Paketmanager haben den Prozess der Software-Installation und Aktualisierung vereinfacht und viele Probleme der Vergangenheit gelöst. Heute sind sie ein integraler Bestandteil vieler Systeme. Während der durchschnittliche Windows-Nutzer wahrscheinlich weniger mit der Begrifflichkeit eines Paketmanagers anfangen kann, sieht es bei Nutzern unixoider Systeme meist anders aus.
Vor allem bei Linux-Systemen sind sie ein essenzieller Bestandteil der allermeisten Distributionen und kommen hier in den unterschiedlichsten Formen vor. Mittlerweile haben sie sich allerdings darüber hinaus ausgebreitet und sind heute auch unter macOS und Windows zu finden.
Über diese Grenzen hinaus haben sich Paketmanager auch in anderen Bereichen etabliert hat, beispielsweise im Paket- und Abhängigkeitsmanagement innerhalb der Softwareentwicklung.
Unabhängig vom spezifischen Paketmanager folgen diese in der Regel einem ähnlichen Ablauf: Ein Nutzer beabsichtigt, eine Anwendung bzw. ein Paket zu installieren. Der Paketmanager identifiziert die erforderlichen Abhängigkeiten und installiert diese zusammen mit der gewünschten Software.
Definition
Doch was zeichnet einen Paketmanager aus? Grundsätzlich handelt es sich bei einem solchen um ein Werkzeug oder eine Sammlung an Werkzeugen, die dazu dient Software zu installieren, sie zu aktualisieren und wieder zu entfernen. Im Idealfall ist diese Entfernung rückstandslos. Auch die Konfiguration der Software ist eine Fähigkeit, welche von vielen Paketmanagementsystemen beherrscht wird.
Ziel ist es meist, die manuelle Installation und Verwaltung von Software unnötig zu machen, sodass diese im Idealfall immer über den Paketmanager bezogen werden kann.
Neben der eigentlichen Bereitstellung der gewünschten Software, ist ein wichtiger Teil des Paketmanagements die Installation und Verwaltung der Abhängigkeiten, welche von der Software benötigt werden. Dies umfasst beispielsweise die Handhabung verschiedener Versionen von Bibliotheken, die erforderlich sind, wenn mehrere installierte Anwendungen unterschiedliche Versionen einer Bibliothek benötigen.
Ein Paket umfasst in solchen Systemen, neben der eigentlichen Anwendung, eine Reihe von zusätzlichen Metadaten, welche als Informationen über das Paket und der Verwaltung dienen.
Daneben führen die Systeme Buch über installierte Software, was z. B. bei der Aktualisierung installierter Anwendungen von Belang ist.
Typen von Paketmanagern
Paketmanager lassen sich in verschiedene Typen einteilen. Einerseits existieren systemgebundene Paketmanager wie das Advanced Packaging Tool (APT), die integraler Bestandteil des jeweiligen Betriebssystems sind und eine konfliktfreie Installation von Anwendungen gewährleisten.
Ziel dieser Paketmanager ist die Softwareverwaltung für den Nutzer des Systems. Auch ist es bei diesen systemspezifischen Paketmanagern in den meisten Fällen so, dass Abhängigkeiten wie Bibliotheken im Idealfall nur einmal installiert werden.
Eine weitere Art von Paketmanagementsystemen sind App Stores. Hier steht jede Applikation für sich und wird mitsamt ihrer Abhängigkeiten installiert. Das bedeutet, dass z. B. Bibliotheken immer wieder mitgeliefert werden. Hier wird in der Theorie Speicherplatz verschenkt, da häufig verwendete Bibliotheken mehrfach vorhanden sein können.
Eine letzte und trotzdem in ihrer Wichtigkeit nicht zu unterschätzende Kategorie von Paketmanagern sind sprachspezifische Paketmanager. Bei diesen geht es um das Paket- und Abhängigkeitsmanagement von Bibliotheken im Rahmen der Softwareentwicklung. Beispiele für diese Manager sind Maven, Cargo und NPM. Sie werden vor allem in den vergangenen Jahren verstärkt eingesetzt. Einen Überblick über diese sprachspezifischen Paketmanager bietet die Webseite libraries.io.
Am Anfang war der Code
In frühen Systemen existierten keine Paketmanager im heutigen Sinne. Entweder wurden die mitgelieferten Systemwerkzeuge genutzt, oder die benötigte Software lag im Quelltext vor und wurde anschließend kompiliert und installiert.
Eine Applikation wird kompiliert
Im Laufe der Zeit wurden nicht nur die Systeme komplexer, sondern auch die auf ihr genutzten Anwendungen. Mithilfe von Build Automation Tools wie Make, wurde es möglich Software anhand des sogenannten Makefiles zu bauen. Allerdings wurde auch hier vorausgesetzt, dass die benötigten Abhängigkeiten auf dem System vorhanden waren.
Über den Befehl make kann der entsprechende Vorgang angestoßen werden. Damit vereinfachten Makefiles die Erzeugung der Software. Statt den Compiler, dazugehörige Linker und weitere Werkzeuge selbst aufrufen zu müssen, fungiert das Makefile als Mittler.
Abhängigkeiten
Im ersten Moment scheint es, als ob die Installation der Software aus dem Quelltext leicht von der Hand geht. Der Quelltext muss bezogen werden und anschließend kann die Applikation kompiliert und installiert werden.
Allerdings steht ein Programm meist nicht für sich, sondern ist auf gewisse Abhängigkeiten, wie verwendete Bibliotheken angewiesen. Sind diese Abhängigkeiten in einer falschen Version installiert, oder nicht vorhanden, schlägt die Erstellung der Applikation fehl.
Ein weiteres Problem ist, dass unixoide Systeme nicht unbedingt identisch sind und sich in kleineren und größeren Feinheiten unterschieden. Eine Lösung für diese Probleme bieten Werkzeuge wie autoconf vom GNU-Projekt und später CMake.
Über diese Build-Automatisierungstools wird das benötigte Makefile generiert, welches dann auf die Eigenheiten des eigentlichen Systems angepasst ist. So wird unter anderem überprüft, ob die benötigten Abhängigkeiten vorhanden sind und unter Umständen abgebrochen, wenn dies nicht der Fall ist.
Bislang nicht betrachtet wurde die Deinstallation einer Anwendung. Neben den eigentlichen Anwendungsdateien, eventuellen Bibliotheken und Konfigurationsdateien können hierzu auch Dateien zählen, welche während der Laufzeit der Anwendung erzeugt wurden.
Diese von Hand zu entfernen, ist im besten Fall ein zeitaufwendiger Prozess. Spätestens an dieser Stelle erweist sich ein funktionierendes Paketmanagementsystem als Segen.
Quell- vs. Binärpakete
Bei dem oben beschriebenen Verfahren wurde die Software direkt auf dem System kompiliert. Dies hat einige Vorteile. So kann die jeweilige Software mit entsprechender CPU-Optimierung kompiliert werden und somit optimal auf das System abgestimmt werden. Allerdings nimmt ein solcher Vorgang Zeit in Anspruch, vorwiegend bei der Kompilierung größerer Softwarepakete wie einem Browser.
Bei Paketmanagern wird hier die Unterscheidung zwischen Quell- und Binärpaketen getroffen. Quellpakete enthalten den Quellcode der Anwendung und werden direkt auf dem Rechner des Nutzers kompiliert.
Binärpakete hingegen enthalten eine vorkompilierte Anwendung, welche auf eine bestimmte Architektur optimiert ist. Damit muss das Paket nur noch vom Paketmanager heruntergeladen, entpackt und installiert werden. Neben der fehlenden Optimierung auf den konkreten CPU-Typ haben Binärpakete weitere Nachteile. Viele Anwendungen verfügen über bestimmte Schalter zu Compile-Zeit, um bestimmte Module und Funktionalitäten in die Anwendung zu integrieren. Ist dies während der Erstellung des Binärpaketes nicht geschehen, so kann das Modul bzw. die gewünschte Funktionalität nicht ohne Weiteres genutzt werden.
Anfänge der Paketmanager
Mit der Idee der Paketierung war der Gedanke zu einem Paketmanager nicht mehr weit. Auch wenn solche Manager unter Linux gängig wurden, gab es sie in Ansätzen bereits davor.
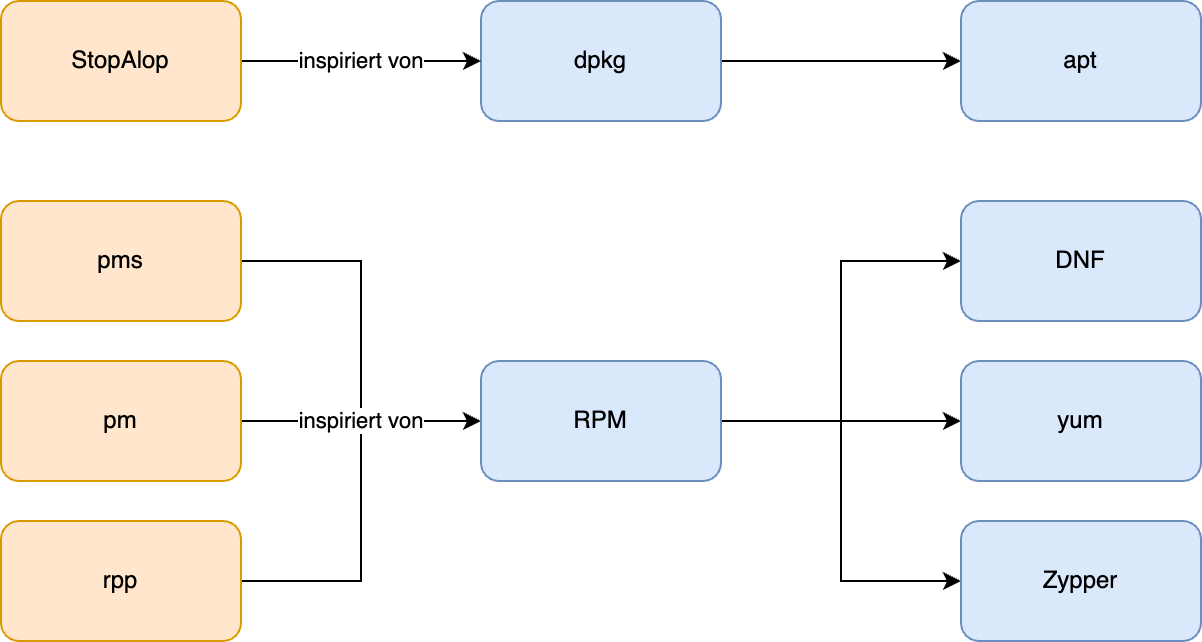
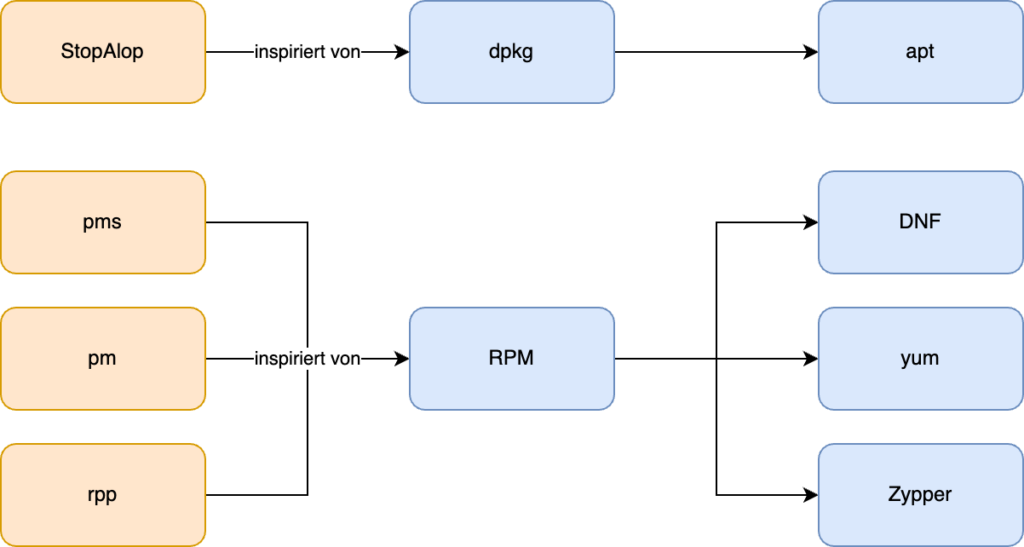
Einer der ersten Paketmanager war das System Management Interface Tool (SMIT) für AIX, welches mit der Version 3.0 von AIX im Jahr 1989 Einzug hielt. Unter der Oberfläche wurde für diese Aufgabe installp als Backend genutzt.
Im Linux-Bereich zählte das package management system (pms) zu den ersten Paketmanagern. Dieses erschien in Version 1.0 Mitte des Jahres 1994. Genutzt wurde dieses in der Distribution Bogus Linux. Dies führte historisch betrachtet unter anderem zum RPM-Paketmanager, welcher ursprünglich von Red Hat stammt und 1995 mit Red Hat Linux 2.0 ausgeliefert wurde.
In einen ähnlichen Zeitrahmen fallen die Entwicklung des Debian Package Managers, der vom StopAlop, einem weiteren Paketmanager aus der Frühzeit der Paketmanager, inspiriert wurde.
Die erste Version des Debian Package Managers wurde 1994 von Ian Murdock entwickelt, damals noch in Form eines Shellskriptes. Aus diesem entstand im Laufe der Jahre das dpkg der Neuzeit.
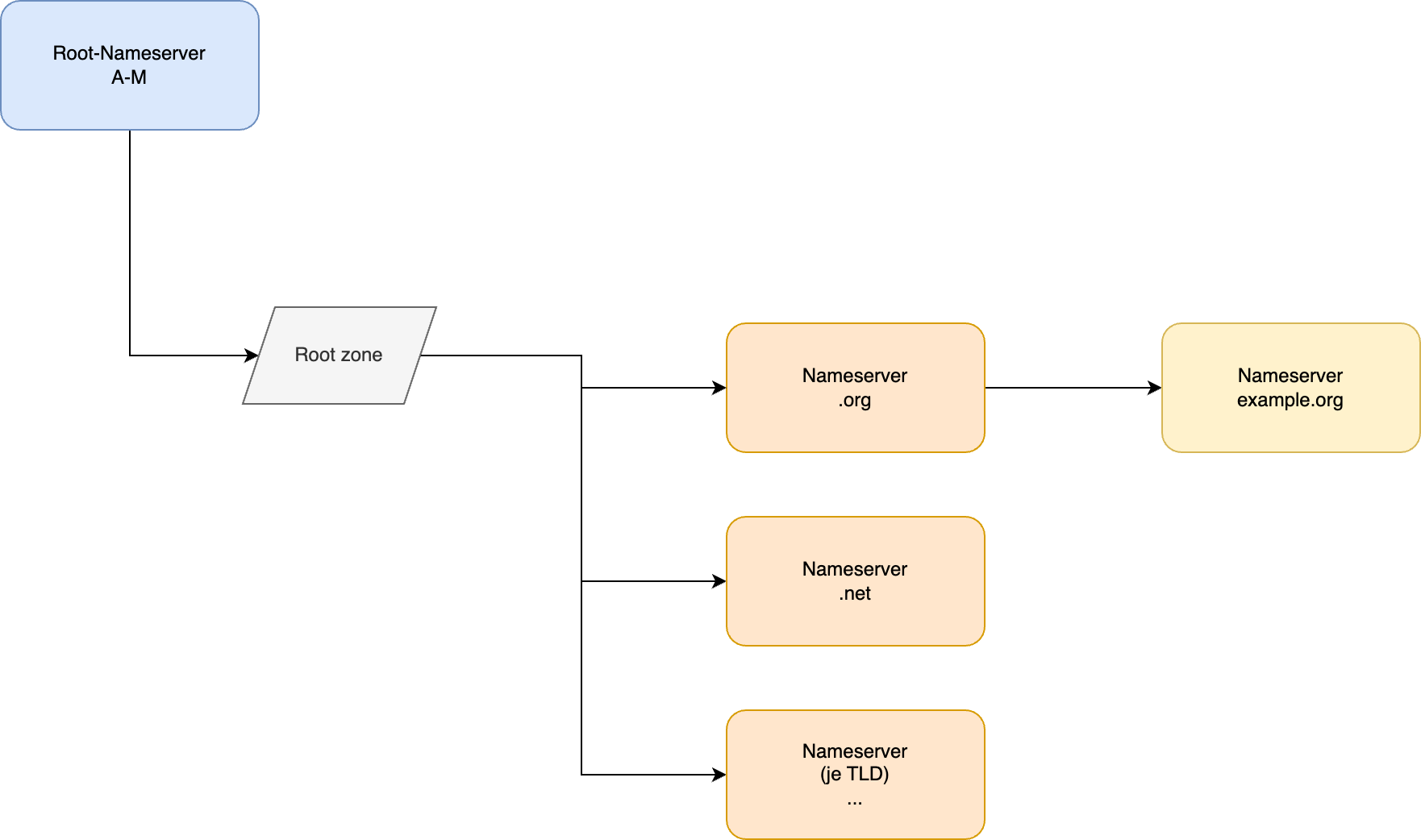
Aus diesen Low-Level-Paketmanagern entwickelten sich schließlich Systeme, welche Repositorys der verfügbaren Software bereithielten und diese zur Installation derselben nutzten, sodass auch das Problem der Paketbeschaffung bzw. der eigenen Paketierung in den meisten Fällen gelöst war.
Im Jahr 1995 begannen viele Paketmanager mit der Implementierung eines Workflows, der mit dem Herunterladen des Pakets beginnt und die automatische Auflösung sowie Installation von Abhängigkeiten beinhaltet.
Neben eigentlichen Applikationen wurden Systempaketmanager auch genutzt, um Bibliotheken und andere Funktionalität bestimmter Programmiersprachen wie Python über diese zu installieren. Heutzutage wird dies mehrheitlich über sprachspezifische Paketmanager gelöst.
Low-Level- und High-Level-Paketmanager
Werkzeuge wie dpkg, zählen wie oben bereits erwähnt zu den Low-Level-Paketmanagern. Zwar vereinfachen sie die Installation von Paketen, aber aus Sicht des Nutzers, sind immer noch viele manuelle Schritte notwendig, um das System auf einem aktuellen Stand zu halten.
Low-Level-Paketmanager samt Herkunft und High-Level-Paketmanager
Hier kommen High-Level-Paketmanager ins Spiel. Diese vereinfachen die Bedienung und dienen sozusagen als Frontend für den eigentlichen Nutzer. Daneben gruppieren sie Operationen der zugrundeliegenden Low-Level-Paketmanager.
Neben dem traditionellen Weg, Software als Archiv auszuliefern, wurde mit den Paketmanagern für die jeweiligen Distributionen ein zentrales Repository mit Software geschaffen, welches von der jeweiligen Distribution gepflegt wurde.
Interessant an diesem zentralen Repositorys ist, dass die Software, welche in diesen vorliegt, technisch betrachtet ein Fork der Originale ist. Der Vorteil dieser Vorgehensweise ist die Entkopplung, sodass eine Distribution eigene Aktualisierungen für eine Anwendung bereitstellen kann. Dies gilt auch für den Fall, dass die Software nicht mehr aktiv unterstützt wird.
Auch wenn von einem zentralen Repository die Rede ist, sieht es in den eigentlichen Distributionen meist etwas differenzierter aus. Unter Ubuntu z. B. existieren die Repositories Main, Universe, Restricted und Multiverse.
Das Main-Repository umfasst von Canonical unterstützte freie Software, die als grundlegend und essenziell für das System angesehen wird. Das Universe-Repository wird von der Community gepflegt und enthält ebenfalls freie Software, die von Nutzern beigetragen und verwaltet wird.
Im Restricted-Repository finden sich proprietäre Treiber für Geräte, die aus lizenzrechtlichen Gründen nicht im Main-Repository enthalten sind. Schließlich existiert noch das Multiverse-Repository, das Software beinhaltet, die durch Urheberrecht oder andere rechtliche Fragen eingeschränkt ist und deshalb spezielle Vereinbarungen für die Nutzung oder Verbreitung erfordert.
Daneben liegen für die unterschiedlichen Repositorys verschiedene Spiegelserver vor, welche die Pakete redundant und geografisch verteilt vorhalten.
Auch Abhängigkeiten werden von High-Level-Paketmanagern wesentlich sinnvoller behandelt. Während eine Paketinstallation per dpkg verlangt, dass alle Abhängigkeiten installiert sind, übernimmt apt diese Aufgabe automatisch. Hierbei werden die Abhängigkeiten in die korrekte Reihenfolge gebracht, bezogen und anschließend installiert.
Durch die zentralen Repositorys ist es über wenige Befehle möglich, den kompletten Softwarebestand zu aktualisieren. Auch der Wegfall von Abhängigkeiten wird bemerkt und so werden nicht mehr benötigte Pakete auf Wunsch automatisch deinstalliert.
Anatomie eines Paketmanagmentsystems
Einige Eigenschaften, welche ein Paket ausmachen, wurden bereits beschrieben. Trotzdem soll an dieser Stelle genauer auf die Anatomie eines Pakets und des Managementsystems dahinter eingegangen werden. Hierbei wird dpkg als Beispiel herangezogen.
Der Debian Package Manager ist dafür verantwortlich, ein Paket zu installieren und wieder zu deinstallieren. Hierzu wird die DEB-Datei, welche das Paket darstellt, im ersten Schritt entpackt und anschließend ein Pre-Install-Skript ausgeführt.
Nach dessen Ausführung werden die Komponenten des Paketes an die korrekten Stellen im Dateisystem kopiert und anschließend das Post-Install-Skript ausgeführt. Bei der Deinstallation läuft dieser Vorgang ähnlich ab. Auch hier werden wieder Pre– und Post-Remove-Skripte durchgeführt. Daneben verwaltet dpkg eine Datenbank der installierten Pakete.
Im Einzelnen besteht ein DEB-Paket aus dem sogenannten Debian-Binary. In dieser Datei ist die Version des Dateiformates hinterlegt. Dies sollte bei aktuellen Distributionen immer 2.0 sein. Trotz ihres Namens handelt es sich um eine gewöhnliche Textdatei.
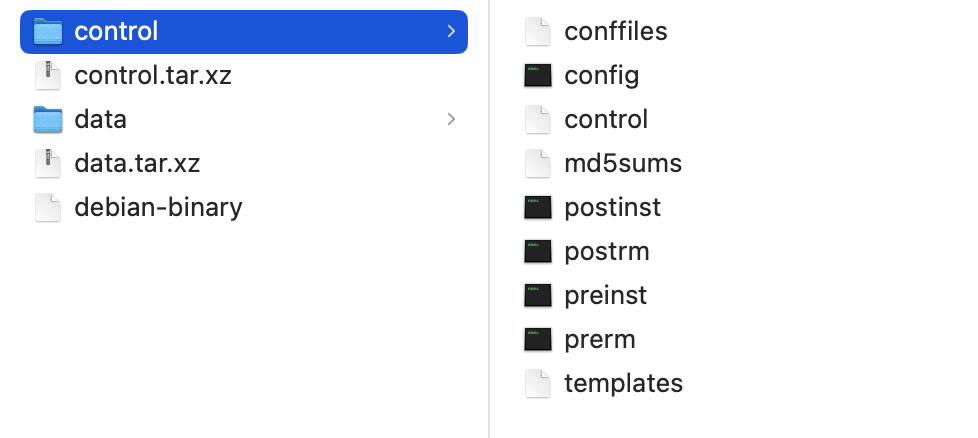
Ein entpacktes DEB-Archiv mit dem control-Ordner
Anschließend folgen zwei Archive, eines für die Meta-Informationen und eines für die eigentlichen Daten. Bei den Archiven werden zwei unterschiedliche Archivierungsverfahren unterstützt. So kann im Falle des control-Archivs das Archiv als control.tar.gz oder control.tar.xz vorliegen.
Das control-Archiv enthält mehrere wichtige Dateien. Die erste Datei ist die Datei control. Diese enthält Informationen über das Paket wie Paketname, Version, Abhängigkeiten, Konflikte, Beschreibung und mehr.
Für das Paket nginx-common sieht diese Datei beispielhaft wie folgt aus:
Package: nginx-common
Source: nginx
Version: 1.24.0-2
Architecture: all
Maintainer: Debian Nginx Maintainers
Installed-Size: 306
Depends: debconf (>= 0.5) | debconf-2.0, nginx (>= 1.24.0-2), nginx (<< 1.24.0-2.1~)
Suggests: fcgiwrap, nginx-doc, ssl-cert
Breaks: nginx (<< 1.22.1-8)
Replaces: nginx (<< 1.22.1-8)
Section: httpd
Priority: optional
Multi-Arch: foreign
Homepage: https://nginx.org
Description: small, powerful, scalable web/proxy server - common files
Nginx ("engine X") is a high-performance web and reverse proxy server
created by Igor Sysoev. It can be used both as a standalone web server
and as a proxy to reduce the load on back-end HTTP or mail servers.
.
This package contains base configuration files used by all versions of
nginx.
Daneben sind die entsprechenden Pre- und Postskripte enthalten (preinst, postinst, prerm, postrm). Diese Skripte werden verwendet, um spezielle Aufgaben auszuführen, die für das Paket notwendig sind, wie das Konfigurieren von Systemdiensten oder das Aktualisieren von Konfigurationsdateien.
Die Datei conffiles enthält eine Liste von Konfigurationsdateien, die vom Paketmanagementsystem während einer Aktualisierung behandelt werden, um benutzerdefinierte Änderungen zu erhalten.
Über die Datei md5sums, eine Liste von MD5-Prüfsummen für die Dateien, die im Paket enthalten sind, kann die Integrität dieser überprüft werden.
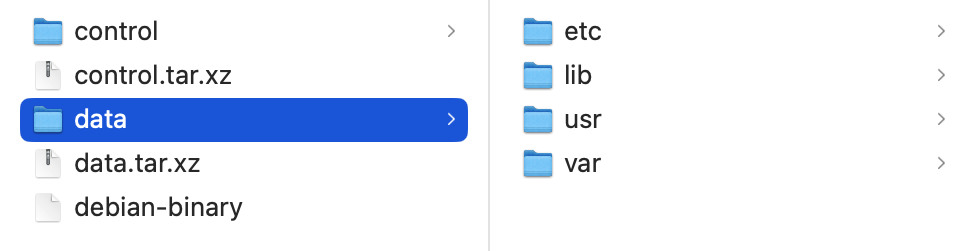
Der entpackte data-Ordner in einem DEB-Archiv
Die eigentlichen Daten des DEB-Archives finden sich im data-Archiv (data.tar.gz oder data.tar.xz). Dieses Archiv enthält die Dateien, die zum System hinzugefügt werden, wenn das Paket installiert wird. Die Dateien in diesem Archiv werden relativ zum Wurzelverzeichnis des Ziel-Dateisystems extrahiert.
Paketdatenbank
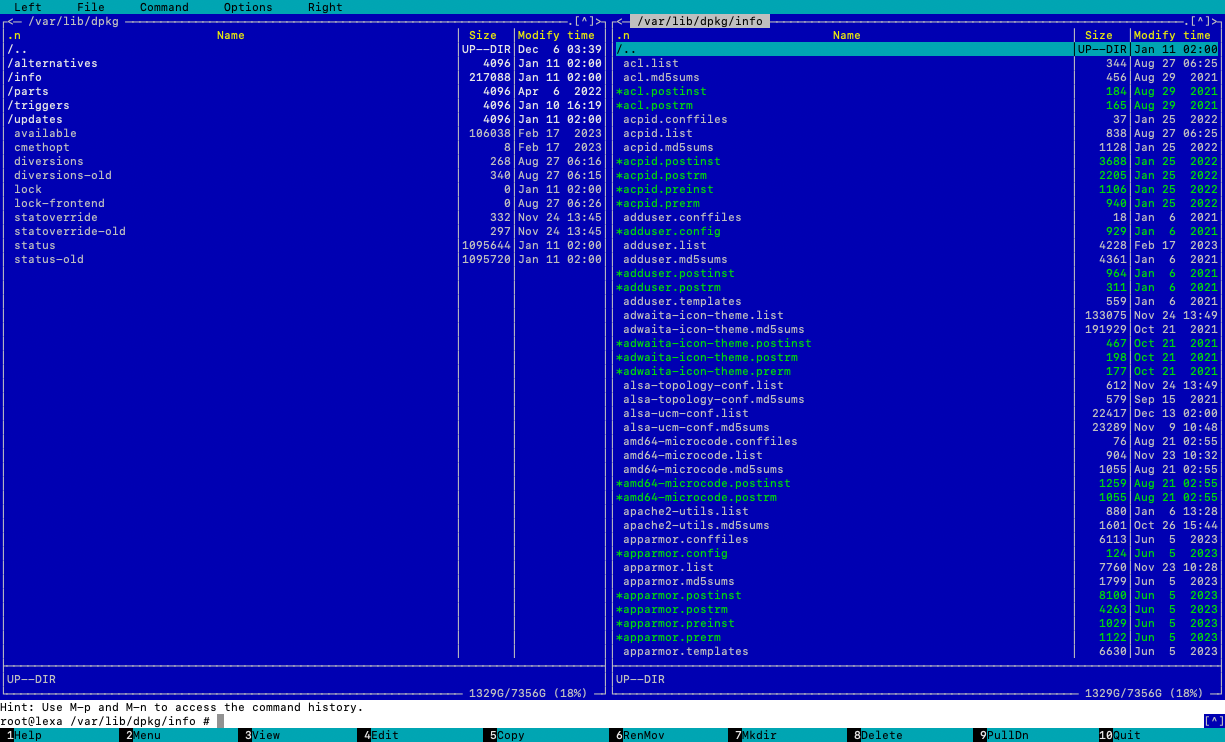
Neben den eigentlichen Paketen nimmt die Paketdatenbank einen großen Stellenwert ein. Die Paketdatenbank von Debian und darauf basierenden Distributionen wird von dpkg verwaltet und speichert Informationen über alle installierten, gelöschten oder sonst wie bekannten Pakete auf dem System. Die Datenbank befindet sich im Verzeichnis /var/lib/dpkg/ und besteht aus mehreren Dateien und Verzeichnissen, die verschiedene Aspekte der Paketverwaltung abdecken.
Die Datei /var/lib/dpkg/status enthält den aktuellen Status aller Pakete. Sie listet Pakete auf, die installiert sind, deren Installation erwartet wird, die zur Deinstallation oder vollständigen Entfernung markiert sind, und so weiter. Für jedes Paket enthält diese Datei Metadaten wie Version, Architektur, Abhängigkeiten, Beschreibung und vieles mehr.
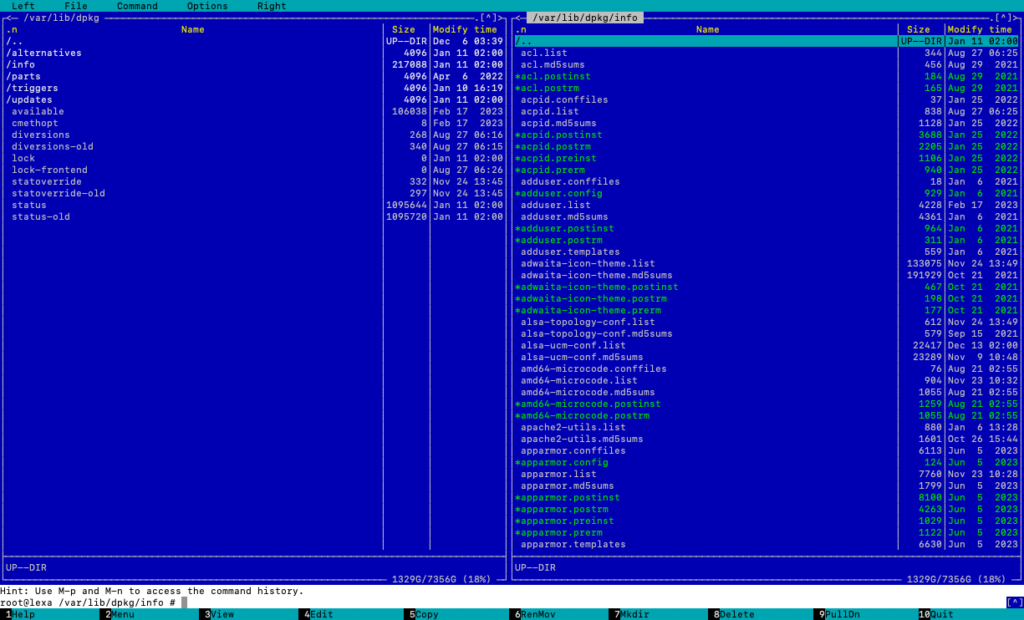
Die Paketdatenbank des Debian Package Managers
Die Datei /var/lib/dpkg/available enthält Informationen über verfügbare Pakete, aus den Repositorys. Diese Datei wird z. B. durch den Befehl apt update aktualisiert.
Das Verzeichnis /var/lib/dpkg/info/ enthält spezifische Dateien für jedes Paket, wie Konfigurationsskripte. Diese Dateien werden von dpkg während der Installation und Deinstallation verwendet, um sicherzustellen, dass diese Prozesse korrekt durchgeführt werden.
Die Paketdatenbank wird von dpkg und anderen Frontends wie APT, Aptitude oder Synaptic verwendet, um Paketoperationen durchzuführen. Es ist wichtig, dass diese Datenbank konsistent und unbeschädigt bleibt, da Inkonsistenzen zu Problemen bei der Paketverwaltung führen können.
Die Konsistenz der Paketdatenbank in Debian-basierten Systemen wird durch eine Kombination aus Designentscheidungen, Dateisystemtransaktionen und Sperrmechanismen sichergestellt.
Welche Version darf es sein?
Eine Paketverwaltung im Distributionsumfeld, kann trotz ihrer Vorteile, einige Herausforderungen mit sich bringen. Je nach der Politik der gewählten Distribution kann es sein, dass nur bestimmte und unter Umständen veraltete Versionen gepflegt werden. Dies ist z. B. bei Debian Stable der Fall, während bei anderen Distributionen wie bei Arch Linux immer die neusten Anwendungen, dank des Rolling Releases-Prozesses, mitgeliefert werden.
Die Nutzung eines Paketmanagers kann dazu führen, dass Nutzer weniger Kontrolle über spezifische Konfigurationen der installierten Software haben, da viele Einstellungen bereits festgelegt wurden.
Die Sicherheit hängt zudem von der Vertrauenswürdigkeit der Softwarequellen, den sogenannten Repositorys, ab. Eine Kompromittierung eines Repositorys kann die Verbreitung schädlicher Software begünstigen. Trotz verschiedener Sicherheitsmaßnahmen kann ein solches Risiko nicht gänzlich ausgeschlossen werden.
Paketmanager je Betriebssystem
Neben der grauen Theorie werden Paketmanager natürlich auch genutzt. Hierfür stehen je nach Betriebssystem unterschiedlichste Paketmanager zur Verfügung, von deinen einige nachfolgend vorgestellt werden sollen.
Linux
Unter Linux existieren eine Vielzahl an Paketmanagern. Zu den häufigeren verwendeten gehört sicherlich dpkg mitsamt seiner Frontends, wie APT. Auf Debian basierende Distributionen wie Ubuntu nutzten dieses System ebenfalls.
Ein weiterer bekannter Paketmanager ist RPM, welcher unter anderem bei Red Hat Linux zum Tragen kommt. RPM steht hierbei für RPM Package Manager, welcher ursprünglich als Red Hat Package Manager bezeichnet wurde.
Im Laufe der Zeit wurde der RPM Package Manager weiterentwickelt und verbessert. Das RPM-Format selbst wurde standardisiert, und es wurden Werkzeuge wie YUM (Yellowdog Updater, Modified) und später DNF (Dandified Yum) entwickelt, die als Frontends für RPM dienen und zusätzliche Funktionen wie einfachere Abhängigkeitsauflösung und automatische Updates bieten.
Daneben existieren weitere Paketmanagementsysteme wie Pacman unter Arch Linux. Üblicherweise ist das Paketverwaltungssystem eines der Systeme, die näher betrachtet werden, wenn sich intensiver mit einer Distribution auseinandersetzt wird.
Neben diesen gewöhnlichen Paketmanagern gibt es auch neue Konzepte, wie Nix und NixOS, welche deklarative Ansätze für die Paketverwaltung nutzen.
Snap, Flatpak und Co.
In der Linux-Welt sind zusätzlich zu den Systempaketmanagern weitere Paketformate entstanden, die darauf abzielen, Softwarepakete unabhängiger von den einzelnen Distributionen zu gestalten.
Unter Ubuntu ist das Snap-Format stark vertreten, bei anderen Distributionen hingegen Flatpack. Snap und Flatpak sind moderne Paketmanagement- und Bereitstellungssysteme, die das Ziel haben, die Installation und Verwaltung von Software auf Linux-Systemen zu vereinfachen und zu vereinheitlichen. Sie ergänzen traditionelle Paketmanager wie APT und bieten einige Vorteile.
Snap ist ein Paketformat, das von Canonical entwickelt wurde. Snap-Pakete sind in sich geschlossene Softwarepakete, die alle notwendigen Abhängigkeiten enthalten, um auf einer Vielzahl von Linux-Distributionen zu laufen. Das Snap-System verwendet ein zentrales Repository namens Snap Store, in dem der Nutzer Software suchen und installieren kann.
Snaps sind in der Regel größer als traditionelle Pakete, da sie alle Abhängigkeiten enthalten, bieten dafür aber andere Vorteile. So laufen Snaps in einer Sandbox-Umgebung, die die Sicherheit erhöht, indem sie den Zugriff der Anwendung auf das System beschränkt.
Durch den Dienst snapd, werden Snaps automatisch aktualisiert, was die Wartung vereinfacht. Aus Entwicklersicht können Anwendungen leichter veröffentlicht und aktualisiert werden, da nicht diese nicht auf die Paketverwaltung der einzelnen Distributionen angewiesen sind.
Flatpak ist ein ähnliches System, entwickelt von der unabhängigen Community. Es zielt ebenfalls darauf ab, distributionsübergreifend Software bereitzustellen und verwendet für die Verteilung von Softwarepaketen sogenannte Remotes wie Flathub. Flatpaks können auf einer Vielzahl von Linux-Distributionen laufen. Ähnlich wie Snaps bieten Flatpaks eine Sandbox-Umgebung, die die Sicherheit verbessern soll.
Beide Systeme, Snap und Flatpak, tragen in der Theorie dazu bei, die Fragmentierung im Linux-Ökosystem zu verringern und die Softwareverteilung zu vereinfachen. Sie bieten eine Plattform für Entwickler, um ihre Anwendungen einem breiteren Publikum zur Verfügung zu stellen. Der Nutzer kann über diese Systeme Anwendungen unabhängig von der spezifischen Linux-Distribution installieren.
AppImage ist ein weiteres Format für portable Softwarepakete unter Linux. Im Gegensatz zu Snap und Flatpak wird bei AppImages keine Installation durchgeführt. Stattdessen sind AppImages eigenständige ausführbare Dateien, die alle Abhängigkeiten enthalten und direkt ausgeführt werden können.
macOS
Unter macOS existieren neben dem integrierten App Store, welcher 2011 eingeführt wurde, weitere Paketmanager, bei denen es sich um Community-Projekte handelt.
Der App Store unter macOS
Der App Store selbst ist im Gegensatz zu seinem iOS-Pendant nicht verpflichtend zu nutzen. Auch wenn unsignierte Software mittlerweile nur nach einigen Warnmeldungen gestartet werden kann.
Bei den Community-Projekten stechen die Werkzeuge MacPorts und Homebrew hervor. MacPorts, früher unter dem Namen DarwinPorts bekannt, ist seit 2002 verfügbar und liegt mittlerweile in Version 2.8.1 vor.
MacPorts ist darauf ausgelegt, für jeden Port alle Abhängigkeiten selbst aus dem Quelltext zu kompilieren und zu verwalten. Dies führt zu einer größeren Isolation und Konsistenz, kann aber auch die Nutzung von mehr Speicherplatz und längere Installationszeiten bedeuten.
Der Paketmanager Homebrew wurde 2009 von Max Howell entwickelt. Homebrew versucht, wo möglich, vorhandene Systembibliotheken zu nutzen und installiert nur Abhängigkeiten die darüber hinaus benötigt werden. Dies kann zu schnelleren Installationen führen, birgt aber auch das Risiko eines Konfliktes mit Systembibliotheken.
Homebrew wird oft als benutzerfreundlicher wahrgenommen, mit einfacheren Befehlen und einer einfacheren Installation. Daneben verfügt es über eine breite Unterstützung für Binärpakete, die auf eine schnelle Installation abzielen und das Softwareangebot erweitern.
Die Anwendung der jeweiligen Paketmanager bleibt hierbei dem Nutzer überlassen, je nach dem gewünschten Anwendungszweck. So benötigt MacPorts Administratorrechte, während Homebrew in den meisten Fällen ohne solche auskommt. Genutzt werden beide Paketmanager über das Terminal.
Windows
An Windows ist der Erfolg der Paketmanager ebenfalls nicht vorbeigegangen. So wurde schon seit Windows Vista die Applikation Pkgmgr.exe mitgeliefert. Dabei handelte es sich um einen Paketmanager zur Installation und Deinstallation von Paketen.
Allerdings war dieser Paketmanager nicht für den Nutzer des Systems gedacht. Stattdessen diente er dazu, Komponenten des Betriebssystems zu installieren. Später wurde dieses System insbesondere durch DISM (Deployment Image Servicing and Management) abgelöst.
Neben dem Microsoft Store, welcher als App Store fungiert, existieren auch für Windows eine Reihe von Community getriebenen Paketmanagern. Hier wären unter anderem Chocolatey und Scoop zu nennen. Microsoft hat mit dem Windows Package Manager (winget) ebenfalls einen solchen Paketmanager vorgestellt. Eine detaillierte Betrachtung dieser Paketmanager findet sich auf Golem.de.
Daneben existieren auch Client-Managment-Plattformen, wie ACMP, welche für die Nutzer die Softwareinstallation aus einem Katalog ermöglichen und meist im geschäftlichen Umfeld zu finden sind.
Mobile Systeme
Während Systeme wie die PDAs von Palm überwiegend von Hand mit Apps bestückt wurden, sah dies bei den großen mobilen Systemen der Neuzeit, namentlich Android und iOS anders aus. Hier gab es bereits zu Beginn entsprechende
App Stores.
Google Play
Unter Android war dies der Android Market, welcher schließlich in Google Play aufging, unter iOS der App Store, welcher mit der Version iOS 2 (iPhone OS 2.0) seinen ersten Auftritt hatte.
Software kann über diese App Stores installiert, aktualisiert und deinstalliert werden. Im Unterschied zu reinen Paketmanagement-Lösungen bieten diese App Stores zusätzliche Dienste. Sie wickeln unter anderem Zahlungen ab, was sowohl In-App-Käufe als auch Abonnements einschließt.
Im Android-Bereich existieren daneben weitere alternative App Stores, wie der F-Droid App Store, welcher auf freie Software spezialisiert ist. Unter iOS ist dies bislang nicht ohne Jailbreak möglich. Dies soll sich allerdings durch den Digital Markets Act in der EU ändern.
Auch andere mobile Ökosysteme nutzen ihre jeweiligen App Stores wie Amazon, Samsung und Huawei.
Fazit
Ian Murdock, einer der Mitbegründer des Debian-Projektes, nannte Paketmanager einmal den größten einzelnen Fortschritt, welchen Linux der Industrie bescherte.
Sie erleichtern die Handhabung von Abhängigkeiten und Kompatibilitätsproblemen, die sonst für den Nutzer eine Herausforderung darstellen könnten. Mit dieser Idee haben sie viele Domänen erobert.
So begegnet uns das Konzept der Paketierung immer wieder, z. B. bei Docker-Containern. Auch bei neuen Programmiersprachen, wie Rust, wird das Paketmanagement gleich mitgedacht.
Paketmanager nehmen eine wichtige Rolle ein, indem sie die Installation, Aktualisierung und Entfernung von Softwarepaketen auf effiziente und benutzerfreundliche Weise ermöglichen und uns so auch in Zukunft begleiten werden.
In Zukunft wird auch verstärkt der Fokus auf unveränderliche Systeme und containerisierte Anwendungen gerichtet sein. Dieser Ansatz hat in jüngster Zeit mit Technologien wie Podman und Co. den Weg zurück auf den Desktop gefunden und spiegelt die wachsende Präferenz für isolierte, konsistente und portable Anwendungsumgebungen wider.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.