Unicode erblickte vor knapp dreißig Jahren das Licht der Welt und brachte ein wenig Ordnung in die babylonische Vielfalt der Kodierungsstandards. Auch wenn er oft genutzt wird, gibt es doch viel Halbwissen rund um diesen Standard.
Wenn eine Datei mit einem Text eingelesen wird, so besteht diese für den Computer nur aus einer Abfolge von Daten, ohne eine wirkliche Bedeutung. Dass wir am Ende in dieser Datei Eine Geschichte zweier Städte von Charles Dickens finden, ist dem Umstand geschuldet, dass sich auf die Codierung dieser Daten geeinigt wurde.
Für die Codierung von Text wurden viele Codierungen erdacht und in der Praxis eingesetzt, vom Morsecode über den Baudot-Murray-Code, welcher als 5-Bit-Code die Tastenstellung eines Telegrafengerät kodierte, bis zum American Standard Code for Information Interchange, kurz ASCII, der für viele Jahre das Fundament der Textkodierung in der IT darstellte.
Eine Telegraphen-Tastatur
Mit Unicode, welcher vor etwa 30 Jahren das Licht der Welt erblickte, wurde ein wenig Ordnung in die babylonische Vielfalt der Codierungsstandards gebracht, was wegen der Internationalisierung der IT dringend nötig war. Und damit ist dieser Standard aus der Vergangenheit gleichzeitig die Zukunft.
ASCII und EBCDIC
Wie vieles in der IT, baut auch Unicode auf einem historischen Erbe auf, in diesem Fall dem ASCII-Standard. In diesem 1963 verabschiedeten Standard waren in einer 7-Bit-Codierung 128 Zeichen kodiert. Neben dem lateinischen Alphabet, also den Zeichen von A bis Z, jeweils in Groß- und Kleinschreibung, den Ziffern und einigen Sonderzeichen, befanden sich in diesem auch etliche Steuerzeichen.
Zu diesen Steuerzeichen gehören bekannte Zeichen wie der Tabulator oder der Zeilenvorschub, als auch weniger bekannte Zeichen wie die Glocke (Bell). Genutzt wurden diese Zeichen zur Steuerung der Geräte, welche mit dem ASCII-Code umgehen sollten.
Technisch betrachtet wurden im ASCII-Code eigentlich nur 126 Zeichen kodiert. Der Hintergrund hierfür ist historisch begründet. Das Zeichen 0 (kodiert als Bits 0000000) wird genutzt, um die Nichtexistenz von Daten anzuzeigen. Im Kontext einer Lochkarte werden keine Löcher im entsprechenden Bereich gestanzt.
Das Gegenteil hiervon ist das Zeichen 127 (1111111), welches festlegt, dass die Daten auf diesem Feld als gelöscht gelten; auch hier wieder der Lochkarten-Hintergrund, bei welchem im Fehlerfalle bestehende Löcher nicht mehr geschlossen werden können bzw. sollten und somit alle Löcher gelocht werden, um ein gelöschtes Datum zu symbolisieren.
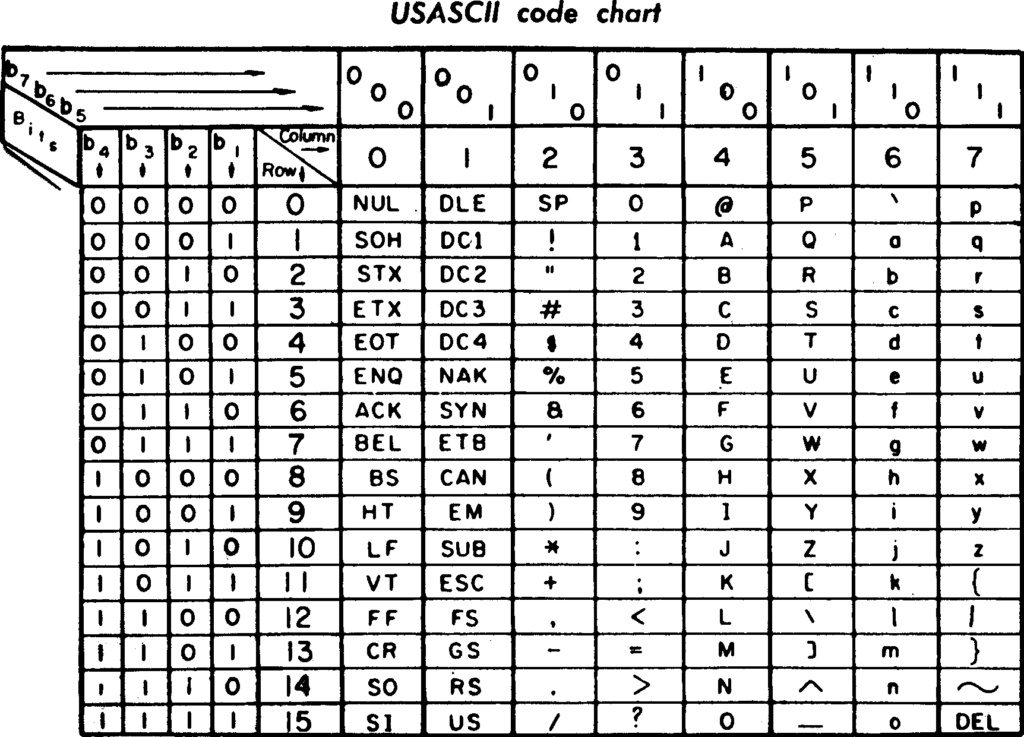
Eine ASCII-Tabelle in einem Drucker von General Electric aus den 70er Jahren
Da sie in dieser Form nicht mehr benötigt wurden, wurden diese Zeichen teilweise anders genutzt. In vielen Programmiersprachen stellt das Zeichen 0 das Ende einer Zeichenkette dar. Somit können in diesen Sprachen, wie z. B. C, Zeichenketten abgespeichert werden, ohne dass die entsprechende Länge bekannt sein muss, im Gegensatz zu Sprachen wie z. B. Pascal.
In seiner heutigen Form wurde der ASCII-Code nach einigen kleineren Änderungen schließlich 1968 verabschiedet. Neben dem ASCII-Code wurde von IBM der Extended Binary Coded Decimal Interchange Code (EBCDIC) entwickelt, welcher vorwiegend auf Großrechnern genutzt wurde. Diese Entwicklung fand zwischen 1963 und 1964 statt und wurde mit dem System/360 der Öffentlichkeit vorgestellt.
Im Westen nichts Neues
Aus Sicht der westlichen Welt war der ASCII-Code für viele Dinge gut genug. So können Umlaute im Deutschen leicht ersetzt werden, z. B. das Zeichen ä durch ae. Allerdings wurde dies nicht immer gemacht und war auch nicht immer gewünscht.
Um andere Zeichen wie Umlaute oder Akzentzeichen abzubilden, entstanden 8-Bit Codes basierend auf dem ASCII-Code, welche somit die doppelte Zeichenanzahl unterbringen konnten.
In Westeuropa hat sich hierbei insbesondere der Standard ISO/IEC 8859-1 etabliert, besser bekannt unter dem Namen Latin-1. Ziel dieses Standards war es, möglichst viele Zeichen westeuropäischer Sprachen abzubilden. Unter Windows wurde eine abgewandelte Form dieses Zeichensatzes unter dem Namen Windows-1252 genutzt.
Durch die ISO standardisiert sind daneben Zeichensätze für weitere europäische Regionen wie Griechisch, aber auch Kyrillisch, Arabisch, Thai und Hebräisch.
Daneben existieren andere 8-Bit-Codierungen, welche teilweise nur mit ihren jeweiligen Anwendungen bzw. Betriebssystemen kompatibel waren und nicht standardisiert sind. Ein Beispiel für eine solche Codierungen ist CBM-ASCII, in welcher unter anderem Zeichen für Blockgrafik enthalten waren und welche bei vielen Heimcomputern von Commodore zum Einsatz kam.
Zeichensalat
Die Nutzung unterschiedlicher Codierungen führt aber auch zu Problemen. Wird ein Dokument z. B. mit der falschen Codierung geöffnet, so erhält der Nutzer in solchen Fällen sogenannten Zeichensalat:
Falsches Üben von Xylophonmusik quält jeden größeren Zwerg.
Auch Texte, in denen mehrere Sprachen vorhanden sind, ließen sich mit diesen bestehenden Codierungen nicht einfach umsetzen.
Noch ein Standard?
Mit der Globalisierung und dem Austausch von Dokumenten über Sprach- und Systemgrenzen hinweg entwickelte sich die Vielfalt an Codierungen zu einem Problem.
Die ISO/IEC 2022 versuchte dieses Problem zu lösen. Bei diesem Standard kann unter Zuhilfenahme verschiedener Escape-Sequenzen zwischen den unterschiedlichen Zeichensätzen umgeschaltet werden. Durchgesetzt hat sich dieser Standard nur in Japan, Korea und China, in erster Linie im Kontext E-Mail; da der Standard auch entsprechende 7-Bit-Codierungen definiert.
Schlussendlich kam es zur Entwicklung von Unicode. Wie so viele Entwicklungen, die die IT weiter brachten, hatten sie etwas mit Xerox zu tun. Vom PARC Universal Packet, welches maßgeblich das Design von TCP/IP beeinflusste, bis zum WIMP-Paradigma (Windows, Icons, Menus, Pointer), dem wir unsere modernen Desktop-Oberflächen und Interface-Konzepte verdanken.
Dort entstand der Xerox Character Code Standard, welcher als inoffizieller Vorgänger des Unicode-Standards betrachtet werden kann. Joseph D. Becker, welcher sich bei Xerox schon länger mit multilingualer Software befasste und unter anderem 1984 das Paper Multilingual Word Processing dazu verfasste, ist einer der Erfinder und Gestalter von Unicode.
Die eigentliche Entwicklung von Unicode begann 1987. Neben Joseph D. Becker arbeiteten Lee Collins und Mark Davis, damals bei Apple angestellt, ebenfalls an dem neuen Standard, welcher ein universelles Set von Zeichen darstellen sollte, in welchem die aktuellen Schriftsysteme der Zeit enthalten sein sollten. In der damaligen Entwurfsphase war es noch nicht das erklärte Ziel historische Schriftsysteme abzubilden:
Unicode gives higher priority to ensuring utility for the future than to preserving past antiquities. Unicode aims in the first instance at the characters published in modern text (e.g. in the union of all newspapers and magazines printed in the world in 1988), whose number is undoubtedly far below 2^14 = 16,384. Beyond those modern-use characters, all others may be defined to be obsolete or rare; these are better candidates for private-use registration than for congesting the public list of generally-useful Unicodes.
Im Laufe des Jahres 1989 stießen zur Gruppe um Becker, Mitarbeiter von Metaphor, RLG und Sun Microsystems hinzu. 1990 wurde das Team um Mitstreiter von Microsoft und NEXT erweitert.
Ende desselben Jahres war der Standard dann so weit gediehen, dass am 3. Januar 1991 das Unicode Consortium gegründet wurde. Dieses setzte einige Monate später im Oktober des Jahres den ersten Unicode-Standard in die Welt.
Allerdings wurde dies nicht überall so verstanden. In der TrueType Spezifikation in Version 1.0 für das entsprechende Font-Format erhielt der Standard die Plattform-ID Apple Unicode, was allerdings ein Irrtum war, welcher mittlerweile korrigiert wurde.
Beim Unicode Consortium selbst handelt es sich um eine gemeinnützige Organisation, mit Sitz in Mountain View in Kalifornien. Sie sorgt für die Weiterentwicklung des Standards und die Aufnahme weiterer Zeichen. Zu den Mitgliedern gehören unter anderem Adobe, Apple, Google und Netflix, aber auch Institutionen wie das Bangladesh Computer Council.
Aufbau
Grundsätzlich definiert der Unicode-Standard einen sogenannten Codespace. Jedem Zeichen wird eine Nummer innerhalb dieses Codespace zugewiesen. Ein vergebener Wert für ein Zeichen innerhalb dieses Codespace wird als Code Point bezeichnet und stellt die Grundlage von Unicode dar. So entspricht z. B. der Code Point 2126 dem Omega-Zeichen (Ω). Der Umfang dieses Codespace erstreckt sich von 0 bis 10FFFF.
Genau betrachtet stellt ein Code Point aber nicht unbedingt ein Zeichen dar, da es Zeichen gibt, welche sich aus mehreren Code Points zusammensetzen. So könnte ein Ä als A mit einem Trema (die Punkte über dem Ä), also mit zwei Code Points, dargestellt werden.
Auch werden keine Repräsentationen der Zeichen durch den Unicode-Standard vorgegeben. Stattdessen handelt es sich um abstrakte Zeichen, welche definiert werden. Ihre jeweilige Ausgestaltung ist z. B. entsprechenden Fonts vorbehalten.
Allerdings ist der Adressraum von Unicode nicht flach, sondern in sogenannte Planes unterteilt. Eine Plane entspricht hierbei 2^16, also 65.536 Code Points. Insgesamt sind 17 Planes (Plane 0 bis 16) im Standard definiert. Damit ist das aktuelle Limit an Zeichen in Unicode auf 1.114.112 festgelegt. Nach dem Abzug von Regionen für die private Nutzung bleiben am Ende in etwa 970.000 Code Points für die öffentliche Nutzung übrig.
Die Planes sind nach bestimmten Kriterien unterteilt und definiert. Aktuell genutzt respektive definiert sind sieben dieser Planes, wobei zwei davon für die private Nutzung definiert sind und somit im Unicode-Standard keinerlei Zeichen zugewiesen bekommen.
Die wichtigste und zuerst definierte Plane ist die Basic Multilingual Plane (BMP) mit der ID 0. In dieser sind die Zeichen für die meisten aktuell genutzten Sprachen, definiert. Grundsätzlich sollten in dieser Plane alle Zeichen definiert werden, welche in modernen Schriftsystemen rund um die Welt Verwendung finden. Hier finden sich neben Symbolen und lateinischen Buchstaben hauptsächlich die Zeichen aus der chinesischen, japanischen und koreanischen Sprache.
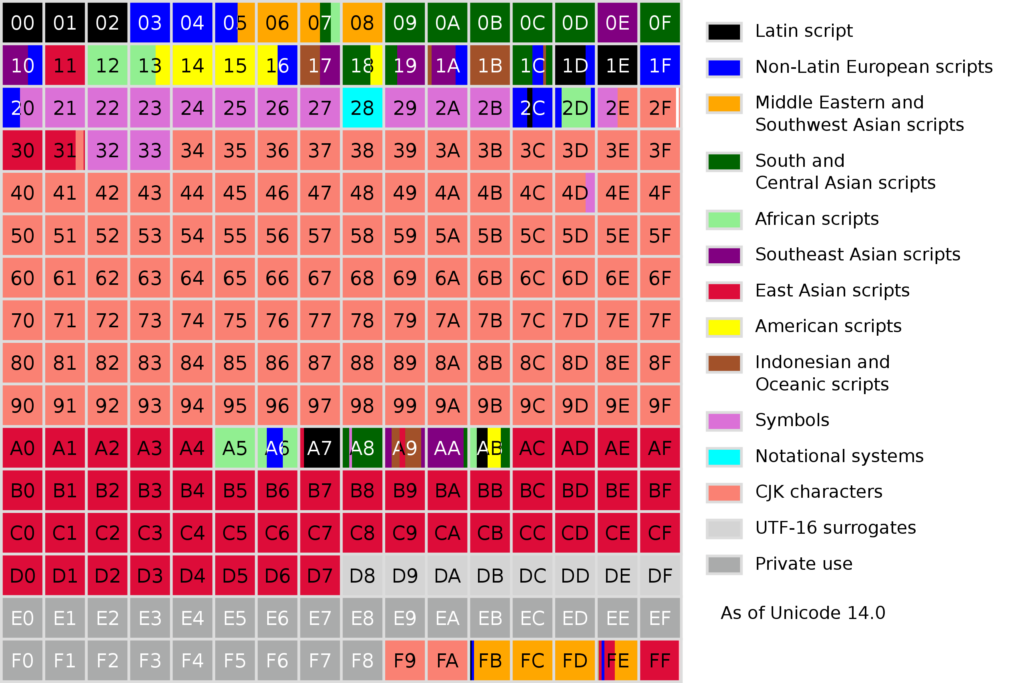
Die Basic Multilingual Plane
Innerhalb der Planes werden die Code Points in sogenannten Blöcken gruppiert. So existieren in der BMP 164 solcher Blöcke. In diesen Blöcken werden Schriftzeichen thematisch gruppiert, so z. B. der Block für lateinische Buchstaben, für Thai, für mathematische Operatoren oder geometrische Formen. Die Größe eines Blockes hängt von der Anzahl der zu kodierenden Code Points ab, ist aber immer ein Vielfaches von 16.
Neben dieser Plane existieren noch die Supplementary Multilingual Plane mit der ID 1, die Supplementary Ideographic Plane mit der ID 2, die Tertiary Ideographic Plane mit der ID 3 und die Supplementary Special-purpose Plane mit der ID 14.
In der Supplementary Multilingual Plane finden sich weitere Schriftsysteme, auch historischer Natur, wie ägyptische Hieroglyphen oder Zeichen zur Notation von Musik. Auf der Supplementary Ideographic Plane finden sich weitere sogenannte CJK-Zeichen also Schriftzeichen aus dem Chinesischen, Japanischen, Koreanischen und Vietnamesischen. Neben einigem historischen Schriftsystemen wie dem Oracle bone script, einem Vorgänger der chinesischen Schrift, welcher auf Orakelknochen gefunden wurde, ist die Tertiary Ideographic Plane größtenteils leer. Die Supplementary Special-purpose Plane wird für bestimmte Spezialzeichen genutzt, die z. B. im Zusammenhang mit Emojis zum Tragen kommen.
Die Planes 4 bis 13 sind im Moment nicht belegt und somit für zukünftige Erweiterungen verfügbar. Die Planes 15 und 16 sind sogenannte Private Use Area Planes, mit welchen Zeichen kodiert werden können, welche nicht im Unicode-Standard definiert sind. Hierbei müssen sich die Anwendungen über die Bedeutung der einzelnen Zeichen bewusst sein, um diese korrekt darstellen zu können.
Teilweise sind die Zeichen innerhalb einer Plane und entsprechender Blöcke fragmentiert, da Blöcke bereits komplett belegt waren und Zeichen erst später dazukamen.
Altlasten
Neben besagter Fragmentierung befinden sich auch historische Altlasten im Unicode.
Damit bestehende Zeichensätze wie die Latin-Familie, aber auch asiatische Systeme, sinnvoll übernommen werden und einfach konvertiert werden konnten, wurden diese als Ganzes in den Standard übernommen. So entsprechen die ersten 256 Zeichen im Unicode-Standard exakt dem Standard ISO/IEC 8859-1, besser bekannt als Latin-1.
Dies führt stellenweise zu doppelten Zeichen im Unicode-Standard und auch Zeichen wie dem Ä, welches eigentlich ein zusammengesetztes Zeichen ist und als solches nach den heutigen Kriterien wohl nicht im Standard aufgenommen würde. Die meisten dieser Zeichensätze sind in der Basic Multilingual Plane gelandet.
Im Standard selbst mag dies zu einigen Problemen geführt haben und wie ein Makel wirken, aber es war eine pragmatische Entscheidung, welche die Umstellung auf Unicode vereinfachen sollte.
Im Reich der Codierungen
Um ein Unicode-Zeichen zu codieren, existieren unterschiedliche Unicode-Codierungen, sogenannte Unicode Transformation Formats (UTF). Diese unterscheiden sich in grob in Codierungen mit fester Länge wie UTF-32 und Codierungen variabler Länge wie UTF-8.
Im Standard existieren drei Geschmacksrichtungen dieser UTFs: UTF-8, UTF-16 und UTF-32. Die Zahl gibt die Minimalbits an, welche zur Codierung eines Zeichens benötigt werden. Auch wenn dies historisch betrachtet nicht immer der Fall war, da es Codierungen wie UTF-1 oder UTF-7 gab.
Im Falle von Buchstaben aus dem ASCII-Zeichensatz benötigt ein Zeichen in der Codierung UTF-8 ein Byte, kann aber bis zu 4 Byte beanspruchen, je nach dem auf welches Unicode-Zeichen verwiesen werden soll. Somit können alle Zeichen des Unicode-Standards entsprechend kodiert werden. Werden nur ASCII-Zeichen genutzt, so ist diese Codierung kompatibel mit ASCII.
Die Geschichte von UTF-8 ist eng mit der des Betriebsystems Plan-9 verbunden, welches in den 80er-Jahren in den Bell Laboratories entwickelt wurde. Die ursprüngliche Umsetzung sah vor 16-Bit breite Zeichen in Plan 9 zu nutzen. Allerdings waren die Entwickler damit unzufrieden. Ein Anruf von IBM, zu einem bevorstehenden Meeting des X/Open Komitees, führte dazu, dass Rob Pike und Ken Thompson an einem Mittwochabend die UTF-8 Codierung entwickelten und sie Plan 9 von Mittwoch zu Freitag auf UTF-8 umstellten. Ein weiterer Anruf beim X/Open Komitee und dem Eingeständnis, dass der Vorschlag von Pike und Thompson wesentlich besser war als der eigene, begann UTF-8 seinen Siegeszug.
Doch wie wird das Ganze technisch gelöst? Da es sich bei ASCII um eine 7-Bit-Codierung handelt, wird das Bit mit dem Index 7 nicht genutzt. Es ist immer Null. So wäre das Zeichen F wie folgt kodiert:
[0 1 0 0 0 1 1 0]
7 6 5 4 3 2 1 0
Dieser Umstand wird nun für UTF-8 genutzt. Ist das Bit (Index 7) Null, so handelt es sich um ein ASCII-Zeichen, ist es Eins, so liegt eine UTF-8 Codierung vor. Das Zeichen Ä (196) sähe in der UTF-8-Codierung wie folgt aus:
[11 00 00 11] [10 00 01 00]
Die Bitfolge 11 im ersten Byte zeigt dabei an, dass es sich um das Startbyte des Zeichens handelt. Die Anzahl der Einsen am Anfang gibt hierbei an, in wie vielen Bytes das Zeichen kodiert ist. Das Yen-Zeichen ¥ würde in UTF-8 wie folgt kodiert werden:
[11 10 11 11] [10 11 11 11] [10 10 01 01]
Hier zeigt das Startbyte drei Einsen am Anfang. Damit ist klar, dass dieses Zeichen in drei Byte kodiert wird. Die folgenden Bytes sind die sogenannten Folgebytes und sind an der Bitfolge 10 am Anfang zu erkennen.
Nach den aktuellen Unicode-Regeln darf ein UTF-8-Zeichen maximal 4 Byte in Anspruch nehmen, auch wenn die Art der Codierung in der Theorie mehr Bytes nutzen könnte. Zu den jeweiligen Codierungen zählen weiterhin bestimmte Feinheiten, die im Rahmen dieses Artikels nicht im Detail besprochen werden sollen, da sie für das Grundprinzip der Codierung unerheblich sind. So dürfen unter anderem bestimmte Bitfolgen nicht genutzt werden, da sie im Rahmen der UTF-8 Codierung als ungültig angesehen werden. Ein Vorteil dieser Codierung ist, dass immer klar ist, wo ein neues Zeichen beginnt und daher defekte Daten in der UTF-8-Codierung problemlos übersprungen werden können.
Bei UTF-16 wird ein Zeichen durch 16 Bit abgebildet, wenn es sich um ein Zeichen aus der Basic Multilingual Plane handelt. Bei Codierungen außerhalb der BMP werden jeweils zwei 16-Bit-Pärchen genutzt. Dies sollte allerdings nicht mit der UTF-32 Codierung verwechselt werden, da es sich trotzdem um zwei UTF-16 codierte Entitäten handelt.
UTF-32 kodiert jeden Code Point immer in vier Byte und stellt damit die speicherintensivste Codierung dar. Im gewissen Rahmen, mit Ausnahme zusammengesetzter Zeichen, bietet sie einen wahlfreien Zugriff auf die Zeichen einer Zeichenkette an. Damit kann auf Zeichen innerhalb der Zeichenkette zugegriffen werden, indem ihre Position berechnet wird, anstatt die komplette Zeichenkette von Anfang an decodieren zu müssen.
Im Zusammenhang mit den Codierungen fallen gelegentlich auch die Begriffe UCS-2 und UCS-4. Bei UCS-2 handelt es sich um eine obsolete Codierung, welche nur die Code Points der Basic Multilingual Plane codieren konnte. UCS-4 hingegen ist gleichbedeutend mit UTF-32. Die Begrifflichkeit UCS kommt vom Universal Coded Character Set aus der Norm ISO/IEC 10646.
Daneben gibt es Codierungen wie UTF-EBCDIC, welche dafür gedacht waren, Unicode auf entsprechende Mainframe-Rechnern, welche mit der EBCDIC-Codierung arbeiten, zu bringen. In der Praxis wird auf solchen Systemen, wie z/OS, aber meist UTF-16 genutzt.
Der Unterschied zwischen Codierungen fester Breite gegenüber denen variabler Breite liegt im Aufwand, die entsprechende Codierung auszuwerten. Bei den Codierungen variabler Breiten, muss ein entsprechender Rechenaufwand in das Lesen der Codierungen gesteckt werden. Dieser entfällt bei Codierungen fester Breite, allerdings ist hier der Speicherbedarf höher als bei den Codierungen variabler Breite.
Byte Order Mark
Doch wie wird erkannt, in welcher Codierung ein Dokument vorliegt? Dafür existiert das Byte Order Mark, kurz BOM. Dieses steht am Anfang einer Datei und teilt die genutzte Codierung mit.
Für UTF-8 haben viele ein solches BOM sicherlich schon einmal gesehen:

Als hexadezimale Repräsentation sieht dieses dann wie folgt aus:
EF BB BF
Bei den UTF-16 und UTF-32 Codierungen muss die Endianness, also die Reihenfolge der Bytes berücksichtigt werden. Dies wird mit dem Byte Order Mark, wie der Name es andeutet, bewerkstelligt. Ein Beispiel eines UTF-16 BOM:
FE FF (Big Endian)
FF FE (Little Endian)
Die Nutzung des Byte Order Mark ist optional. Ist keines gesetzt, so wird automatisch davon ausgegangen, dass die Byte-Reihenfolge Big-Endian ist.
ISO und Unicode
Mit dem Standard ISO/IEC 10646, dem Universal Coded Character Set sind die Zeichen des Unicodes auch in einem ISO-Standard verewigt. Mittlerweile werden der ISO-Standard und Unicode synchronisiert; das bedeutet, sie definieren die gleichen Zeichen.
Allerdings existieren Unterschiede zwischen diesem Standard und Unicode. Während die Namen und Code Points in beiden Standards gleich sind, spezifiziert der Unicode Standard Regeln zur Interoperabilität und liefert weitere Dinge wie entsprechende Algorithmen mit. Im Vergleich dazu stellt der ISO-Standard nur eine Zeichentabelle dar.
Im Laufe der Zeit
Während im Oktober 1991 die Unicode-Version 1.0.0, mit 7129 Code Points, veröffentlicht wurde, ist die aktuelle Version 14.0 im September 2021 erschienen und definiert ein Vielfaches an Code Points im Standard.
Dabei sind von Version zu Version immer wieder neue Zeichen hinzugekommen. Der Unicode-Standard legt fest, dass einmal eingebrachte Zeichen nie wieder aus dem Standard entfernt werden dürfen. Das bedeutet, dass sich gut überlegt werden muss, ob ein Zeichen wirklich dem Standard zugeschlagen wird.
Allerdings ist dies nicht immer so gewesen. In der Frühzeit des Standards bis einschließlich Version 2.0, welche im Juli 1996 erschien, wurden unter anderem das koreanische Alphabet in Version 2.0 entfernt und durch neue Zeichen an einer anderen Stelle in der Codeplane ersetzt. Auch in den vorherigen Versionen 1.1 und 1.0.1 wurden Zeichen entfernt.
Ab der Version 2.1 des Standards wurde sich von dieser Praxis gelöst und seitdem wird der Standard nur noch erweitert. Wird nun von der Nutzung eines Zeichens abgeraten, so wird dieses im Unicode-Standard als deprecated gekennzeichnet.
Im Oktober 2010 wurden mit dem Unicode-Standard 5.2 nicht nur Symbole für Spielkarten und weitere Schriftsysteme hinzugefügt, sondern auch Emojis feierten ihr Debüt in dieser Version. Gab es ursprünglich 722 definierte Emojis, sind diese mittlerweile angewachsen und verfügen auch über die Unterstützung unterschiedliche Hautfarben anzeigen zu können.
Mit Version 1.40 sind 144.697 Code Points definiert. Damit ist in etwa ein Siebtel des Codespace belegt. Dass das klingonische Schriftsystem darunter ist, ist im Übrigen ein Gerücht. Allerdings werden klingonische Zeichen über die privaten Bereiche des Unicode-Codespaces genutzt. Für diese privaten Bereiche innerhalb des Codespace gibt es mit der Under-ConScript Unicode Registry eine Art informelle Registry für diese.
Umsetzung in der IT
Standards und damit auch der Unicode-Standard sind nur dann sinnvoll, wenn sie umgesetzt und genutzt werden. Aktuelle Windows-Versionen und macOS-Versionen nutzen für die interne Repräsentation von Unicode UTF-16, bei Linux ist es UTF-8. Damit ist die grundlegende Nutzung in den entsprechenden Betriebssystemen gegeben.
In den Betriebssystemen selbst gibt es für den Nutzer unterschiedliche Möglichkeiten Unicode-Zeichen einzusetzen. Viele Varianten arbeiten mit der Eingabe der entsprechenden ID des Code Points in dezimaler oder hexadezimaler Repräsentation in Verbindung mit einer Taste. Unter Windows kann die Alt-Taste in Verbindung mit der entsprechenden ID zur Eingabe genutzt werden. Auch unter Linux und macOS sind solche Eingaben möglich, wobei diese unter macOS explizit aktiviert werden müssen.
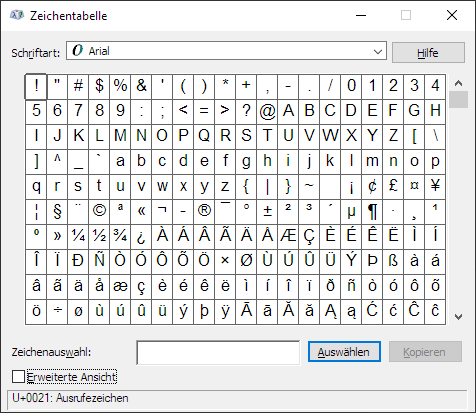
Die Zeichentabelle unter Windows 10
Daneben existieren in den Betriebssystemen auch entsprechende Applikationen, wie die Zeichentabelle unter Windows, mit der Unicode-Zeichen über ein entsprechendes Interface herausgesucht und genutzt werden können.
Bei Programmiersprachen wie Java oder den auf .NET basierenden Sprachen wird intern ebenfalls mit UTF-16 gearbeitet. Unter Rust kann der primitive Typ einen sogenannten Unicode scalar value speichern. Dieser entspricht einem Code Point; allerdings sind die sogenannten Low- und High-Surrogate, welche für UTF-16 benötigt werden, hier nicht mit eingeschlossen.
Interessant ist auch die Betrachtung von Fonts in Bezug auf Unicode. Die erste Frage, die sich hier vielleicht stellt, ist ob ein Font existiert, welcher alle Unicode-Zeichen unterstützt.
Aus technischen Gründen ist dies schon nicht möglich. So kann eine TrueType-Schriftart maximal 65.535 Glyphen enthalten. Auch im OpenType-Format ist eine solche Beschränkung enthalten.

Einer der Fonts aus der Noto-Familie
Allerdings gibt es Font-Familien wie Noto, welche von Google beauftragt wurde und mittlerweile über 77.000 Code Points des Unicodes-Standards abdeckt. Daneben gibt es eine Reihe weiterer Fonts wie GNU Unifont oder WenQuanYi, welche ebenfalls eine Vielzahl an Zeichen aus dem Unicode-Zeichensatz unterstützen.
Der Name der Schriftartfamilie Noto steht für No Tofu und spielt auf das Kästchen an, welches angezeigt wird, wenn ein Font ein entsprechendes Unicode-Zeichen nicht enthält. Früher wurde hierbei häufig der Replacement Character, welcher sich in der Basic Multilingual Plane befindet, genutzt. Dieser zeigt eigentlich an, dass ein Zeichen nicht als valides Unicode-Zeichen erkannt werden konnte, also ein Kodierungsfehler vorliegt. Heutzutage wird für den Fall, dass ein valides Unicode-Zeichen vom Font nicht dargestellt werden kann, die .notdef Glyphe des entsprechenden Fonts angezeigt.
Auch bei der softwareseitigen Unterstützung von Unicode gibt es hier und da Probleme. So wurden bis in die 2000er-Jahre hauptsächlich die Code Points aus der Basic Multilingual Plane unterstützt. Andere Planes waren nicht wirklich zugänglich.
Auch die Zusammensetzung von Zeichen aus mehreren Code Points wird von vielen Anwendungen nicht richtig beherrscht. Gebessert hat sich dies unter anderem durch den Standard GB 18030 der chinesischen Regierung, welcher ebenfalls die entsprechenden Zeichen aus der Codeplane unterstützt und damit ein Unicode Transformation Format darstellt.
Dieser Standard definiert, welche Zeichen zwingend in entsprechenden Betriebssystemen und Anwendungen unterstützt werden müssen und brachte damit die Unicode-Unterstützung jenseits der Basic Multilingual Plane voran.
Auch in anderen Anwendungen, wie E-Mail kann Unicode dank des MIME-Standards seit vielen Jahren genutzt werden. Für die Codierungen von Domainnamen, mit Nicht-ASCII-Zeichen, waren ebenfalls Unicode Transformation Formate in der Entwicklung (UTF-5, UTF-6), allerdings hat sich hier Punnycode durchgesetzt.
Trotz der Durchdringung der Unicode-Standards, kommt es immer wieder zu kleineren und größeren Problemen mit ihm. So akzeptierte Outlook 2016 keine Passwörter mit Unicode-Zeichen und ein Schriftzeichen der Sprache Telugu führte zu Problemen unter iOS und macOS.
Kritik
Der Unicode-Standard ist nicht perfekt und so gab und gibt es immer wieder Kritik an diesem. Einer dieser Punkte ist die Han-Vereinheitlichung. Bei dieser ging und geht es darum, die Zeichen aus den unterschiedlichen ostasiatischen Sprachen auf ihre Grundformen zurückzuführen und diese entsprechend im Unicode-Standard abzubilden. Dies führte zu einiger Kritik, obwohl hierbei möglichst alle betroffenen Sprachgruppen eingebunden wurden, da teilweise Zeichen vereinheitlicht wurden, welche nicht unbedingt dieselbe Bedeutung hatten.
Auch das besagte Mapping bestehender Zeichensätze in den Unicode-Standard, wie im Abschnitt über die Altlasten beschrieben, war ein solcher Kritikpunkt.
Aus der Sicht der IT-Sicherheit wird manchmal die Nutzung von Homoglyphen kritisiert, da dort bestimmte Zeichen durch andere, ähnliche aussehende Zeichen ausgetauscht werden, um z. B. eine Domain einer Bank zu imitieren und den Kunden so um seine Zugangsdaten zu bringen. Ein bekanntes Beispiel hier ist der Austausch des Buchstabens O durch eine 0, welches schon beim ASCII-Standard funktionierte. Mit dem Unicode-Standard sind viele weitere Möglichkeiten für solche Homoglyphen dazugekommen.
Auch die Sortierung und Groß- und Kleinschreibung kann sich im Codespace von Unicode und entsprechender lokaler Regelungen manchmal als schwierig erweisen, da sich z. B. die Sortierreihenfolge nicht unbedingt aus der Anordnung der Zeichen innerhalb des Codespace ergibt.
Die Zukunft
Unicode ist bisher nicht überall angekommen. So wird der Standard ISO/IEC 8859-15 respektive Latin-9 als 8-Bit-Code weiterhin verwendet. Genutzt wird diese Codierung unter anderem bei amtlichen Werken wie der elektronischen Gesundheitskarte.
Im Internet sind mittlerweile über 97,6 % aller Webseiten als UTF-8 kodiert, 1,1 % als ISO-8859-1 und noch mal knapp ein Prozent entfallen auf die Codierungen Windows-1251 und Windows-1252.
Alte Zeichensätze und Codierungen werden über kurz oder lang ein Nischendasein führen und zum Großteil durch Unicode ersetzt werden, zumindest was moderne System angeht.
Im Rahmen der Script Encoding Initiative von Deborah Anderson, welche sie seit 2002 an der University of California in Berkeley betreibt, werden neue Schriftsysteme für den Standard vorgeschlagen, sodass auch in Zukunft weitere Zeichen in den Standard aufgenommen werden.
So zog 2016, mit Adlam, ein ungewöhnliches Schriftsystem in den Standard ein. Ungewöhnlich deshalb, weil dieses System erst seit 1989 existiert. Zwei Brüder entwickelten dieses System, um ihre Sprache, Fulani, phonetisch in einem Schriftsystem abbilden zu können. Etliche Jahre später wurde das System dank der Unterstützung der Script Encoding Initiative schließlich in den Unicode-Standard übernommen und wird mittlerweile unter Windows, Chrome OS sowie Android unterstützt.
Dieses Beispiel zeigt, wie Unicode eine Grundlage für die Nutzung und Überführung von Schriftsystemen in die digitale Welt ist. Noch einige Jahrzehnte zuvor war ein Großteil des Internets und der IT auf einige lateinische Buchstaben reduziert. Dank Unicode ist es möglich in seiner jeweiligen Muttersprache und in seinem angestammten Schriftsystem digital zu kommunizieren, sich zu informieren und teilzuhaben.
Das Unicode Consortium wird seine Arbeit fortsetzen und sich dabei auch in einem teilweise politischen Spannungsfeld bewegen. Wie Randall Munroe, Autor des xkcd-Comics, dazu einmal sagte:
I am endlessly delighted by the hopeless task that the Unicode Consortium has created for themselves. […] They started out just trying to unify a couple different character sets. And before they quite realized what was happening, they were grappling with decisions at the heart of how we use language, no matter how hard they tried to create policies to avoid these problems. It’s just a fun example of how weird language is and how hard human communication is and how you really can’t really get around those problems.
So bietet uns Unicode lateinische Schrift, Spielkarten, Operatoren, Emojis, Schriftzeichen aus vielen menschlichen Kulturen und mehr. Und da sich Schrift und Sprache im Laufe der Zeit verändern, wird der Unicode-Standard wohl nie fertiggestellt, sondern ein lebendiger und sich weiterentwickelnder Standard sein.
Mit seinen 144.697 Zeichen und der Abbildung von über 150 Schriftsystemen liefert er einen Beitrag zur Erhaltung der Schriftkultur und der Daten über die Jahrzehnte. In Zeiten von Globalisierung und weltweit miteinander interagierenden Systemen ist ein gemeinsamer Zeichensatz sicherlich nicht die schlechteste Idee gewesen.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.