es sollte sichergestellt werden, dass die Maßnahmen zur Selbstheilung nicht von außen manipuliert oder missbraucht werden können.
Ein einfaches Beispiel
Wie könnte die Anwendung dieses Konzeptes aussehen? Ein heruntergebrochenes Beispiel unter Java könnte sich wie folgt darstellen:
public Connection connectToDatabase() {
Connection connection = null;
while (connection == null) {
try {
connection = DriverManager.getConnection(URL, USER, PASSWORD);
} catch (SQLException e) {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
// Ignore
}
}
}
return connection;
}
In der Methode connectToDatabase soll eine Datenbankverbindung erstellt und diese anschließend zurückgegeben werden. Tritt beim Aufbau der Verbindung eine Ausnahme auf, so wird versucht nach einer Wartezeit nochmals eine Verbindung aufzubauen, in der Hoffnung, dass der Fehler nur temporärer Natur war.
Damit wird dem Nutzer eine Alternative zu einem völligen Abbruch des Verbindungsversuches geboten. Im Idealfall, auch bei Auftreten eines Fehlers, wird ein verzögerter Aufbau der Verbindung ermöglicht. In der Praxis sollte dieses Beispiel allerdings in der vereinfachten Form nicht genutzt werden, da die Methode connectToDatabase niemals eine Antwort liefern würde, wenn die Datenbank nicht mehr antwortet. Hier ist es nötig, nach einer gewissen Zeit oder einer bestimmten Anzahl an Versuchen abzubrechen.
Methodiken und Pattern
Für die Bereitstellungen selbstheilenden Codes können unterschiedlichste Methodiken innerhalb einer Applikation genutzt werden, um dieses Konzept zum Erfolg zu führen.
Dies führt vom Einsatz von Entwurfsmustern wie dem Circut Breaker über die Möglichkeit zum Failover, den Neustart fehlerhafter Komponenten, oder die Nutzung von Read-Only-Mechanismen, bei verschlechternder Servicequalität.
Circut Breaker
Der Circuit Breaker ist ein Entwurfsmuster, welches verwendet wird, um Systeme zu schützen. Die Benamung ist nicht ohne Grund so gewählt, da er wie eine Sicherung die Verbindung zu einem System kappt, wenn bestimmte Kriterien erfüllt sind.
Dies kann z. B. eine definierte Fehlerrate in einem bestimmten Zeitraum sein. Ein Beispiel wäre ein Webservice, welcher wiederholt auf Anfragen nicht antwortet. Der Aufrufer könnte nun versuchen immer und immer wieder Anfragen zu senden, was dazu führen kann, dass das System im schlimmsten Fall unter der Last zusammenbricht.
Hier greift der Circut Breaker ein und unterbricht die Verbindung. Indessen kann in der Anwendung auf den Fehler reagiert werden, die Anfrage z. B. zu einem späteren Zeitpunkt wiederholt werden.
Meist wird nach einer Cooldown-Phase die Verbindung zum Service wieder aufgenommen. Treten hierbei wieder Fehler auf, so wird der Circut Breaker die Verbindung erneut trennen und der Prozess beginnt von vorn.
Auch in der Applikation selbst führt dies zu positiven Effekten, da nicht mehr auf die entsprechende Verbindung gewartet werden muss und eventuell dafür genutzte Threads und weitere Ressourcen für diesen Moment abgewickelt werden können.
Failover
Eine weitere Möglichkeit für Self Healing Code ist die Implementierung von Failover-Verfahren unter der Bereitstellung von Redundanz. Grundsätzlich bedeutet dies, dass auf andere Systeme umgeschaltet wird, wenn das angefragte System ausfällt.
Dies kann bedeuten, dass im Falle eines nicht oder fehlerhaft antwortenden Webservices, eine andere Instanz des Webservices genutzt wird.
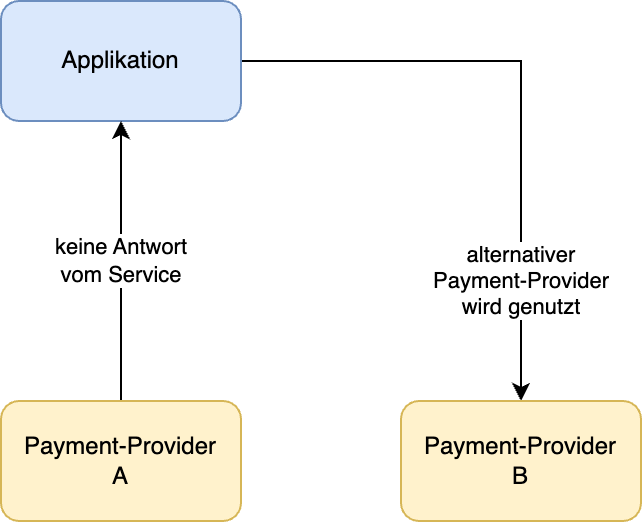
Ein Rückfall auf einen alternativen Payment-Provider sichert den Geschäftsprozess ab
Daneben sind auch andere Szenarien denkbar. So konnte die eigene Applikation einen Payment-Provider nutzen. Bei einem Ausfall könnte dies ein geschäftskritisches Problem darstellen. Als Failover-Variante kann auf einen zweiten unabhängigen Payment-Provider umgeschwenkt werden, bis der primäre Provider wieder verfügbar ist.
Ziel ist es beim Failover, die Ausfallzeiten zu minimieren und die Verfügbarkeit zu gewährleisten. Aus Sicht eines Nutzers würde ein solcher Ausfall eines Service zu keinem veränderten Ergebnis führen.
Änderung in der Applikationslogik
Eine weitere Möglichkeit innerhalb einer Applikation auf Probleme zu reagieren, ist es Änderung in der eigentlichen Logik vorzunehmen. Beispielhaft könnte von einem externen Webservice eine Route anhand gewisser Parameter geliefert werden.
Fällt dieser Service aus, könnte die Anwendung stattdessen intern eine Route mit einem vereinfachten Algorithmus berechnen. Das Ergebnis ist qualitativ nicht unbedingt mit dem des externen Service zu vergleichen, allerdings kann es aus Sicht des Nutzers trotzdem ausreichend sein, falls der Webservice nicht zur Verfügung steht.
Limiter
Eine weitere Klasse nützlicher Methodiken sind Limiter. So begrenzt ein Rate Limiter die Anzahl der Anfragen, die ein Nutzer in einem bestimmten Zeitraum senden kann. Dies ist besonders nützlich in Szenarien, in denen Systemressourcen begrenzt sind oder um versehentliche Denial-of-Service-Angriffe zu verhindern.
Daneben existieren weitere Limiter, wie der Time Limiter welcher die Zeit begrenzt, die ein bestimmter Prozess zur Ausführung nutzen kann. Wenn der Prozess die zugewiesene Zeit überschreitet, wird er abgebrochen oder eine Ausnahme wird ausgelöst. Dies kann eine Möglichkeit darstellen, Timeouts zu realisieren.
Let It Crash
Aus einer übergeordneten Sicht kann es sinnvoll sein, Services abstürzen zu lassen, wenn es zu schwerwiegenden Problemen kommt. Je nachdem, wie das System gestaltet ist, wird der Service anschließend wieder gestartet und hochgefahren.
Erlang ist ein anschauliches Beispiel für diese Let It Crash-Philosophie. Sie führt dazu, dass sobald ein Prozess auf einen Fehler stößt, dieser beendet wird, anstatt den Fehler zu beheben. Andere, überwachende Prozesse können anschließend entscheiden, wie sie auf den Absturz reagieren, oft indem sie den fehlerhaften Prozess neu starten.
Hier gibt es im Service selbst keinen selbstheilenden Code, sondern es wird sich auf die Gesamtarchitektur des Systems verlassen, welche dafür sorgt, dass der Dienst wieder neu gestartet wird oder das Problem auf andere Art und Weise behoben wird.
Hier muss darauf geachtet werden, dass die Applikationen auf diesen Fall vorbereitet sein müssen. So müssen z. B. Verbindungen wieder aufgenommen werden, nachdem der jeweilige Service wieder verfügbar ist.
Caches
Auch Caches können im Rahmen selbstheilender Anwendungen nützlich sein. Wenn eine Information nicht vom externen Service bezogen werden kann, kann unter Umständen die letzte gecachte Antwort für die Anforderung genutzt werden.
Dies ist natürlich nur in solchen Fällen möglich, in denen der Cache für die gewünschte Anfrage vorhanden ist und sichergestellt werden kann, dass die gespeicherte Antwort den Anforderungen an die benötigte Aktualität gerecht wird.
Veränderung der Servicequalität
Wer Dienste entwickelt und betreibt, kann weitere Funktionalitäten implementieren, um zumindest ein Teil eines Dienstes noch funktionsfähig zu halten. So kann ein entsprechender Service z. B. in einen Read-Only-Modus gesetzt werden, wenn Schreibzugriffe aufgrund eines Fehlers aktuell nicht funktionieren.
Da in den meisten Fällen Lesezugriffe einem Schreibzugriff überwiegen, können in einem solchen Read-Only-Modus viele der Anfragen immer noch erfolgreich beantwortet werden.
Das dahinter liegende Konzept ist es, die Funktionalität, welche noch zur Verfügung steht, dem Aufrufer zur Verfügung zu stellen, anstatt den Betrieb komplett einzustellen. So können einzelne Features im Fehlerfall abgeschaltet werden, anstatt den kompletten Service zu deaktivieren.
Allerdings müssen die aufrufenden Applikationen hierauf vorbereitet sein und damit umgehen können.
Retry
Wie bereits im Beispiel oben demonstriert, können wiederholte Versuche einen Service aufzurufen, eine Möglichkeit sein, Systeme fehlertolerant und selbstheilend zu gestalten. Dies ist vorwiegend bei Problemen temporärer Natur wie kurzzeitigen Netzwerkausfällen oder einer Überlastung nützlich.
Dieses Muster kann jedoch komplexer werden, abhängig von den Anforderungen der Anwendung. Es kann unter anderem notwendig sein, die Wartezeit zwischen den Wiederholungsversuchen zu erhöhen oder bestimmte Arten von Fehlern von den Wiederholungsversuchen auszuschließen.
Auch zu häufige Wiederholungen sollten ausgeschlossen werden, damit z. B. im Falle einer Überlastung der aufgerufene Service nicht weiter belastet wird.
Timeouts
Ein weiterer wichtiger Punkt bei selbstheilendem Code und fehlertoleranten Architekturen sollten Timeouts sein. Operationen wie Netzwerk oder IO sollten immer mit einem Timeout versehen werden, damit niemals der Fall entsteht, dass auf unbestimmte Zeit auf Ressourcen gewartet wird.
Ähnliche Verfahren lassen sich in der Theorie auch anwenden, wenn längere Berechnungen getätigt werden. In einigen Fällen ist es hier sinnvoll, einen Timeout zu definieren.
Grundsätzlich sollte es immer das Ziel sein, endlose Warteschleifen zu vermeiden und Systemressourcen wie CPU oder Speicher wieder freizugeben. Auch erhält die Anwendung durch Timeouts eine gewisse Art an Kontrolle, da durch diese klar wird, wie lange bestimmte Prozesse maximal laufen dürfen.
Aus Sicht des Nutzers sind Timeouts hilfreich, da dieser nicht unnötige Wartezeiten in Kauf nehmen muss und eine zeitnahe Rückmeldung erhält, wenn auch im schlechtesten Fall in Form einer Fehlermeldung.
Ein interessanter Nebeneffekt ist, dass Timeouts teilweise zur Fehlersuche genutzt werden können. Wenn bestimmte Anforderungen ständig zu Timeouts führen, könnte dies auf ein tiefer liegendes Problem hinweisen, das analysiert werden sollte.
Tooling
Viele der beschriebenen Mechanismen können von Grund auf vom Entwickler implementiert werden. Allerdings existieren eine Reihe von Bibliotheken und Frameworks welche einen Teil dieser Arbeit abnehmen.
In der Java-Welt liefern Frameworks z. B. Spring Boot, Möglichkeiten für eine robuste Fehlerbehandlung. Bibliotheken, wie Resilience4j, bieten Lösungen für Selbstheilungsfunktionen und Fehlertoleranz. Sie ermöglicht es Entwicklern, selbstheilende Muster zu implementieren, wie Circut Breaker oder Fallback-Mechanismen, um Ausfälle effektiv zu behandeln.
Damit wird es einfacher und bequemer, selbstheilenden Code zu implementieren.
Self Healing Code in der Zukunft
Neben den klassischen Methoden, um selbstheilenden Code zu realisieren, werden in letzter Zeit immer mehr Varianten von Self Healing Code in Verbindung mit generativer KI postuliert, wie dem Large Language Model GPT-4.
Während die bisherigen Beispiele selbstheilender Systeme auf die Laufzeit abzielten, existieren auch Verfahren und Ideen, generative KI zu Nutzung bei der Entwicklung einzusetzen, um Quellcode „ohne Mitwirkung des Entwicklers“ zu realisieren.
Mittelfristig sind Systeme im breiten Einsatz denkbar, welche die Codebasis eines Projektes analysieren und basierend darauf Änderungen generieren, welche anhand von Pull-Requests dem menschlichen Entwickler vorgeschlagen werden können.
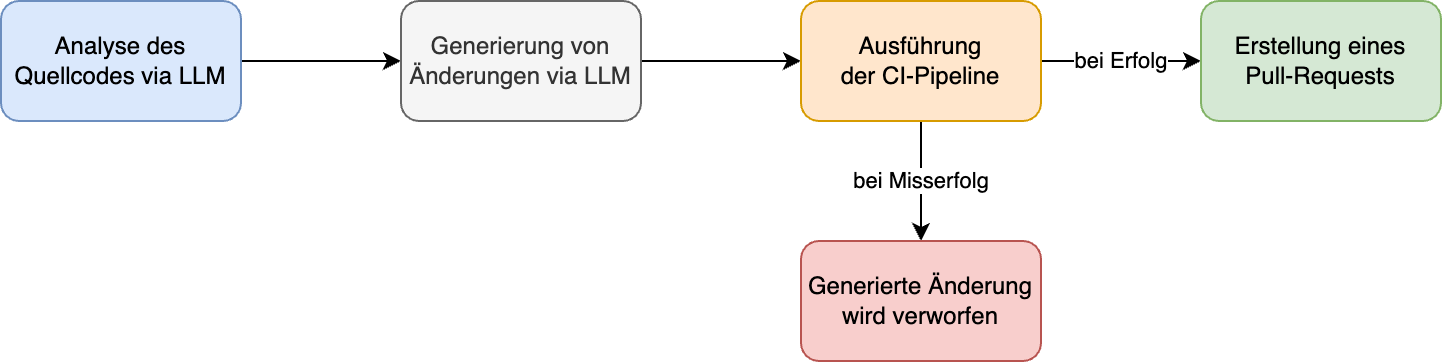
Ein Workflow zur Erzeugung automatisierter Änderungen via LLM
Damit bei den automatisiert erstellten Änderungen möglichst sichergestellt wird, dass sie auch funktionieren, können die Änderungen durch eine Continuous Integration-Pipeline entsprechenden Tests unterworfen werden. Nur wenn die Pipeline erfolgreich durchläuft, werden die Änderungen dem Entwickler vorgeschlagen.
So nutzt Microsoft mit InferFix ein System zur semiautomatischen Fehlerbehebung, um den Arbeitsablauf für interne Projekte zu verbessern. Auch andere Firmen, wie Stackoverflow, denken ebenfalls über die Nutzung von LLMs und generativer KI im Rahmen der Softwareentwicklung nach.
Automatisiertes Debugging
Solche „selbstheilenden Fähigkeiten“ können auch für die komplett automatische Fehlerbehebung genutzt werden. So existiert mit Wolverine ein Proof of Concept für ein solches System. Wolverine nutzt GPT-4 von OpenAI, um Fehler in einem Python-Skript zu reparieren.
Dabei werden Fehler im Skript in das Sprachmodell gegeben und anschließend die Lösung auf den Quelltext angewendet. Danach wird ermittelt, ob das Skript nach der Änderung funktioniert. Treten erneut Fehler auf, werden diese wieder an das LLM übermittelt und dessen Lösung wieder in das Skript übernommen.
Solche Verfahren könnten weitergedacht und direkt beim Nutzer, im Falle eines Fehlers, ausgeführt werden.
Auch in IDEs ziehen Plugins basierend auf generativer KI ein, wie das AI Assistant-Plugin von Jetbrains. Mit diesem können Fehlermeldungen und Codeteile analysiert und erklärt und eine weitere Interaktion mit den Sprachmodellen durchgeführt werden. Dazu zählen unter anderem das Generieren von Dokumentation, sowie von Namen.
Probleme
Im Idealfall können solche Systeme eine Arbeitserleichterung sein, allerdings führen sich auch zu Problemen. So ist nicht sichergestellt, dass die von der KI gefundenen Lösungen wirklich die geforderten fachlichen Spezifikationen erfüllen. Daneben kann sich die Codequalität verschlechtern, wenn solche Änderung ungeprüft übernommen werden.
Hier könnte es im Laufe der Zeit vorkommen, dass aus Bequemlichkeit dazu übergegangen wird, solche Änderungen automatisiert auf den Quellcode anzuwenden.
Auf lange Sicht kann dies dazu führen, dass die eigene Codebasis immer schlechter verstanden wird, wenn diese generativer KI „gepflegt“ wird und diese Änderungen ohne ein sinnvollen Reviewprozess übernommen werden. Es ist denkbar, dass sich die Verantwortlichkeit von der eigentlichen Implementation des Quellcodes immer mehr in Richtung des Reviews verschiebt.
Wenn es an den Einsatz generativer KI geht, müssen neben solchen Fragen auch datenschutzrechtliche und sicherheitstechnische Aspekte bedacht werden.
Auch sollte beachtet werden, dass generative KI, wie die meistgenutzten Modelle von OpenAI Kosten verursachen, welche meist je Token abgerechnet werden. Werden lokale Modelle genutzt, muss stattdessen Rechenleistung und dahinterstehende Infrastruktur bereitgestellt werden.
Daneben existieren Größenbeschränkungen. Modelle wie solche von OpenAI sind bezüglich der maximal verarbeitbaren Token beschränkt, sodass größere Quelltext auf diese Art und Weise nur schwer am Stück analysiert werden können.
In Bezug auf selbstheilenden Code und Systeme kann ein blindes Vertrauen zu erheblichen Problemen führen.
Beispielhaft könnte ein System nur bestimmte Datentypen verarbeiten. Wenn ein solches Datenfeld vom Typ Integer ist und der Nutzer nun stattdessen Zeichenketten sendet, würde die Anwendung dies ablehnen. In einem solchen Fall könnte ein auf KI basierendes System zur Behebung dieses Fehlers den Typ der Schnittstelle, so ändern, dass auch Zeichenketten erlaubt sind und somit weiteren Problemen die Tür öffnen.
Fazit
Self Healing Code bietet eine Reihe von Vorteilen, im Betrieb der Anwendungen und sollte beim Design entsprechender Applikationen und Systeme berücksichtigt werden.
So sind diese Systeme zuverlässiger, bieten erhöhte Verfügbarkeit, und verringern eventuelle Downtimes. Auch in der Wartung können solche Systeme günstiger sein.
Allerdings sollten die Schwierigkeiten bedacht werden. Die Entwicklung von selbstheilendem Code kann komplex sein. Es kann eine Herausforderung darstellen, effektive Mechanismen zur Fehlererkennung, Diagnosealgorithmen und Strategien zur Fehlerbehebung zu entwickeln, die reibungslos miteinander interagieren.
Daneben bedeutet Self Healing Code in vielen Fällen auch ein Overhead. Unter Umständen werden zusätzliche Systemressourcen, für die Erkennung und die Beseitigung von Problemen, benötigt.
Wenn fälschlicherweise Fehler erkannt werden und die selbstheilenden Mechanismen aktiv werden, kann dies problematisch sein. Dazu gehören die Schwierigkeit, solche Systeme zu testen und zu überprüfen, und die Möglichkeit, dass das System unvorhersehbare oder unerwünschte Änderungen vornimmt.
Neben dem klassischen selbstheilenden Code hält generative KI immer mehr Einzug in unseren Alltag und dies wird auch in Verbindung mit Self Healing Code keine Ausnahme sein. Allerdings sollte hier Vorsicht geboten sein und der Mensch nicht aus dem Loop genommen werden.
Self Healing Code hat das Potenzial, die Zuverlässigkeit und Verfügbarkeit von Systemen zu verbessern und dieses Potenzial sollte nicht brach liegen gelassen werden.