Im Rahmen digitaler Souveränität ist das Hosten auf GitHub eine zwiespältige Sache. Während die zugrundeliegenden Werkzeuge wie Git frei verfügbar sind, trifft dies auf Plattformen wie GitHub nicht zu.
Allerdings existieren auch Alternativen, wie Codeberg. Dabei handelt es sich um eine gemeinnützige, community-getriebene Plattform für die Entwicklung und das Hosting von Open-Source-Softwareprojekten. Betrieben wird sie vom eingetragenen Verein Codeberg e.V. mit Sitz in Berlin. Die Plattform bietet eine datenschutzfreundliche Alternative zu kommerziellen Diensten wie GitHub und richtet sich an Entwickler:innen, die Wert auf Transparenz, Offenheit und digitale Souveränität legen.
Die Plattform Codeberg
Nun ist ein vollständiger Wechsel für viele Nutzer nicht unbedingt immer möglich. Eine Alternative ist dann unter Umständen die Nutzung zweier Plattformen wie GitHub und Codeberg und eine entsprechende Spiegelung. Die der Codeberg zugrundeliegende Plattform Forgejo beherrscht die Spiegelung von Repositories. Allerdings ist dieses Feature auf der Plattform mit Absicht deaktiviert.
Wer eine solche Synchronisation nutzen möchte, ist damit auf weitere Werkzeuge angewiesen. Eines dieser Werkzeuge ist Gickup. Nach der Installation:
brew install gickup
sollte eine Konfigurationsdatei mit dem Namen conf.yml angelegt werden. Eine Minimalkonfiguration könnte folgendermaßen aussehen:
source:
github:
- token: topsecret-github-token
includeorgs:
- Entitaet
- seeseekey
wiki: true
issues: true
destination:
gitea:
- url: https://codeberg.org/
token: topsecret-codeberg-token
createorg: true
mirror:
enabled: true
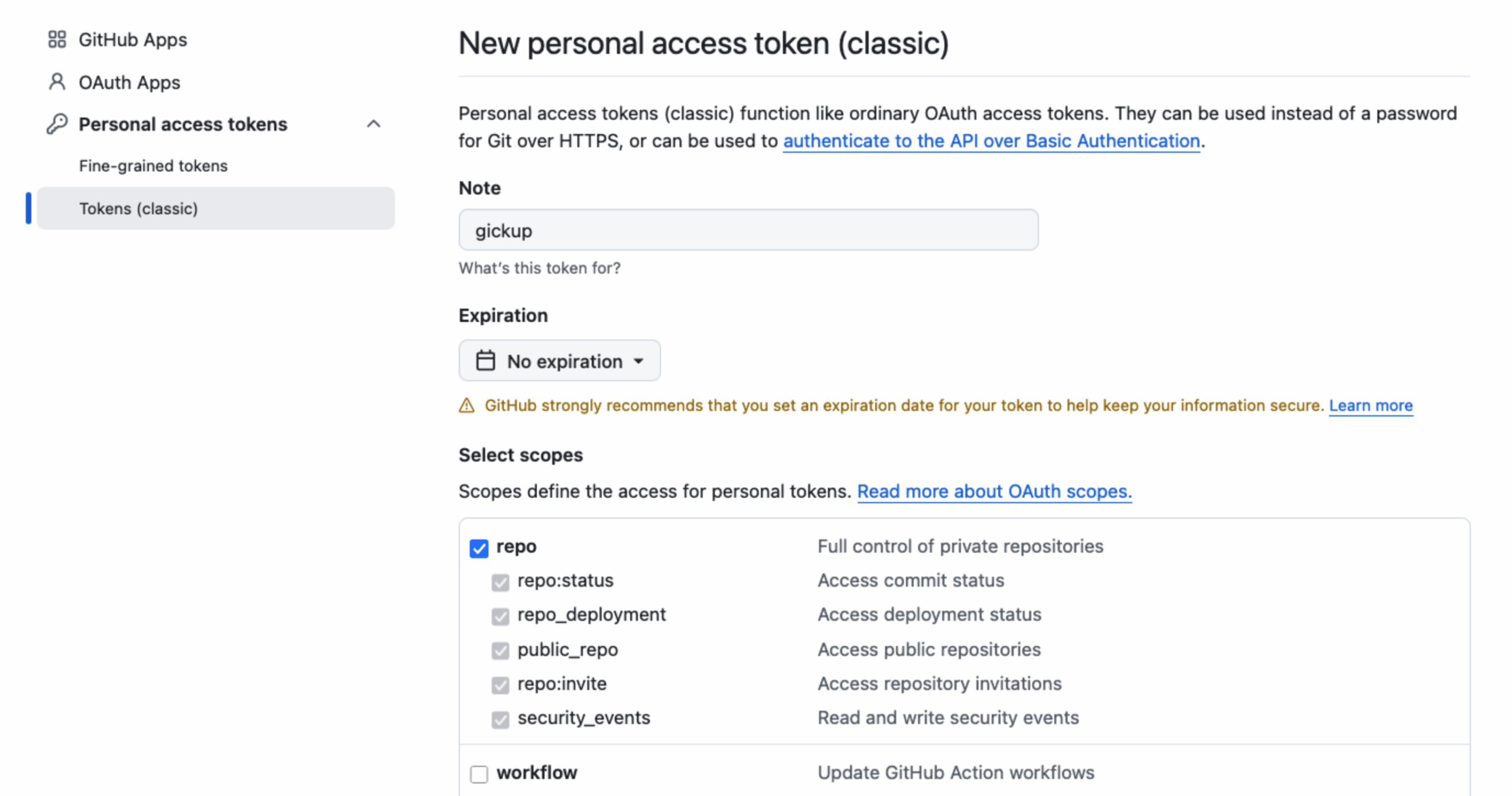
Diese Konfiguration stellt sicher, dass nur gewünschte Organisationen synchronisiert werden und dass Repositories von Organisationen, als solche in Codeberg angelegt werden. Die Token müssen auf GitHub und Codeberg angelegt werden und anschließend in der Konfiguration hinterlegt werden. Für GitHub wird dieses Token in den Einstellungen erzeugt. Hier sollte ein Classic-Token erzeugt werden und die Rechte für repo sollten zugewiesen werden.
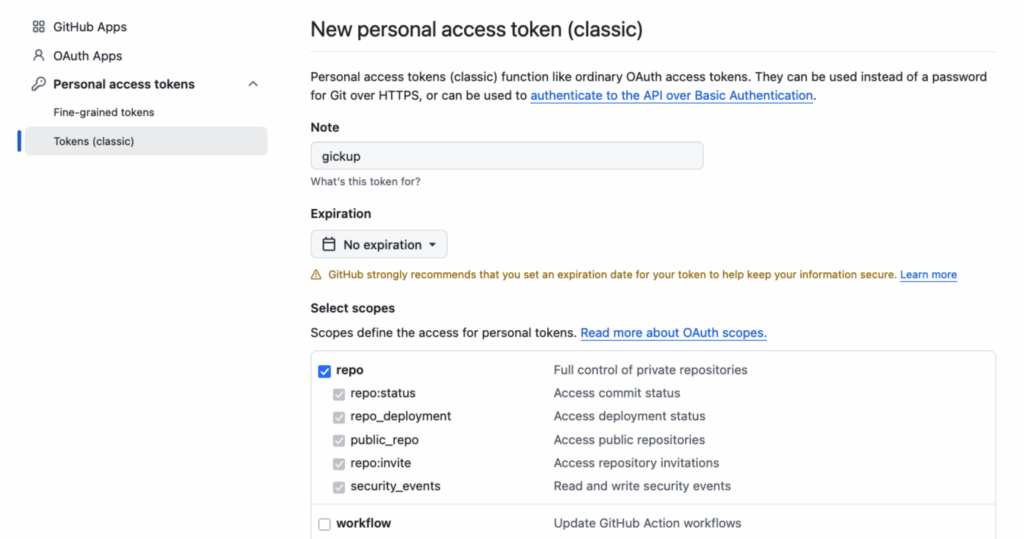
Für GitHub werden die repo-Berechtigungen benötigt
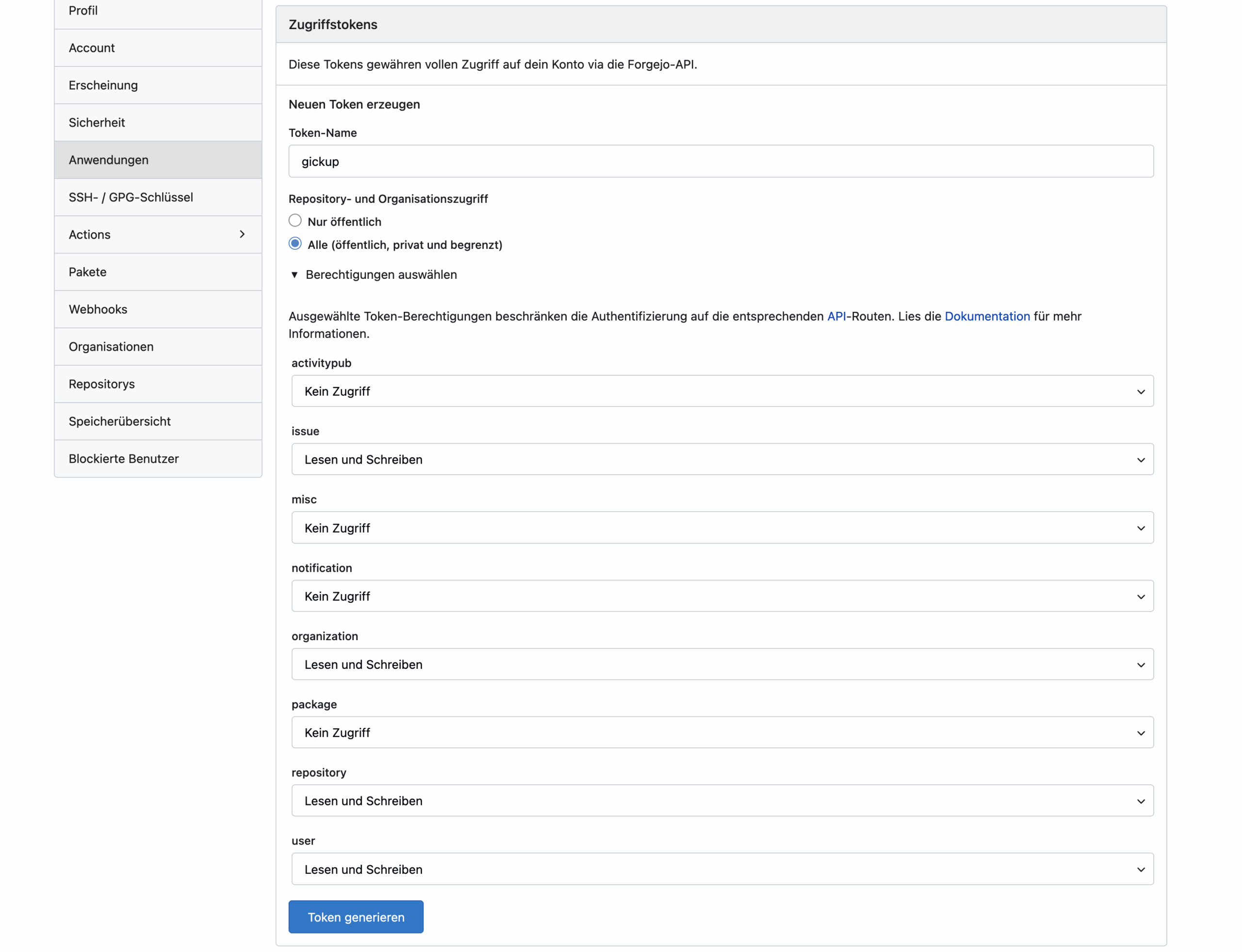
Unter Codeberg wird das neue Token ebenfalls in den Einstellungen unter Anwendungen angelegt.
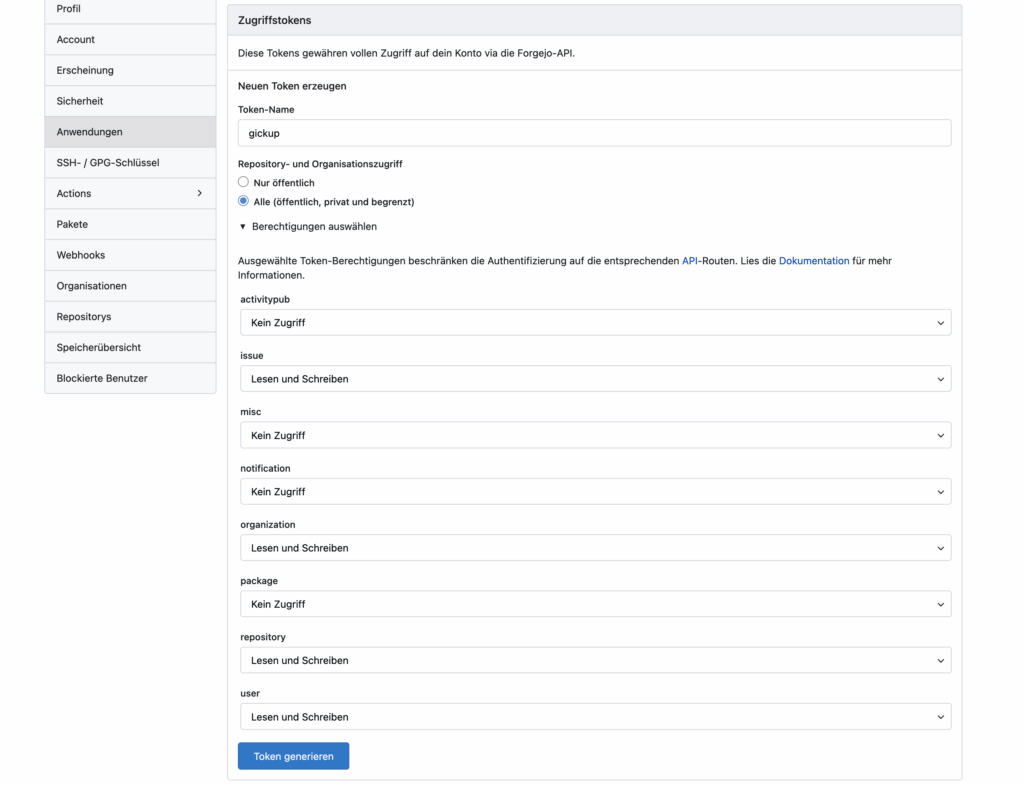
Das Token für Codeberg wird erzeugt
Nachdem die Token in der Konfiguration hinterlegt worden sind, kann der Prozess mittels gickup gestartet werden:
2025-05-20T21:18:50+02:00 INF Reading conf.yml file=conf.yml
2025-05-20T21:18:50+02:00 INF Configuration loaded destinations=1 pairs=1 sources=1
2025-05-20T21:18:50+02:00 INF Backup run starting
2025-05-20T21:18:50+02:00 INF grabbing my repositories stage=github url=https://github.com
2025-05-20T21:19:20+02:00 INF starting backup for https://github.com/Entitaet/autoxylophon.git stage=backup
2025-05-20T21:19:20+02:00 INF mirroring autoxylophon to https://codeberg.org/ stage=gitea url=https://codeberg.org/
2025-05-20T21:19:21+02:00 INF already up-to-date stage=gitea url=https://github.com/Entitaet/autoxylophon.git
Je nach Größe der eigenen Repositories kann die Spiegelung einige Minuten in Anspruch nehmen. Ist eine Aktualisierung gewünscht, so kann der Prozess einfach erneut angestoßen werden. Neben dieser Möglichkeit existieren weitere Möglichkeiten, um eine Spiegelung von Repositories zu Codeberg zu realisieren.