Unendliche Mannigfaltigkeit in unendlicher Kombination. Frei nach diesem Grundprinzip der vulkanischen Philosophie könnte der geneigte Nutzer auch die Vielfalt der Dateimanager betrachten.
Neben den mit den Betriebssystemen mitgelieferten Dateimanagern, wie dem Explorer unter Windows oder dem Finder unter macOS, existieren viele weitere Dateimanager, mit teils recht unterschiedlichen Herangehensweisen.
Eine Klasse von Dateimanagern stellen die orthodoxen Dateimanager, auch Zwei-Panel-Datei-Manager genannt, dar. Diese nutzen ein Konzept, welches insbesondere dann seine Vorteile ausspielt, wenn viel und oft mit Dateien gearbeitet wird und eine flexible Arbeitsweise gewünscht ist.
Mit ihrer charakteristischen Zwei-Panel-Architektur und tastaturzentrierten Bedienung bieten sie eine Effizienz, die moderne grafische Dateimanager selten erreichen.
Definition
Orthodoxe Dateimanager verdanken ihre Bezeichnung nicht einer religiösen Konnotation, sondern ihrer Treue zu den etablierten Designprinzipien des Norton Commander, welcher erstmals 1986 erschien.
Der Begriff Orthodox File Manager (OFM) wurde durch Nikolai Bezroukov 1996 geprägt und bezeichnet die standardisierte Implementierung der Zwei-Panel-Philosophie:
I introduced the term „orthodox file managers“ in 1996 (see OFM Bulletin 1998) …
Das zentrale Element eines orthodoxen Dateimanagers sind zwei symmetrische Verzeichnisfenster (Panels), die es ermöglichen, Dateien direkt zwischen Quell- und Zielverzeichnis zu verwalten. Eines der beiden Panels ist aktiv (Quelle), das andere passiv (Ziel). Sämtliche Befehle beziehen sich auf dieses Verhältnis.
OFMs bieten einen einheitlichen Funktionsumfang: Kopieren, Verschieben, Löschen und Umbenennen über klar strukturierte Menüs und vordefinierte Shortcuts.
Die vollständige Tastaturbedienung steht im Vordergrund und erlaubt es, sämtliche Operationen ohne Maus durchzuführen. Die Belegung entspricht auch heute noch größtenteils denen des Norton Commanders:
F1: Hilfe
F2: Benutzermenü
F3: Datei betrachten
F4: Datei bearbeiten
F5: Kopieren
F6: Verschieben/Umbenennen
F7: Verzeichnis erstellen
F8: Löschen
F9: Menüleiste aktivieren
F10: Beenden
Tab: Zwischen Panels wechseln
Einfügen: Dateien markieren
Auch Archivformate wie ZIP oder TAR werden meist direkt unterstützt, oft so, als wären sie normale Verzeichnisse. Hierbei ist die Rede von virtuellen Dateisystemen. Diese abstrahieren verschiedene Speicherquellen, Archive, FTP-Server oder Cloud-Speicher und binden sie transparent als Verzeichnisse ein.
Ergänzt wird dieser Ansatz durch integrierte Dateibetrachter und Editoren, sodass viele Aufgaben innerhalb des Dateimanagers, ohne einen Rückgriff auf andere Anwendungen, erledigt werden können.
Orthodoxe Dateimanager sind eng mit der nativen Shell des Systems verbunden. Pfade und Befehle lassen sich direkt, innerhalb des Dateimanagers, an die Kommandozeile übergeben.
Trotz der Standardisierung der Kommandos und des generellen Aussehens ist die Anpassbarkeit ein weiteres Merkmal orthodoxer Dateimanager. Tastenkombinationen, Menüstrukturen und das Erscheinungsbild lassen sich in vielen Fällen an persönliche Bedürfnisse anpassen.
Spezifikationen
Nikolai Bezroukov prägte nicht nur den Begriff des orthodoxen Dateimanagers, sondern überführte diese Philosophie in einige Spezifikationen.
Die OFM-Spezifikation von 1999 hatte das Ziel, diese Philosophie zu standardisieren. Sie legt Grundfunktionen und Interaktionsmuster fest, um eine langfristig tragfähige Basis für Entwickler und Anwender zu schaffen.
Nach dem ursprünglichen OFM-Standard von 1999 wurde im Jahr 2004 eine Erweiterung veröffentlicht.
Ziel war es, neben dem fest etablierten Grundkonzept auch fortgeschrittene Funktionen wie Filter, benutzerdefinierte Sortierung und Archivverwaltung zu normieren.
Die letzte Erweiterung stammt aus dem Jahr 2012. Zu den wesentlichen Erweiterungen zählen flexible Panel-Größen, erweiterte Skriptintegration mit Variablenzugriff sowie die Vorbereitung auf Funktionen wie Tabs und Plugin-gesteuerte Dateiansichten.
Um übermäßige Komplexität zu vermeiden, wurden nur Features aufgenommen, die sich in mindestens einem Jahr realer Nutzung bewährt hatten.
Seitdem wurde die Spezifikation nicht weiter überarbeitet. Dennoch lieferte sie wichtige Impulse und eine Orientierung für die Praxis.
Geschichte
Einer der ersten Dateimanager mit textbasierter, aber visuell strukturierter Oberfläche war PathMinder von Albert Nurick und Brittain Fraley. Dieser erschien im Jahr 1984. Einen Monat nach der Veröffentlichung erschien mit DualView ebenfalls ein textbasierter Dateimanager.
Mit XTree erschien 1985 ein weiterer Vertreter, welcher ähnlich wie PathMinder eine Art Baumstruktur darstellte.
Der De-facto-Standard der orthodoxen Dateimanager wurde 1986 mit dem Norton Commander definiert, der durch geschicktes Marketing und technische Verfeinerung stilbildend wirkte.
Gestartet wurde die Arbeit am Norton Commander von John Socha im Jahr 1986. Zu dieser Zeit trug das Projekt den Namen Visual DOS bzw. VDOS:
I started work on what became known as the Norton Commander in the fall of 1984 while I was still a graduate student in Applied Physics at Cornell University. The first versions were entirely in assembly language, but that was too time-consuming, so I soon switched to a blend of C and assembly language at a time when most „real programmers“ wouldn’t touch C.
At the time I called it Visual DOS, with the abbreviation of VDOS instead of the usual two-letter abbreviations used at the time.
Norton Commander 1.0 erschien im Mai 1986 und definierte die Grundprinzipien, die bis heute Gültigkeit haben. Auch bot er erstmals einen integrierten Viewer und Editor, wodurch komplette Workflows ohne Anwendungswechsel möglich wurden.
Die Version 3.0 von 1989 gilt als Höhepunkt der DOS-Ära mit Hypertext-Hilfe und dem legendären Sternenhimmel-Bildschirmschoner.
Inspiriert vom Norton Commander erschienen ab Ende der 1980er-Jahre weitere orthodoxe Dateimanager wie der Volkov Commander oder der DOS Navigator.
In der Unix- bzw. Linux-Welt entstand 1994 mit dem Midnight Commander, von Miguel de Icaza, einer der bekanntesten orthodoxen Dateimanager.
Auch für Systeme wie OS/2 wurden orthodoxe Dateimanager entwickelt, wenngleich diese heute nur noch eine geringe Nutzerschaft aufweisen.
Vom Terminal zur GUI
Neben den textbasierten orthodoxen Dateimanagern entstanden mit dem Aufkommen von Windows auch grafische Umsetzungen dieses Konzepts.
Hier sind Entwicklungen wie der Windows Commander (1993), welcher später zum Total Commander wurde, sowie die Umsetzung des Norton Commander für Windows (1998) zu nennen.
Unter Linux entstanden grafische OFMs, wie der GNOME-Commander und Krusader.
OFMs im Einzelporträt
Heutzutage werden eine Vielfalt von orthodoxen Dateimanagern für unterschiedliche Systeme aktiv entwickelt und vorangetrieben.
Neben den hier vorgestellten orthodoxen Dateimanagern existieren unzählige weitere – von kleineren Prototypen bis zu ausgewachsenen kommerziellen Varianten.
Grundsätzlich müssen zwei Formen unterschieden werden. Die klassischen auf einer Terminal UI (TUI) basierten Dateimanager und die auf einer grafischen UI (GUI) basierten Dateimanager.
TUI-basierte Implementationen
Zu den TUI-basierten Implementationen würde aus heutiger Sicht auch der Norton Commander gehören.
Selbst im Zeitalter grafischer Systeme und Bildschirmauflösungen jenseits der 4K haben solche Dateimanager nach wie vor ihre Berechtigung.
Sei es auf der Nutzung im Terminal oder auf entfernten Rechnern per SSH.
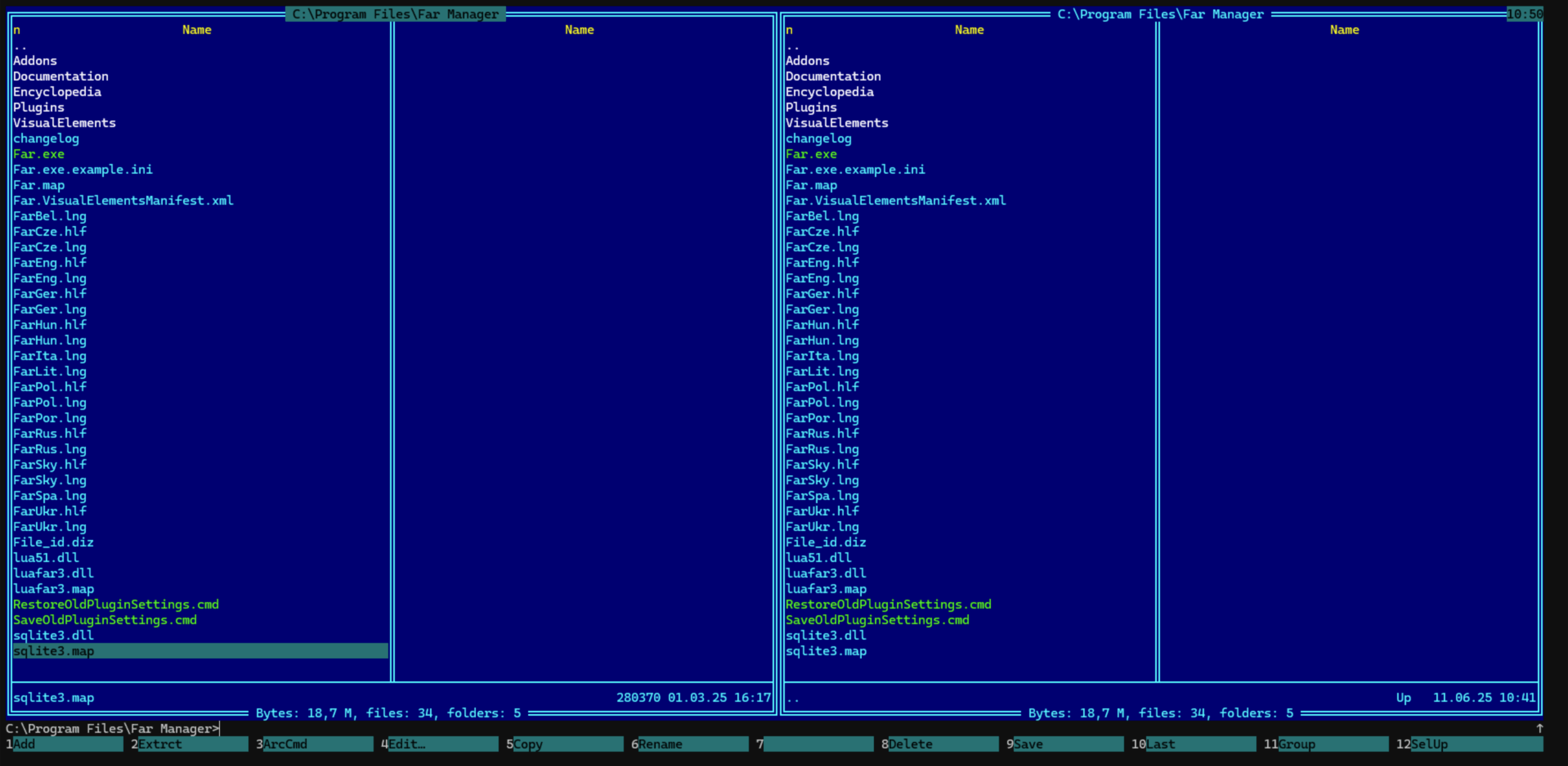
Far Manager
Der Far Manager wurde 1996 von Eugene Roshal, seines Zeichens Schöpfer des RAR-Formats, entwickelt. Seit 2007 ist er freie Software unter der modifizierten BSD-Lizenz und wird aktiv entwickelt.
Er ist ein textbasierter orthodoxer Dateimanager für Windows, der die Tradition des Norton Commanders in die moderne Windows-Ära überträgt.
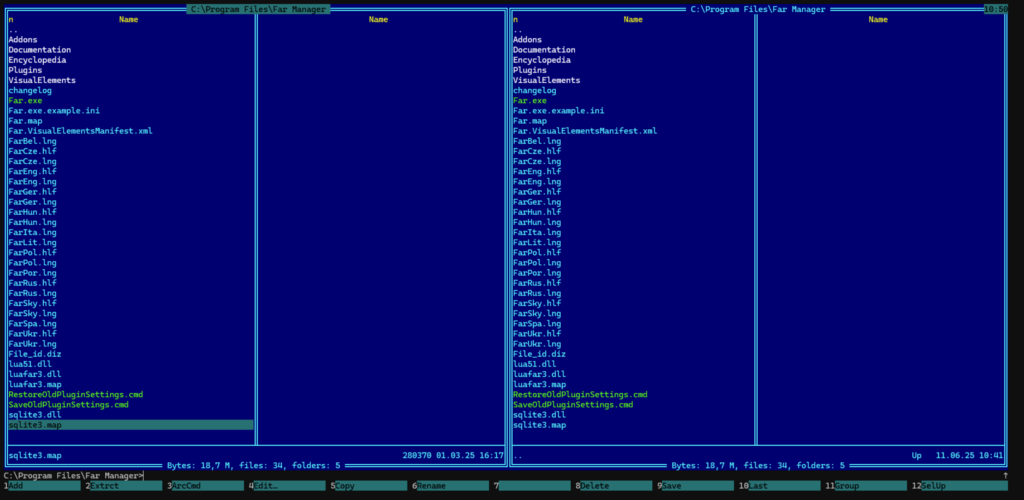
Der Far Manager erinnert an den Norton Commander
Die Zwei-Panel-Struktur wird durch eine Kommandozeile am unteren Rand ergänzt, die eine direkte Ausführung der Befehle ermöglicht. Dabei wird eine Art Autovervollständigung geboten.
Die Oberfläche unterstützt verschiedene Farbschemata und kann detailliert angepasst werden. Moderne Features wie Drag & Drop innerhalb des Dateimanagers werden, trotz der Konsolennatur, unterstützt.
Daneben verfügt der Far Manager über einen integrierten Text-Editor sowie einen Viewer. Auch die Unterstützung für Archiv-Formate und deren Einbindung ist gegeben.
Mit seinem umfangreichen Plugin-System und der Fokussierung auf Effizienz richtet er sich an erfahrene Anwender.
Verfügbar ist der Dateimanager für Windows, jeweils in einer x64 und einer ARM64-Version. Es existiert auch eine Linux-Portierung des Managers.
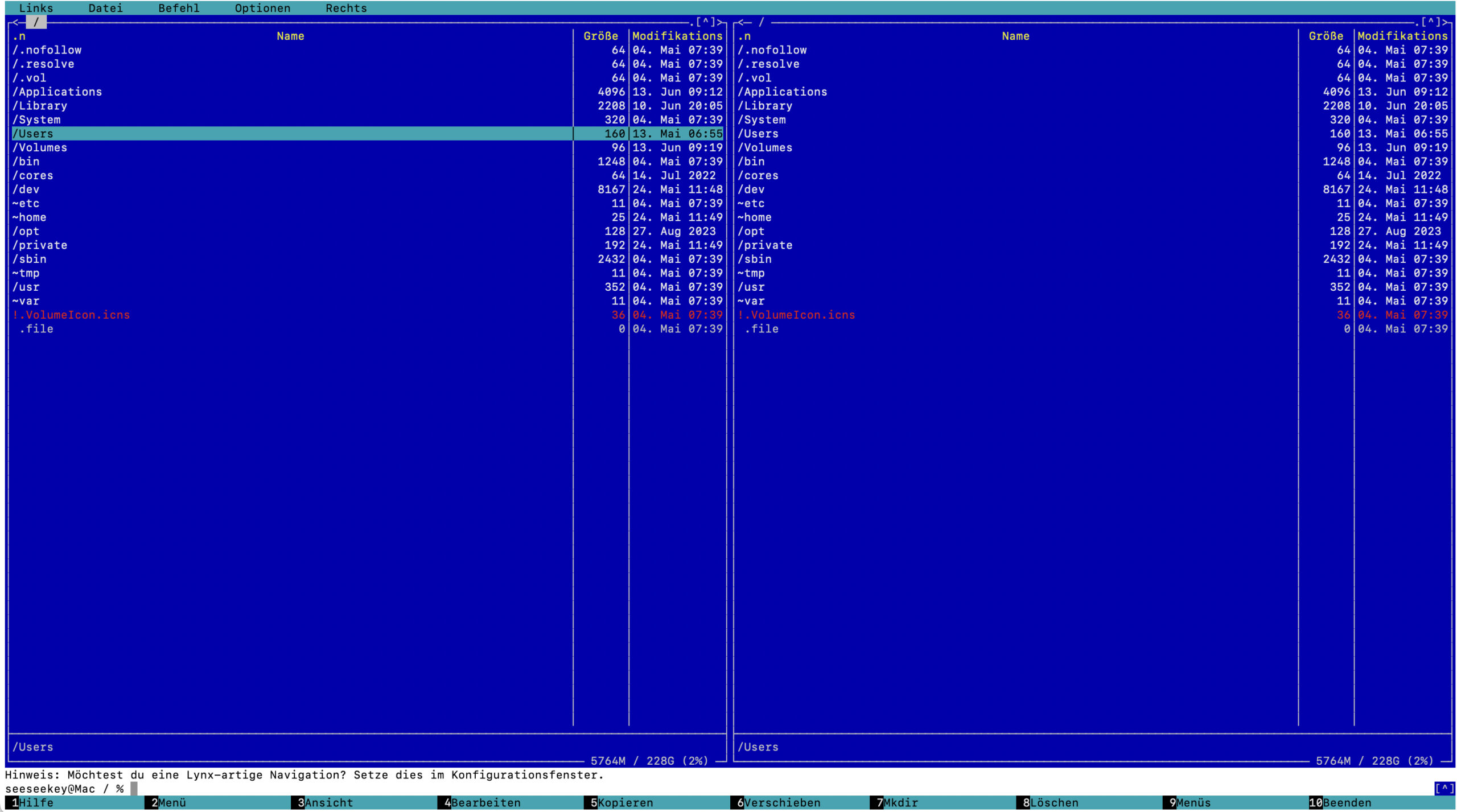
Midnight Commander
Der Midnight Commander gilt auf dem Terminal unter Unix- und Linux-Systemen als Standard-OFM. Erstmalig veröffentlicht wurde er im Jahre 1994 durch Miguel de Icaza, welcher später das GNOME-Projekt mitbegründete.
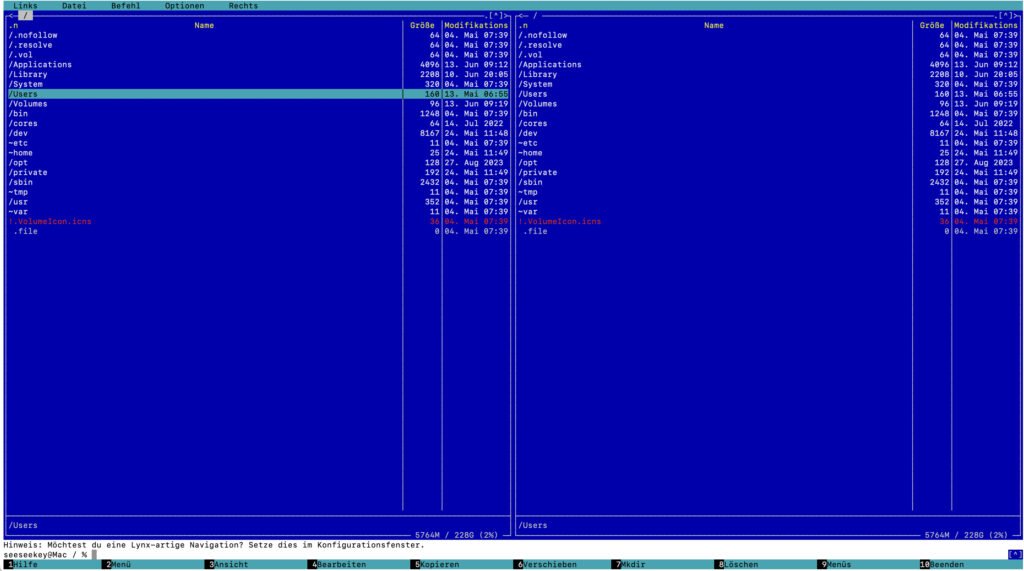
Der Midnight Commander unter macOS
Als GNU-Software unter der GPL in Version 3 veröffentlicht, läuft er in Textterminals und bietet seine volle Funktionalität sowohl lokal als auch über SSH-Verbindungen.
Seine Entwicklung kam mehrere Jahre zum Erliegen, aber seit 2009 wurde er mit der Version 4.6.2 wieder aktiv weiterentwickelt.
Die VFS-Implementierung unterstützt SSH, SFTP, FTP und zahlreiche Archivformate.
Für die direkte Arbeit mit Dateien steht ein eingebauter Texteditor zur Verfügung. Er bietet unter anderem Syntax-Highlighting für viele Programmiersprachen.
Ergänzt wird der Editor durch einen Viewer, der Text- und Binärdateien unterstützt. Die integrierte Suchfunktion hilft beim Auffinden von Dateien im Verzeichnisbaum. Die Farbgebung ist anpassbar, und verschiedene Skins stehen zur Verfügung.
Trotz der text-basierten Natur bietet der Midnight Commander eine Maus-Unterstützung in modernen Terminal-Emulatoren.
Unter Linux-Systemen kann der Midnight Commander über den Paketmanager installiert werden. Für macOS gilt das Gleiche, etwa über Homebrew. Daneben existiert mit mcwin32 eine Windows-Portierung des Dateimanagers.
GUI-basierte Implementationen
Neben den terminal-basierten Implementationen existiert eine große Auswahl an GUI-basierten Implementationen des OFM-Paradigmas.
Linux
In der Linux-Welt existierten einige historische OFMs, wie der Tux Commander, emelFM2 oder Sunflower, welche mittlerweile mehr oder weniger inaktiv sind. Gleichzeitig existieren dort aktiv weiterentwickelte orthodoxe Dateimanager.
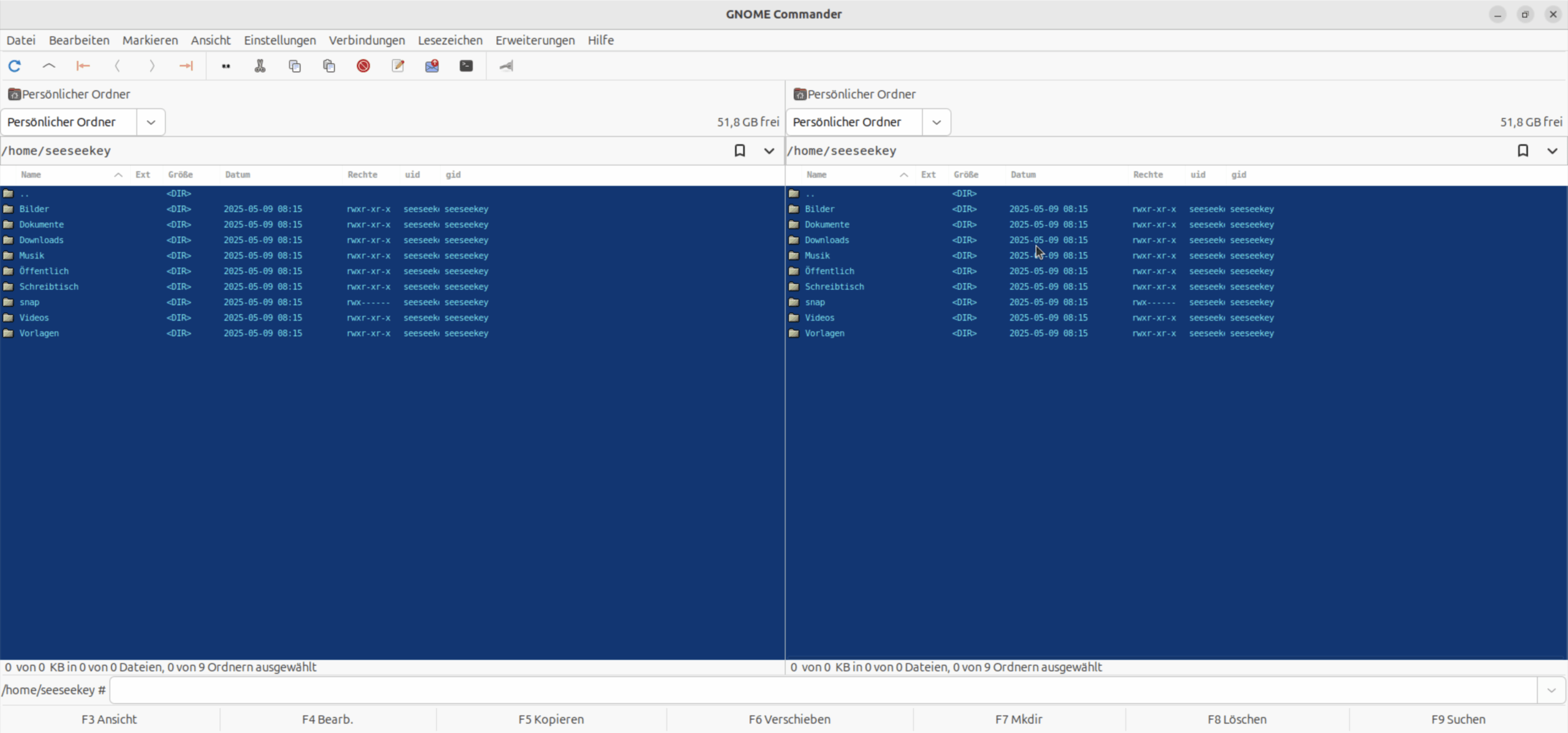
GNOME Commander
Der GNOME Commander wurde ursprünglich 2001 vorgestellt und richtet sich an Nutzer der GNOME-Desktop-Umgebung. Die Anwendung ist in C++ geschrieben und nutzt GTK für die grafische Oberfläche. Interessant ist dass mittlerweile eine Reimplementation in Rust vorgenommen wird.
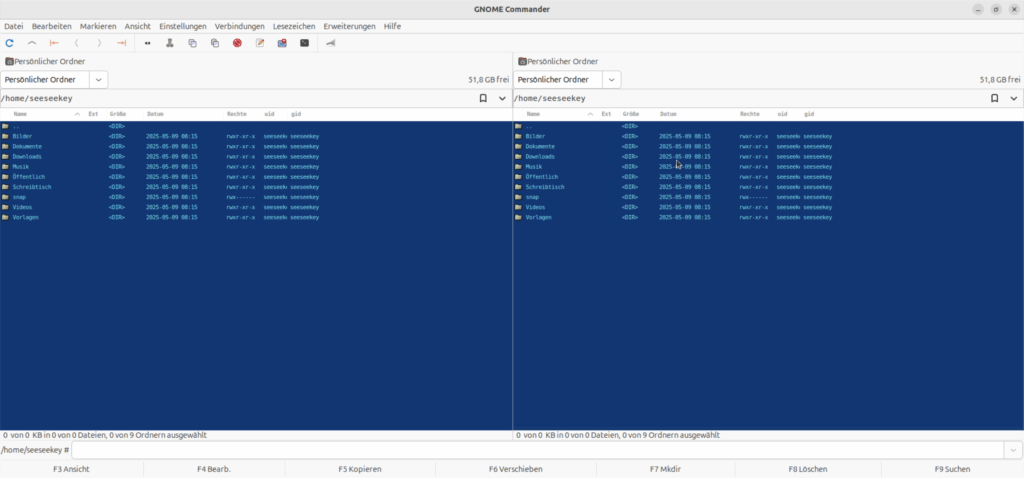
GNOME Commander unter Ubuntu
GNOME Commander integriert sich gut in GTK-basierte Desktop-Umgebungen. Standardmäßig glänzt er in einem Norton Commander-Blau.
Der Dateimanager ist eng in die GNOME-Desktopumgebung integriert und nutzt das zugrunde liegende GIO-Framework als Abstraktionsschicht für Dateien und andere Ressourcen.
Der Archivzugriff ist im GNOME Commander nicht so komfortabel gelöst wie in anderen orthodoxen Dateimanagern, da sie hier auf externe Tools verlassen wird und keine Integration in ein virtuelles Dateisystem erfolgt.
Daneben bietet der Dateimanager Unterstützung für erweiterte Dateiattribute, darunter Eigentümer, Benutzergruppen, Zugriffsrechte und Zeitstempel.
Ein Lesezeichen- und Favoritensystem erlaubt es, häufig genutzte Pfade als Schnellzugriffe zu speichern und wieder aufzurufen.
Weiterhin unterstützt der Dateimanager entfernte Verbindungen, was den Zugriff auf SSH-, SFTP-, FTP-, SMB-, sowie WebDAV-Server ermöglicht.
Das Projekt ist unter der GPL in Version 2 lizenziert und wird aktiv auf GitLab gepflegt.
Installiert werden kann der GNOME Commander über den jeweiligen Paketmanager der Linux-Distribution.
Krusader
Krusader wurde im Jahr 2000 vorgestellt und bietet eine moderne, grafische Interpretation der orthodoxen Dateimanager-Philosophie. Die Oberfläche integriert sich nahtlos in KDE und nutzt dessen Design-Sprache. Tabs, Toolbars und Kontextmenüs sind vollständig anpassbar.
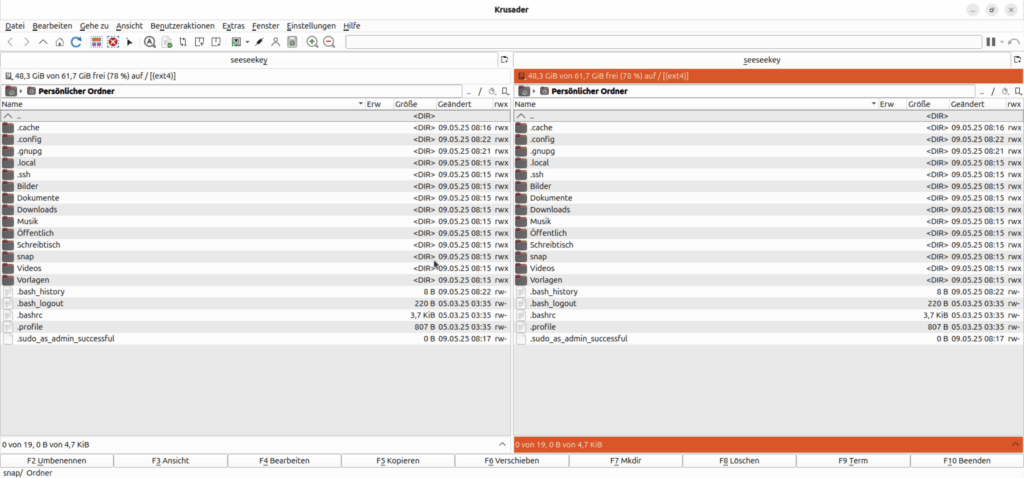
Krusader unter Ubuntu
Die C++-Implementierung nutzt KDE-Frameworks, was den Zugriff auf verschiedenste Dateisysteme und Ressourcen ermöglicht. Dadurch lassen sich Netzwerkpfade und Archive wie reguläre Ordner behandeln.
Die Archiv-Unterstützung ist dank der KDE-Bibliotheken sehr breit aufgestellt: Krusader kann mit nahezu allen gängigen Archivformaten umgehen, darunter ZIP, RAR, 7Z und TAR. Die Archive lassen sich direkt durchsuchen und bei Bedarf entpacken oder erstellen.
Die Suchfunktion erlaubt nicht nur das schnelle Auffinden von Dateien, sondern auch die inhaltsbasierte Suche.
Zur Vorschau von Dateien nutzt Krusader den einen kombinierten Viewer und Editor.
Für Dateivergleiche steht eine eingebaute Synchronisationsfunktion mit grafischer Oberfläche zur Verfügung, die Unterschiede zwischen Verzeichnissen übersichtlich darstellt und verschiedene Synchronisationsmodi anbietet.
Andere Funktionen wie die Mehrfachumbennenung werden über externe Werkzeuge wie KRename realisiert.
Krusader ist unter der GPL lizenziert und kann über den Paketmanager installiert oder alternativ bezogen werden.
macOS
Auch für das macOS stehen eine Reihe von orthodoxen Dateimanagern zur Verfügung, darunter auch solche, die besonderen Wert auf eine gelungene Integration in das System legen.
Commander One
Commander One wurde 2015 von Eltima Software (jetzt Electronic Team) veröffentlicht und ist ein orthodoxer Dateimanager für macOS. Er kombiniert die klassische Zwei-Panel-Struktur mit einer modernen Cocoa-Oberfläche.
Die Zwei-Panel-Ansicht ist zentrales Element, ergänzt durch Toolbar, Pfadleiste und Dateidetails. Der Dateimanager unterstützt macOS-Finder-Tags, Quick Look und bietet native Hotkey-Unterstützung.
Die Anwendung wurde in Swift entwickelt und ist sowohl in einer kostenlosen Grundversion als auch in einer kostenpflichtigen Pro-Variante mit erweiterten Funktionen erhältlich.
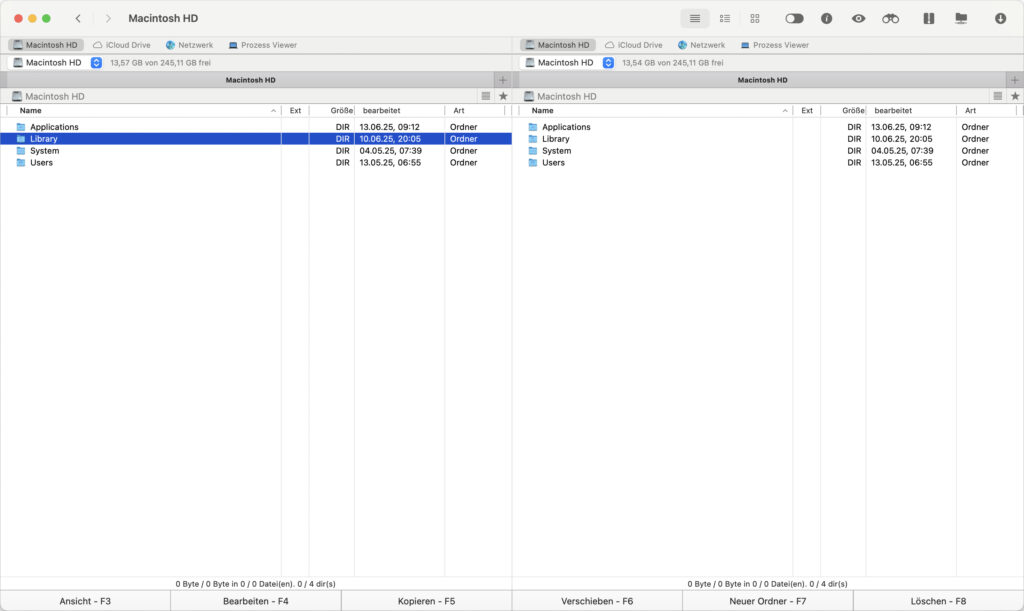
Commander One
Klassische OFM-Funktionstasten werden weitgehend unterstützt, ebenso wie Drag & Drop und Kontextmenüs im Stil des macOS-Finders. Auch die einfache Möglichkeit versteckte Dateien anzuzeigen ist positiv hervorzuheben.
In der Pro-Version wartet Commander One mit erweiterten Archivfunktionen auf. Archive in Formaten wie ZIP, RAR, 7z oder TAR lassen sich nicht nur extrahieren, sondern auch direkt erstellen. Hinzu kommt eine leistungsfähige Cloud-Integration, die unter anderem Google Drive, Dropbox, OneDrive, Amazon S3 und WebDAV unterstützt. Auch Apples iCloud ist sinnvoll eingebunden.
Für den Zugriff auf entfernte Server bietet Commander One integrierte Clients für FTP, SFTP und SCP. Ein eingebautes Terminal-Fenster ermöglicht den direkten Zugriff auf die Shell, ohne die Anwendung zu verlassen.
Allerdings muss hier berücksichtigt werden, dass es Unterschiede zwischen der Version aus dem App Store und der von der Webseite des Herstellers gibt. Aufgrund der Sandbox-Beschränkungen sind einige Funktionen nur in der Version des Herstellers verfügbar. Dazu zählen z. B. das Beenden von Prozessen, das Mounten von iOS-Geräten und das Ignorieren der System-Einstellungen für die Funktionstasten.
Neben dem Bezug über den App Store kann Commander One auch direkt über die Webseite des Herstellers bezogen werden.
Marta
Marta ist ein moderner und minimalistisch gestalteter Zwei-Panel-Dateimanager für macOS, der 2017 als Indie-Projekt von Yan Zhulanow vorgestellt wurde.
Geschrieben in Swift und vollständig nativ, vereint Marta orthodoxe Bedienphilosophie mit der Ästhetik und Performance moderner Apple-Systeme.
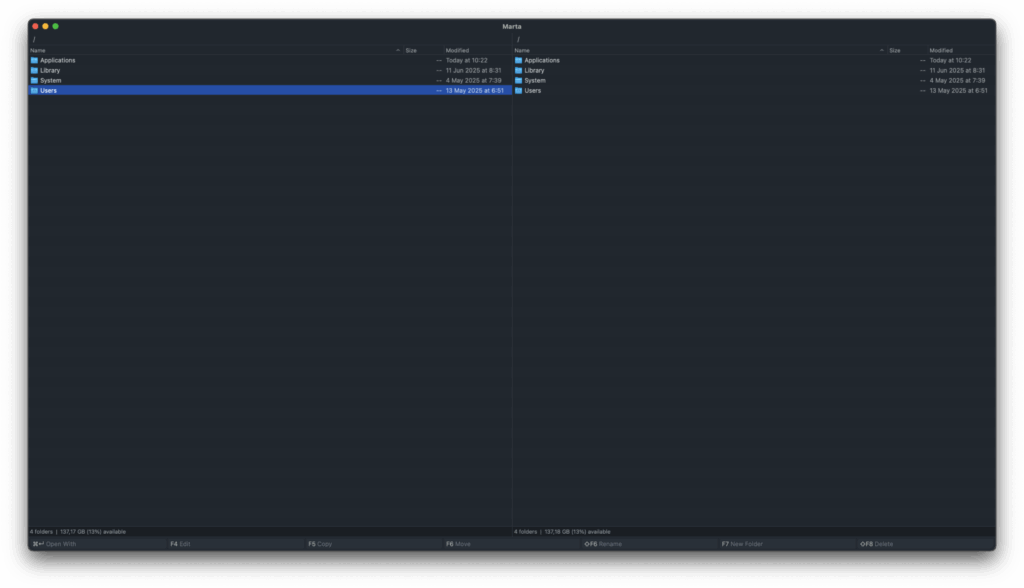
Marta
Das Zwei-Panel-Layout steht im Fokus, unterstützt durch eine konfigurierbare Statusleiste und eine leistungsfähige Kommandozeile. Klassische OFM-Funktionstasten werden weitgehend unterstützt.
Ein modular aufgebautes Plugin-System, das derzeit auf Lua-Basis entwickelt wird, erlaubt die individuelle Erweiterung der Funktionalität. Daneben existiert seit der ersten Version eine Swift-API.
Bereits integriert ist eine Unterstützung für Archivformate wie ZIP, TAR, RAR und 7z, die sich direkt als virtuelle Verzeichnisse öffnen lassen.
Für den komfortablen Zugriff auf häufig verwendete Pfade stehen Favoriten sowie eine durchsuchbare Verlaufsfunktion zur Verfügung. Ein integriertes Terminal ist vorhanden und kann optional angezeigt bzw. versteckt werden.
Die Konfiguration erfolgt über Marco-Dateien, ein für Marta entwickeltes Format, dass die Konfiguration allerdings unnötig umständlich erscheinen lässt.
Die Software ist kostenlos, wird aktiv weiterentwickelt und kann über die offizielle Webseite oder Homebrew bezogen werden.
Nimble Commander
Nimble Commander ist ein weiterer ressourcenschonender und klassisch orientierter Zwei-Panel-Dateimanager für macOS. Die Anwendung wurde in Objective-C++ entwickelt und ist nativ für macOS geschrieben.
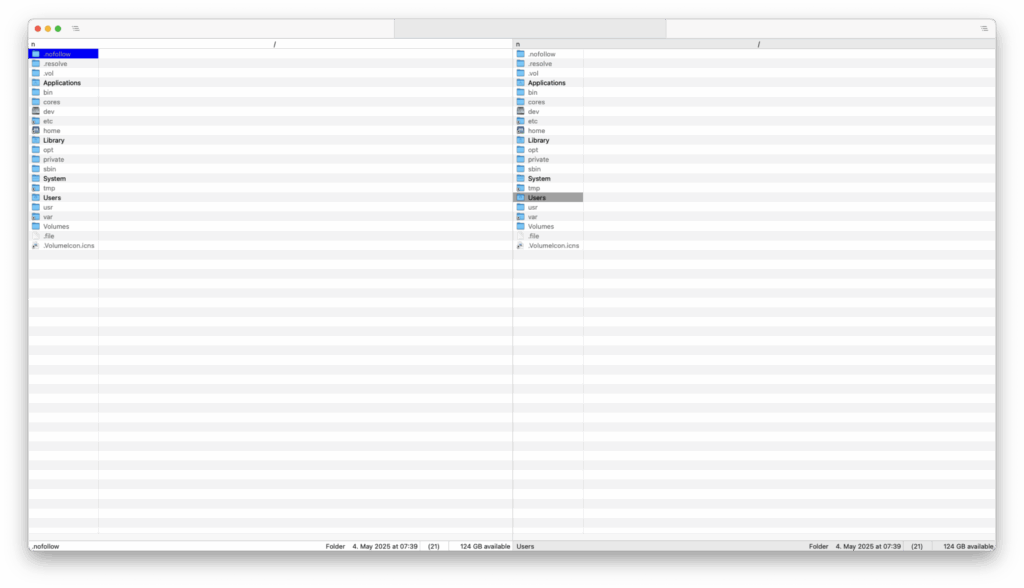
Nimble Commander
Im Zentrum steht ein übersichtliches Zwei-Fenster-Layout, das Terminal-Fenster ist nicht in dieses integriert, sondern kann über das „View“-Menü als Overlay aktiviert werden.
Daneben stehen Funktionen zur Dateiverwaltung wie Suchen, Umbenennen oder die Arbeit mit Archiven zur Verfügung. Nimble Commander unterstützt viele Archivformate, darunter ZIP, TAR, GZ, BZ2 und weitere Formate.
Auch ermöglicht der Nimble Commander es, in den Admin-Modus zu wechseln und mit entsprechenden Rechten zu arbeiten.
Die Konfiguration bietet zahlreiche Anpassungsmöglichkeiten, von Tastenkürzeln über Dateitypen bis hin zum Erscheinungsbild.
Nimble Commander ist unter der GPL in Version 3 lizenziert, damit freie Software, und kann über die offizielle Webseite, den App Store oder Homebrew bezogen werden.
Windows
Nachdem DOS über Jahre hinweg als bevorzugte Plattform orthodoxer Dateimanager gedient hatte, erfolgte mit dem Aufstieg grafischer Betriebssysteme eine allmähliche Migration dieser Gattung in die Windows-Welt – meist als Neuentwicklungen mit vertrautem Bedienkonzept.
Altap Salamander
Der Altap Salamander wurde ursprünglich 1997 unter dem Namen Servant Salamander von Petr Šolín und Pavel Schreib veröffentlicht und zählt zu den ältesten grafischen orthodoxen Dateimanagern für Windows. Entwickelt in Tschechien, bot das Programm von Beginn an eine schlanke, schnelle Alternative zum Windows Explorer.
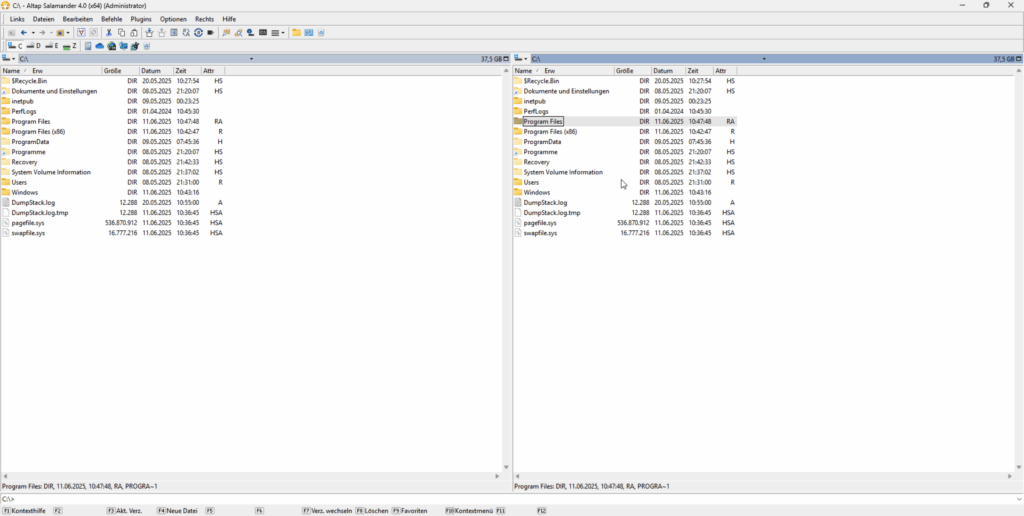
Der Altap Salamander unter Windows
Altap Salamander kombiniert klassische Zwei-Panel-Ansicht mit einer aufgeräumten und funktionalen Benutzeroberfläche.
Die integrierte Archivunterstützung erlaubt den direkten Zugriff auf Formate wie ZIP, RAR, ISO oder CAB. Mit eingebauten Clients für FTP, FTPS, SFTP und SCP können Dateioperationen auch im Netzwerk durchgeführt werden.
Werkzeuge zur Dateiverwaltung runden das Paket ab. Dazu gehören Funktionen zum Verzeichnisvergleich, zur Datei-Synchronisation sowie zur Berechnung und Prüfung von Prüfsummen und die Suche.
Ein interner Viewer unterstützt die Anzeige im Text- und Binärmodus, während der genutzte Editor sich frei konfigurieren lässt. Durch das Plugin-System lässt sich der Funktionsumfang erweitern.
Während der Dateimanager lange Zeit als Shareware vertrieben wurde, wurde er nach dem Kauf von Altap durch Fine zu freier Software. Die freigegebene Variante, genannt Open Salamander, findet sich auf GitHub und ist unter GPL in Version 2 lizenziert.
Derzeit ist keine aktive Weiterentwicklung erkennbar, was darauf hindeutet, dass das Projekt momentan pausiert.
Technisch gesehen ist die Anwendung ein Kind seiner Zeit: eine reine WinAPI-Anwendung, ohne moderne C++-Paradigmen wie RAII, Smart Pointers oder STL; dafür mit reichlich tschechischen Kommentaren im Code.
Bezogen werden kann der Altap Salamander über die offizielle Seite des Herstellers.
FreeCommander XE
FreeCommander XE ist ein orthodoxer Dateimanager für Windows, der seit den frühen 2000er-Jahren entwickelt wird.
Die Anwendung wurde von Marek Jasinski initiiert und richtet sich an Nutzer, die ein flexibles, Zwei-Panel-basiertes Werkzeug für Dateiverwaltung unter Windows suchen.
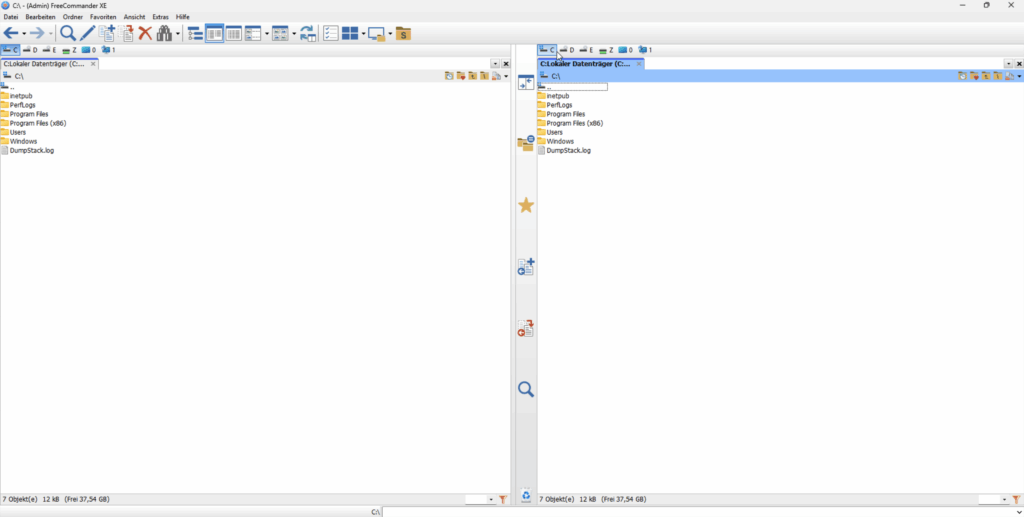
FreeCommander XE
FreeCommander XE wurde in Delphi entwickelt und läuft nativ unter Windows. Das Programm wird aktiv weiterentwickelt und ist sowohl als kostenlose Version als auch in einer Donator-Version verfügbar. Diese Donator-Version scheint aktuell die 64-Bit Version zu umfassen.
Die Oberfläche orientiert sich an klassischen Prinzipien orthodoxer Dateimanager, wurde aber mit modernen Windows-Elementen angereichert. Zwei horizontal oder vertikal teilbare Panels bilden das zentrale Layout. Tabs, anpassbare Toolbars und farbige Dateiansichten sorgen für Übersichtlichkeit.
Eine eingebaute Kommandozeile, Kontextmenüs und Drag & Drop sind ebenso vorhanden wie Einstellungen zur Nutzeranpassung.
Für die Organisation und den Abgleich von Dateien steht ein integriertes Tool für Dateivergleich und Verzeichnis-Synchronisation zur Verfügung.
Die Archivunterstützung umfasst gängige Formate wie ZIP, RAR, CAB und 7z. Der Zugriff erfolgt je nach Format direkt oder über externe Anwendungen.
Die Netzwerkfunktionen ermöglichen den Zugriff auf Netzwerkpfade, UNC-Freigaben sowie FTP- und SFTP-Server.
Ein interner Viewer erlaubt die Anzeige und Bearbeitung von Texten, Bildern und Daten. Als Editor wird eine externe Anwendung konfiguriert.
Ein Batch-Umbenennungstool mit Unterstützung für reguläre Ausdrücke ermöglicht das gleichzeitige Umbenennen vieler Dateien.
Die Anwendung ist Freeware und kann über die offizielle Webseite bezogen werden.
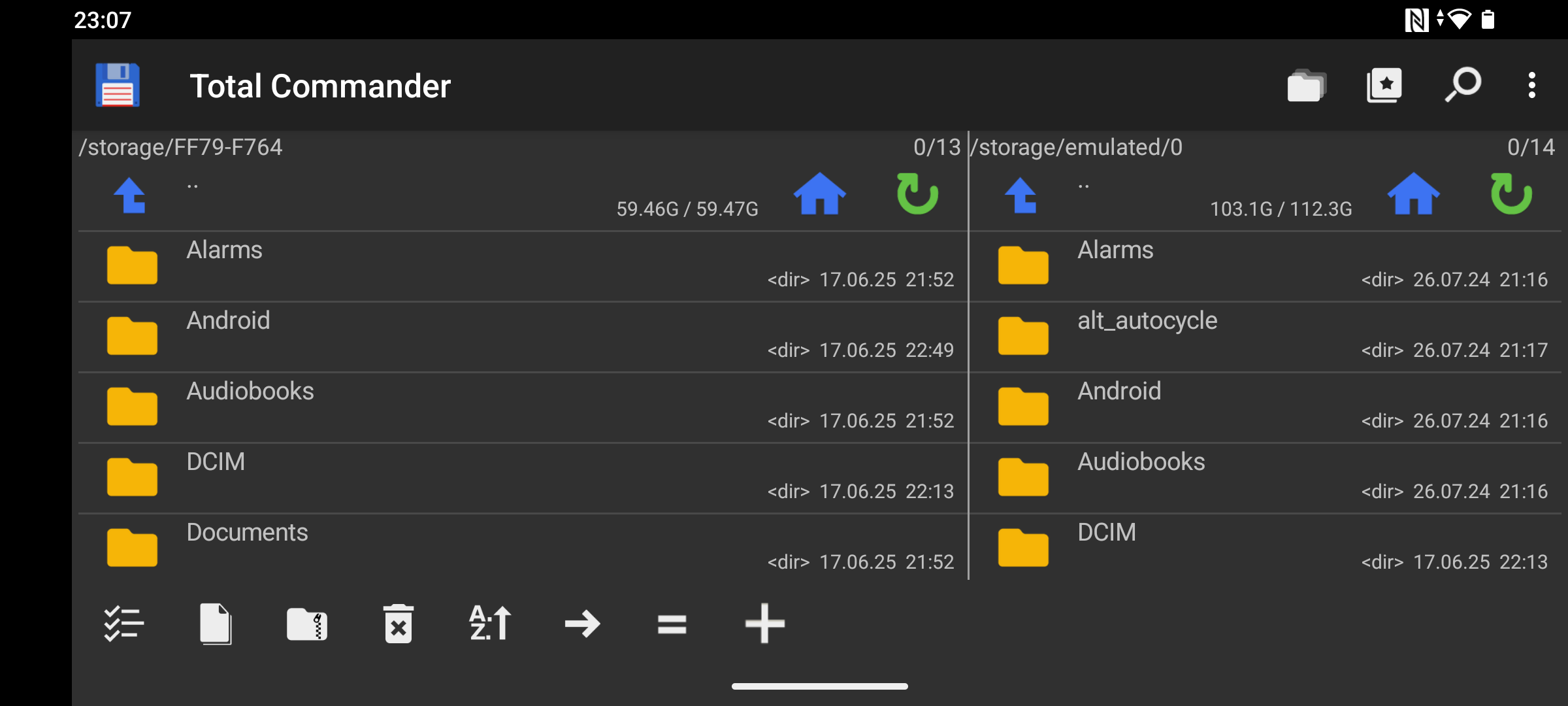
Total Commander
1993, ursprünglich als Windows Commander gestartet, musste Christian Ghisler das Programm nach einer Aufforderung von Microsoft aus markenrechtlichen Gründen umbenennen. Total Commander gilt als einer der bekanntesten orthodoxen Dateimanagern für Windows.
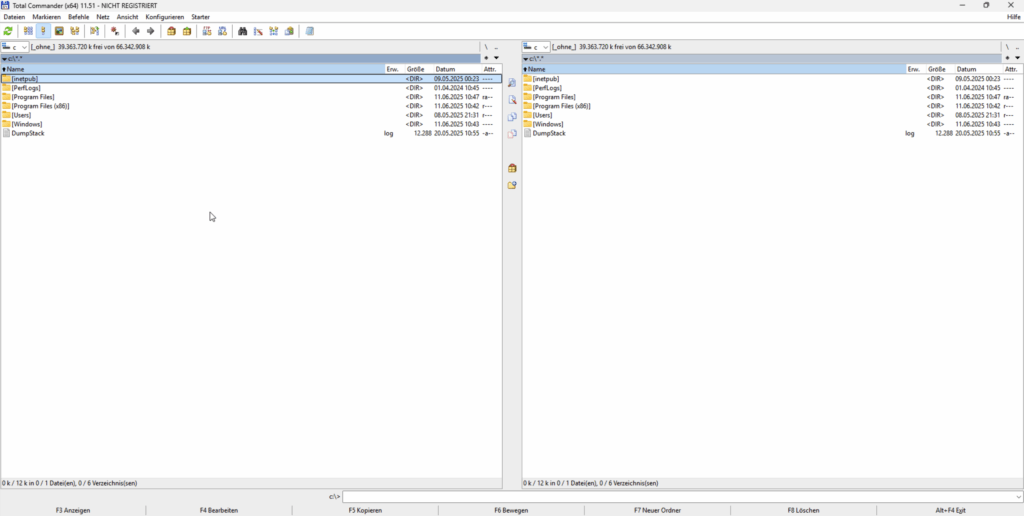
Total Commander
Die Oberfläche von Total Commander ist funktional und anpassbar. Die klassische Zwei-Panel-Ansicht lässt sich durch verschiedene Ansichtsmodi ergänzen, von einfachen Dateilisten bis zu detaillierten Spaltenansichten. Die Symbolleisten sind vollständig konfigurierbar, und Nutzer können praktisch jeden Aspekt der Oberfläche ihren Bedürfnissen anpassen.
Die integrierte Archiv-Unterstützung erlaubt den direkten Zugriff auf Formate wie ZIP, RAR, 7Z, TAR, GZ und viele weitere. Ein FTP/SFTP-Client ist ebenfalls integriert und unterstützt neben klassischem FTP auch FTPS, SFTP und WebDAV. Verbindungen können gespeichert, organisiert und über Bookmarks schnell aufgerufen werden.
Die Such- und Filterfunktionen bieten Unterstützung für reguläre Ausdrücke, Volltextsuche im Dateiinhalt und einen integrierten Duplikat-Finder. Zusätzlich erlauben Schnellfilter das sofortige Eingrenzen angezeigter Dateien in Echtzeit.
Ein integriertes Synchronisationswerkzeug unterstützt verschiedene Abgleichmodi, darunter bidirektionale und asymmetrische Synchronisation, während das Multi-Rename-Tool Funktionen zum gleichzeitigen Umbenennen von mehreren Dateien bietet.
Mit dem integrieren Viewer können Textdatei bis zu 8192 Petabyte betrachtet werden. Auch Bilder und Multimedia-Inhalte können direkt angezeigt werden.
Total Commander verfügt über ein umfangreiches Plugin-System, das verschiedene Plugin-Typen unterscheidet.
Packer-Plugins (WCX) erweitern die Unterstützung für Archivformate.
Dateisystem-Plugins (WFX) ermöglichen den Zugriff auf alternative Datenquellen außerhalb des regulären Dateisystems, etwa auf FTP-Server, WebDAV, Cloudspeicher, die Windows-Registry oder laufende Prozesse. Diese Ressourcen erscheinen innerhalb des Dateimanagers wie normale Verzeichnisse.
Lister-Plugins (WLX) ermöglichen die Anzeige spezieller Dateiformate im internen Betrachter, z. B. für Multimedia-, Office- oder CAD-Dateien.
Inhalts-Plugins (WDX) stellen zusätzliche Dateieigenschaften bereit, die z. B. in benutzerdefinierten Spalten angezeigt oder für Such- und Filterfunktionen verwendet werden können.
Bezogen werden kann Total Commander über die offizielle Webseite. Dort kann ebenfalls eine Lizenz erworben werden.
Plattformübergreifend OFMs
Neben den bisher vorgestellten orthodoxen Dateimanagern, die meist auf ein einzelnes Betriebssystem beschränkt sind, existieren auch plattformübergreifende Lösungen.
Double Commander
Double Commander, dessen erste Version 2006 erschien, versteht sich als plattformübergreifende Lösung eines orthodoxen Dateimanagers. Die in Object Pascal geschriebene Anwendung bietet native Binaries für Linux, macOS und Windows.
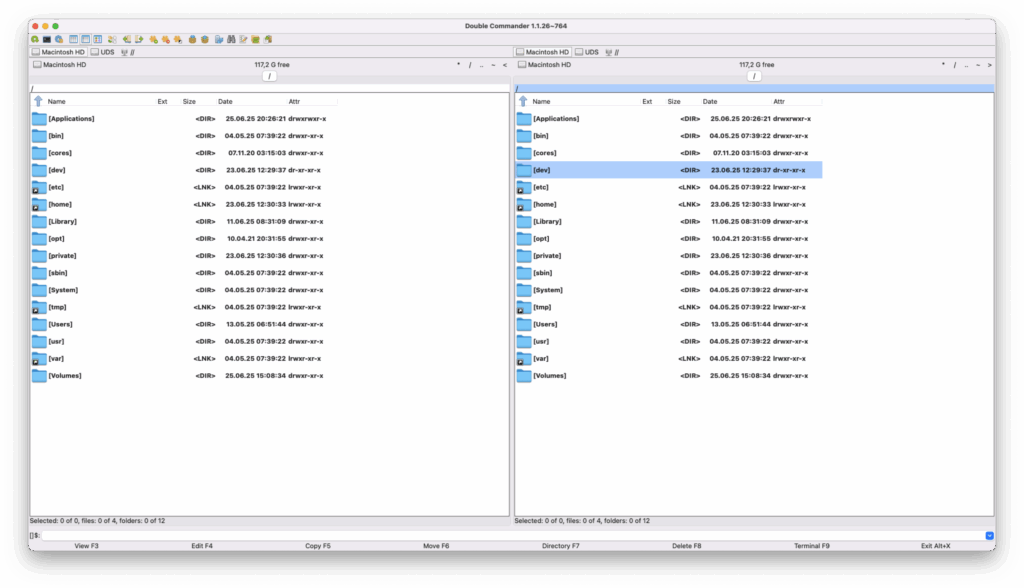
Double Commander unter macOS
Die Bedienelemente sind größer und klarer als bei vielen Konkurrenten, was der Benutzerfreundlichkeit zugutekommt, allerdings auch als klobig empfunden werden kann. Tabs ermöglichen das Arbeiten mit mehreren Verzeichnissen pro Panel.
Die Oberfläche ist anpassbar, vom Farbschemata über Symbolleisten hin zu Tastenkombinationen.
Die Archiv-Unterstützung umfasst eine breite Palette von Formaten wie ZIP, 7Z oder TAR.
Die erweiterte Suchfunktion erlaubt nicht nur Dateinamen- und Pfadsuche, sondern auch die Nutzung von regulären Ausdrücken sowie die Suche im Dateiinhalt.
Eine integrierte Synchronisationsfunktion mit grafischer Darstellung erleichtert das Vergleichen und Angleichen von Verzeichnissen.
Abgerundet wird der Funktionsumfang durch einen integrierten Viewer, der Texte, Bilder und Dateien anzeigen kann.
Der Dateimanager nutzt die Total Commander Plugin-API, sodass Total Commander-Plugins unter Windows auch im Double Commander genutzt werden können.
Der Double Commander ist unter der GPL in Version 2 lizenziert und kann über die offizielle Seite bezogen werden.
muCommander
muCommander ist ein plattformunabhängiger, Java-basierter orthodoxer Dateimanager, der 2002 veröffentlicht wurde. Er setzt auf ein klassisches Zwei-Panel-Layout und ist besonders für Nutzer interessant, die einen leichtgewichtigen Dateimanager auf unterschiedlichen Betriebssystemen wie Windows, Linux, macOS oder BSD nutzen möchten.
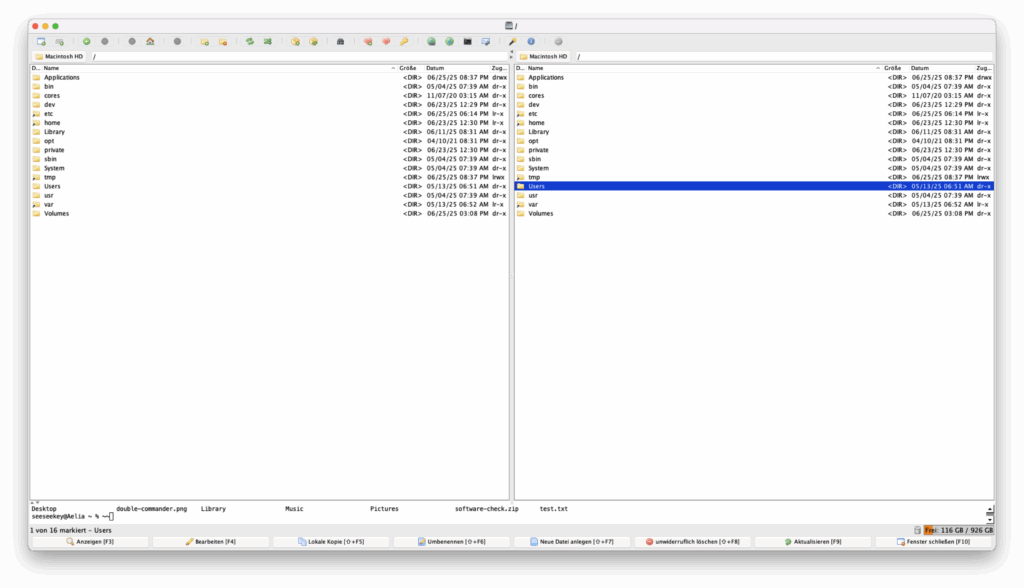
muCommander unter macOS
Zwei Panels stehen im Fokus, ergänzt durch eine Shell, Pfadleisten, Toolbar, Statusanzeigen und ein Menüband. Das Design lässt sich über verschiedene Styles konfigurieren, ist aber nicht auf native Optik ausgelegt.
Der Funktionsumfang umfasst integrierte Unterstützung für zahlreiche Netzwerkprotokolle wie FTP, SFTP, SMB, HTTP, Amazon S3 und Bonjour. Auch Archivformate wie ZIP, TAR, GZip und BZip2 werden unterstützt und lassen sich direkt wie normale Verzeichnisse durchsuchen.
Praktische Funktionen wie Favoriten und eine Verlaufsansicht erleichtern den Zugriff auf häufig verwendete oder zuletzt besuchte Pfade. Der integrierte Dateibetrachter erlaubt die Vorschau von Text-, Binär- und Bilddateien.
Das Programm ist unter der GPL lizenziert und wird aktiv als Open-Source-Projekt gepflegt. Es kann über die offizielle Webseite, oder je nach System über den Paketmanager bezogen werden.
Mobile Adaptierung
Neben orthodoxen Dateimanagern für Desktop-Systeme existieren auch Lösungen für mobile Systeme, allem voran Android.
Allerdings sind solche Dateimanager unter Android und iOS eher selten, da diese Plattformen restriktiver im Umgang mit dem Dateisystemzugriff und Benutzeroberflächenparadigmen sind.
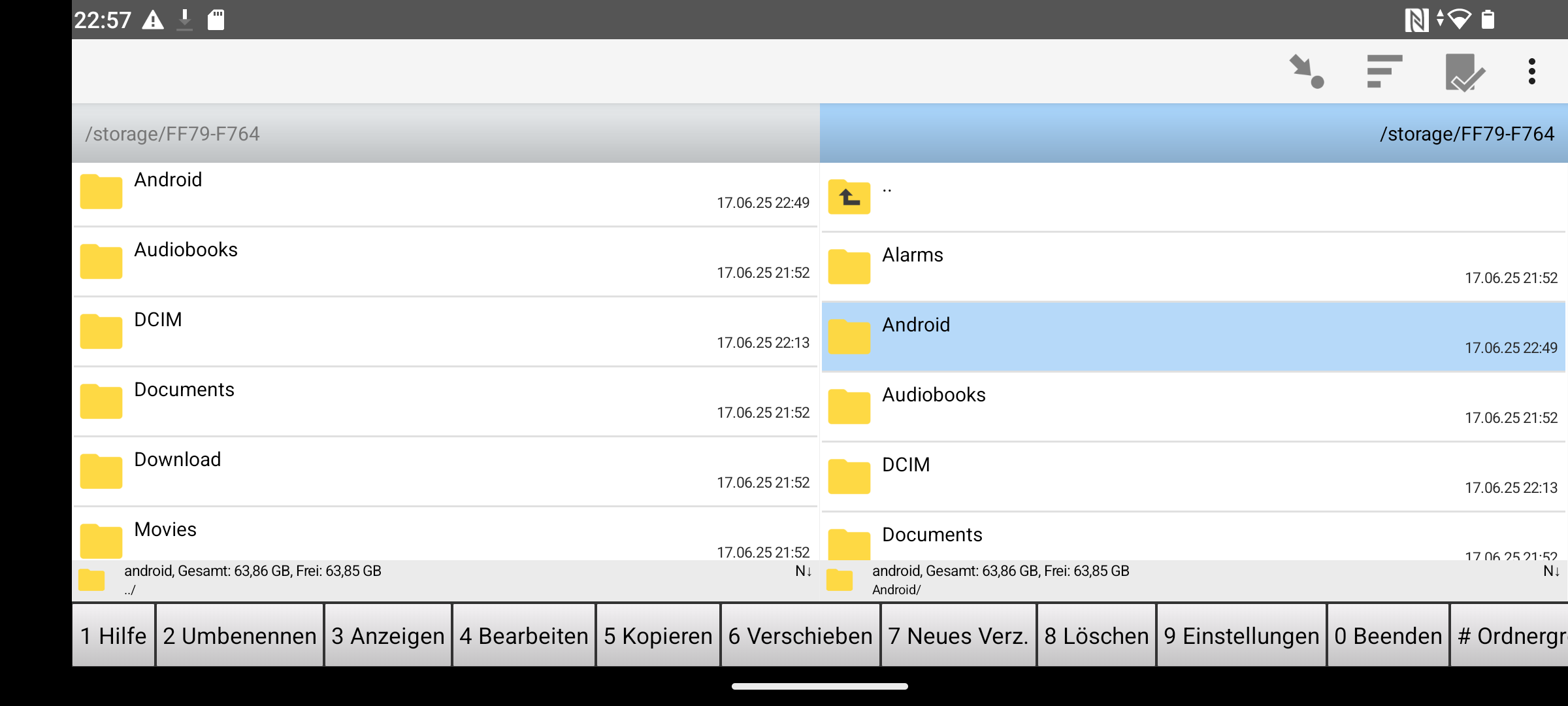
So existiert eine Umsetzung des Total Commander für Android, welche als Freeware vertrieben wird.
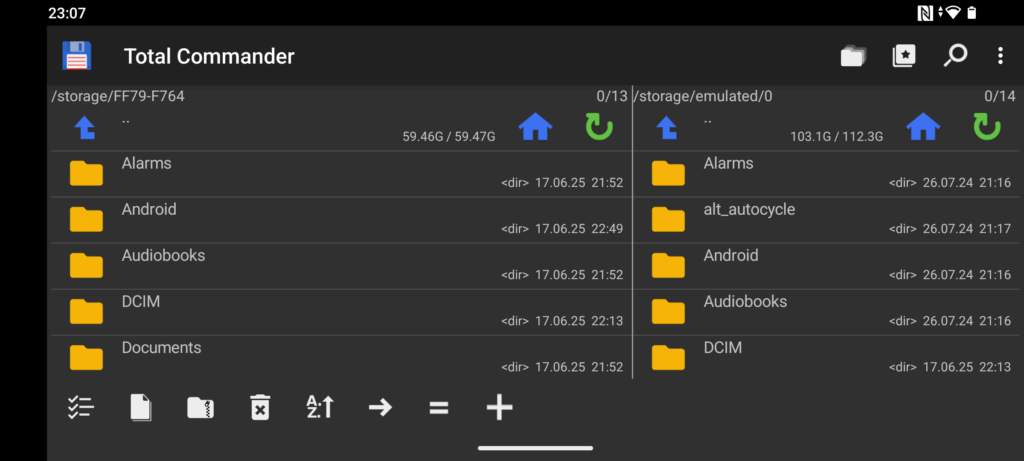
Der Total Commander unter Android
Ein weiterer mobiler Vertreter findet sich mit dem Ghost Commander, welcher ebenfalls das OFM-Paradigma implementiert, dies allerdings noch konsequenter umsetzt.
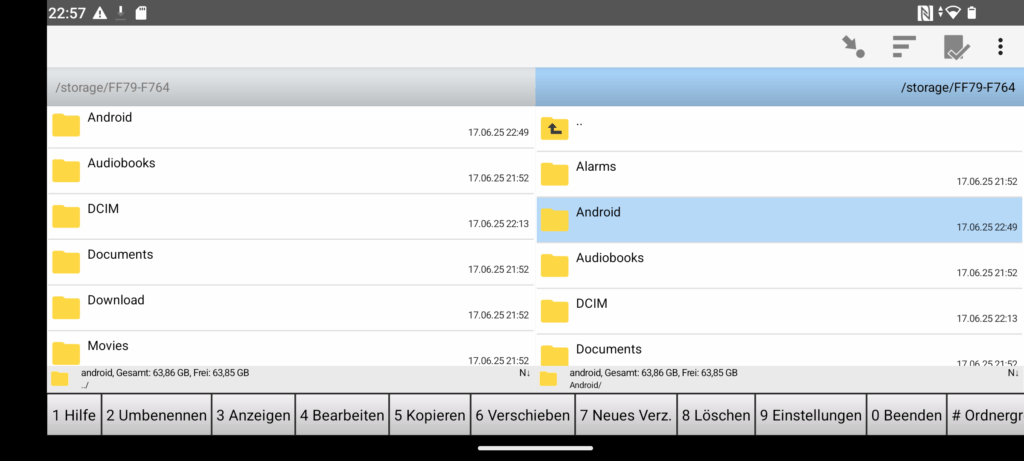
Ghost Commander
iOS-Beschränkungen verhindern echte orthodoxe Implementierungen. App-Sandboxing und File-System-Zugriffsbeschränkungen machen die charakteristischen Features nur schwer umsetzbar.
Daneben stellt sich im mobilen Bereich die Frage nach der Sinnhaftigkeit solcher Implementierungen, da die Vorteile wie eine schnelle Bedienung über die Tastatur, wenn überhaupt, nur in bestimmten Setups zum Tragen kommen.
Fazit
Orthodoxe Dateimanager repräsentieren ein Konzept, das sich über fast vier Jahrzehnte bewährt hat. Ihre Effizienz, Konsistenz und Erweiterbarkeit machen sie zu unverzichtbaren Werkzeugen für Power-User, Entwickler und Systemadministratoren.
Die Philosophie der tastaturorientierten, effizienten Dateiverwaltung bleibt relevant für all jene, die täglich mit großen Mengen von Dateien arbeiten müssen.
Besonders interessant ist, dass trotz des Alters dieses Konzepts die Entwicklung sehr aktiv ist. Heutige Implementierungen werden kontinuierlich weiterentwickelt und an aktuelle Bedürfnisse angepasst.
Diese Einheitlichkeit im Bedienkonzept, bedingt durch die informelle Standardisierung, sorgt dafür, dass Nutzer beim Wechsel zwischen verschiedenen orthodoxen Dateimanagern kaum Einarbeitungszeit benötigen.
Welcher orthodoxe Dateimanager für wen geeignet ist, ist eine Frage der persönlichen Präferenz. Hier kann nach Betriebssystem vorselektiert werden und auch die Frage, ob es freie Software oder auch ein kommerzielles Produkt sein darf, entscheidet.
Gemeinsam haben alle hier vorgestellten Dateimanager eine gewisse Basisfunktionalität. Die Differenzierung der einzelnen Dateimanager fängt meist erst bei den komplexen Features an.
Während z. B. der Total Commander mit vielen Funktionalitäten glänzt und über ein reichhaltiges Pluginangebot verfügt, kann er für einige Nutzer altgebacken oder überladen wirken.
Nicht alle orthodoxen Dateimanager sind in die eigene Landessprache übersetzt, sodass auch dies ein Entscheidungskriterium sein kann.
Unter Linux bieten sich je nach gewählter Desktop-Umgebung der GNOME Commander oder Krusader an, während macOS mit Commander One, Marta und dem Nimble Commander über gut integrierte Dateimanager verfügt. Auch für Windows-Nutzer stehen mehrere orthodoxe Dateimanager zur Verfügung, die nativ auf dem System laufen.
Wer betriebssystemübergreifend unterwegs ist, kann auf Multiplattform-Manager wie den Double Commander oder den muCommander zurückgreifen.
Je nach individuellen Anforderungen kann auch die Nutzung terminalbasierter Varianten wie des Far Managers oder des Midnight Commander eine sinnvolle Alternative darstellen.
Welche Lösung am besten passt, lässt sich meist erst im praktischen Einsatz beurteilen; eine individuelle Erprobung ist daher unerlässlich.
Zusammenfassend lässt sich sagen, dass orthodoxe Dateimanager ein effizientes Arbeiten mit vielen Dateien und komplexen Verzeichnisstrukturen ermöglichen; ganz ohne den Umweg über mausgesteuerte Bedienkonzepte. Dies spart Zeit, schont die Nerven und steigert die Produktivität.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.