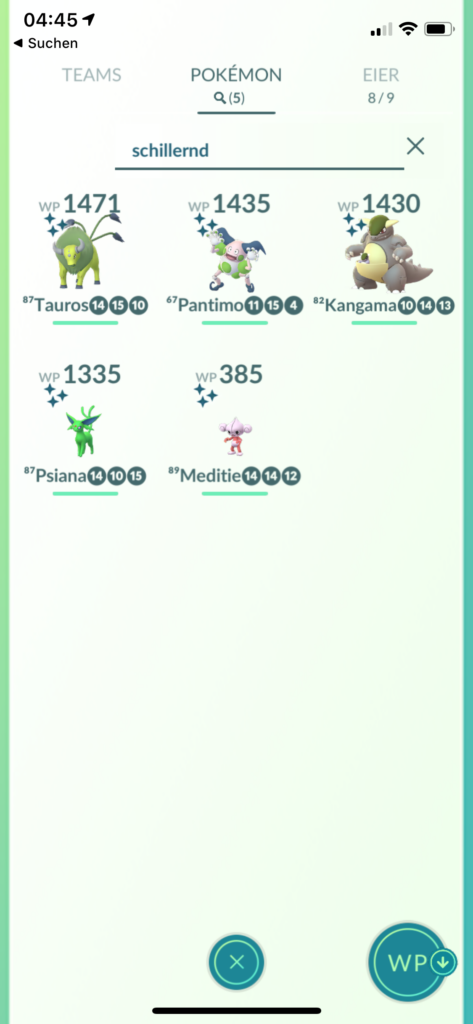
Im Spiel Pokémon Go existiert eine Suche, mit der innerhalb der eigenen Pokémon gesucht werden kann. Neben der normalen Suche nach dem Namen bzw. Spitzname eines Pokémons lässt sich mit der Suche wesentlich mehr erreichen. Dies fängt bei der Suche nach den Pokédex-Nummern an. Wird eine Nummer eingegeben, so werden Pokémon mit der entsprechenden Nummer angezeigt. Auch ein Nummernbereich lässt sich mit der Suche abbilden:
1-151
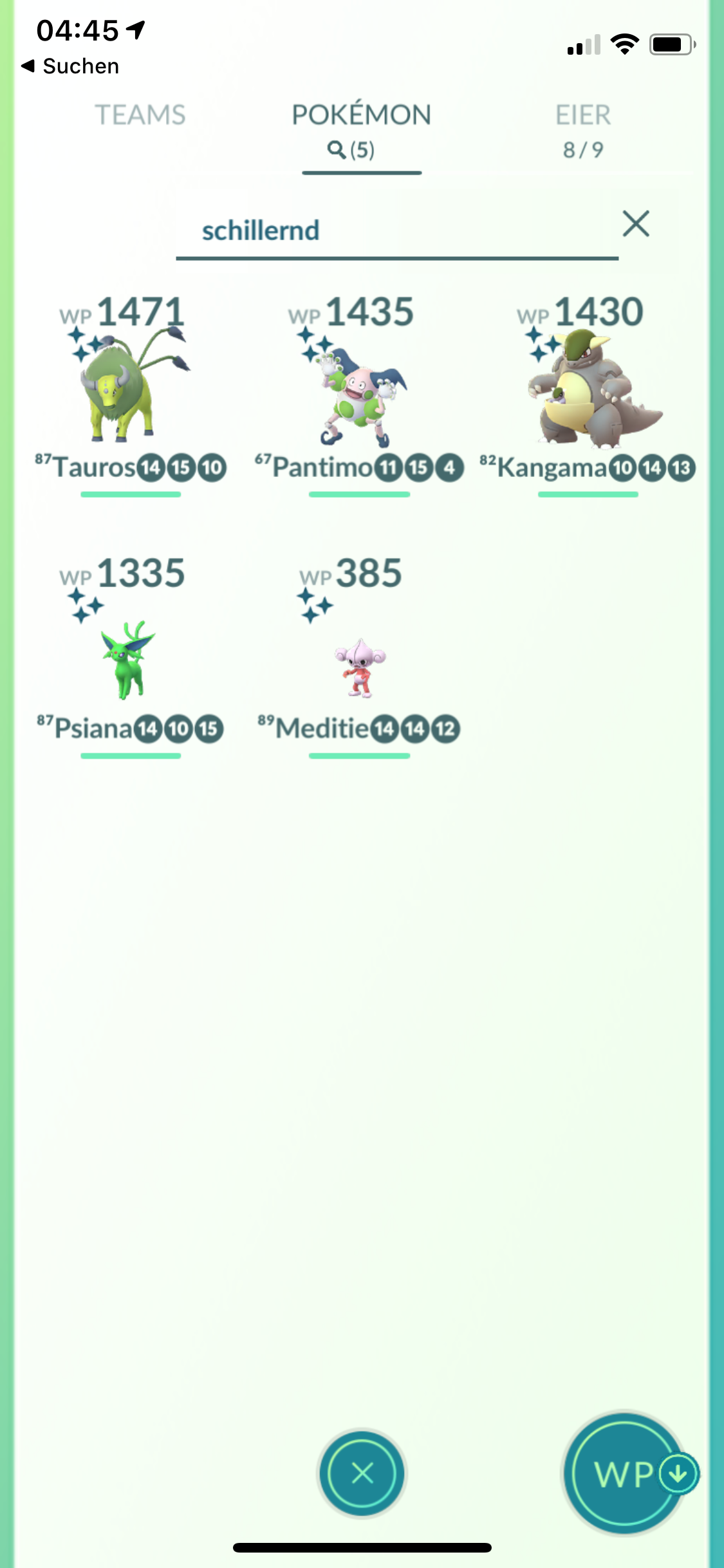
Diese Suche würde alle Pokémon anzeigen, welche im Pokédex die Nummern 1 – 151 haben. Daneben existieren Schlüsselwörter, um bestimmte Pokémon anzuzeigen. Wird nach schillernd gesucht, so werden alle Shiny-Pokémon angezeigt. Mit der Suchphrase entwickeln werden alle Pokémon angezeigt, welche entwickelt werden können.
Von diesen Schlüsselwörtern existieren ein gutes Dutzend: alola (alle Alola Pokémon), ausgebrütet (Pokémon, welche aus einem Ei geschlüpft sind), crypto (alle Crypto-Pokémon), entwickeln (alle Pokémon welche entwickelt werden können), erlöst (alle erlösten Pokémon), getauscht (alle getauschten Pokémon), glücks (alle Glücks-Pokémon), item (alle Pokémon, welche ein Item für die Entwicklung benötigen), kostümiert (alle Pokémon mit Verkleidungen), legendär (alle legendären Pokémon), männlich (alle männlichen Pokémon), mysteriös (alle mysteriösen Pokémon), nurauseiern (alle Pokémon, welche nur aus Eiern schlüpfen können), schillernd (alle Shiny-Pokémon), verteidiger (alle Pokémon, welche aktuell Arenen verteidigen) und weiblich (alle weiblichen Pokémon).
Die Pokémon Go-Suche in Aktion
Neben diesen speziellen Schlüsselwörtern existieren weitere Möglichkeiten der Suche. Wenn nach Namen gesucht wird, kann die Suche weiter spezifiziert werden. Die Suche mit einem vorangestellten Plus:
+Glumanda
findet das entsprechende Pokémon, sowie alle dazugehörigen Vor- und Weiterentwicklungen; in diesem Fall wären dies Glumanda, Glutexo und Glurak. Neben der direkten Suche lässt sich auch nach den Pokémon-Typen suchen:
Feuer
Bei dieser Suche würde alle Pokémon vom Typ Feuer anzeigt werden. Gesucht werden kann hierbei nach allen in Pokémon Go vorkommenden Pokémon-Typen: Boden, Drache, Eis, Elektro, Fee, Feuer, Flug, Geist, Gestein, Gift, Kampf, Käfer, Normal, Pflanze, Psycho, Stahl, Unlicht und Wasser.
Wird das At-Zeichen zu Beginn der Suche genutzt, kann nach Attacken gesucht werden:
@Feuerodem
Diese Suche würde alle Pokémon finden, welche die Attacke Feuerodem besitzen. Diese Suche kann verfeinert werden, indem nur auf einem bestimmten Slot gesucht wird:
@1Feuerodem
@2Feuerodem
@3Feuerodem
Die jeweiligen Suchen würden nur die Attacke auf dem entsprechenden Slot der Pokémon finden. Die Suche:
@spezial
zeigt alle Pokémon an, welche über Legacy-Attacken verfügen. Dies sind Attacken welche bei aktuell gefangenen Pokémon nicht mehr zu finden sind. Mit der Suche:
@wetter
zeigt die Suche alle Pokémon an, welche zurzeit einen Wetterbonus besitzen. Neben Namen kann auch nach dem KP- und WP-Werten gesucht werden. Dazu muss ein KP- bzw. WP dem Wert vorangesetzt werden:
KP100
Damit würden alle Pokémon mit 100 KP gefunden werden. Auch die Suche zwischen zwei Werten ist möglich:
KP100-750
Mit dieser Suche würden alle Pokémon gefunden werden, dessen KP zwischen 100 und 750 liegen. Die Suche nach Werten beherrscht auch die von bis-Suche:
KP-750
Damit würden alle Pokémon mit einer KP bis 750 gefunden. Umgekehrt würde die Suche:
KP750-
alle Pokémon mit einer KP ab 750 anzeigen. Analog dazu funktioniert dies auch mit den WP und dem Schlüsselwort entfernung:
entfernung-7
Der Parameter Entfernung zeigt an, wie weit der Fangort entfernt ist. Um so größer die Zahl, je weiter weg der Fangort des Pokémon; wobei es sich bei der Zahl nicht um Kilometer handelt. In Pokémon Go können die Pokémon bewertet werden. Nach diesen Sternebewertungen lässt sich ebenfalls suchen:
3*
Mithilfe dieser Suche würden alle Pokémon aufgelistet, welche mit drei Sternen bewertet wurden. Die unterschiedlichen Suchen lassen sich kombinieren, indem sie mittels eines Komata getrennt werden:
151, Glumanda, KP100-150
Diese Suche würde das Pokémon Mew, alle Glumandas und alle Pokémon mit einer KP zwischen 100 und 150 anzeigen. Mit dem & kennt Pokémon Go auch logische Operatoren zur Verknüpfung von Suchparametern:
Glumanda&KP100-150
Diese Suche würde alle Glumandas anzeigen, deren KP-Wert sich zwischen 100 und 150 bewegt. Mithilfe des logischen Operators ! können Suchen negiert werden. Eine Suche nach dem Schema:
!alola
würde in diesem Fall alle Pokémon anzeigen, welche nicht der Alola-Form entsprechen. Mit diesen Möglichkeiten bietet die Pokémon Go-Suche mehr als nur eine einfache Suche und vereinfacht bestimmte Aufgaben immens, wenn z.B. nach zu entwickelnden Pokémon geschaut werden soll.