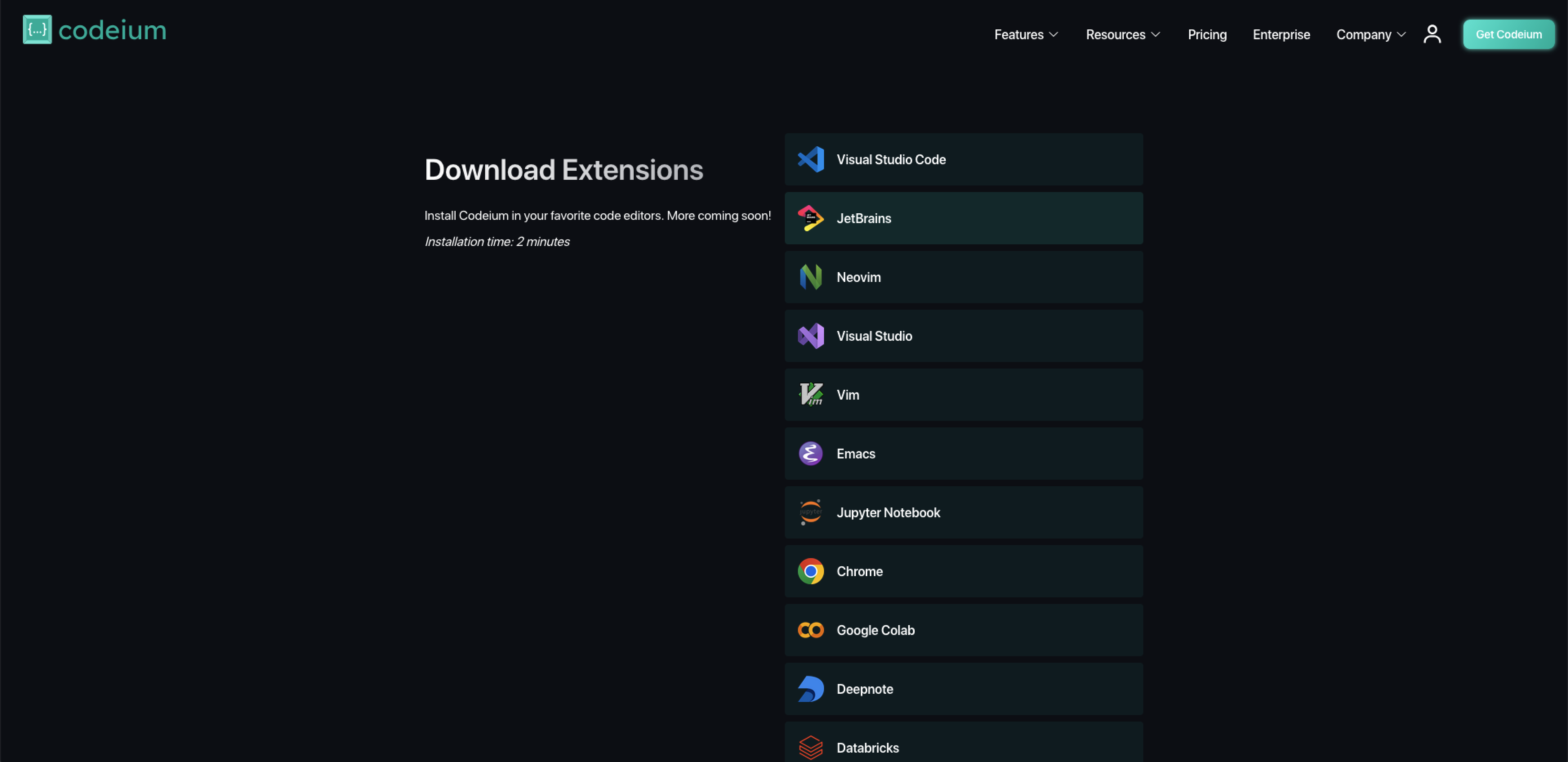
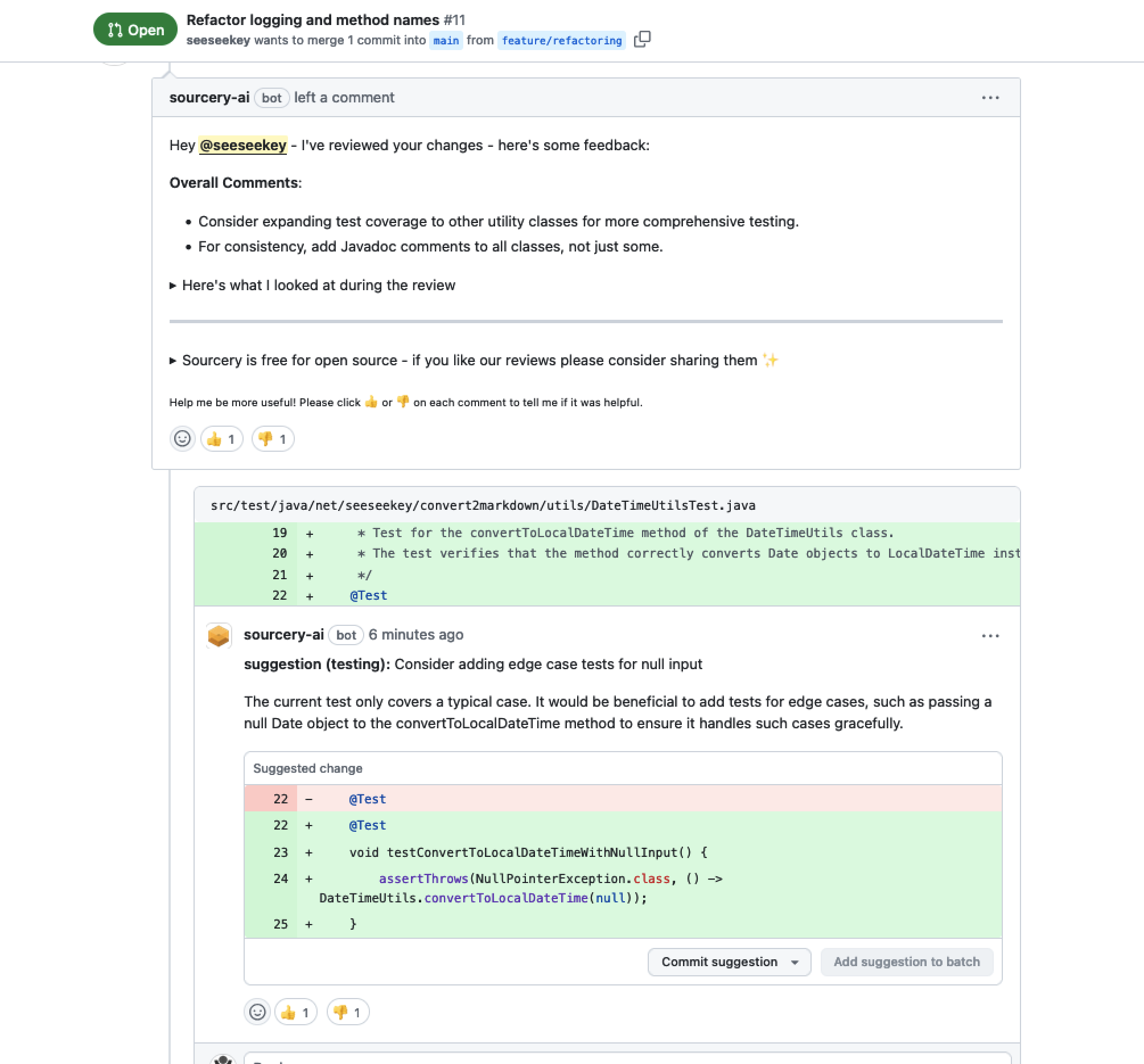
Wer den Begriff iCloud hört, denkt wohl meist an den Cloud-Speicher für Apple-Nutzer. Tatsächlich steckt hinter iCloud jedoch weit mehr. iCloud bildet die technische Grundlage für Backups, Synchronisation, Dateiverwaltung, Passwortspeicherung und eine wachsende Zahl an Funktionen im gesamten Apple-Ökosystem.
Neben der technischen Funktionalität spielen auch politische Gegebenheiten und die Frage nach digitaler Souveränität eine Rolle. Debatten über Ende-zu-Ende-Verschlüsselung, staatlichen Zugriff und die Grenzen cloudbasierter Komfortsysteme zeigen, dass iCloud längst nicht nur als Produkt verstanden werden sollte, sondern als technische und politische Infrastruktur.
Der Artikel wirft einen Blick hinter die Kulissen von iCloud und erläutert die zugrunde liegende Geschichte, Architektur und Infrastruktur, Sicherheitsmechanismen sowie Werkzeuge für Analyse und Fehlerdiagnose.
Geschichte
Im Grundsatz lässt sich die Geschichte der iCloud als eine tiefergehende Verzahnung und Funktionserweiterung beschreiben. Aus ursprünglich voneinander getrennten Einzellösungen entwickelte sich iCloud im Laufe der Jahre zu einem zentralen Bestandteil des gesamten Apple-Ökosystems.
Diese Geschichte beginnt am 5. Januar 2000, als Steve Jobs auf der Macworld Expo iTools vorstellte. Dabei handelte es sich um ein kostenloses Paket aus Mac.com-E-Mail, iDisk, HomePage-Webhosting und dem Webfilter KidSafe. iTools war ausschließlich für Mac-Nutzer gedacht und sollte das Apple-Ökosystem attraktiver machen.
Zwei Jahre später, am 17. Juli 2002, ersetzte Apple iTools durch das kostenpflichtige .Mac zum Preis von 99,95 USD pro Jahr. Die Umstellung sorgte für Unmut, da zuvor kostenlose Dienste nun bezahlt werden mussten. Der neue Service brachte IMAP-E-Mail, verbesserten iDisk-Speicher und ein Backup-Werkzeug. Allerdings galt er als überteuert und stagnierend.
Mit MobileMe, das auf der WWDC am 9. Juni 2008 angekündigt wurde, wagte Apple den Sprung auf mehrere Plattformen. Erstmals wurden Mac OS X, Windows und das iPhone OS unterstützt.
MobileMe führte eine servergestützte Push-Synchronisation für E-Mails, Kontakte und Kalender ein. Änderungen wurden nicht mehr in festen Intervallen abgefragt, sondern nach ihrer Erfassung unmittelbar an die verbundenen Geräte übertragen; damals im Privatbereich eine Seltenheit. Ein Jahr später führte MobileMe auch Find My iPhone ein.
Der Start geriet jedoch zum Desaster. Schwere E-Mail-Ausfälle, Probleme mit der Synchronisation und Datenverluste begleiteten den Start. Steve Jobs schrieb dazu in einer internen E-Mail an das MobileMe-Team unter anderem:
MobileMe was simply not up to Apple’s standards
Daraufhin wurde das MobileMe-Team organisatorisch neu aufgestellt und direkt dem Apple-Manager Eddy Cue unterstellt.
Der Neuanfang mit iCloud
Am 6. Juni 2011 stellte Steve Jobs bei einem seiner letzten öffentlichen Auftritte iCloud auf der WWDC vor. Er räumte das MobileMe-Debakel ein und erklärte:
We’re going to move the digital hub, the center of your digital life, into the cloud.
iCloud startete am 12. Oktober 2011 mit iOS 5 und Mac OS X Lion und bot erstmals 5 GB kostenlosen Speicher. Dies markierte zugleich einen Bruch mit dem reinen Bezahlmodell von MobileMe. Innerhalb einer Woche registrierten sich 20 Millionen Nutzer.
In den folgenden Jahren wurde iCloud schrittweise um wichtige Funktionen erweitert. Im Oktober 2013 führte Apple die iCloud-Schlüsselbundfunktion ein, bei der sensible Daten wie Passwörter Ende-zu-Ende-verschlüsselt gespeichert wurden.
Mit iOS 8 folgte im September 2014 iCloud Drive, ein vollwertiger Cloud-Dateispeicher, der mit Diensten wie Dropbox konkurrierte. Einen Monat später startete die iCloud-Fotomediathek, mit der Fotos und Videos zentral in der Cloud gespeichert und auf allen Geräten synchronisiert werden konnten.
Ebenfalls auf der WWDC 2014 stellte Apple das CloudKit-Framework vor. Es bot Entwicklern eine moderne Infrastruktur für Cloud-Daten und löste damit viele der Probleme, die zuvor bei der Synchronisation aufgetreten waren.
Von iCloud+ bis Advanced Data Protection
Mit iCloud+ leitete Apple im Jahr 2021 einen wichtigen Wandel in seiner Datenschutzstrategie ein. Alle zahlenden iCloud-Abonnenten erhielten ohne zusätzliche Kosten Zugriff auf mehrere neue Datenschutzfunktionen. Dazu gehörte das iCloud Private Relay, ein Proxy-System, das die IP-Adresse und das Surfverhalten in Safari besser schützt. Ebenfalls eingeführt wurde Hide My Email, mit dem sich anonyme Weiterleitungsadressen erstellen lassen, sowie die Möglichkeit, eigene E-Mail-Domains mit iCloud Mail zu verwenden.
Der eigentliche Meilenstein folgte am 7. Dezember 2022 mit der Ankündigung von Advanced Data Protection (ADP). Damit führte Apple eine optionale Ende-zu-Ende-Verschlüsselung für einen Großteil der iCloud-Datenkategorien ein, darunter iCloud-Backups, Fotos, Notizen und iCloud Drive. Ausgenommen blieben E-Mail, Kontakte und Kalender, da diese Dienste weiterhin auf offenen Standards wie IMAP, CardDAV und CalDAV basieren und serverseitige Funktionen erfordern, die einen Zugriff auf die Daten voraussetzen.
Im September 2023 erweiterte Apple die Speichertarife um 6 TB und 12 TB, während die kostenlosen 5 GB seit 2011 unverändert geblieben sind.
Dienste
Wie bereits erwähnt, besteht iCloud nicht aus einem einzelnen Dienst, sondern einer Kombination unterschiedlichster Dienste, von denen einige der wichtigsten nachfolgend kurz vorgestellt werden sollen.
iCloud Drive
iCloud Drive ist Apples cloudbasierter Dateispeicher, der tief in macOS, iOS und iPadOS integriert ist. Dateien werden automatisch zwischen Geräten synchronisiert und können wie ein klassisches Dateisystem genutzt werden.
iCloud Drive erscheint als integrierter Speicherort im Finder
Für Nutzer wirkt das iCloud Drive wie ein gewöhnlicher Ordner. Im Hintergrund gleicht das System zunächst Metadaten wie Dateinamen, Änderungszeitpunkte und Verzeichnisstrukturen mit den iCloud-Servern ab. Anschließend werden neue und geänderte Inhalte synchronisiert.
Auf dem Mac übernehmen Hintergrunddienste wie bird und cloudd die Aufgabe, Änderungen zu erkennen, Uploads anzustoßen und Konflikte zwischen mehreren Geräten aufzulösen. Im Gegensatz zu macOS sind die beteiligten Prozesse unter iOS und iPadOS für den Anwender weitgehend verborgen.
iCloud-Fotomediathek
Die iCloud-Fotomediathek speichert Fotos und Videos zentral in der iCloud-Infrastruktur und synchronisiert sie über alle angemeldeten Geräte hinweg. Ein aufgenommenes Foto wird nicht nur als einzelne Datei abgelegt, sondern zusammen mit umfangreichen Metadaten wie Aufnahmedatum, Standort, Albenzuordnung, Bearbeitungsinformationen, HDR-Daten und Live-Foto-Komponenten verwaltet.
Die Einstellungen zur iCloud-Fotomediathek in der Fotos-App unter macOS
Die eigentlichen Bild- und Videodateien werden als Assets in einem verteilten Objektspeicher abgelegt, während Metadaten und Beziehungen zwischen den Objekten in CloudKit-Datenbanken gespeichert werden. Dadurch können Änderungen an Bearbeitungen, Alben oder Favoriten effizient synchronisiert werden, ohne jedes Mal die vollständigen Originaldateien neu übertragen zu müssen.
Zur Optimierung werden unterschiedliche Datenklassen getrennt behandelt. Vorschaubilder, Thumbnails und Bildschirmversionen stehen schnell zur Verfügung, während hochauflösende Originale bei Bedarf nachgeladen werden. Auf Geräten mit aktivierter Speicheroptimierung verbleiben lokal nur komprimierte Darstellungen, während die vollständigen HEIF-, JPEG- oder RAW-Dateien in der iCloud gespeichert bleiben.
iCloud-Backups
iCloud-Backups sichern automatisch den Zustand eines iPhones oder iPads, einschließlich App-Daten, Geräteeinstellungen, Nachrichten, Home-Bildschirm-Layouts und weiterer Konfigurationsdaten. Die Sicherung erfolgt in der Regel einmal täglich im Hintergrund, sofern das Gerät geladen wird, gesperrt und mit einem WLAN- oder Mobilfunknetz verbunden ist. Ziel dieser Backups ist die möglichst vollständige Wiederherstellung eines Geräts nach Verlust, Defekt oder beim Umstieg auf ein anderes Gerät.
Die Einstellungen für das iCloud-Backup unter iOS
Gesichert werden insbesondere Daten, die sich nicht bereits über andere iCloud-Dienste synchronisieren. Dazu zählen lokale App-Daten, Einstellungen, Gerätekonfigurationen und bestimmte Anwendungszustände. Inhalte wie Fotos, Kontakte, Kalender oder Notizen, die ohnehin separat über iCloud abgeglichen werden, sind nicht Bestandteil des Backups. Wird aber z. B. die iCloud-Fotomediathek nicht genutzt, so enthält das Backup die lokalen Fotos und Videos des Geräts.
Die Backups werden verschlüsselt in der iCloud gespeichert. Hierbei werden die eigentlichen Nutzdaten und die für Wiederherstellung und Verwaltung erforderlichen Metadaten getrennt verarbeitet. Jedes Backup besteht aus zahlreichen Einzelkomponenten, die bei Bedarf auf ein neues Gerät übertragen werden können. Dadurch lässt sich ein iPhone oder iPad nach der Anmeldung mit dem Apple Account weitgehend in den Zustand zum Zeitpunkt der letzten Sicherung zurückversetzen.
iCloud-Schlüsselbund
Der iCloud-Schlüsselbund synchronisiert Passwörter, WLAN-Zugangsdaten, Kreditkartendaten und weitere sensible Informationen sicher zwischen den Geräten eines Nutzers. Diese Daten stehen dadurch auf anderen Apple-Geräten automatisch zur Verfügung und sind eng mit Systemfunktionen wie AutoFill, Safari, der Passwort-App und der WLAN-Konfiguration verknüpft.
Neben der eigentlichen Synchronisation der Schlüsselbunddaten existiert ein Wiederherstellungsverfahren für den Fall, dass alle vertrauenswürdigen Geräte verloren gehen. Die gespeicherten Informationen werden bereits auf dem Gerät verschlüsselt und anschließend Ende-zu-Ende-gesichert über iCloud übertragen. Apple speichert lediglich verschlüsselte Datenblöcke und besitzt keine Schlüssel, mit denen sich die Inhalte entschlüsseln ließen.
Die kryptographischen Schlüssel werden in der Secure Enclave beziehungsweise im geschützten Schlüsselbund des Geräts erzeugt und verwaltet. Nur Geräte, die ausdrücklich vom Nutzer autorisiert wurden, erhalten Zugriff auf diese Schlüssel und können die Daten entschlüsseln. Wird ein neues Gerät hinzugefügt, muss es zunächst von einem bereits vertrauenswürdigen Gerät bestätigt oder über ein spezielles Wiederherstellungsverfahren legitimiert werden.
Mail, Kalender, Kontakte und Erinnerungen
iCloud Mail ist Apples E-Mail-Dienst, der IMAP-basiert arbeitet und sich in die Mail-Apps der Plattformen integriert. Neben klassischem E-Mail-Versand bietet er Spamfilter, Alias-Adressen und eine enge Kopplung an den Apple Account.
Diese Dienste basieren auf etablierten Internetstandards. iCloud Mail verwendet IMAP und SMTP über verschlüsselte TLS-Verbindungen, während iCloud Kalender und Kontakte über die Standards CalDAV und CardDAV bereitgestellt werden.
Der iCloud-Kalender synchronisiert Termine und Erinnerungen über alle Geräte hinweg und ermöglicht das Teilen von Kalendern mit anderen Nutzern. Änderungen werden nahezu in Echtzeit propagiert, was eine konsistente Terminplanung über verschiedene Geräte und Nutzer hinweg erlaubt.
Der Kontakte-Dienst speichert und synchronisiert Adressbuchdaten zentral. Änderungen an Kontakten werden auf allen verbundenen Geräten aktualisiert. Der Dienst dient zudem als Grundlage für andere Funktionen wie E-Mail, Telefonie und Messaging.
Der Erinnerungen-Dienst synchronisiert Aufgabenlisten und Todos zwischen Geräten. Er unterstützt strukturierte Listen, Prioritäten und zeitbasierte Erinnerungen und ist eng mit dem Kalender verbunden.
Notizen
iCloud-Notizen ermöglicht das Speichern und Synchronisieren von Texten, Checklisten, Bildern und Dokumenten. Die Daten werden in Echtzeit abgeglichen und können zwischen Nutzern geteilt werden.
Wo ist?
Wo ist? kombiniert die klassische Geräteortung mit einem weltweiten Crowd-Netzwerk aus hunderten Millionen Apple-Geräten. Verlorene iPhones, iPads, Macs oder AirTags können auch dann lokalisiert werden, wenn sie keine aktive Internetverbindung besitzen. Dazu senden sie regelmäßig kryptografisch gesicherte Bluetooth-Signale aus, die von vorbeikommenden Apple-Geräten empfangen und an die iCloud weitergeleitet werden.
Die gesamte Kommunikation erfolgt Ende-zu-Ende-verschlüsselt. Apple erhält lediglich verschlüsselte Standortinformationen und kann weder nachvollziehen, welches Gerät die Positionsdaten gemeldet hat, noch welchem Nutzer das verlorene Gerät gehört. Selbst das weiterleitende Apple-Gerät erfährt nicht, welches Objekt es gerade unterstützt hat.
Neben der Ortung bietet Wo ist? weitere Funktionen wie das Abspielen eines Tons, das Anzeigen einer Nachricht auf dem Sperrbildschirm, die Aktivierung des Verloren-Modus sowie das ferngesteuerte Löschen eines Geräts. Durch die Integration der Aktivierungssperre bleibt ein verlorenes oder gestohlenes Gerät zudem an den Apple Account des Besitzers gebunden und kann ohne dessen Zugangsdaten nicht erneut eingerichtet werden.
Nachrichten
Mit Messages in iCloud werden iMessage-Inhalte nicht mehr ausschließlich lokal auf den einzelnen Geräten gespeichert, sondern zusätzlich in der iCloud vorgehalten und zwischen allen angemeldeten Geräten synchronisiert.
Dadurch bleibt der Nachrichtenbestand konsistent, während ältere Nachrichten und Anhänge bei Bedarf aus der Cloud nachgeladen werden können. Änderungen wie das Löschen, Bearbeiten oder Reagieren auf Nachrichten werden über die Synchronisationsmechanismen der iCloud auf alle Geräte übertragen.
Private Relay
Private Relay ist ein Datenschutzdienst, der Webanfragen über mehrere Server leitet, um IP-Adresse und Surfverhalten zu verschleiern. Er steht jedem Nutzer von iCloud+ zur Verfügung. Dabei wird die Anfrage in zwei Schritte aufgeteilt, sodass kein einzelner Anbieter sowohl Identität als auch Ziel kennt.
Es handelt sich nicht um ein VPN, sondern um ein Dual-Hop-Proxy-System, das sicherstellt, dass keine einzelne Partei sowohl die IP-Adresse des Nutzers als auch dessen Browsing-Aktivitäten kennt. Der erste Hop wird von Apple betrieben und sieht die IP-Adresse des Nutzers, aber nicht die Zielwebsite. Der zweite Hop wird von ausgewählten externen CDN- und Infrastrukturpartnern wie Akamai, Cloudflare und Fastly bereitgestellt. Er sieht die Zielwebsite, aber nicht die echte IP-Adresse.
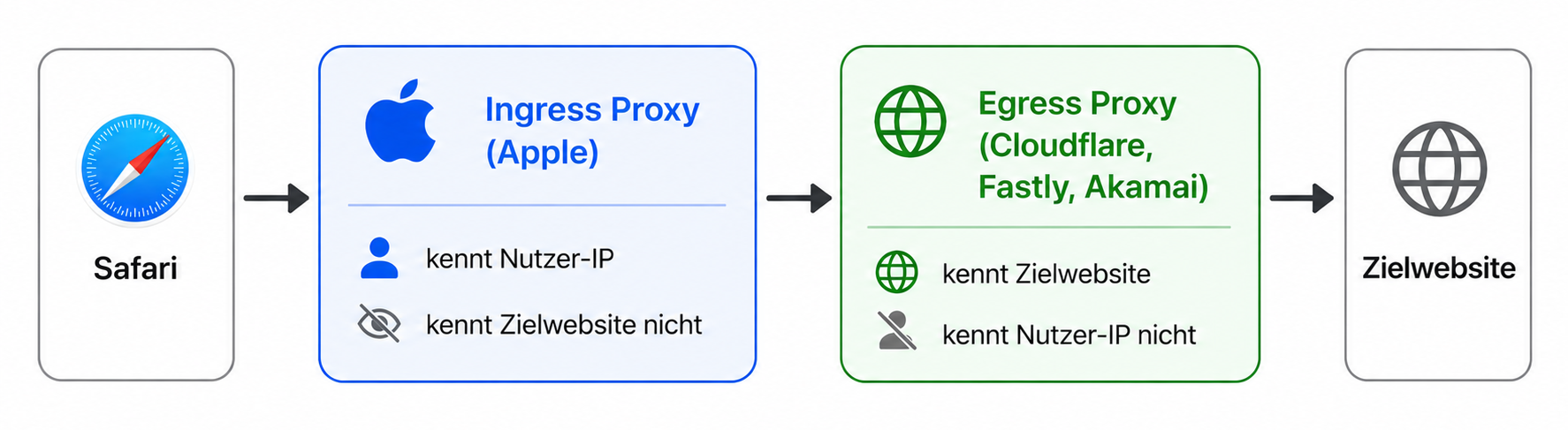
Die Funktionsweise des Private Relay
Technisch basiert das System auf dem MASQUE-Protokoll über HTTP/3 und QUIC, mit Fallback auf HTTP/2. DNS-Anfragen werden über datenschutzfreundliche Verfahren wie Oblivious DNS over HTTPS übertragen.
Private Relay schützt primär den Safari-Webverkehr. Andere Anwendungen und Browser werden nicht umfassend durch Private Relay abgesichert.
Hide My Email
Hide My Email generiert zufällige, eindeutige E-Mail-Adressen, die Nachrichten automatisch an die tatsächliche E-Mail-Adresse des Nutzers weiterleiten. Dadurch können Nutzer ihre echte Adresse gegenüber Onlinediensten verbergen und das Risiko von Spam, Tracking oder Datenweitergaben reduzieren.
Jede erzeugte Adresse kann individuell verwaltet und bei Bedarf jederzeit deaktiviert werden, ohne dass die eigentliche E-Mail-Adresse geändert werden muss. Eingehende Nachrichten werden transparent weitergeleitet, während Antworten weiterhin über die zufällige Alias-Adresse versendet werden können, sodass die echte Adresse verborgen bleibt.
Architektur
iCloud selbst basiert im Kern auf Apples CloudKit-Architektur. Technisch handelt es sich um eine verteilte Datenbank- und Synchronisationsplattform, die nicht einfach eine Datenbank bereitstellt, sondern Milliarden einzelner, logisch getrennter Datenbereiche verwaltet.
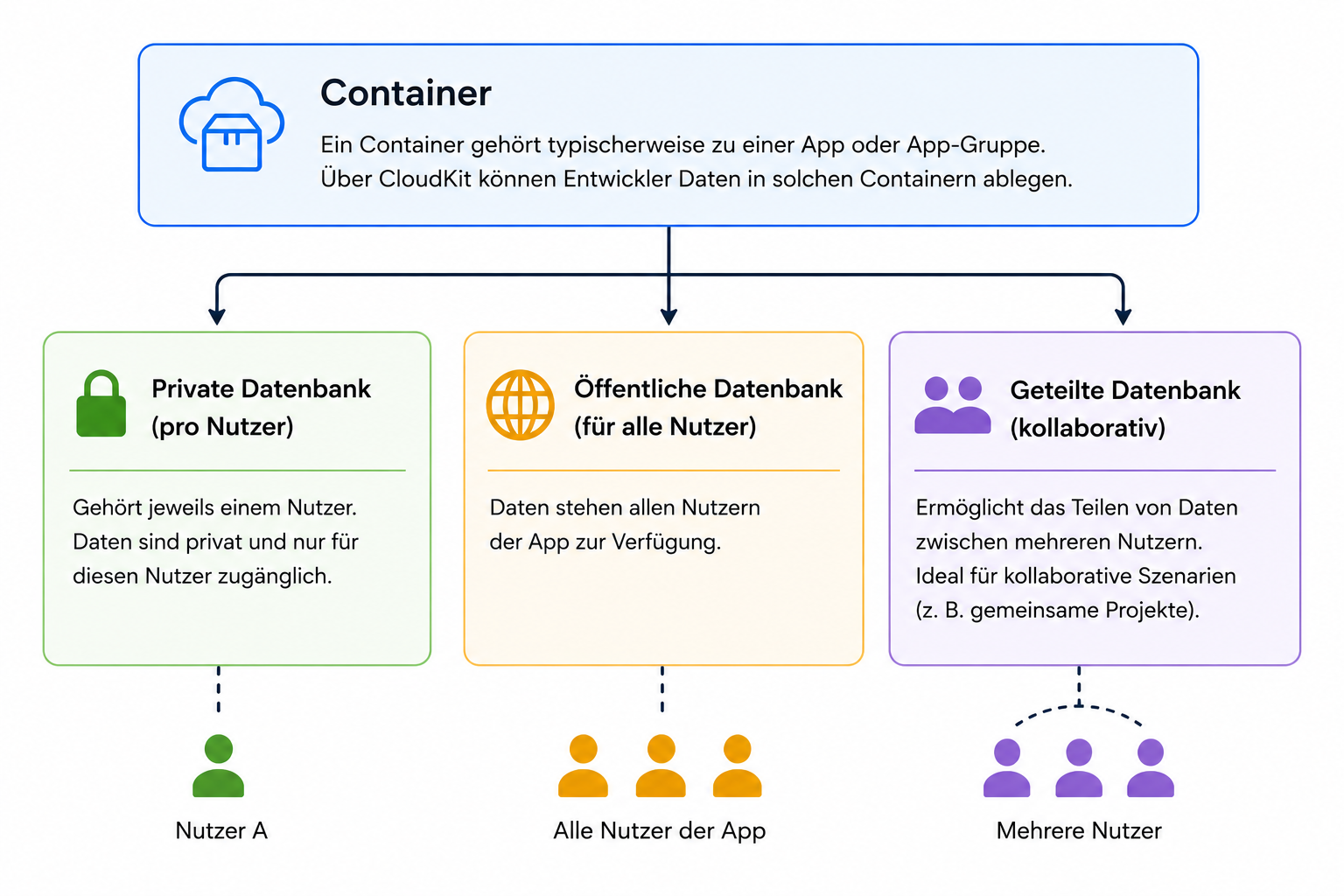
Container und Datenbanken in CloudKit
CloudKit kapselt diese Daten in einer Entwickler-API, die hierarchisch organisiert ist. Auf der obersten Ebene liegt der Container. Ein Container gehört typischerweise zu einer App oder App-Gruppe; darin können Daten in privaten, öffentlichen oder geteilten Datenbanken liegen. Jeder App-Entwickler kann über CloudKit Daten in solchen Containern ablegen. Private Datenbanken gehören jeweils einem Nutzer, öffentliche Datenbanken stehen allen Nutzern einer App zur Verfügung und geteilte Datenbanken ermöglichen kollaborative Szenarien.
Innerhalb dieser Datenbanken organisiert CloudKit die Daten weiter in sogenannten Record Zones, die als logische Container für die eigentlichen Datensätze dienen. Die Datensätze selbst werden als Records gespeichert und können über definierte Schemata, Indizes und Abfragemechanismen effizient verwaltet und durchsucht werden.
Im Backend setzt Apple auf eine stark skalierbare Architektur. Frühere technische Einblicke nennen Apache Cassandra für die Datenspeicherung und Apache Solr für Indizes. Damit gehörte Apple zu den weltweit größten Cassandra-Anwendern. Öffentlichen Angaben zufolge umfasste die Infrastruktur zehntausende Cassandra-Knoten und verarbeitete Datenmengen im Exabyte-Bereich.
Später entwickelte Apple zusätzlich den auf FoundationDB basierenden CloudKit Record Layer, der eine höhere Datenmodellschicht für Records, Indizes und Abfragen bereitstellt. Dadurch lassen sich Milliarden logisch getrennter Datenbereiche effizient verwalten, ohne dass Anwendungen direkt mit den zugrunde liegenden Speichersystemen interagieren müssen.
Mittlerweile deutet vieles darauf hin, dass FoundationDB zusammen mit dem CloudKit Record Layer den wesentlichen Bestandteil der heutigen CloudKit-Infrastruktur bildet. FoundationDB fungiert hierbei als verteilter, transaktionaler Key-Value-Store mit ACID-Eigenschaften.
Infrastruktur
Die physische iCloud-Infrastruktur basiert auf einem hybriden Modell aus eigenen Rechenzentren und Diensten von Drittanbietern. Apple betreibt einige große Rechenzentren in den USA sowie in Dänemark und China.
Parallel nutzt Apple Amazon S3 und Google Cloud Platform als primäre Speicherplattform für verschlüsselte Nutzerdaten. Apple gilt als einer von Googles größten Speicherkunden und lagerte 2021 über 8 Exabyte Daten auf der Google Cloud. Seit 2016 setzte Apple verstärkt auf Google Cloud, während Azure für Apple an Bedeutung verlor.
Das entscheidende Architekturprinzip ist, dass alle Nutzerdaten vor dem Upload auf Drittanbieter-Server auf dem Gerät verschlüsselt werden. Die Schlüssel und Metadaten verbleiben auf Apples eigener Infrastruktur. Sicherheitskritische Dienste wie Siri-Verarbeitung, App Store, Apple Pay und die Schlüsselverwaltung laufen ausschließlich auf Apple-eigener Hardware.
Zusätzlich zur Backend-Infrastruktur setzt Apple auf ein weltweites CDN-Netzwerk. Dieses übernimmt die Auslieferung von Webinhalten, Medienobjekten und anderen häufig abgerufenen Daten und ergänzt damit die eigentlichen Speicher- und Synchronisationsdienste der iCloud.
Verschlüsselung
Alle iCloud-Daten werden bei der Übertragung mit TLS gesichert. Der Umfang der serverseitig gespeicherten Daten sowie deren kryptographischer Schutz unterscheidet sich je nachdem, ob Standard Protection oder die Advanced Data Protection aktiv ist.
Die meisten Datenkategorien wie Fotos, iCloud Drive, Backups, Mail, Kalender und Kontakte werden auf Apples Servern verschlüsselt; die Schlüssel liegen in Apples Hardware-Sicherheitsmodulen. Apple kann theoretisch auf diese Daten zugreifen und ist grundsätzlich in der Lage, Behördenanfragen nachzukommen. Mehrere besonders sensible Kategorien sind davon ausgenommen und standardmäßig Ende-zu-Ende-verschlüsselt, darunter der iCloud-Schlüsselbund, Gesundheitsdaten, HomeKit-Daten und Zahlungsinformationen.
Advanced Data Protection erweitert den Ende-zu-Ende-Schutz auf einen Großteil der weiteren Kategorien, einschließlich Backups, Fotos und iCloud Drive.
Bei der Aktivierung von Advanced Data Protection startet das Gerät eine Schlüsselrotation für die betroffenen iCloud-Dienste. Hierbei werden neue Schlüssel erzeugt, die ausschließlich durch die vertrauenswürdigen Geräte des Nutzers kontrolliert werden. Die zuvor in Apples Rechenzentren verfügbaren Schlüssel werden aus der Schlüsselverwaltung entfernt, sodass neu gespeicherte Daten nur noch mit den neuen, Ende-zu-Ende-geschützten Schlüsseln entschlüsselt werden können.
Die Synchronisation dieser Schlüssel erfolgt über den bereits Ende-zu-Ende-verschlüsselten iCloud-Schlüsselbund. Ausgenommen bleiben Mail, Kontakte und Kalender, da diese Dienste weiterhin auf interoperablen Standards wie IMAP, CardDAV und CalDAV basieren.
Der Zugriff über icloud.com wird bei aktivierter ADP standardmäßig deaktiviert. Er lässt sich im Bedarfsfall reaktivieren. Anschließend autorisiert ein vertrauenswürdiges Gerät den Webzugriff zeitlich begrenzt durch temporäre, an die jeweilige Sitzung gebundene Schlüssel.
Chunking
Nach öffentlich dokumentierten Sicherheitsunterlagen von Apple werden Dateien in iCloud in verschlüsselte Datenblöcke (Chunks) zerlegt und getrennt von ihren Metadaten gespeichert. Die verschlüsselten Datenblöcke können auf externen Speichersystemen abgelegt werden, während Apple die Schlüsselverwaltung und Metadaten kontrolliert.
Frühere Apple-Sicherheitsdokumente beschreiben hierfür eine Verschlüsselung der einzelnen Chunks mit AES-128, wobei die Schlüssel mittels SHA-256 aus dem jeweiligen Datenblock abgeleitet werden. Die konkrete Implementierung und die verwendeten Algorithmen können sich jedoch im Laufe der Zeit geändert haben.
Synchronisation
Die Synchronisation innerhalb der iCloud erfolgt weitgehend automatisch und wird von Apple-Diensten sowie den jeweiligen Frameworks gesteuert. Dabei steht nicht die sofortige Übertragung jeder Änderung im Vordergrund, sondern ein ausgewogenes Verhältnis zwischen Energieverbrauch, Netzwerkauslastung und Datenkonsistenz.
So regeln Apple-Dienste die Synchronisationsfrequenz selbstständig. Beispielsweise garantiert Core Data in Verbindung mit CloudKit keine Echtzeit-Synchronisation, sondern nutzt die vom jeweiligen Betriebssystem bereitgestellten Hintergrundmechanismen. Anwendungen können eine Synchronisation daher in der Regel nicht erzwingen. Dies gilt sowohl für iOS als auch für macOS, auch wenn dort Hintergrundaktivitäten meist großzügiger behandelt werden.
Je nach Dienst unterscheiden sich die Synchronisationsmechanismen. CloudKit bietet innerhalb von Record Zones Konsistenzgarantien für Änderungen an Datensätzen, während iCloud Drive auf die geräteübergreifende Synchronisation von Dateien ausgerichtet ist. Darüber hinaus berücksichtigt das System Faktoren wie Netzwerkverbindung, Akkustand und Gerätezustand. Bei niedrigem Akkustand oder hoher Last pausiert das System die Synchronisation und auch Mechanismen zur Drosselung sind vorgesehen.
Treten Bearbeitungskonflikte auf, etwa wenn dieselbe Datei auf mehreren Geräten gleichzeitig verändert wird, speichert iCloud Drive mehrere Dokumentversionen und fordert den Nutzer gegebenenfalls zur Konfliktauflösung auf. Für CloudKit-Daten stellt die Plattform Mechanismen zur Konflikterkennung bereit. So können Entwickler auch eigene Strategien zur Konfliktbehandlung implementieren.
Der Ablauf der Synchronisation folgt einem festen Muster. Geräte übertragen Änderungen an CloudKit, wo sie in der zugrunde liegenden Datenbank gespeichert werden. Anschließend informiert CloudKit andere Geräte per Push-Benachrichtigung über verfügbare Änderungen. Diese laden die fehlenden Daten anschließend vom Server nach.
Weiterhin unterliegen die verschiedenen iCloud-Dienste bestimmten Kapazitäts- und Nutzungslimits. Private CloudKit-Datenbanken verfügen über nutzerbezogene Speichergrenzen, während öffentliche Container eigene Vorgaben besitzen. Anwendungen müssen solche Einschränkungen berücksichtigen und entsprechende Fehlerfälle behandeln.
Andere iCloud-Dienste verwenden ebenfalls eigene Nutzungs- und Kapazitätsgrenzen. So gelten für iCloud Mail etwa Beschränkungen hinsichtlich der Nachrichtengröße, der Anzahl versendbarer Nachrichten sowie der Zahl der Empfänger pro Tag.
Authentifizierung und Identität
Der Apple Account (früher Apple ID) bildet die zentrale Identität für iCloud und andere Apple-Dienste. Nutzer authentifizieren sich mit ihrem Account und erhalten nach erfolgreicher Anmeldung kryptografisch geschützte Sitzungstoken, die für weitere Zugriffe auf die Dienste verwendet werden.
Zum Schutz des Kontos setzt Apple standardmäßig auf Zwei-Faktor-Authentifizierung. Bei der Anmeldung auf einem neuen Gerät oder in einem Browser müssen neben dem Passwort ein sechsstelliger Bestätigungscode sowie gegebenenfalls weitere Vertrauensnachweise erbracht werden. Der Code wird auf einem vertrauenswürdigen Gerät angezeigt oder an eine hinterlegte Telefonnummer gesendet.
Beim Zugriff auf bestimmte Ende-zu-Ende-verschlüsselte iCloud-Daten kann zusätzlich die Eingabe des Gerätecodes eines bereits vertrauenswürdigen Geräts erforderlich sein. Dadurch wird nachgewiesen, dass der Nutzer Zugriff auf ein autorisiertes Gerät besitzt und die für die Entschlüsselung benötigten Schlüssel verwenden darf.
Diagnose
In der Praxis erweist sich iCloud in vielen Fällen als stabil. Doch manchmal treten Probleme auf. Vor allem in früheren Iterationen des iCloud-Systems war dies häufiger der Fall. Typische Probleme bei der Nutzung von iCloud sind Synchronisationskonflikte oder ausbleibende Aktualisierungen zwischen Geräten.
Besonders relevant für die iCloud sind die Dienste cloudd (CloudKit), bird (iCloud Drive) und cloudphotod (Fotos). Für einen dieser Dienste können die Logs unter macOS mittels log eingesehen werden:
log show –predicate ‚process == „cloudd“‚ –last 1h
Alternativ kann die Console-Applikation genutzt werden.
Anekdotisch wird oft berichtet, dass sich viele iCloud-Probleme durch einen Neustart und längeres Warten lösen lassen. Vor allem das initiale Setup größerer Datenmengen wie einer neuen Fotomediathek oder größerer iCloud-Drive-Bestände, kann mehrere Stunden bis Tage in Anspruch nehmen.
Kommt die Synchronisation ins Stocken, hilft auf dem Mac häufig ein Neustart der beteiligten Hintergrunddienste:
killall bird
killall cloudd
Auch Netzwerkprobleme können die Synchronisation beeinträchtigen. Da iCloud über HTTPS kommuniziert, müssen die entsprechenden Verbindungen über TCP-Port 443 erreichbar sein. Firewalls, VPN-Dienste oder Netzwerkfilter können den Datenaustausch behindern. Bei Verdacht auf allgemeine Störungen lohnt sich ein Blick auf die System Status-Seite von Apple.
Im Terminal existiert für das iCloud Drive die Möglichkeit, das Werkzeug brctl (bird control) zu nutzen.
Der aktuelle iCloud Drive Status kann hier mittels:
brctl status
angezeigt werden. Der Befehl liefert Informationen über den Zustand der iCloud-Synchronisation, insbesondere über ausstehende Upload- und Downloadvorgänge.
Die aktuelle Synchronisationsaktivität kann mittels des Kommandos:
brctl monitor -g
angezeigt werden. Dort wird die aktuelle Aktivität in Echtzeit angezeigt. Soll der verfügbare Speicherplatz eingesehen werden, kann das Kommando:
brctl quota
genutzt werden. Für tiefergehende Diagnosen hingegen eignet sich das Kommando:
brctl dump –verbose –output=dump.txt
Damit wird ein ausführlicher Diagnose-Dump des aktuellen Zustands des iCloud Drive erstellt. Für weitere Diagnosen insbesondere im Zusammenhang mit dem Apple Support kann das Kommando:
brctl diagnose
genutzt werden. Dieses erzeugt eine umfangreiche Protokolldatei zur Fehleranalyse.
Fazit
iCloud kombiniert viele Dienste zu einer nahtlosen Cloud-Erfahrung für Apple-Nutzer. Dabei hat sich die Plattform von einem notorisch unzuverlässigen Dienst zu einer der technisch anspruchsvollsten Cloud-Plattformen entwickelt.
Mit iCloud+ hat Apple 2021 den Fokus auf Datenschutz im Internet verstärkt. Die Einführung von Advanced Data Protection markiert einen echten Paradigmenwechsel. Erstmals können Nutzer einen Großteil ihrer Cloud-Daten mit Ende-zu-Ende-Verschlüsselung schützen, bei der Apple vom Zugriff ausgeschlossen ist.
Die hybride Infrastruktur aus eigenen Rechenzentren und Drittanbietern ermöglicht Skalierung, während die konsequente Verschlüsselung vor dem Upload die Abhängigkeit von der Vertrauenswürdigkeit externer Anbieter minimiert.
Von den bescheidenen Anfängen als kostenloses iTools-Angebot im Jahr 2000 bis zur Datenschutz-Offensive mittels Advanced Data Protection hat Apple über zweieinhalb Jahrzehnte hinweg eine der komplexesten Cloud-Plattformen der Welt aufgebaut, die heute das Rückgrat des Apple-Ökosystems bildet.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.