Wenn IPv4 als Initialzündung des modernen Internets gelten kann, dann ist IPv6 die seit Jahrzehnten geplante und inzwischen vielerorts gelebte Zukunft des Netzes.
Ein IETF-Entwurf (Draft) von Jamie Thain aus Bermuda will IPv6 überflüssig machen, das Internet neu erfinden und zu einhundert Prozent rückwärtskompatibel sein. Der Entwurf mit dem provokanten Namen Internet Protocol Version 8 wurde im April 2026 eingereicht und erhitzt seitdem die Gemüter.
Nicht, weil er als realistischer Nachfolger für IPv6 gilt, sondern weil viele Netzwerkexperten ihn als technisch fragwürdigen Alleingang mit Hang zum Größenwahn betrachten.
Er demonstriert, wie sehr der offene Einreichungsprozess der IETF zugleich Stärke und Schwäche ist. Jeder darf mitreden, doch am Ende trennt sich die Spreu vom Weizen. Der Vorfall trifft einen wunden Punkt. Nach 25 Jahren schleppender IPv6-Migration, steigendem geopolitischem Druck rund um Huaweis New IP und einer Community, die bei jeder neuen Versionsnummer reflexartig zuckt, entfaltet selbst ein aussichtsloser Einzelvorschlag erstaunliche Wirkung.
Das neue Internet
Im Entwurf sollen drei grundlegende Probleme des heutigen Internets gleichzeitig gelöst werden.
Das erste Problem ist der Mangel an IPv4-Adressen, den der Entwurf beheben möchte. Die vierte Version des Internet Protocols verwendet 32-Bit-Adressen und kann dadurch rund 4,3 Milliarden eindeutige Adressen bereitstellen. Diese Anzahl ist angesichts von Milliarden Smartphones, Servern, IoT-Geräten und Heimroutern nicht mehr ausreichend. Deshalb werden seit Jahren Techniken wie Network Address Translation (NAT) eingesetzt, bei denen sich viele Geräte eine einzige öffentliche IP-Adresse teilen.
Zweitens will der Entwurf die verteilte und uneinheitliche Netzwerkverwaltung beseitigen. Gemeint ist damit, dass Netzwerke heute über viele unterschiedliche Protokolle, Werkzeuge und Verwaltungsoberflächen konfiguriert und überwacht werden. Für Administratoren bedeutet das einen hohen Aufwand, da es keinen einheitlichen Mechanismus gibt, um alle Komponenten zentral zu steuern.
Drittens soll das unbegrenzte Wachstum der globalen BGP-Tabelle gestoppt werden. Das Border Gateway Protocol (BGP), ist das Routing-Protokoll, das festlegt, über welche Wege Datenpakete durch das Internet transportiert werden. Jeder Internetanbieter kündigt dabei an, für welche IP-Adressbereiche er erreichbar ist. Diese Informationen werden weltweit gesammelt. Die daraus entstehende Routing-Tabelle umfasst inzwischen weit über eine Million Einträge und wächst kontinuierlich weiter. Das stellt hohe Anforderungen an Speicher und Rechenleistung der Router im Internet-Backbone.
Der Entwurf behauptet, dass IPv6 auch nach 25 Jahren nur einen Minderheitsanteil des weltweiten Internetverkehrs erreiche und der parallele Betrieb von IPv4 und IPv6 wirtschaftlich nicht tragbar sei.
Aus dieser Analyse zieht der Autor den Schluss, dass nicht eine Vereinfachung, sondern ein noch umfassenderer Neuansatz erforderlich sei; gebündelt unter der bewusst provokanten Bezeichnung IPv8, einer Versionsnummer, die bereits in den 1990er Jahren mit dem PIP-Vorschlag verbunden war.
Der Entwurf im IETF-Datatracker
Begleitet wird der Kern-Entwurf zumindest dem Anspruch nach von einem ganzen Paralleluniversum aus BGP8, OSPF8, IS-IS8, WHOIS8, NetLog8, WiFi8 und SNMPv8. Im Hauptdokument werden diese Begleit-Spezifikationen zwar aufgelistet, die angegebenen Drafts sind jedoch nicht bei der IETF hinterlegt. Was wie ein kompletter Protokoll-Stack wirkt, ist offenbar vorwiegend eine Verweiskulisse.
Wer ist Jamie Thain?
Öffentlich taucht Thain bereits 2004 auf, damals als CTO des bermudianischen Internetproviders Transact im Kontext des Sasser-Wurms. In den folgenden Jahren arbeitete er laut Unternehmensprofilen als Technologiearchitekt im Telekommunikationsumfeld und war unter anderem an der Planung von 4G-LTE-Netzen, FTTH-Infrastrukturen und Unterseekabelsystemen beteiligt.
Später war Thain CTO bei Bluewave Bermuda, einem lokalen WISP- und ISP-Betreiber. Gemeinsam mit Jack Benaim gründete er anschließend den Bermuda-Inkubator InnoFund. InnoFund betrieb zusammen mit dem Inkubator DMZ den Startup-Accelerator i3 powered by DMZ. Daneben existiert auch BPMS Ltd, eine weitere von Thain mitbegründete Firma. Als aktuelle Zugehörigkeit führt der IPv8-Draft One Limited auf.
Doch welche Motivation steckte hinter dem Draft? Thain wollte ursprünglich keine neue Version des Internet-Protokolls entwickeln, sondern eine schlüsselfertige Komplettlösung für den Betrieb eines Netzwerks erstellen. Weil ihm IPv6 für dieses Vorhaben zu komplex erschien, entwickelte er während eines krankheitsbedingten Ausfalls mithilfe von KI innerhalb von fünf Tagen einen Vorschlag für einen neuen Protokoll-Stack.
IPv4 mit Vorwahl
Thains Kernidee ist überraschend konservativ. Statt IPv6 mit seinen 128-Bit-Adressen und neuem Header abzulösen, erweitert IPv8 den klassischen IPv4-Header um acht zusätzliche Oktette.
Architektonisch sieht der Entwurf einen 64-Bit-Adressraum vor, der wie folgt aufgebaut ist:
r.r.r.r.n.n.n.n
Die ersten 32 Bit codieren hierbei laut Spezifikation direkt eine 32-Bit-ASN. Eine Autonomous System-Nummer (ASN) ist die eindeutige Kennung eines Netzbetreibers oder einer Organisation im globalen Routing.
Große Provider wie die Deutsche Telekom, Cloudflare oder Google besitzen jeweils eine oder mehrere ASNs. Jede Organisation mit einer ASN erhält damit jeweils einen eigenen IPv4-Adressraum mit knapp 4,3 Milliarden Hostadressen. Im Entwurf stellt sich dies beispielhaft wie folgt dar:
64496.192.0.2.1 = 0.0.251.240.192.0.2.1 64497.192.0.2.1 = 0.0.251.241.192.0.2.1
Im Kern handelt es sich damit um eine Rückkehr zu einer frühen 64-Bit-Adressidee, die Steve Deering in der Vorgeschichte von IPv6 verfolgte, mit dem Unterschied, dass Thain die obere Hälfte des Adressraums fest an ASNs bindet.
Die zentrale Verkaufsbotschaft des Entwurfs lautet, dass IPv4 eine Teilmenge von IPv8 sei. Gemeint ist damit, wenn die ersten vier Oktette einer IPv8-Adresse auf 0.0.0.0 gesetzt werden, soll die Adresse wie eine ganz normale IPv4-Adresse behandelt werden.
Aus dieser Konstruktion leitet der Autor die weitreichende Behauptung ab, dass bestehende Geräte, Anwendungen und Netzwerke nicht verändert werden müssen, um an einem IPv8-Netz teilzunehmen. Der Übergang könne schrittweise erfolgen, ohne Stichtag und ohne erzwungene Migration. Der Entwurf fasst das selbstbewusst zusammen:
No existing device, application, or network requires modification. The suite is 100% backward compatible. There is no flag day and no forced migration at any layer.
Diese Behauptung kollabiert spätestens im Abschnitt über das Header-Format:
IPv8 uses IP version number 8 in the Version field. The header extends IPv4 by replacing the 32-bit src/dst address fields with 64-bit equivalents.
Bestehende IPv4-Stacks und Router würden Pakete mit der Versionsnummer 8 aber in aller Regel verwerfen.
Zone Server
Das eigentliche Kern des Entwurfs verbirgt sich nicht in der Adressmathematik, sondern im Abschnitt mit dem Namen IPv8 Management Philosophy.
Zentrales Element der Architektur ist der sogenannte Zone Server. Dabei handelt es sich um ein redundant ausgelegtes Serverpaar, bei dem beide Systeme gleichzeitig aktiv sind und gemeinsam eine Vielzahl bislang getrennter Dienste in einer einzigen Infrastruktur bündeln.
Im IPv8-Entwurf übernehmen diese Zone Server gemeinsam DHCP, DNS, Authentifizierung, Logging und Routenvalidierung. Fällt einer aus, bleibt der andere ohne Umschaltung weiter in Betrieb. Der Entwurf verlangt genau zwei sogenannte Zone Server pro Subnetz.
Dabei sollen die ebenfalls neuen Protokolle wie DHCP8, DNS8, NTP8, NetLog8, OAuth8, WHOIS8, ACL8 und XLATE8 auf diesen Systemen laufen. Jeder Endpunkt erhält bereits mit einer einzigen DHCP8-Discover-Antwort sämtliche Informationen über die verfügbaren Dienste.
Vorgeschrieben sind zwei Zone Server pro Subnetz, die auf den Adressen .254 und .253 betrieben werden. Hosts mit geraden Adressen verwenden standardmäßig den einen Server, Hosts mit ungeraden Adressen den anderen.
Komplexität gewünscht
Zusätzlich setzt der Entwurf voraus, dass in jedem Netzwerk ein zentraler Switch als sogenannter PVRST-Root fungiert. Per-VLAN Rapid Spanning Tree (PVRST) ist eine von Cisco Systems entwickelte proprietäre Variante des Spanning-Tree-Protokolls, die Schleifen in Ethernet-Netzen verhindert.
In größeren Ethernet-Netzen existieren oft mehrere redundante Verbindungen zwischen Switches. Ohne Schutzmechanismen könnten dadurch Schleifen entstehen, bei denen Datenpakete endlos im Kreis laufen. Spanning Tree-Protokolle verhindern das, indem sie einen Root-Switch auswählen und anschließend überflüssige Verbindungen deaktivieren.
Bemerkenswert ist, dass der Entwurf eine herstellerspezifische Technologie zur festen Voraussetzung eines globalen Internetprotokolls macht. Ein offener Internetstandard sollte sich nicht auf proprietäre Mechanismen eines einzelnen Herstellers stützen.
Auch das Routing wird vollständig neu organisiert. Vorgesehen sind eBGP8, IBGP8 und OSPF8; IS-IS8 bleibt als unterstützte Option erhalten, während die Protokolle RIP und EIGRP ausdrücklich als veraltet gelten. Über die Grenzen von autonomen Systemen hinweg sollen nur Präfixe bis maximal /16 propagiert werden. Jede Route muss vor ihrer Installation über die neue WHOIS8-Infrastruktur validiert werden, die der Entwurf als globale kritische Infrastruktur versteht. Die weltweite Routingtabelle soll dadurch strukturell auf die Anzahl der autonomen Systeme begrenzt werden.
Zur Pfadbewertung führt der Entwurf den sogenannten Cost Factor ein, einen 32-Bit-Wert, der Round-Trip-Time, Paketverlust, Congestion-Window, Sitzungsstabilität, Linkkapazität, wirtschaftliche Vorgaben und geografischer Entfernung kombiniert. So versucht der Entwurf, technische Messwerte, physikalische Grenzen und sogar wirtschaftliche Interessen in einer einzigen Zahl zu vereinen. Diese Vermischung sehr unterschiedlicher Einflussfaktoren wird von vielen Fachleuten als übermäßig komplex und praktisch kaum umsetzbar angesehen.
Im Bereich Sicherheit verfolgt der Entwurf einen sehr weitreichenden Ansatz. Jede verwaltbare Komponente, vom Endgerät über den Switch bis zum Router, muss sich mithilfe von OAuth2 und JSON Web Tokens eindeutig authentifizieren. Bevor ein Gerät am Netzwerk teilnehmen darf, muss es also nachweisen, dass es dazu berechtigt ist.
Auch ausgehende Verbindungen werden streng kontrolliert. Bevor ein Paket das Netzwerk verlassen darf, muss zunächst ein DNS8-Lookup erfolgreich sein. Erst dann wird ein entsprechender XLATE8-Eintrag angelegt, der die Verbindung überhaupt ermöglicht. Zusätzlich wird überprüft, ob das Zielnetz in der WHOIS8-Infrastruktur als gültig registriert ist. Schlagen diese Prüfungen fehl, wird die Verbindung blockiert.
Die Netzwerkkarten selbst sollen nicht überschreibbare Hardware-Limits durchsetzen, die nur durch explizite Anweisung des Zone Servers angehoben werden können. Konkret sind das maximal zehn Broadcasts pro Sekunde, zehn unauthentifizierte Pakete pro Sekunde und einhundert authentifizierte Pakete pro Sekunde.
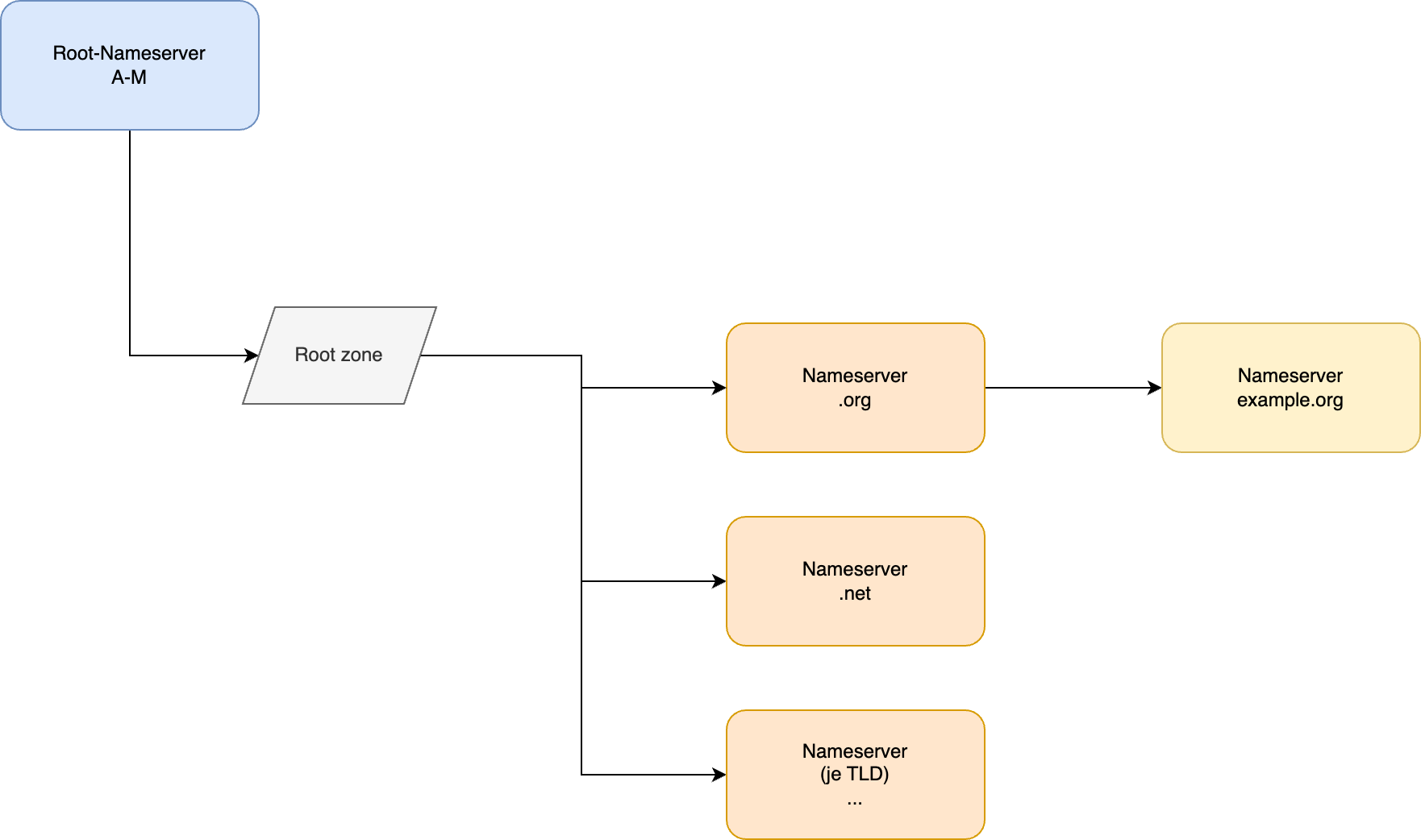
Schließlich verlangt der Entwurf eine ganze Reihe offizieller Zuweisungen durch die Internet Assigned Numbers Authority. Die IANA verwaltet weltweit zentrale Nummern- und Adressbereiche des Internets, darunter IP-Versionen, DNS-Recordtypen und spezielle Netzwerkbereiche.
Der Entwurf beantragt zunächst, die Versionsnummer 8 für ein neues Internetprotokoll zu reservieren, obwohl diese Bezeichnung historisch bereits mit PIP verbunden war. Ferner sollen mehrere bekannte IPv4-Adressbereiche für neue Zwecke fest zugewiesen werden: 127.0.0.0/8 als interner Bereich für Zone Server, 100.0.0.0/8 für RINE-Peering und 222.0.0.0/8 für interne Verbindungen.
Zusätzlich fordert der Entwurf einen neuen DNS-Recordtyp mit dem Namen A8, spezielle Reservierungen für ASNs sowie einen eigenen Multicast-Adressbereich. Damit IPv8 funktionieren könnte, müssten zahlreiche zentrale Ressourcen des Internets offiziell neu vergeben und dauerhaft reserviert werden.
Angriff auf das Schichtenmodell
Was der Entwurf als elegante Vereinheitlichung präsentiert, verletzt ein grundlegendes Prinzip des Internets: die Trennung der Protokollschichten. IP arbeitet auf einer sehr niedrigen Ebene und hat im Wesentlichen nur die Aufgabe, Pakete von A nach B zu transportieren.
OAuth2 und JSON Web Tokens gehören dagegen in eine deutlich höhere Schicht, in der sich Anwendungen um Benutzeranmeldung und Zugriffsrechte kümmern. Der IPv8-Entwurf vermischt beide Ebenen und verlangt damit von einfachen Netzwerkgeräten Aufgaben, für die sie weder konzipiert noch ausgelegt sind.
Was IPv8 ignoriert
Bemerkenswert ist nicht nur, was der IPv8-Entwurf vorschlägt, sondern auch, was er komplett ausblendet. Zahlreiche Technologien, die genau die von ihm beschriebenen Probleme bereits heute adressieren, werden mit keinem Wort erwähnt. Dazu gehören moderne Routing-Erweiterungen für IPv6, etablierte Verfahren zur Absicherung von BGP-Routen sowie bewährte Übergangstechniken, mit denen IPv4 und IPv6 seit Jahren parallel betrieben werden.
So ignoriert der Entwurf beispielsweise RPKI und ROA, obwohl diese Mechanismen bereits heute die Herkunft von Routen kryptografisch absichern. Stattdessen entwirft er mit WHOIS8 eine vollkommen neue globale Validierungsinfrastruktur.
Gleiches gilt für NAT64, 464XLAT und andere Techniken, die in Mobilfunknetzen weltweit produktiv eingesetzt werden, um IPv6-only-Infrastrukturen mit IPv4-Diensten zu verbinden.
Selbst grundlegende Bestandteile moderner IPv6-Netze wie SLAAC, Router Advertisements und DHCPv6 werden übergangen und durch neue Eigenentwicklungen wie DHCP8 ersetzt.
Für die Authentifizierung an Switch-Ports schlägt der Entwurf OAuth2 vor, ohne das etablierte Verfahren 802.1X mit EAP-TLS auch nur zu erwähnen. Insgesamt entsteht der Eindruck, dass der Entwurf viele Probleme neu erfindet, ohne bestehende Lösungen oder die Erfahrungen der letzten zwei Jahrzehnte zu berücksichtigen.
Reaktionen
Besonders häufig wird kritisiert, dass der Entwurf bestehende und bereits standardisierte Lösungen ignoriert, gleichzeitig aber eine Vielzahl neuer Protokolle, Dienste und zentraler Kontrollinstanzen einführt.
Viele Kritiker sehen in dem Entwurf daneben ein von Grund auf kontrollorientiertes Protokoll, das sich besonders gut für zentrale Überwachung und Regulierung eignet. Wer den Zone Server, die WHOIS8-Registry oder die zentrale Authentifizierungsinfrastruktur betreibt, erhält letztlich die Kontrolle über das gesamte Netzwerk.
Die versprochene vollständige Rückwärtskompatibilität gilt vielen als nicht glaubwürdig, weil das Paketformat, die Routing-Protokolle und zahlreiche Infrastrukturkomponenten grundlegend verändert werden. Auch die enge Verzahnung von IP mit OAuth2, zentralen Authentifizierungsdiensten und globalen Validierungsinstanzen wird als deutlicher Bruch mit den dezentralen Grundprinzipien des Internets gesehen.
Mehrere Analysen heben hervor, dass der Entwurf reale Probleme wie IPv6-Migrationskosten, BGP-Wachstum und operative Komplexität durchaus korrekt benennt. Die vorgeschlagene Lösung wird jedoch als unverhältnismäßig und praktisch kaum umsetzbar bewertet. Insbesondere die starke Zentralisierung, die Abhängigkeit von neuen kritischen Infrastrukturen und die Vermischung unterschiedlichster Technologien stoßen auf breite Skepsis.
Bemerkenswert ist auch, was ausbleibt. Auf den etablierten Fachforen und Mailinglisten der Internet-Community blieb der Entwurf weitgehend ohne ernsthafte Unterstützung. Prominente Stimmen aus der Routing- und IETF-Welt äußerten sich entweder gar nicht oder nur am Rande. Dieses Schweigen ist in einem Umfeld, in dem tragfähige Ideen normalerweise schnell fachliche Diskussionen auslösen, selbst eine deutliche Form der Einordnung.
Eine kurze Phantomologie
Wer IPv8 sagt, betritt einen Friedhof. Die niedrigen Versionsnummern des Internet Protocols sind seit Jahrzehnten vergeben, verworfen oder Teil der Netzfolklore geworden.
Die Versionen 0 bis 3 stammen aus der Frühzeit des Internets. Sie tauchten in den experimentellen Vorläufern von TCP/IP in den späten 1970er Jahren auf, erreichten aber nie einen produktiven Einsatz. Mit IPv4, spezifiziert in RFC 791 aus dem Jahr 1981, entstand schließlich das Protokoll, das bis heute das Fundament des Internets bildet.
Die Version 5 wurde für ST und ST-II verwendet, ein Streaming-Protokoll mit Reservierungsmechanismen für Echtzeitdaten. IPv6 ging aus Steve Deerings SIPP-Entwurf hervor und wurde Mitte der 1990er Jahre als offizieller Nachfolger von IPv4 standardisiert. IPv7 stand für TP/IX und später CATNIP, zwei alternative Vorschläge, die sich nie durchsetzen konnten.
Besonders relevant für den aktuellen Fall ist die Versionsnummer 8. Sie war bereits in den 1990er Jahren mit PIP von Paul Tsuchiya verbunden, einem der Kandidaten im damaligen Wettbewerb um den IPv4-Nachfolger. Auch wenn diese Zuordnung heute keine praktische Bedeutung mehr hat, ist IPv8 in der Geschichte der IETF keineswegs eine unbeschriebene Zahl.
Die Version 9 ist gleich mehrfach belegt. Dazu gehören TUBA, der berühmte Aprilscherz RFC 1606 und das sogenannte chinesische IPv9, das Anfang der 2000er Jahre als nationale Alternative zu IPv6 propagiert wurde. Selbst IPv10 existiert bereits als individueller Internet-Draft aus dem Jahr 2017, der schlicht argumentierte, dass IPv4 plus IPv6 zusammen eben zehn ergeben.
Thain verwendet damit eine Versionsnummer erneut, ohne auf ihre historische Vorbelegung einzugehen, und behandelt die Version, als stünde sie zur freien Verfügung. Streng genommen ist das nicht falsch: IANA hat die Reservierungen nach dem IPv6-Beschluss bereinigt. Aber die völlige Abwesenheit jeglicher historischen Einordnung im Entwurf ist ein bemerkenswertes Symptom.
Politisch aufgeladen
Dass ein technischer Einzelvorschlag überhaupt derart reflexhaft als zensurfreundlich gelesen wird, hat eine Vorgeschichte. Im September 2019 reichte Huawei, gemeinsam mit China Mobile, China Unicom und dem MIIT, bei der ITU-T einen Vorschlag mit dem Namen New IP ein. Im Rahmen der Focus-Group Network 2030 unter Richard Li präsentierte Huawei variable Adresslängen, semantische Adressen, benutzerdefinierte Header und ein berüchtigtes Shut-up Kommando auf Paketebene.
Die britische Financial Times zitierte anonyme ITU-Delegierte, die von einem enormen Kampf unter der Oberfläche sprachen. Seither ist jeder neue alternative IP-Stack-Vorschlag mit diesem Bezugsrahmen markiert, ob er aus Shenzhen, Shanghai oder eben Bermuda stammt.
Thains Entwurf adressiert keinerlei chinesische Agenda, doch seine zentralen Designentscheidungen wie OAuth2-Authentifizierung pro verwaltbarem Element, WHOIS8-Egress-Validierung jeder ausgehenden Verbindung, Zone-Server als Pflicht-Gateway, NIC-Firmware mit hardwareseitig erzwungenen Paketlimits, treffen exakt die Alarmnerven, die New IP hinterlassen hat.
Die Einschätzung, der Entwurf sei von Grund auf zensurfreundlich, ist kein Zufall, sondern spiegelt die Erfahrungen und Befürchtungen wider, die seit den Debatten um Huaweis New IP die Diskussion über die Zukunft des Internets prägen.
Die späte Pubertät von IPv6
Um sich den Fakten anzunähern, lohnt sich ein Blick auf den Zustand von IPv6 im April 2026. Googles Messung erreichte am 28. März 2026 erstmals einen Tages-Spitzenwert von 50,1 Prozent auf Google-Dienste weltweit; eine Schlagzeile, die mit kaum verhohlener Erleichterung gefeiert wurde. Der Durchschnitt pendelt seither zwischen 45 und 50 Prozent, je nach Wochentag. APNIC Labs misst rund 43 Prozent, Cloudflare etwa 40 Prozent bezogen auf HTTP-Requests.
Zu den Spitzenreitern zählen Frankreich, Indien und Saudi-Arabien; je nach Messmethode liegen sie deutlich über dem weltweiten Durchschnitt, dicht gefolgt von Indien, dessen hohe Werte wesentlich durch Reliance Jios früh eingeführte IPv6-only-Mobilfunknetze geprägt sind, sowie Deutschland.
Die USA überschreiten inzwischen die 50-Prozent-Marke, liegen im internationalen Vergleich jedoch nur im Mittelfeld. China wird im IPv6 Development Report 2025 mit 77 Prozent aktiven IPv6-Nutzern ausgewiesen; der dort genannte IPv6-Anteil am Gesamttraffic liegt jedoch nur bei 34 Prozent. Länder wie Sudan, Turkmenistan und viele Staaten in Afrika und Zentralasien erreichen weiterhin nur sehr geringe IPv6-Anteile von unter fünf Prozent.
Die IPv4-Knappheit hat sich dagegen deutlich entspannt. Große Blöcke ab /16 fielen bis Februar 2026 im Durchschnitt auf knapp unter zehn US-Dollar pro Adresse. Halter werfen Pools auf den Markt, weil sie fallende Preise antizipieren. Das Leasing-Geschäft bleibt stabil bei rund 0,50 US-Dollar pro IP und Monat. AWS berechnet seit Februar 2024 rund 44 Dollar pro Jahr pro öffentlicher IPv4-Adresse. Der wirtschaftliche Druck, auf IPv6 zu migrieren, ist real, aber nicht existenziell.
Geoff Huston von APNIC kommt in einer linearen Fortschreibung der aktuellen Entwicklung zu dem Ergebnis, dass der Übergang zu IPv6 erst gegen Ende des Jahres 2045 abgeschlossen wäre. Zugleich stellt er die Frage, ob das Internet nicht dauerhaft in einer Koexistenz aus IPv4 und IPv6 verharren könnte.
Die IETF-Gremien 6MAN und V6OPS beschäftigen sich mit Wartung, nicht mit Nachfolgern. Forschungsansätze wie SCION oder Named Data Networking haben den Testbed-Status bisher nicht verlassen und ersetzen IP in der Praxis nicht, während QUIC und HTTP/3 Performance-Probleme auf der Transportschicht lösen.
Der IETF-Prozess
Die entscheidende Einordnung, die in vielen Berichten untergeht, ist, dass ein Internet-Draft für sich nahezu keine Bedeutung hat. Jede Person kann einen solchen Entwurf einreichen. Die Prüfung durch das IETF-Sekretariat beschränkt sich im Wesentlichen auf formale Aspekte wie Struktur, vorgeschriebene Standardtexte und offensichtliche Verstöße gegen grundlegende Richtlinien. Anschließend erhält das Dokument einen offiziellen Dateinamen, ist für sechs Monate gültig und wird mit dem üblichen Hinweis versehen:
This I-D is not endorsed by the IETF and has no formal standing in the IETF standards process.
Bis aus einem Internet-Draft ein offizieller RFC wird, ist es ein weiter Weg. Zunächst muss eine zuständige Working Group den Entwurf überhaupt aufgreifen und zu ihrem eigenen Arbeitsdokument machen. Danach folgen meist zahlreiche Überarbeitungen, öffentliche Diskussionsrunden und mehrere formale Prüfungen durch die Führungsgremien der IETF. Erst wenn dabei ein breiter Konsens entsteht und idealerweise bereits mehrere unabhängige Implementierungen existieren, wird das Dokument als RFC veröffentlicht.
Für Einzelentwürfe ohne Unterstützung einer Working Group ist dieser Weg in der Praxis nur selten erfolgreich. Aber es existieren Ausnahmen wie HTTP/1.0, TLS, OAuth 2.0, QUIC und JWT, welche als Individual Drafts starteten, bevor sie in Working Groups überführt wurden.
Sie brachten jedoch von Anfang an funktionierende Implementierungen, konkrete Einsatzszenarien und starke Unterstützung aus der Industrie und der Community mit. Fehlt eine solche technische und organisatorische Basis, verschwinden die meisten Vorschläge nach kurzer Zeit wieder, ohne jemals den Status eines Standards zu erreichen.
Fazit
Der Fall IPv8 zeigt in erster Linie, dass das IETF-System bewusst offen gestaltet ist. Diese Offenheit ist eine Stärke, bringt aber zwangsläufig auch Vorschläge hervor, die nie eine realistische Chance auf Standardisierung haben.
Der Entwurf ist kein realistischer Nachfolger für IPv6, sondern ein technisch fragwürdiger Alleingang. Er benennt zutreffend die schleppende IPv6-Migration, das Wachstum der BGP-Tabelle und die betriebliche Komplexität moderner Netze. Die Antwort darauf ist jedoch ein noch komplexerer Protokoll-Stack.
Die versprochene vollständige Rückwärtskompatibilität hält einer technischen Prüfung nicht stand. Bestehende Systeme werden Pakete mit der Versionsnummer 8 in aller Regel schlicht verwerfen. Wer IPv6 aus Kosten- und Trägheitsgründen bisher nicht eingeführt hat, wird einen noch aufwendigeren Nachfolger erst recht nicht ausrollen.
Dass der Entwurf dennoch für Aufmerksamkeit sorgt, liegt weniger an seiner technischen Substanz als an seinem Namen und am Zeitgeist. Die eigentliche Konsequenz ist unspektakulär, aber naheliegend: die konsequente Weiterverbreitung von IPv6.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.





{kind=link}