Wenn man mal auf der Suche nach einem kleinen Zeitvertreib ist, kann man natürlich so einiges ausdenken, so z. B. eine eigene CPU-Architektur. Dabei muss man diese nicht in Hardware gießen, sondern es reicht wenn man diese emuliert. Und so entstand in einiger Zeit eine CPU, welche auf den Namen Structura hört. Ein Designziel war es dabei, die CPU nur mit den nötigsten Maschinenbefehlen auszustatten. Das führte bei der Structura zu folgenden Befehlen (hier als Assembler Mnemonics dargestellt):
- [0] – JUMP
- [1] – ADD
- [2] – COPY
Das bedeutet, dass es unter anderem keine Nichtoperation wie z.B. NOOP bzw. NOP im Befehlssatz der CPU gibt. Der Grund dafür ist ganz einfach. Eine Nichtoperation lässt sich durch einen JUMP um null Byte emulieren, was im Endeffekt nur eine Erhöhung des Instruction Counters kurz IC zur Folge hat. Da JUMP auf den Opcode 0 gelegt wurde führt, dies zu einer interessanten Reaktion der CPU, wenn sie das Ende des Programms erreicht und versucht den restlichen Speicher zu interpretieren. Die CPU interpretiert das als Sprung an die Adresse 0 und beginnt mit dem Programm von vorne.
Der Befehlsaufbau der Maschinenbefehle stellt sich dabei so da:
JUMP (Breite: 40 Byte)
[Int64|Befehlswort - 0]
[Int64|Adressinterpretation - 0/ANCTAAV 1/ACTAAV 2/RNCTAAV 3/RCTAAV]
ANCTAAV - Adress not contains target adress as value
ACTAAV - Adress contains target adress as value
RNCTAAV - Register not contains target adress as value
RCTAAV - Register contains target adress as value
[Int64|Sprungbedingung - 0/NONE 1/ZERO 2/POS 3/NEG 4/OVF]
[Int64|Sprungadressierung - 0/ABS 1/REL]
[Int64|Adresse oder Wert]
ADD (Breite: 32 Byte)
[Int64|Befehlswort - 1]
[Int64|Modus - 0/RAR 1/RANR 2/RAV]
RAR - Register and register
RANR - Register and negative register
RAV - Register and value
[Int64|Register]
[Int64|Register oder Wert]
COPY (Breite: 40 Byte)
[Int64|Befehlswort - 2]
[Int64|Modus - 0/NACTAAV 1/FACTAAV 2/SACTAAV 3/BACTAAV]
NACTAAV - No adress contains target adress as value
FACTAAV - First adress contains target adress as value
SACTAAV - Second adress contains target adress as value
BACTAAV - Both adress contains target adress as value
[Int64|Menge an kopierenden Daten in Byte]
[Int64|Register, Speicheradresse oder ZERO]
[Int64|Register oder Speicheradresse]
Jeder Opcode auf der CPU ist 8 Byte lang und wird als Int64 interpretiert. Die Structura ist mit den Registern A bis Z ausgestattet, was 26 Allzweckregister mit einer Breite von 8 Byte sind. Neben diesen Allzweckregistern besitzt es das Spezialregister IC bei welchem es sich um den Instruction Counter handelt und einige Flags mit den Namen Zero, Positive, Negative und Overflow. Beim Start beginnt die CPU mit der Ausführung des Programms ab der Adresse 0. Eine Besonderheit ist, das die CPU keinen Stack und keine Interrupts unterstützt.
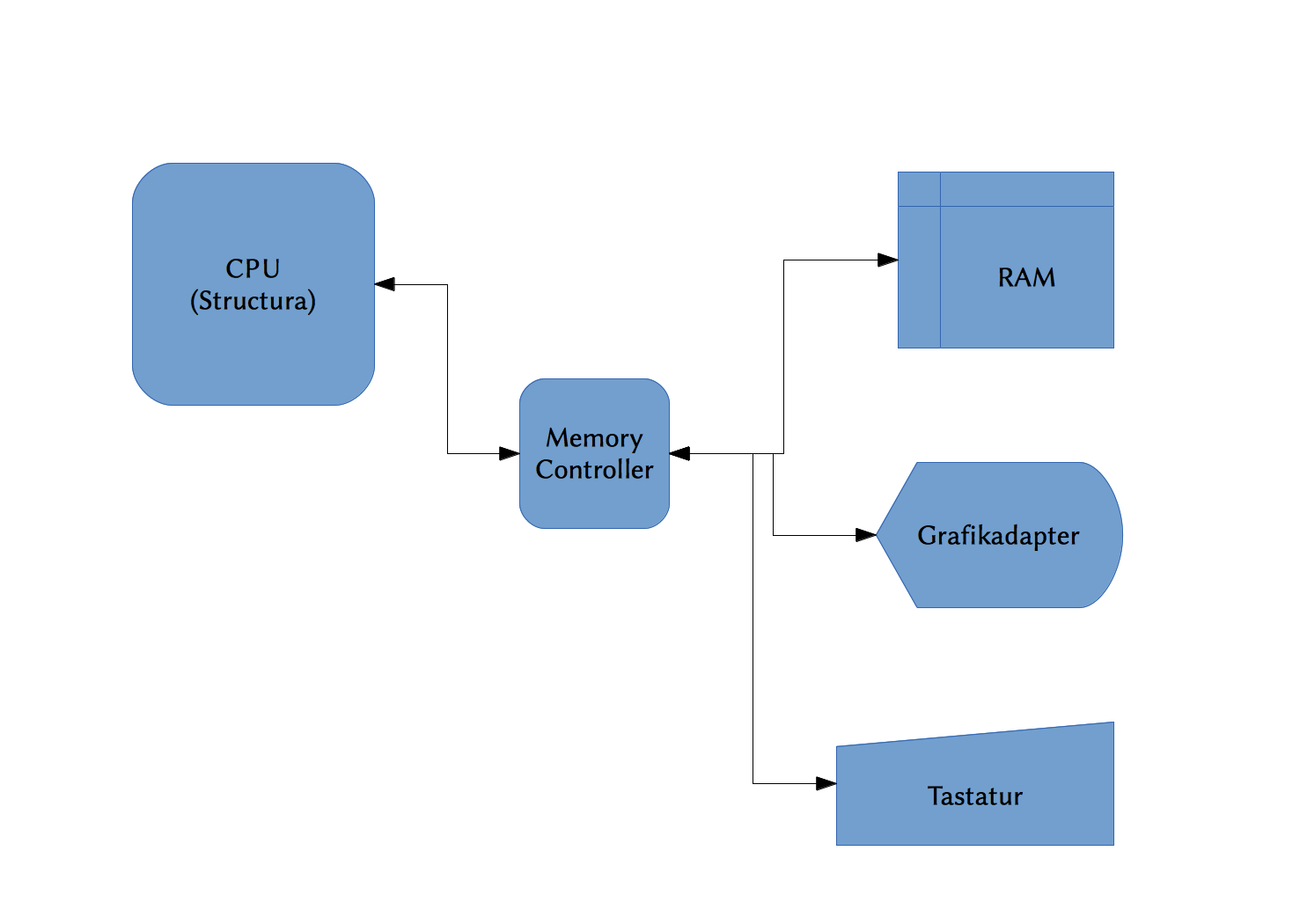
Damit Peripherie angesprochen werden kann, gibt es bestimmte Bereiche im Speicher, in welche sich diese Geräte einblenden. Der Bereich für Einblendungen ist dabei ab der Adresse 9.000.000.000.000.000.000 (7CE66C50E2840000) bis 9.223.372.036.854.775.807 (7FFFFFFFFFFFFFFF) zu finden.
Die Grafikkarte wird dabei ab der Adresse 9.000.000.000.000.000.000 bis einschließlich 9.099.999.999.999.999.999 eingeblendet. In den ersten 4096 Byte befindet sich dabei der Konfigurationsblock der Grafikkarte, welcher Informationen über die Auflösung und andere Einstellungen enthält.
Ab der Adresse 9.100.000.000.000.000.000 bis einschließlich 9100000000000008191 wird die Tastatur bzw. deren Eingabepuffer eingeblendet. Die ersten zwei Byte im Speicher der CPU sind dabei ein UInt16 welcher den aktuellen Zeichenindex der Tastatur in ihrem Tastaturpuffer angibt. Jede Eingabe auf der wird dabei vom Tastaturgerät in Form eines Bytearrays mit der Größe von fünf Byte übertragen. Das erste Byte gibt dabei den Modifier an, die restlichen 4 Bytes enthalten das erzeugte Zeichen in Form eines UTF-32 Zeichens.
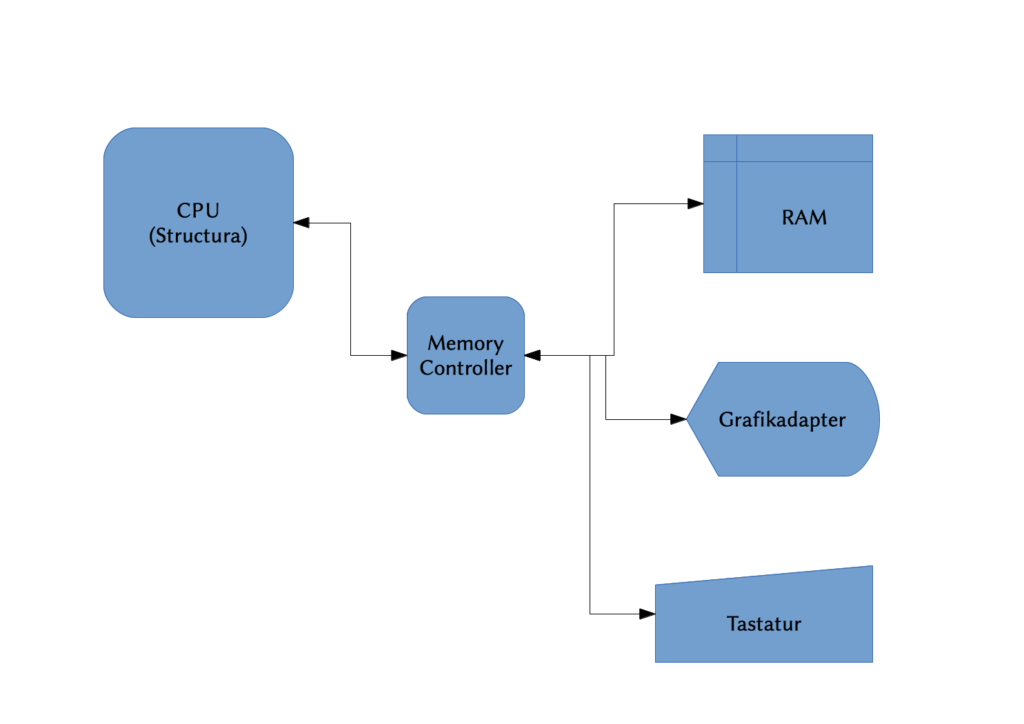
Der schematische Aufbau der CPU und deren Peripherie
Der Assembler für die CPU unterstützt eine Reihe von Mnemonics, welche anschließend in die Maschinensprache übersetzt werden. Diese sind:
ABS [Register]
ADD [Register] [Register oder Wert]
CLR [Register oder ALL]
COPY [Int64|Menge an kopierenden Daten in Byte] [Register oder Speicheradresse] [Register oder Speicheradresse]
DIV [Register] [Register oder Wert]
LOAD [Speicheradresse] [Register]
DEC [Register]
INC [Register]
JUMP [Sprungbedingung|NONE|ZERO|POS|NEG|OVL] [Sprungadressierung|ABS|REL] [Adresse oder Wert]
MOD [Register] [Register oder Wert]
MUL [Register] [Register oder Wert]
NEG [Register]
NOOP
SHIFTL [Register] [Register oder Wert]
SHIFTR [Register] [Register oder Wert]
WRITE [Register] [Speicheradresse]
Beim Assembler handelt es sich genaugenommen nicht um einen Assembler der reinen Lehre, sondern um eine Kreuzung aus Assembler, Makroassembler und Hochsprache. Für die komplexeren Kommandos wie MUL oder SHIFTL werden bestimmte Register während der Berechnung belegt (im Fall von MUL z. B. das W, X, Y und Z Register). Die vom Kommando belegten Register sind dabei in der Dokumentation aufgeführt. Das führt natürlich dazu das eine solche Multiplikation nach der Auflösung aus sehr vielen Befehlen besteht:
COPY 8 Y A;
COPY 8 Z ZERO;
ADD Z 3;
COPY 8 X ZERO;
ADD Y 0;
JUMP POS REL 72;
JUMP ZERO REL 32;
ADD X 1;
ADD Z 0;
JUMP POS REL 72;
JUMP ZERO REL 32;
ADD X 1;
COPY 8 A ZERO;
ADD Y 0;
JUMP POS REL 184;
JUMP ZERO REL 144;
COPY 8 W Y;
ADD Y -W;
ADD Y -W;
COPY 8 W ZERO;
ADD Z 0;
JUMP POS REL 184;
JUMP ZERO REL 144;
COPY 8 W Z;
ADD Z -W;
ADD Z -W;
COPY 8 W ZERO;
ADD A Y;
ADD Z -1;
JUMP POS REL -104;
COPY 8 W X;
ADD W -2;
JUMP ZERO REL 368;
COPY 8 W X;
ADD W -1;
JUMP ZERO REL 112;
COPY 8 W X;
ADD W 0;
JUMP ZERO REL 144;
COPY 8 W A;
ADD A -W;
ADD A -W;
COPY 8 W ZERO;
COPY 8 X ZERO;
COPY 8 Y ZERO;
COPY 8 Z ZERO;
Während der Entwicklung gab es dabei einige interessante Ideen wie man bestimmte Sachen im Assembler lösen könnte. So zum Beispiel folgendes Problem:
ADD A 555; // Fülle das Register A mit dem Wert 555
COPY 8 B A; // Kopiere Register A zu B
DEC B; // Reduziere B um 1
COPY 8 *A B; // Kopiere der Wert von B an die Adresse welche im A Register A definiert ist (555)
COPY 8 D *A; // Kopiere das was ab 555 steht in den Register D
Im D Register sollte nun der Wert 554 stehen. Möglich wird dies dadurch, das die CPU weiß, dass sie nicht den Wert nach A kopieren soll, sondern den Wert welcher in A enthalten ist, als Zieladresse benutzt. Theoretisch wäre dies auch anders lösbar gewesen. So hätte der Assembler das * in selbst modifizierenden Quellcode auflösen können. Aus einem COPY 8 *A D wäre dann in etwa folgender Quelltext erzeugt worden:
COPY 8 (IC+32) A;
COPY B [IC+32];
Das Problem an dieser Geschichte ist, das der Assembler bei dieser Variante sehr viel über die Innereien der CPU wissen muss. So muss z. B. genau definiert sein, wann der IC erhöht wird, da dieser für den selbst modifizierenden Code benötigt wird. Zur Erklärung: Die erste Zeile kopiert die Adresse welche in A liegt in die nächste Zeile und modifiziert somit den COPY Befehl während der Laufzeit. Dadurch wird die Adressierung über den Registerwert möglich.
Interessant ist auch die Berechnung eines Sprungzieles. Möchte man z. B. folgendes Programm ausführen:
ADD A 7;
JUMP NONE REL -104
stellt sich die Frage wie man die relative Sprungweite ausrechnet. Hierbei kommt es auf die Breite der Befehle an. Bei den Grundbefehlen (ADD, COPY und JUMP) entspricht diese den in der Maschinencodebeschreibung angegebenen Breite. Andere Befehle wie MUL oder SHIFTL zählen zu den komplexen Befehlen, da diese im Maschinencode aus mehreren Anweisungen bestehen.
Hier besteht die einfachste Möglichkeit darin, den JUMP-Befehl im ersten Moment mit Fantasiewerten zu füllen. Anschließend wird der Emulator mittels:
Structura.exe program.asm -disassemble -withIC
aufgerufen. Bei der Darstellung mittels withIC wird der Wert des ICs am Anfang des Befehls und am Ende des Befehls angezeigt.
(256/296) JUMP ZERO REL 32;
(296/328) ADD X 1;
(328/360) ADD Z 0;
Möchte man nun also zum Befehl ADD Z 0; springen so rechnet man 328-296 und hat so das richtige Sprungziel errechnet.
Und natürlich fehlt auch noch eine Umsetzung in Hardware, aber bis das so weit ist, kann es naturgemäß dauern. Bei der Structura handelt es sich natürlich nicht um eine effiziente CPU, sondern um eine bei welcher versucht wurde, die CPU internen Befehle auf ein Minimum zu begrenzen und das Design als solches einfach zu halten. Dies schlägt sich unter anderem darin nieder, das jedes Befehlswort 8 Byte lang ist, und somit für 3 Befehle überdimensioniert, aber dafür die Einfachheit der Maschine intern gegeben ist.
Und natürlich erkauft man sich dies mit einigen Nachteilen, so sind die Bitverschiebungsoperation eigentlich eine der schnellsten in einer CPU. Durch die Emulation über zusätzlichen Assemblercode wird es eine der langsamsten Operation. Aber eine CPU mit einem großen Befehlssatz zu emulieren, ist schließlich einfach und das war nicht der Sinn der Übung.
Anschauen kann man sich das unter der GPLv3 stehende Projekt unter https://github.com/seeseekey/Structura/. Eine vorkompilierte Version zum Testen gibt es hier zum Download. In der Implementation befinden sich sicherlich noch einige Fehler, auf welche mich gerne hingewiesen werden darf. Jetzt müsste nur noch jemand Linux auf das System portieren, wobei dies ohne weiteres nicht funktionieren sollte, das die CPU Dinge wie Interrupts nicht unterstützt. Allerdings wäre es natürlich durchaus möglich ein eigenes minimales Betriebssystem für das emulierte System zu schreiben.