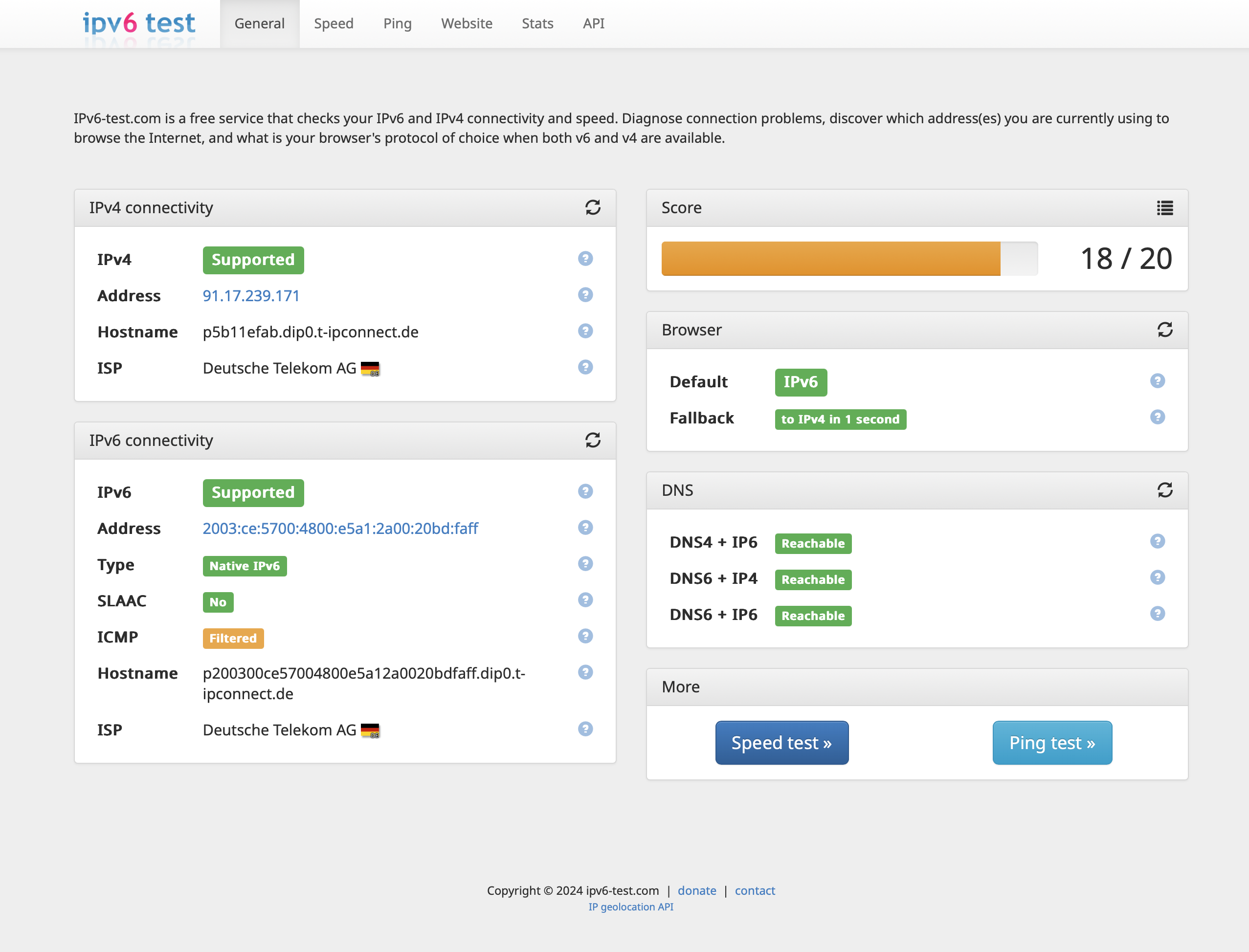
Vor einiger Zeit bin ich zu Congstar DSL gewechselt. Charmant fand ich, dass keine Festnetztelefonie mit angeboten wird und sich stattdessen auf ein reines Datenprodukt konzentriert wurde.
ipv6-test.com
Weniger schön war das Congstar nur IPv4 unterstützte, obwohl es ebenfalls zur Deutschen Telekom gehört, welche IPv6 bei ihren Anschlüssen anbietet. Allerdings scheint dieser Makel zumindest bei mir der Vergangenheit anzugehören, da neben einer IPv4-Adresse nun auch eine IPv6-Adresse zugeteilt wird und genutzt werden kann. Damit bleibt nur zu hoffen das dies auch in Zukunft so bleibt und es sich nicht nur um einen unverbindlichen Test handelt.
Der Begriff des Fluent Interface hat mittlerweile knapp zwei Jahrzehnte auf dem Buckel und solche Schnittstellen sind mittlerweile auch in größerem Umfang in der Praxis angekommen und werden dort vielfältig genutzt. Trotzdem scheint es manchmal schwer zu fallen genau zu definieren, was ein solches Fluent Interface ist, was es auszeichnet und wie es in der Praxis sinnvoll genutzt werden kann.
Herkunft
Fluent Interfaces, welche wohl holprig mit einer fließenden Schnittstelle übersetzt werden könnten, sind eine Begrifflichkeit, welche in dieser Form erstmals 2005 von Martin Fowler und Eric Evans definiert wurden.
Martin Fowler ist bekannt für seine Arbeit, am Manifest für Agile Softwareentwicklung und seine Bücher, welche unter anderem das Code-Refactoring in die breite Öffentlichkeit trugen und populär machten.
Eric Evans ist vorwiegend für seine Beiträge rund um das Domain-Driven Design bekannt, dessen Gedanken er erstmals im gleichnamigen Buch Anfang der 2000er-Jahre zusammenfasste und somit den Begriff prägte.
Sinnvoller wäre für Fluent Interfaces allerdings die Bezeichnung als sprechende Schnittstelle, welcher eher der Idee im Kern entspricht. Bezugnehmend auf die Wortherkunft aus dem englischen to be fluent in a language, kann allerdings auch im Deutschen von Fluent Interfaces gesprochen werden.
Ideen des Fluent Interfaces
Dem Namen entsprechend ist eines der Ziele eines Fluent Interfaces, APIs besser lesbar und verstehbarer zu gestalten. Daneben soll die API Funktionalitäten passend zum Objekt bereitstellen können.
Bei Betrachtung einer solchen sprechenden Schnittstelle, soll der Quellcode sich wie eine natürliche Sprache bzw. ein Text in einer solchen anfühlen, anstatt eine Reihe von abstrakten Anweisungen darzustellen. Martin Fowlerdefinierte auch ein Maß für diese Fluidität:
The key test of fluency, for us, is the Domain Specific Language quality. The more the use of the API has that language like flow, the more fluent it is.
Ein schönes Beispiel für die Nutzung einer solchen sprechenden Schnittstelle ist die Anwendung des Mock-Frameworks Mockito:
when(uuidGenerator.getUUID()).thenReturn(15);
Auch ohne genauere Kenntnisse über Mockito kann der Programmierer aus diesem Beispiel herauslesen, dass wenn die Methode getUUID angefordert wird, im Rahmen des Mocks immer der Wert 15 zurückgegeben wird.
Die Zeile kann mit sprachlichen Mitteln einfach gelesen werden und verrät dem Nutzer etwas über die dahinterliegende Funktionalität. Das Ziel, die entsprechenden Schnittstellen einfach lesbar und benutzbar zu machen, wird sich dadurch erkauft, dass es meist aufwendiger ist, solche Schnittstellen zu designen und zu entwickeln.
Dies bedingt sich durch das vorher zu durchdenkende Design und einem Mehraufwand beim Schreiben des eigentlichen Quellcodes, unter anderem in Form zusätzlicher Methoden und anderen Objekten zur Abbildung des Fluent Interface.
Zur Implementierung von Fluent Interfaces werden unterschiedliche Techniken wie das Method Chaining genutzt. Daneben werden häufig Elemente wie statische Factory-Methoden und entsprechende Imports, sowie benannte Parameter genutzt.
Sprechende Schnittstellen ermöglichen es auch Personen einen Einblick in den Quellcode zu geben, welche nicht mit den technischen Details desselben vertraut sind. Auch bei der Abbildung von fachlicher Logik helfen Fluent Interfaces, z. B. über entsprechende Methodennamen, welche sich auf die Fachlichkeit der Anwendung beziehen.
Method Chaining
Eine der Techniken zur Erstellung von sprechenden Schnittstellen ist das Method Chaining, welches im Deutschen treffend mit Methodenverkettung übersetzt werden kann.
Methodenketten sind eine Technik, bei der mehrere Methoden aufeinanderfolgend aufgerufen werden, um ein Ergebnis zu erhalten. Beispielsweise könnte ein Entwickler mehrere Methoden aufrufen, um einen bestimmten Wert aus einem Array zu extrahieren oder einen Alternativwert bereitzustellen. Die Methodenketten ermöglichen es dem Entwickler, mehrere Aufgaben in einer Kette zu erledigen, anstatt sie auf getrennte Statements zu verteilen.
Das bedeutetet allerdings im Umkehrschluss nicht, dass die Verkettung von Methoden gleich einem Fluent Interface entspricht, sodass an dieser Stelle immer differenziert werden sollte.
Am Ende einer Methodenkette wird das benötigte Objekt zurückgegeben oder die gewünschte Aufgabe ausgeführt. Aussehen könnte eine solche Methodenkette, in diesem Fall am Beispiel der Stream-API, wie folgt:
User nathalie = Arrays.stream(users)
.filter(user -> "Nathalie".equals(user.getForename()))
.findFirst()
.orElse(null);
Bei solchen Methodenketten gilt es zu berücksichtigen, dass bestimmte Methoden innerhalb der Kette im schlimmsten Fall null zurückgeben oder Exceptions auslösen. Je nach genutztem Interface müssen diese Fälle entsprechend beachtet werden.
Interessanterweise brechen Methodenketten mit einigen älteren Konventionen. So würden z. B. Setter in einem Builder-Pattern:
einen Wert zurückgeben, in diesem Beispiel das Builder-Objekt. Im Normalfall würde der Setter stattdessen keinen Rückgabeparameter aufweisen. Er wäre in einem gewöhnlichen Objekt wie folgt definiert:
public void setName(String name) {
this.name = name;
}
Diese Konvention rührt vom Command-Query-Separation-Pattern, welches besagt, dass entweder Kommandos oder Queries definiert werden sollten. Abfragen als solche, dürfen keinerlei Auswirkungen am Zustand der Klasse haben, während bei Kommandos entsprechende Auswirkungen explizit erwünscht sind. Dies ist z. B. dann der Fall, wenn Daten geändert werden.
Method Nesting
Eine weitere Technik, welche für die Nutzung und das Design von Fluent Interfaces benutzt wird, ist das Method Nesting bzw. das Verschachteln von Methoden. Ein Beispiel hierfür liefert die Java-Bibliothek REST Assured, welche eine domänenspezifische Sprache zur Abfrage und Validierung von REST-Services darstellt:
Neben der Verkettung von Methoden werden hier auch Methoden ineinander verschachtelt. In diesem Fall wird die startWith-Methode innerhalb der body-Methode geschachtelt, was dafür sorgt, dass beim Lesen ein besseres Verständnis entsteht, was im Quellcode passiert.
Die startWith-Methode stammt hierbei aus dem Hamcrest-Framework, welches viele solcher Methoden, unter anderem zur Nutzung in Unit-Tests, bereitstellt.
Statische Imports
Damit die Sprachelemente der Bibliothek im obigen Beispiel nicht immer voll referenziert werden müssen, werden statische Imports genutzt:
Damit kann eine statische Methode ohne ihren Klassennamen referenziert und genutzt werden. Ohne diesen statischen Import würde obiges Beispiel etwas umfangreicher aussehen:
Damit wird über den Mechanismus der statischen Importe sichergestellt, dass der Quelltext, im Rahmen der Philosophie der sprechenden Schnittstellen, möglichst lesbar bleibt.
Object Scoping
Vor allem in Programmiersprachen mit einem globalen Namensraum und echten Funktionen können Funktionen, welche einzelne Bestandteile einer domänenspezifischen Sprache darstellen, in diesem globalen Namensraum angelegt werden.
Allerdings ist dies in den meisten Fällen unerwünscht, sodass die Bestandteile der domänenspezifischen Sprache, wie im Beispiel REST Assured in entsprechende Objekte verpackt werden und damit den globalen Namensraum entlasten. Dieses Vorgehen trägt den Namen Object Scoping.
Anwendung
Doch wozu können solche Fluent Interfaces in der Praxis genutzt werden? Unterschiedlichste Szenarien werden immer wieder angesprochen, wenn es um die Nutzung dieser Technik geht.
Eine häufigere Anwendung ist das Builder-Pattern und die Nutzung in Form domänenspezifischer Sprachen kurz DSLs bzw. im englischen Original Domain Specific Languages.
Eine solche domänenspezifische Sprache ist eine Programmiersprache, welche für ein bestimmtes Feld, besagte Domäne, entwickelt wird. Häufig werden sie verwendet, um komplexe Aufgaben zu vereinfachen, indem eine auf die Domäne und die zu lösenden Probleme angepasste Syntax genutzt wird, welche meist große Schnittmengen mit der Fachlichkeit der Domäne beinhaltet.
Fluent Interfaces in der Java-Welt
Auch in der Java Class Library existieren APIs, welche als Fluent Interface angelegt sind. Ein prominentes Beispiel hierfür ist die Stream-API:
User aMustermann = Arrays.stream(users)
.parallel()
.filter(user -> "Mustermann".equals(user.getName()))
.findAny()
.orElse(null);
Über die Stream-API können unterschiedlichste Anforderungen abgebildet werden. In diesem Fall wird ein Array mit Objekten vom Typ User durchsucht und parallel ein Nutzer mit dem Nachnamen Mustermann gesucht. Dieses Objekt wird dann zurückgegeben. Wird kein solches Objekt gefunden, so wird stattdessen null zurückgegeben.
Auch in anderen Frameworks wie Mocking-Frameworks oder solchen Bibliotheken, welche domänenspezifische Sprachen abbilden, wird intensiv Gebrauch von Fluent Interfaces gemacht.
Frameworks, wie Spring, nutzen ebenfalls interne DSLs, um bestimmte Anforderungen und Möglichkeiten zur Konfiguration abzubilden.
Fluent Interfaces im Builder-Pattern
Eine weitere Anwendung für Fluent Interfaces im weiteren Sinne ist das sogenannte Builder-Pattern. Bei diesem existiert eine Klasse und ein dazugehöriger Builder, welcher dazu dient das Objekt zu konstruieren.
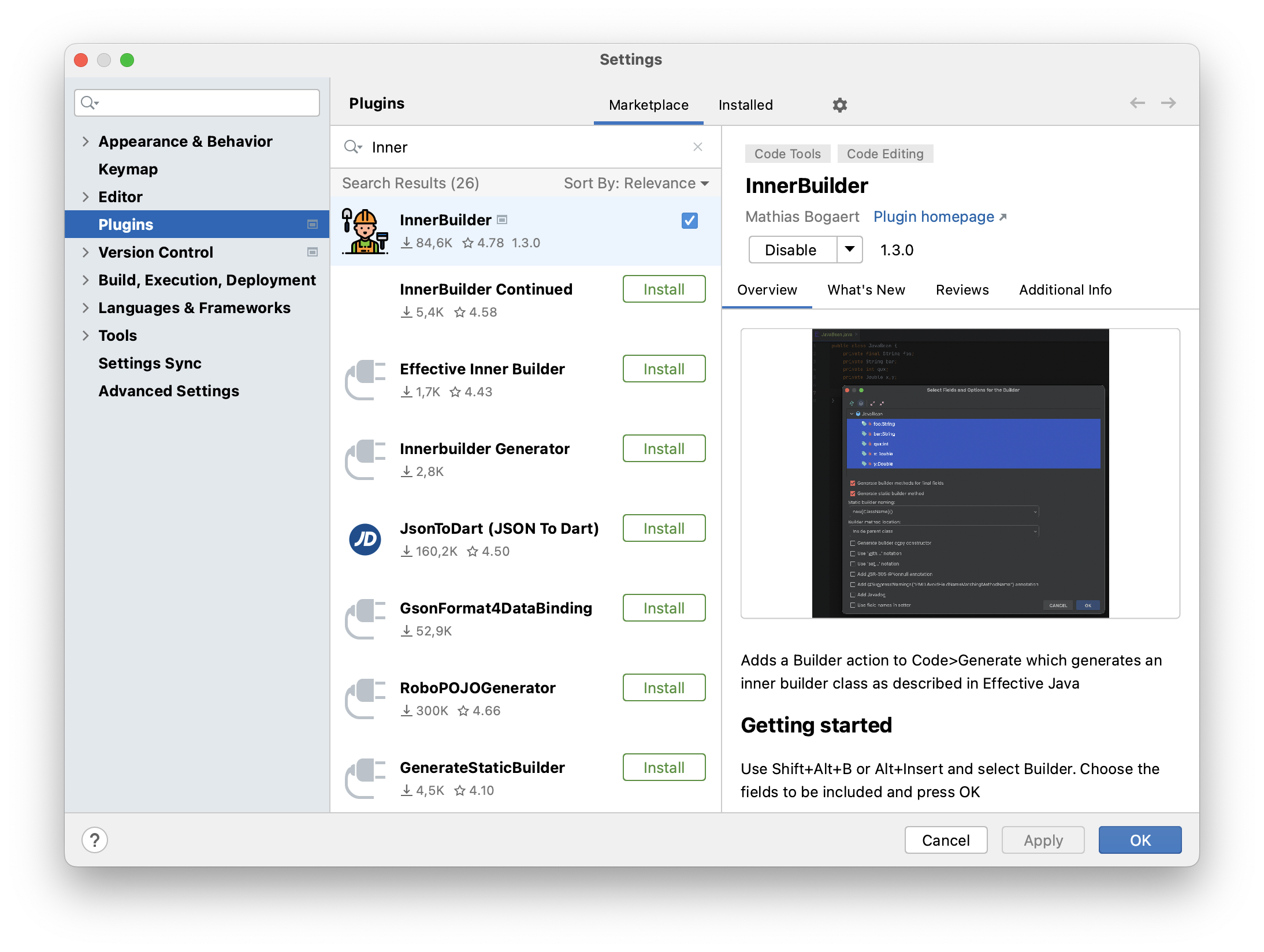
Hier wird ersichtlich, dass dies auf den ersten Blick mehr Aufwand bei der Implementation bedeutet. Allerdings müssen „Standardaufgaben“, wie das Erstellen eines Builders nicht unbedingt von Hand erledigt werden, da es für unterschiedlichste IDEs entsprechende Unterstützung in Form von Erweiterungen gibt. Für IntelliJ IDEA wäre ein Plugin für diese Aufgabe der InnerBuilder von Mathias Bogaert.
Ein Plugin für die einfache Erzeugung von Buildern in IntelliJ IDEA
Mithilfe dieser Plugins können Builder-Klassen schnell erstellt und bei Änderungen der eigentlichen Basisklasse angepasst werden, indem die Builder-Klasse über das Plugin neu generiert wird. Dies ermöglicht eine unkomplizierte Änderung von Klassen samt ihrer dazugehörigen Builder.
Manchmal wird beim Builder-Pattern infrage gestellt, ob es sich bei diesem wirklich um ein Fluent Interface handelt. Dabei wird die Unterscheidung getroffen, dass Fluent Interfaces sich mehr auf die Manipulation und Konfiguration von Objekten konzentrieren, während Builder den Fokus auf die Erzeugung von Objekten legen.
Es stellt sich allerdings die Frage, inwiefern diese Gedanken akademischer Natur, in der Praxis relevant sind, da auch Builder sich aus Sicht des Lesers des Quellcodes gut als Fluent Interfaces erschließen lassen.
Builder-Pattern im Beispiel
Wie könnte ein solches Builder-Pattern nun an einem einfachen Beispiel aussehen? Gegeben sei folgende Klasse:
public class User {
private String name;
private String forename;
private String username;
public User() {
}
}
Die Klasse mit dem Namen User enthält drei Felder in welchen der Name, Vorname und der Nutzername des Nutzers gespeichert werden. Um die Felder der Klasse zu befüllen, existieren unterschiedliche Möglichkeiten.
So könnte ein entsprechender Konstruktor definiert werden, welcher diese Felder setzt:
Dieser könnte nun aufgerufen werden, um eine Instanz der Klasse zu erstellen und die Felder zu füllen:
User max = new User("Mustermann", "Max", "maxmustermann");
Soll jedoch ein Wert nicht gesetzt werden, kann dieser auf null gesetzt werden. Allerdings kann es hier auch den Fall geben, dass mit NotNull-Annotationen und einer entsprechenden Validation gearbeitet wird:
public User(@NotNull String name, @NotNull String forename, @NotNull String username)
Durch die Annotation soll verhindert werden, dass die entsprechenden Felder mit dem Wert null initialisiert werden können. In einem solchen Fall ist für die entsprechenden Felder auch die Anwendung des Builder-Patterns nur schwer vorstellbar, z. B. über das Setzen der Werte in der newBuilder-Methode.
Sind solche Einschränkungen nicht vorhanden, könnte alternativ mit unterschiedlichen Konstruktoren gearbeitet werden, in welchen jeweils nur einige der Felder gesetzt werden können.
Spätestens bei komplexeren Objekten wird auffallen, dass diese Methode eher ungeeignet ist. Der klassische Weg ist es hier entsprechende Getter und Setter zum Abrufen und Setzen der Eigenschaften bereitzustellen:
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getForename() {
return forename;
}
public void setForename(String forename) {
this.forename = forename;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
Zwar können Getter und Setter auch über Annotationen, z. B. mithilfe der Bibliothek Lombok, vor dem Compile-Vorgang, generiert werden, allerdings hält der Autor nicht sonderlich viel von dieser Art von „Präprozessor-Magie“.
Hierbei werden unnötige Abhängigkeiten für doch recht simple Aufgaben, an das Projekt angehangen, welche wiederum bestimmte Funktionsweisen vor dem Entwickler verstecken. Vor allem, wenn der Entwickler nicht mit dem Projekt vertraut ist, kann dies das Verständnis erschweren.
Unter Nutzung der Setter kann ein Objekt nun feingranular mit den gewünschten Werten befüllt werden:
User user = new User();
user.setName("Mustermann");
user.setForename("Max");
user.setUsername("maxmustermann");
Soll z. B. der Vorname nicht gesetzt werden, so kann die entsprechende Zeile einfach weggelassen werden. Diese Nutzung bzw. Schreibweise wird manchmal unter dem Namen Method Sequencing zusammengefasst.
An dieser Stelle könnte stattdessen ein Builder genutzt werden. Bei diesem würde das Ganze wie folgt aussehen:
User user = User.Builder.newBuilder()
.name("Mustermann")
.forename("Max")
.username("maxmustermann")
.build();
Bei dieser Schreibweise wird der Builder genutzt, um das Objekt zu erstellen und mit seinen Werten zu befüllen. Der Builder liefert dazu die benötigen Methoden:
public static final class Builder {
private String name;
private String forename;
private String username;
private Builder() {
}
public static Builder newBuilder() {
return new Builder();
}
public Builder name(String name) {
this.name = name;
return this;
}
public Builder forename(String forename) {
this.forename = forename;
return this;
}
public Builder username(String username) {
this.username = username;
return this;
}
public User build() {
return new User(this);
}
}
In vielen modernen Implementationen des Pattern wird meist auf das Präfix set für die Setter verzichtet und stattdessen nur der Name des Feldes als Methode definiert. Alternativ wird häufig auch das Präfix with genutzt.
Beim Quelltext wird ersichtlich, dass jede Methode, bis auf die build-Methode, eine Instanz des Builders zurückgibt und damit die Verkettung der unterschiedlichen Methoden erlaubt.
Fluent Interfaces zur Definition einer DSL nutzen
Neben dem Entwicklungsmuster des Builders können mithilfe von Fluent Interfaces domänenspezifische Sprachen (DSLs) erstellt werden.
Bei solchen Sprachen handelt es sich um speziell für ein bestimmtes Anwendungsgebiet entwickelte Programmiersprachen. Sie sind oft einfacher und leichter zu verstehen als allgemeine Programmiersprachen und ermöglichen es Entwicklern bzw. den Anwendern der Sprache, effizienter und präziser zu programmieren.
DSLs werden häufig in bestimmten Bereichen wie der Finanzbranche, der Medizin, der Luftfahrtindustrie, der Spieleentwicklung und der Datenanalyse eingesetzt. Sie können dazu beitragen, Prozesse zu automatisieren und zu vereinfachen und ermöglichen Entwicklern, komplexe Aufgaben in kürzerer Zeit zu erledigen.
Zu den bekanntesten domänenspezifischen Sprachen gehört SQL und auch reguläre Ausdrücke können als DSL gesehen werden. Grundsätzlich werden domänenspezifischen Sprachen in externe und interne Sprachen unterteilt.
Bei den internen DSLs wird eine Wirtssprache, in diesem Beispiel Java, genutzt, um die DSL abzubilden. Externe DSLs hingegen stehen für sich allein und nutzen keinerlei Wirtssprache. Deshalb sind sie auf eigens dafür entwickelte Compiler oder Interpreter angewiesen.
Im folgenden Beispiel soll eine DSL für HTML entwickelt und anhand dieser sollen einige Konzepte der sprechenden Schnittstellen in Zusammenhang gebracht werden. Die HTML-DSL soll dazu genutzt werden, HTML-Dokumente zu bauen. Ein Aufruf dieser DSL könnte wie folgt aussehen:
String html = new Html()
.head()
.meta("UTF-8")
.meta("keywords", "fluent, interface")
.title("Fluent interfaces")
.finalise()
.body()
.text("Fluent interfaces")
.br()
.finalise()
.generate();
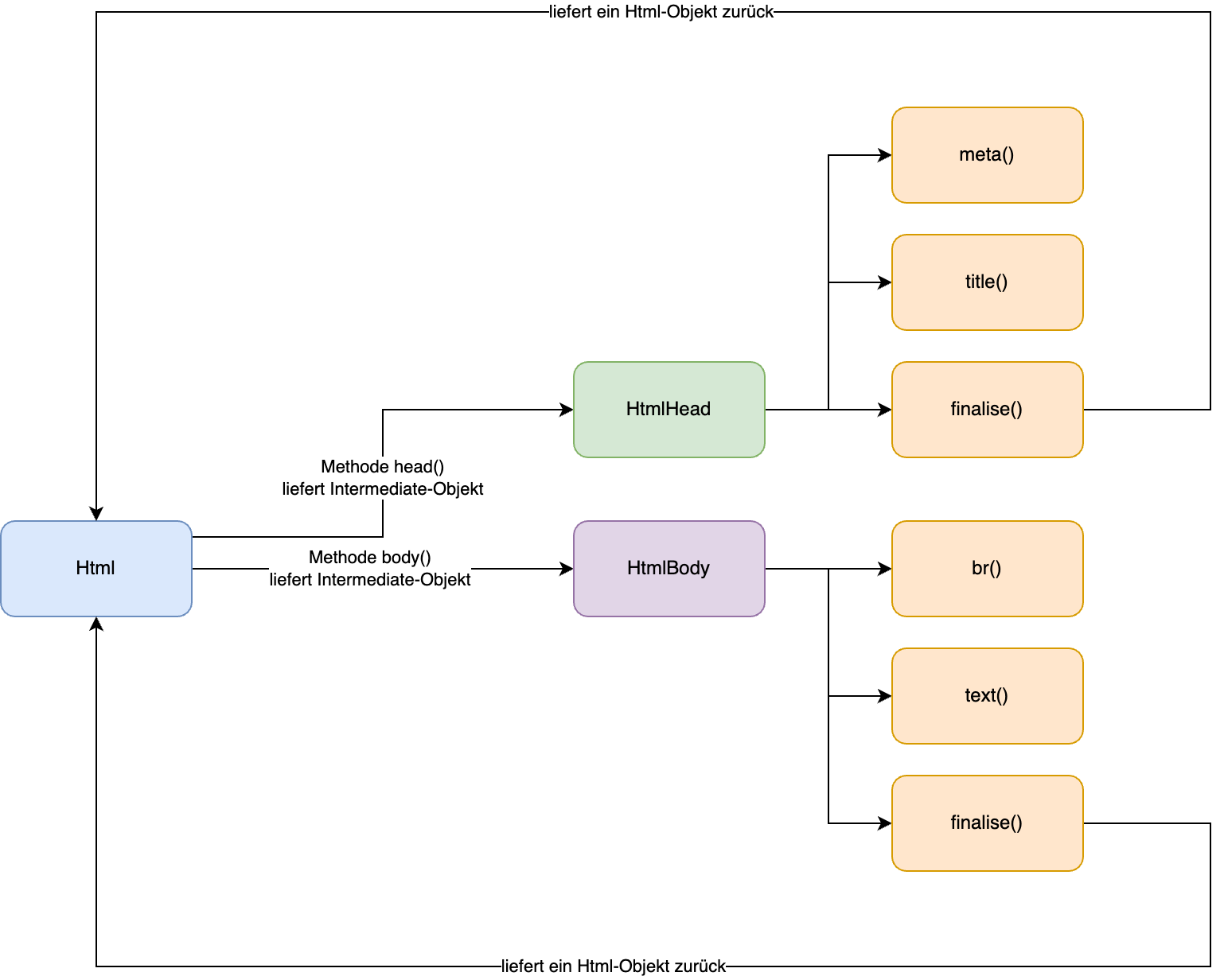
Während bei einem einfachen Builder immer der Builder als solcher zurückgegeben wird, wird in diesem Fall nicht immer das Hauptobjekt, die Klasse Html, zurückgegeben. Stattdessen werden teilweise sogenannte Intermediate-Objekte zurückgegeben. Diese haben außerhalb der DSL keinerlei sinnvolle Funktionalität, sondern dienen dazu nur die Methoden anzubieten, welche im Kontext von HTML erlaubt sind.
Über Intermediate-Objekte lassen sich somit auch bestimmten Reihenfolgen erzwingen. Damit kann der Compiler zumindest zur partiellen Überprüfung der Anweisungen benutzt werden und dem Anwender bzw. Entwickler werden nur die Funktionalitäten zur Verfügung gestellt, welche im entsprechenden Kontext sinnvoll sind.
Über die Intermediate-Objekte werden die entsprechenden Methoden zur Verfügung gestellt
Unterstützt wird der Entwickler daneben durch die Autovervollständigung der IDE, welche die Methoden des jeweiligen Intermediate-Objektes darstellen kann. Anschließend dient die Methode finalise dazu, wieder eine Ebene höher in der Hierarchie der Intermediate-Objekte zu wandern.
In der Theorie könnten die entsprechende Verschachtelung beliebig komplex gestaltet werden. So können div-Blöcke als Elemente genutzt werden und innerhalb des Intermediate-Objektes für den div-Block stehen dann ausschließlich solche Elemente, welche im Rahmen eines div-Blockes genutzt werden können.
Bei der Nutzung einer solchen domänenspezifischen Sprache ist es wichtig, dass der jeweilige Aufruf auch sinnvoll beendet werden muss. So kann es bei falscher Nutzung durchaus passieren, dass der Entwickler, wenn er entsprechende Aufrufe vergisst, ein Intermediate-Objekt als Rückgabe am Ende erhält, mit welchem er nicht viel anfangen kann. Dieses Problem wird auch als Finishing-Problem bezeichnet.
Beim Design einer DSL muss immer sichergestellt werden, dass es einen Aufruf in den jeweiligen Intermediate-Objekten gibt, welcher dafür sorgt am Ende ein sinnvolles Ergebnis zu erhalten bzw. wieder zum eigentlichen Objekt zurückführt.
Automatische Generation von sprechenden Schnittstellen
Viele domänenspezifische Sprachen werden von Hand geschrieben, allerdings existieren durchaus Ansätze solche Sprachen auch über eine entsprechende definierte Grammatik zu generieren.
Auch Codegeneratoren wie z. B. für GraphQL-Schnittstellen erzeugen unter Umständen Fluent Interfaces, welche dann genutzt werden können:
return new ProductResponseProjection()
.categoryId()
.categoryName()
.issuingCountry();
In diesem Fall wird aus dem GraphQL-Schema eine entsprechende API plus das dazugehörige Modell generiert, welches sich dann nach Außen hin als Builder– bzw. Fluent Interface darstellt.
Ob und wieweit die Generierung von sprechenden Schnittstellen automatisiert werden kann, hängt immer sehr stark vom jeweiligen Anwendungsfall ab.
Fazit
Fluent Interfaces sind ein Begriff, der nun schon eine Weile durch die Welt geistert und wahrscheinlich finden sich in den Köpfen unterschiedliche Vorstellung davon.
Teilweise ist es schwierig, eine harte Definition von sprechenden Schnittstellen zu finden, wie der StringBuilder unter Java zeigt:
String abc = new StringBuilder()
.append("ABC")
.append("DEF")
.append("GHJ")
.toString();
Die append-Methode stellt hier eine Art Builder-Pattern in Form einer sprechenden Schnittstelle zur Verfügung und kann damit im Kleinen als solche gesehen werden. Die Bandbreite von Fluent Interfaces im Kleinen, wie dem Builder-Pattern, bis zu ausgewachsenen domänenspezifischen Sprachen mit eigenen Grammatiken ist groß.
Alles in allem spielen sprechende Schnittstellen vorwiegend bei komplexen Objekten und entsprechenden Use Cases ihre Stärken aus. Sie sorgen für mehr Verständnis und nutzen die Möglichkeiten des Compilers und der IDE zur Unterstützung aus.
Trotz der Vorteile, welche solche sprechenden Schnittstellen bieten, sollte vor der Implementation immer genau überlegt werden, ob für den jeweiligen Anwendungszweck wirklich ein solche benötigt wird. Hier sollte die erhöhte Komplexität in der Implementation und Pflege mit der Notwendigkeit abgewogen werden.
Der Quellcode der einzelnen vorgestellten sprechenden Schnittstellen kann über GitHub eingesehen und ausprobiert werden.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.
Im Internet existieren eine Reihe von Diensten und Applikationen. Eine der wichtigsten Dienste, wenn nicht die Killerapplikation des Internets als es noch das ARPANET war, ist E-Mail. Zeit, ein wenig auf die Hintergründe dieses Systems zu blicken.
Einleitung
Zur Kommunikation existieren unterschiedlichste Dienste, welche das Internet nutzen, um Nachrichten von A nach B zu übermitteln. So sind im privaten Umfeld Messenger wie WhatsApp und Co nicht mehr wegzudenken. Daneben ist einer der wichtigsten Dienste für die Kommunikation die klassische E-Mail.
Der durchschnittliche Nutzer wird meist ein E-Mail-Programm auf dem Rechner, dem Mobilgerät oder ein Web-Mailer im Browser nutzen. Für den Nutzer ist es nicht wichtig wie das System funktioniert, allerdings lohnt es sich einen Blick hinter die Kulissen zu werfen und zu sehen, wie das System funktioniert und welche Herausforderungen der Betrieb eines E-Mail-Servers in der heutigen Zeit mit sich bringt.
Geschichte
Die Idee Nachrichten von A nach B zu verschicken gab es schon in der Frühzeit der Computertechnik, sogar noch früher, wenn elektrische Telegrafen einbezogen werden. So gab es ab dem Jahr 1962 mit dem Automatic Digital Network des US-Militärs bereits ein System, um Nachrichten an unterschiedlichste Standorte zu verteilen.
1968, mit der Erfindung des ARPANET, einem Forschungsprojekt im Auftrag des US-Militärs, wurden nicht nur die Grundlagen für unsere heutige Internetarchitektur geschaffen, sondern einige Jahre später, im Jahr 1971, die erste E-Mail versendet. Wobei hier der Terminus Network Mail genutzt wurde.
Für den Transfer der E-Mail wurde das Programm SNDMSG genutzt, welches es ermöglichte Nachrichten bzw. E-Mails von einem Nutzer zu einem anderen Nutzer auf dem gleichen System zu schicken.
Technisch war eine Mailbox nicht mehr als eine Datei, welche nur vom berechtigten Nutzer gelesen werden konnte, aber von unterschiedlichen Nutzern über SNDMSG geschrieben werden konnte.
Die Neuerung war nun die Idee, SNDMSG so zu erweitern, dass es E-Mails auch zu anderen Hosts senden konnte. Dafür wurde das At-Zeichen als Trennzeichen gewählt, um den eigentlichen Nutzer vom entsprechenden Host zu trennen. Daneben wurde READMAIL zum Lesen der Mails genutzt. Beide Programme, SNDMSG und READMAIL, wurden damals mit dem Betriebssystem TENEX genutzt.
Parallel zur ARPANET-Implementation und Vorstellung von Network Mail entstanden im Laufe der Zeit einige kommerzielle E-Mail-Systeme, sowie der X.400-Standard, welche bereitstanden, die Vorherrschaft der E-Mail-Systeme anzunehmen.
Bedingt durch die Öffnung des Internets gegenüber der kommerziellen Nutzung, genauer gesagt der Aufhebung der Restriktionen im Jahr 1995, mauserten sich SMTP, POP3 und IMAP zu den vorherrschenden Protokollen für das Senden und Abfragen von E-Mails.
Vorher war die kommerzielle Nutzung der damals im Rahmen des National Science Foundation Network-Programmes bereitgestellten Netzwerke durch entsprechende Richtlinien stark eingeschränkt. Grundsätzliche sollten diese Netzwerke hauptsächlich der Forschung und Lehre genutzt werden.
Auch wenn es heutzutage noch einige Bereiche gibt, in denen andere Standards genutzt werden, wie der X.400-Standard bei der Rufnummernportierung, hat sich der aktuelle E-Mail-Standard durchgesetzt.
Damit die Systeme trotzdem miteinander verbunden sein können, gab und gibt es unterschiedlichste Gateways, welche andere Netzwerke und E-Mail-Systeme miteinander verbinden.
Trennzeichen gesucht
Die Idee Nachrichten über Rechnergrenzen hinweg zu versenden führte zu dem Problem, dass diese Rechner adressiert werden müssen. Als Trennzeichen wurde das At-Zeichen (@) gewählt, welches nicht nur von der Bedeutung ideal war, sondern auch das Zeichen als solches war größtenteils ungenutzt. Damit war der Weg zu Adressen nach dem Schema nutzer@host frei.
Auf heutigen Tastaturen ist das At-Zeichen selbstverständlich
Bei der Auswahl des Zeichens war das Kriterium, dass das Zeichen auf den damaligen Tastaturen vorhanden war, aber auf keinen Fall ein Bestandteil eines Namens sein dürfte.
The primary reason was that it made sense. at signs didn’t appear in names so there would be no ambiguity about where the separation between login name and host name occurred. (Of course, this last notion is now refuted by the proliferation of products, services, slogans, etc. incorporating the at sign.) The at sign also had no significance in any editors that ran on TENEX. I was later reminded that the Multics time-sharing system used the at sign as its line-erase character. This caused a fair amount of grief in that community of users. Multics used IBM 2741 terminals which used EBCDIC character coding. They did not have a „control“ modifier key and didn’t have many (any?) non-printing characters beyond space, backspace, tab, and return. The designers of Multics were constrained to using printing characters for line-editing.
Während das Zeichen zuvor hauptsächlich zur Trennung von Mengen und Preisen genutzt wurde, hielt das Zeichen damit Stück für Stück Einzug in die moderne Welt und wurde praktisch zu einem unverkennbaren Zeichen der vernetzten Welt.
E-Mail, email, Mail?
Neben der eigentlichen Technik hinter dem E-Mail-System wurden im Laufe der Zeit auch andere Dinge, wie die Terminologie und Schreibweise, verhandelt. Während die Schreibweise im Deutschen als E-Mail definiert ist, sind im englischen Formen wie email, e-mail, E-mail, EMAIL und weitere Schreibweisen bekannt. Gebräuchlich ist hier meist die Schreibweise email bzw. e-mail. Bei RFCs hingegen wird im Author’s Adressblock die historisch bedingte Form EMail genutzt.
Dezentral wie das Netz
Das E-Mail-System an sich ist als dezentrales System für asynchrone Kommunikation konzipiert.
Das bedeutet, dass es nicht ein großer Betreiber existiert, welcher für alle E-Mail-Adressen der Welt zuständig ist. In der Theorie kann jeder Nutzer eines Rechners, welcher mit dem Internet verbunden ist, einen solchen E-Mail-Server betreiben.
Die Asynchronität definiert unter anderem dadurch, dass E-Mails abgeschickt werden können, ohne dass der Mail-Server des Empfängers erreichbar sein muss.
Systeme mit drei Buchstaben
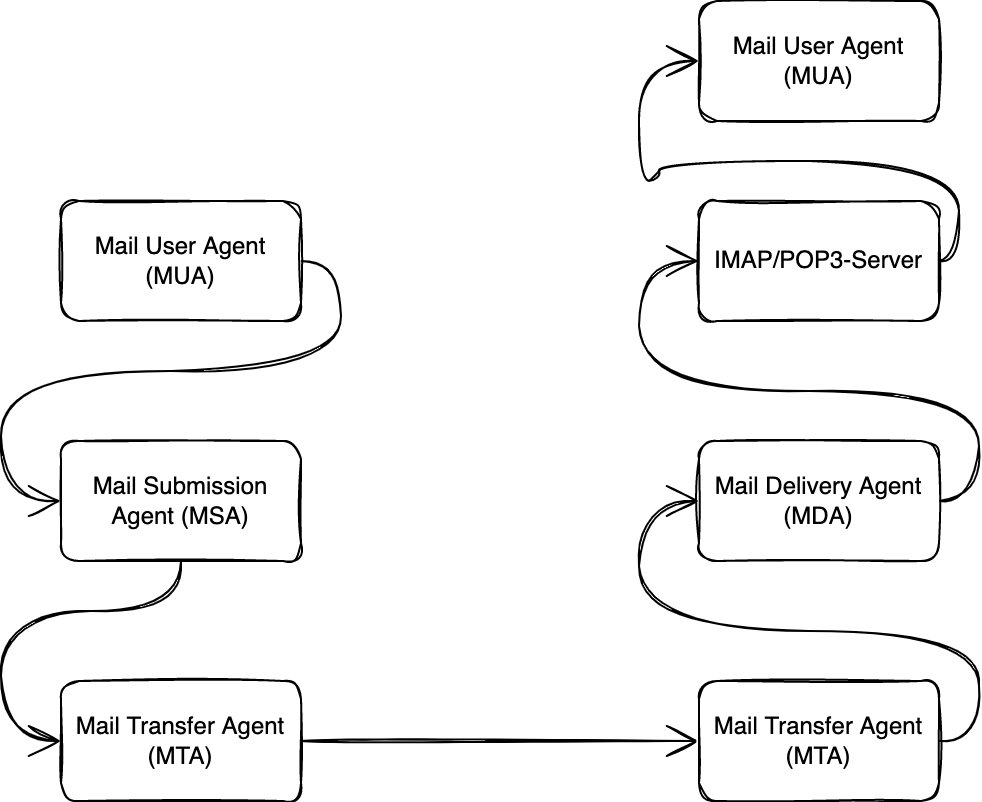
Wer sich näher mit dem E-Mail-System auseinandersetzt, wird feststellen, dass es den E-Mail-Server an sich nicht gibt, sondern es sich um eine Ansammlung von Systemen, Diensten oder Programmen handelt.
Diese tragen überwiegend Abkürzungen bestehend aus drei Buchstaben wie MUA, MSA, MTA und MDA. Ordnung lässt sich in die Begriffe bringen, wenn der Weg einer E-Mail vom Sender zum Empfänger verfolgt wird.
Grundsätzlich geht es darum, eine E-Mail bzw. eine Nachricht von einem Rechner zu einem anderen Rechner zu transferieren und sie dort in der Mailbox des entsprechenden Nutzers zu hinterlegen.
Eine E-Mail wird in einem E-Mail-Client geschrieben
Wird eine E-Mail geschrieben, so geschieht das in einem E-Mail-Client, welcher im Kontext der Architektur des E-Mail-Systems als Mail User Agent (MUA) bezeichnet wird.
Manchmal wird das Wort Mail in den entsprechenden Begrifflichkeiten durch Message ersetzt. Je nach RFC findet sich eine unterschiedliche Terminologie in dieser. Die Begriffe werden dabei synonym verwendet. So bezeichnen beispielhaft Mail User Agent und Message User Agent das Gleiche.
Nachdem die Mail fertig geschrieben und ein Empfänger eingetragen wurde, kann die E-Mail versandt werden. Je nach Konfiguration sind hier unterschiedliche Wege denkbar.
Vom MUA zum MSA
So kann die entsprechende Mail per Simple Mail Protocol (SMTP) an den sogenannten Mail Submission Agent (MSA) gesendet werden. Gewöhnlich geschieht dies über den Port 587. Die Idee hinter dem Mail Submission Agent ist, dass dieser die E-Mails vom Endbenutzer entgegennimmt und diese an den Mail Transfer Agent (MTA) weiterleitet.
Damit stellt er in der Theorie die Schnittstelle zwischen dem Mail User Agent und dem Mail Transfer Agent dar. Im Gegensatz zum Mail Transfer Agent darf der Mail Submission Agent die eingelieferte E-Mail noch bearbeiten. So kann das E-Mail-Format überprüft und gegebenenfalls repariert sowie unvollständige E-Mail-Adressen vervollständigt werden. Dies ist z. B. dann der Fall, wenn die Domain des Absenders nicht voll qualifiziert angegeben wurde.
In der Theorie kann ein Mail User Agent ergo das E-Mail-Programm E-Mails auch direkt an einen Mail Transfer Agent senden. Allerdings nimmt dieser keine der obigen Prüfungen vor.
Mail Transfer Agent
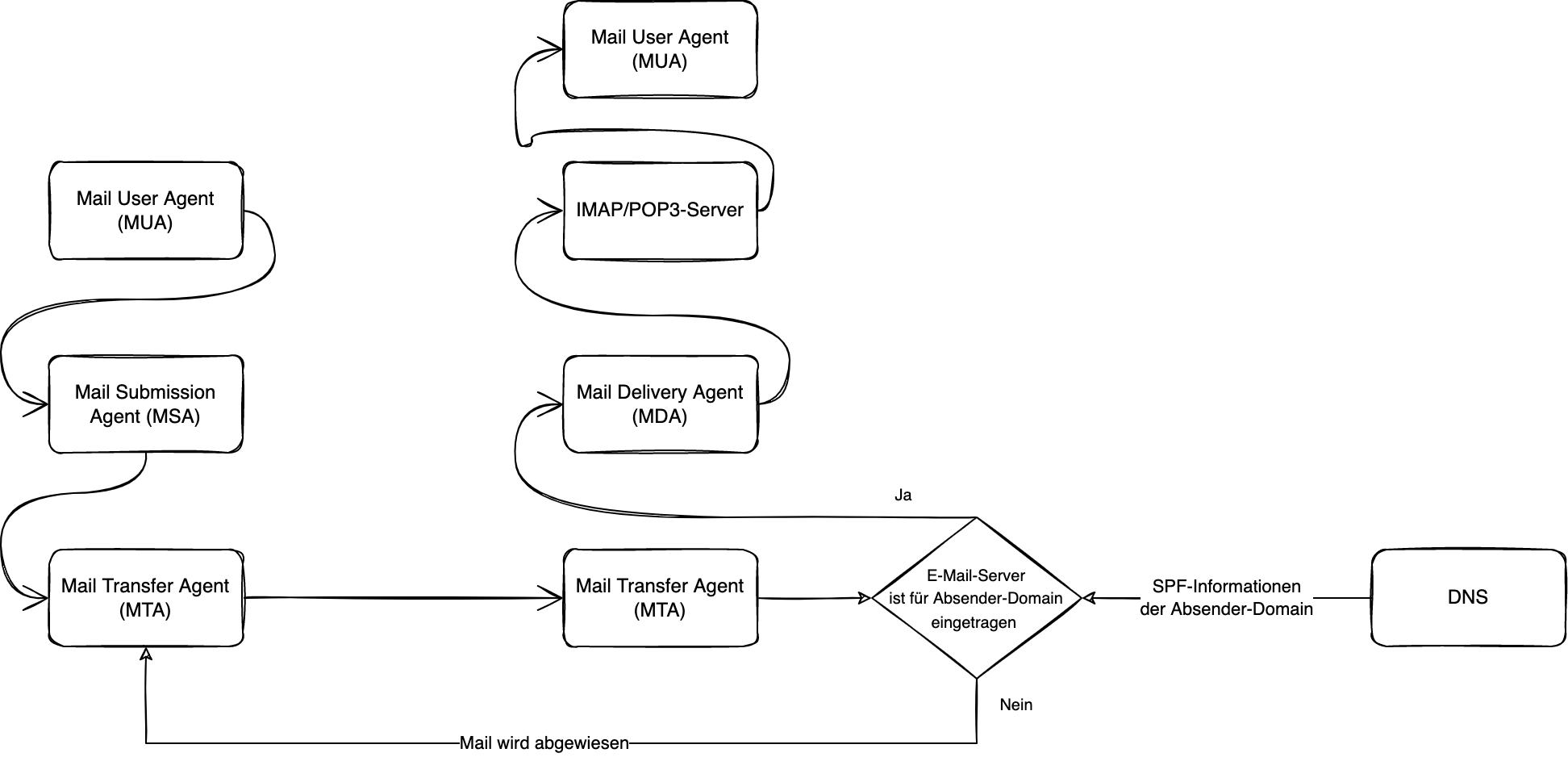
Nachdem die E-Mail an den Mail Transfer Agent weitergeleitet wurde, entscheidet dieser, was mit der E-Mail geschieht. Im Grunde ist der MTA ist dafür zuständig, die E-Mail zum Ziel zu transportieren und die Nachricht schlussendlich an den Mail Delivery Agent (MDA) zu übergeben.
Eine Möglichkeit wie eine E-Mail zum Empfänger übertragen wird
Der Mail Transfer Agent führt in seiner Konfiguration eine Liste von Domains bzw. Hosts, für die er lokal zuständig ist. E-Mails, welche zu diesen Domains führen, werden direkt über den Mail Delivery Agent zugestellt.
Der MTA verändert die Mail beim Transfer im Grundsatz nicht, außer dass einige Headerfelder wie Received oder Return-Path, welche laut der entsprechenden RFC benötigt werden, hinzugefügt werden.
In der Frühzeit des E-Mail-Systems waren die meisten MTAs als sogenannte offene Relays (Open Relays) konfiguriert. Das bedeutete, dass sie von beliebigen Clients entsprechende E-Mails entgegennahmen und weiterleiten.
Diese Funktionalität konnte z. B. von Systemen genutzt werden, welche nur sporadisch am Netz waren und somit ihre E-Mail an ein Relay weiterleiten konnten, welches sich anschließend um die Zustellung kümmerte.
Dies führte schlussendlich zum Problem des Spams, da diese Relays missbraucht wurden, um Empfänger mit unerwünschten Mails zu belästigen. Infolgedessen finden sich heutzutage nur noch wenige offene Relays im Internet. Meist handelt es sich dabei um Fehlkonfigurationen. Ein MTA sollte in der heutigen Zeit nur nach einer entsprechenden Authentifizierung E-Mails entgegennehmen.
Auf Linux-Systemen wird gerne Postfix für diesen Teil des E-Mail-Systems genutzt. Je nach Konfiguration kann Postfix hier sowohl als MSA als auch als MTA verwendet werden.
Von MTA zu MTA
Ist die Empfänger-Domain nicht im Einflussbereich des Absender-MTAs, so wird die Mail an den zuständigen MTA gesendet.
Hierzu wird die Domain per DNS aufgelöst und es werden die entsprechenden MX-Records ausgewertet. In diesen sind die für die Domain zuständigen Mail Transfer Agents hinterlegt.
Ein solcher MX-Record könnte wie folgt aussehen:
@ IN MX 10 mail.example.org.
Es können pro Domain mehrere MX-Records angelegt werden. Der MTA, versucht diese nun nacheinander, sortiert nach ihrer Priorität, zu erreichen und die entsprechende E-Mail auf dem MTA der Empfänger-Domain einzuliefern.
Kann die E-Mail nach einer gewissen Zeit nicht eingeliefert werden oder erhält der MTA eine entsprechende Fehlermeldung, wird der ursprüngliche Absender der E-Mail informiert, damit dieser darauf reagieren kann.
Ist die Einlieferung der E-Mail hingegen erfolgreich gewesen, leitet der MTA der Empfänger-Domain die Mail an den Mail Delivery Agent weiter. Der MDA hat die Aufgabe, die E-Mails an die jeweiligen Nutzerkonten bzw. Mailboxen weiterzuleiten.
Beispiele für einen solchen MDA ist die Software Dovecot unter Linux. Daneben bietet Dovecot die Funktionalität mittels der Protokolle IMAP und POP3 auf die Mails der jeweiligen Nutzer über ein Netzwerk zuzugreifen.
Über diesen Weg können die E-Mails von den Nutzern vom Server geladen und gelesen werden. Damit landen die E-Mails beim Nutzer im Mail User Agent, dem E-Mail-Programm auf dem Endgerät des Empfängers.
Mailboxen
Die Mailboxen der Nutzer können auf dem Server in unterschiedlichen Formaten gespeichert werden. Die bekanntesten und am häufigsten genutzten Formate sind Maildir und Mbox.
Beim Speicherverfahren Maildir wird jede Mail in einer separaten Datei, innerhalb der durch Maildir festgelegten Verzeichnisstruktur, abgelegt. Beim Verfahren Mbox hingegen, befinden sich die Mails in einer großen Datei und werden in dieser Datei nacheinander gespeichert.
Anatomie einer E-Mail
Damit ist geklärt, wie eine Mail ihren Weg vom Absender zum Empfänger findet. Doch wie sieht eine solche E-Mail eigentlich aus? Dies definiert die RFC 5322. Eine simple E-Mail, gemäß der RFC, könnte wie folgt aussehen:
Return-Path: <>
Delivered-To:
Received: by mail.example.org (Postfix, from userid 33)
id 81FC87EE09FD; Sat, 1 Jan 2022 00:19:10 +0100 (CET)
From: (Cron Daemon)
To:
Subject: Update cronjob successfully
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
X-Cron-Env:
X-Cron-Env:
X-Cron-Env:
X-Cron-Env:
Message-Id: <>
Date: Sat, 1 Jan 2022 00:19:10 +0100 (CET)
Update cronjob successfully executed.
Im Groben besteht eine E-Mail aus einem Header, in welchem sich unterschiedlichste Header-Felder befinden, welche Auskunft darüber geben, woher die E-Mail kam, wohin sie gehen soll und welche MTAs sie empfangen haben.
Daneben befinden sich weitere Informationen in der E-Mail, einige davon wie Subject, oder Date werden für die Anzeige der E-Mail im E-Mail-Programm herangezogen. Anschließend folgt der Message Body, in welchem die eigentliche Nachricht kodiert ist.
Da E-Mails an sich nur 7-Bit-ASCII-Zeichen unterstützen, müssen andere Zeichen und Typen von Inhalten wie Binärdateien erst umkodiert werden. Dazu wurden unter anderem die Multipurpose Internet Mail Extensions definiert, welche regeln, wie die entsprechenden Codierungen auszusehen haben.
Protokolle
Während sich bis zum Jahr 1980, innerhalb des ARPANET und dem dortigen E-Mail-System Protokolle wie SNDMSG und FTP mail hielten, haben sich im Laufe der Zeit einige Standardprotokolle herauskristallisiert, welche bis zur heutigen Zeit, mit einigen Erweiterungen genutzt werden.
Es handelt sich um die Protokolle SMTP, POP3 und IMAP. Während SMTP dem Transfer der E-Mail vom E-Mail-Client zum MSA bzw. dem Weiterversand von E-Mails von einem MTA zum nächsten dient, werden die Protokolle POP3 und IMAP zur Kommunikation des E-Mail-Servers mit dem E-Mail-Client genutzt.
SMTP
Das Simple Mail Transfer Protocol kurz SMTP nimmt beim E-Mail-System eine gehobene Stellung ein.
Während die E-Mails, welche auf dem eigenen E-Mail-Server empfangen wurden, theoretisch mit einem entsprechenden Shellzugriff direkt auf dem Server gelesen werden können, wird ein Protokoll benötigt, welches die E-Mails von einem Mail Transfer Agent zum nächsten MTA transportiert.
Hierfür wurde SMTP in der RFC 821 im August 1982 spezifiziert. Diese Version kam noch ohne Authentifizierung aus, sodass jedermann eine E-Mail bei einem MTA einliefern konnte, was im Laufe der Zeit zu einem Spam-Problem führte.
Deshalb wurde SMTP mit der RFC 1869 so erweitert, dass das Protokoll über einen Mechanismus verfügte, über welchen der Server den Client informieren konnte, über welche Service extensions der Server verfügt.
Dies ermöglichte es Authentifizierung und Verschlüsselungen über Erweiterungen wie STARTTLS durchzuführen und somit neben der Authentifizierung auch die Verschlüsselung zu gewährleisten.
Heutzutage sollten SMTP allerdings nicht mehr über STARTTLS, sondern direkt über TLS durchgeführt werden, da Technologien wie STARTTLS gegenüber Man-in-the-Middle-Angriffen anfällig sind.
POP3
Nachdem die E-Mails auf dem E-Mail-Server gelandet sind, wird ein Protokoll benötigt, um diese vonseiten des meist externen E-Mail-Clients wieder abzuholen.
Mit dem Post Office Protocol, welches in der aktuellen Version als POP3 abgekürzt wird, können die entsprechenden Mails vom E-Mail-Server heruntergeladen und vom Server gelöscht werden.
Mit POP4 sollte eine Weiterentwicklung des Protokolls verbunden sein, allerdings scheint diese seit 2003 nicht mehr gepflegt zu werden.
IMAP
Während sich POP3 gut dafür eignet, E-Mails vom Server zu holen, um die Postfächer im eigenen E-Mail-Client lokal zu verwalten, eignet sich das Internet Message Access Protocol kurz IMAP dazu, die entsprechenden E-Mails direkt auf dem Server zu verwalten.
IMAP unterstützt Funktionalitäten wie unterschiedliche Verzeichnisstrukturen oder die Benachrichtigung über neue E-Mails per Push-Verfahren.
Wie bei POP3 müssen auch bei IMAP zwei Protokolle unterstützt werden, da das Senden der Mails wiederum über SMTP erfolgt. Mit dem Simple Mail Access Protocol gab es Ansätze dies zu ändern, allerdings hat sich dieses bisher nicht durchgesetzt.
Ausfallsicherheit
Während wir heute daran gewöhnt sind, dass eine E-Mail meist innerhalb weniger Minuten beim Empfänger ankommt, war dies historisch gesehen nicht immer so. So konnte es schon einmal Tage dauern, bis eine entsprechende E-Mail schlussendlich beim Empfänger ankam.
Dies war unter anderem dadurch bedingt, dass nicht alle E-Mail-Server immer eine permanente Verbindung zum Internet hatten und es auch vorkommen konnte, dass Server für einige Zeit nicht verfügbar waren.
Das zeigt aber auch auf, wie resilient das E-Mail-System gestaltet wurde. Wenn ein MTA auf Empfängerseite nicht verfügbar ist, versuchen die sendenden MTAs die E-Mail später zuzustellen. Meist wird eine E-Mail erst nach einiger Zeit z. B. 48 Stunden als unzustellbar angesehen und der Absender entsprechend informiert.
Das bedeutet, wenn der eigene E-Mail-Server einmal ausfällt, so ist dies im ersten Moment kein dramatisches Ereignis, weil im Idealfall trotzdem alle E-Mails zugestellt werden.
Einen E-Mail-Server aufsetzen
Wer seine Domain bei einem Webhoster untergestellt hat, bekommt meist einen entsprechenden, vom Anbieter gewarteten E-Mail-Server dazu.
Interessanter wird es, wenn ein solcher E-Mail-Server selbst aufgesetzt werden soll. In einem solchen Fall muss ein MTA und MDA ausgewählt werden. Unter Linux ist eine beliebte Kombination für diese Funktionalitäten Postfix und Dovecot.
Grundsätzlich ist der Markt an Server-Anwendungen breit gestreut. Neben den Linux-Varianten und Servern wie Postfix und Dovecot existieren auch proprietäre Lösungen wie der Microsoft Exchange Server.
Nachdem die passende Lösung gewählt wurde, sollte diese für den jeweiligen Anwendungsfall konfiguriert oder entsprechend vorkonfektionierte Pakete genutzt werden.
Betrieb des Servers
Ist der E-Mail-Server aufgesetzt, fangen die eigentlichen Probleme an. Dies fängt damit an, dass es praktisch unmöglich ist, einen E-Mail-Server zu Hause zu betreiben. Die Einlieferung von E-Mails von Servern, welche in dynamischen DSL-IP-Adressbereichen unterwegs sind, wird von den meisten Betreibern von E-Mail-Servern unterbunden, meist um Spam zu verhindern.
Damit bleibt als Lösung der Betrieb eines Servers in einem Rechenzentrum, mit entsprechend fixer IP-Adressen oder entsprechenden Tarifen im gewerblichen Umfeld.
Ist der E-Mail-Server eingerichtet, der MX-Record korrekt gesetzt und sind die entsprechenden Nutzer angelegt, kann der Nutzer in der Theorie Mails senden und empfangen.
Neben dem Setzen des MX-Records ist es mittlerweile auch hilfreich, die DNS-Records für die automatische Erkennung durch E-Mail-Clients zu konfigurieren. Geregelt wird das Verfahren in der RFC 6186. Dies ermöglicht es den Clients, die Konfiguration für den E-Mail-Server schnell und unkompliziert vorzunehmen.
In der Praxis ist das erfolgreiche Senden von E-Mails eine kleine Herausforderung. So müssen entsprechende PTR-Records für die Auflösung der IP-Adresse zur entsprechenden Domain hinterlegt werden.
Andere E-Mail-Server überprüfen, ob der Name der IP-Adresse (Reverse DNS) zum eigenen E-Mail-Server passt. Wird etwa die IP-Adresse 192.168.10.1 genutzt und deren Reverse DNS-Name lautet mail.example.com, so muss auch der Hostname mail.example.com in der Konfiguration des Mailservers dementsprechend konfiguriert sein.
Sendet der Server die E-Mails auch per IPv6, so muss überprüft werden, dass ein entsprechender PTR-Record für die Adresse gesetzt ist, ansonsten kann es zu solchen Meldungen im E-Mail-Verkehr kommen:
host mail.example.com[2001:db8:a0b:abf0::1]
said: 550-Inconsistent/Missing DNS PTR record (RFC 1912 2.1)
(example.org) 550 [2001:db8:a0b:12f0::1]:34865 (in reply to RCPT TO command)
Selbst wenn der Eintrag zur Auflösung der IP-Adresse (Reverse DNS) korrekt gesetzt ist, kann es passieren, dass bei der Nutzung von IPv6 diese Meldung erscheint. Hintergrund ist meist, dass der entsprechende Server ein IPv6-Subnetz erhält und z. B. Postfix dann eine beliebige Adresse aus diesem Subnetz zum Senden benutzt. Hier bietet es sich an, die entsprechende Interface-Adresse für den Server fest zu definieren.
E-Mails sinnvoll zuzustellen ist insbesondere bei größeren Anbietern wie Gmail problematisch, weil eine Reihe von Voraussetzungen erfüllt sein müssen.
Hier ist es neben den normalen Maßnahmen wie dem korrekten Setzen der DNS-Einträge (Forward und Reverse), meist auch notwendig Verfahren wie SPF, DKIM und DMARC zu implementieren, welche die Komplexität für den entsprechenden E-Mail-Server steigen lassen.
SPF
Mit dem Sender Policy Framework (SPF), wurde ein Verfahren geschaffen, welches sicherstellen sollte, dass E-Mails mit bestimmten Absendern nur von berechtigten E-Mail-Server versendet werden können.
SPF wird auf der Empfängerseite geprüft
Dazu wird bei SPF im DNS eine entsprechende Konfiguration hinterlegt, welche festlegt, welche Server berechtigt sind, für die Absender-Domain E-Mails zu versenden. Die entsprechend notwendigen DNS-Records können über unterschiedlichste Tools erzeugt werden, z. B. über die Webseite spf-record.de.
DKIM
Bei DomainKeys Identified Mail (DKIM) wird die jeweilige E-Mail um eine Signatur ergänzt, über welche der empfangende MTA feststellen kann, ob die E-Mail wirklich vom MTA der Absender-Domain stammt.
Dazu wird über einen im DNS hinterlegten öffentlichen Schlüssel für die Absender-Domain überprüft, ob die Signatur in der E-Mail valide ist.
DMARC
Aufbauend auf SPF und DKIM existiert mit Domain-based Message Authentication, Reporting and Conformance (DMARC) eine Spezifikation, mit welcher festgelegt wird, wie mit entsprechenden E-Mails, welche durch die SPF- und DKIM-Prüfung durchgefallen sind, reagiert werden soll.
Auch hier werden DNS-Records der Absender-Domain genutzt, um entsprechende Informationen für die Richtlinie zu hinterlegen.
Eine Besonderheit bei DMARC ist, dass der im DNS-Record hinterlegte DMARC-Admin über fehlgeschlagene DMARC-Prüfungen informiert werden kann und somit erfährt, dass die entsprechende Domain für Spam missbraucht wird.
Klein anfangen
Bei kleinen E-Mail-Servern, mit geringen Volumen an E-Mails, reicht es meist aus SPF zu aktivieren. Spätestens bei der Nutzung von IPv6 müssen einige Maßnahmen wie SPF eingerichtet werden, um E-Mails sicher versenden können. Andernfalls kann es vorkommen, dass solche E-Mails abgelehnt werden.
Auch ist es nicht ratsam sofort mit großen E-Mail-Volumina auf die Server von Google zu feuern, hier wird ein langsames Ansteigen der Last über einen längeren Zeitraum bevorzugt, um nicht von eventuellen Anti-Spam-Maßnahmen betroffen zu sein.
Dann gibt es auch noch speziellere Fälle, wie bei T-Online, in deren Dokumentation sich folgender Abschnitt findet:
Insbesondere empfehlen wir, den Hostnamen so zu wählen, dass seine Nutzung als Mailserver für Außenstehende erkennbar ist (z. B. mail.example.com), und sicherzustellen, dass die Domain zu einer Website führt, die eine Anbieterkennzeichnung mit sämtlichen Kontaktdaten beinhaltet.
Bei solchen Regeln ist es damit praktisch unmöglich einen reinen E-Mail-Server zu konfigurieren, da zumindest ein Webserver mit dem Impressum vorhanden sein muss. Ansonsten erhält der Betreiber des E-Mail-Servers entsprechende Meldungen im Log:
Dec 6 19:07:26 host42 postfix/smtp[3017216]: ED2DA7EE0104: to=<>, relay=mx00.t-online.de[194.25.134.8]:25, delay=0.33, delays=0.16/0.02/0.14/0, dsn=4.0.0, status=deferred (host mx00.t-online.de[194.25.134.8] refused to talk to me: 554 IP=192.168.9.1 - A problem occurred. (Ask your postmaster for help or to contact to clarify.))
Spam, Spam, Spam
Monty Python schenkte uns nicht nur Silly Walks, sondern auch Spam. Der berühmte Sketch führte schlussendlich dazu, dass wir ungewollte E-Mails als Spam bezeichnen. Das Problem selbst wurde relativ früh erkannt und in die RFC 706, welche den schönen Titel On the Junk Mail Problem trägt, gegossen.
Spam ist in unserer heutigen Zeit allgegenwärtig und wird leider massenhaft versendet. Ohne zumindest minimale Maßnahmen, um Spam zu unterdrücken, sollte ein E-Mail-Server nicht betrieben werden. Hier muss auch immer die Abwägung getroffen werden zwischen der Filterung unerwünschter Mails und dem Abweisen von legitimen Mails, welche fälschlicherweise als Spam erkannt worden sind.
Greylisting
Eine der einfachsten und effektivsten Maßnahmen gegen Spam ist das sogenannte Greylisting. Beim Greylisting wird eine Mail von einem unbekannten Absender im ersten Schritt nicht angenommen und stattdessen ein technischer Fehler kommuniziert.
Standardkonforme E-Mail-Server senden eine solch zurückgewiesene E-Mail nach einer Wartezeit noch einmal. Ist die eingestellte Greylisting-Zeit abgelaufen, wird die E-Mail anschließend angenommen.
Bei einer Spamnachricht, welche an viele Millionen Empfänger gesendet wird, findet dieses abermaliges Versenden der E-Mail in den meisten Fällen nicht statt. Damit kann mittels Greylisting ein Großteil von Spam-E-Mails gefahrlos aussortiert werden.
Problematisch wird Greylisting dann, wenn z. B. Zwei-Faktor-Authentifizierungscodes empfangen werden sollen, welche nur eine gewisse Zeit gültig sind und durch die Verzögerung beim Greylisting ihre Gültigkeit verlieren.
Weitere Filter
Neben dem Greylisting, gibt es eine Reihe von kleineren Überprüfungen, welche vorgenommen werden können, bevor eine E-Mail angenommen wird. Je nach eingesetzter Software können diese Direkten aktiviert werden und somit E-Mails, welche den Direktiven widersprechen, abzuweisen.
So existiert unter Postfix z. B. die Direktive reject_unknown_sender_domain. Diese Direktive weist E-Mails zurück, welche Adressen nutzen, für welche kein MX- oder A-Record vergeben wurde. Dies ist dann der Fall, wenn entsprechender Spam von Adressen versendet wird, welche in Wirklichkeit nicht existieren oder von Servern kommen, welche nicht als E-Mail-Server konfiguriert sind.
In einer Postfix-Konfiguration werden diese Direktiven nacheinander abgearbeitet:
Durch diese Direktiven, welche gewisse Prüfungen auf Standardkonformität durchführen, wird idealerweise ein Großteil des Spams abgewiesen.
DNS-based blocklists
Daneben sind zur Bekämpfung von Spam auch DNS basierte Blocklisten in Gebrauch. Bei einer solchen Liste wird die IP-Adresse des Senders per DNS gegenüber dem Anbieter der Blockliste aufgelöst. Über den Rückgabecode kann damit ermittelt werden, ob das entsprechende sendende System als Spam eingestuft wird und die entsprechende Mail zurückgewiesen werden.
Auf dem Markt sind einige größere Listen verfügbar, z. B. von Spamhaus. Für den eigenen E-Mail-Server, sollte hier eine sinnvolle Abwägung getroffen werden, welche Liste(n) zur Prüfung hinterlegt werden sollen, da diese Listen im schlimmsten Fall darüber entscheiden ob eine E-Mail abgewiesen wird.
E-Mail-Server goes Cloud
Wer diesen Aufwand nicht treiben möchte, kann seine eigene Domain mit einem E-Mail-Server aus der Cloud versorgen. Unter anderem Google unterstützt dies.
So kann mit Google Workspace eine eigene Domain für die Nutzung von Gmail eingerichtet werden. Damit wird das E-Mail-System von Google benutzt und in der Theorie hält sich der Wartungs- und Verwaltungsaufwand in Grenzen.
Problematisch ist allerdings, dass sich in eine entsprechende Abhängigkeit begeben wird und auch datenschutzrechtliche Aspekte eine Rolle spielen, was z. B. den Transfer von Daten in das Nicht-EU-Ausland angeht.
Technisch realisiert wird dies so, dass die entsprechenden MX-Records für die eigene Domain auf die E-Mail-Server von Google zeigen und somit die offiziellen E-Mail-Server für die Domain sind.
Rechtliche und weitere Anforderungen
Neben den technischen Anforderungen kommen je nach Größe des E-Mail-Servers noch weitere rechtliche Anforderungen hinzu. So müssen ab einer bestimmten Nutzeranzahl unter Umständen Abhörschnittstellen eingerichtet werden, was sich aus der Telekommunikations-Überwachungsverordnung ergibt.
Auch ist es sinnvoll bestimmte E-Mail-Adressen, wie sie in der RFC 2142 definiert werden, bereitzuhalten. Daneben sollten auch Prozesse eingerichtet werden, um Anfragen an diese E-Mail-Adressen, wie. z. B. Abuse-Adressen, zu bearbeiten.
Resümee
Auch wenn der Betrieb eines E-Mail-Servers mit gewissen Anforderungen verbunden ist, bietet er durchaus Vorteile. So können private Daten auf der eigenen Infrastruktur gehalten und verarbeitet werden und es löst Abhängigkeiten von großen Infrastrukturanbietern.
Außerdem trägt ein solcher Server zum Grundgedanken des E-Mail-Systems bei, dass es sich um ein dezentrales System handelt.
Wer einen E-Mail-Server für private Zwecken einrichten möchte, kann sich z. B. der Top-Level-Domain .email annähern, mit welcher sich angenehm kurze E-Mail-Adressen für die eigene Familie (z. B. ) realisieren lassen.
Auch wenn heutzutage die firmeninterne Kommunikation in vielen Fällen über andere Systeme wie Slack oder Teams läuft und wir in persönlichen Kontakten meist auf Messenger à la WhatsApp oder Signal setzen, wird E-Mail, auch wenn sie ein in die Jahre gekommenes Medium ist, uns in der Zukunft begleiten.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.
Reine VDSL-Modems sind eine aussterbende Art. Trotzdem gibt es noch hier und da entsprechende Modems, unter anderem im SFP-Standard. Diese SFP können genutzt werden z.B. einen MikroTik-Router mit einer entsprechenden Funktionalität nachzurüsten. In diesem Fall sollte es die Möglichkeit sein VDSL über das Interface sfp1 zu nutzen. Die erhältlichen SFP-Module für VDSL sind meist baugleich mit dem VersaTec VX-160CE VDSL2-SFP.
Ein VDSL Modem als SFP
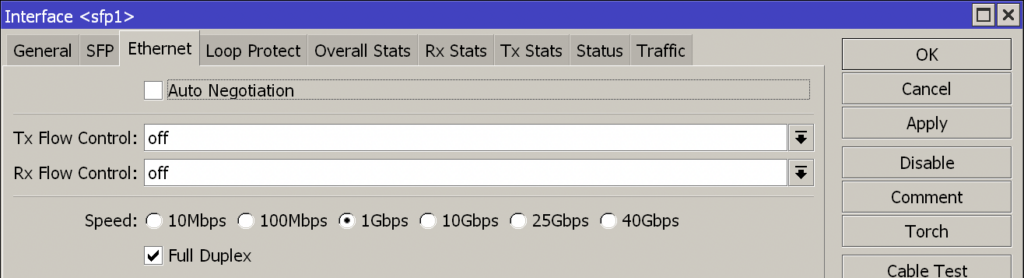
Nachdem das Modul im MikroTik-Router installiert wurde, ist das Interface sfp1 aktiv. Die Auto Negotiation muss für das Modul deaktiviert werden. Andernfalls schlägt später die Neuverbindung nach einem Neustart fehl, da das Modul nicht mehr erkannt wird.
Die Auto Negotiation muss für das Modul deaktiviert werden
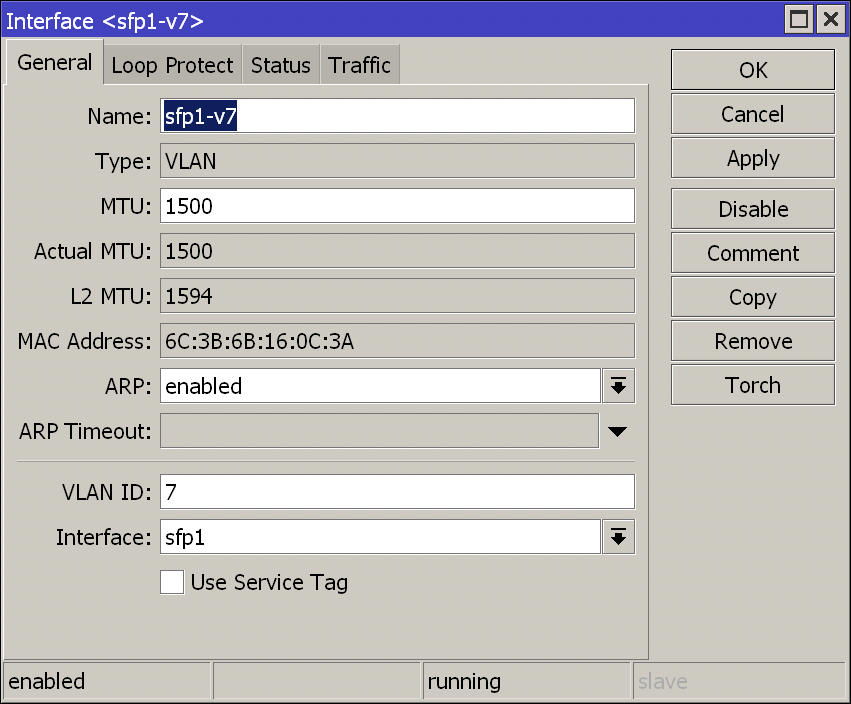
Eingestellt wird das Modul hierbei auf 1Gbps bei Full Duplex. Im nächsten Schritt muss ein VLAN für die Schnittstelle angelegt werden. Hintergrund ist, das erwartet wird das die Daten sich im VLAN mit einer bestimmten ID befinden. Bei der Deutschen Telekom ist dies die 7, bei anderen Anbietern kann dies teilweise abweichen. So z.B. bei 1&1; dort wird je nach genutzter Infrastruktur die 7 oder die 8 genutzt.
Das VLAN-Interface
Beim anzulegenden VLAN-Interface ist darauf zu achten, das kein Service-Tag gesetzt wird. Nachdem das Interface sfp1 und das entsprechende VLAN-Interface konfiguriert sind, kann im nächsten Schritt die PPPoE-Verbindung eingerichtet werden. Dazu wird unter PPP ein neues PPPoE-Interface eingerichtet. Das zu nutzende Interface für das PPPoE-Interface ist hierbei das VLAN-Interface, im Beispiel sfp1-v7.
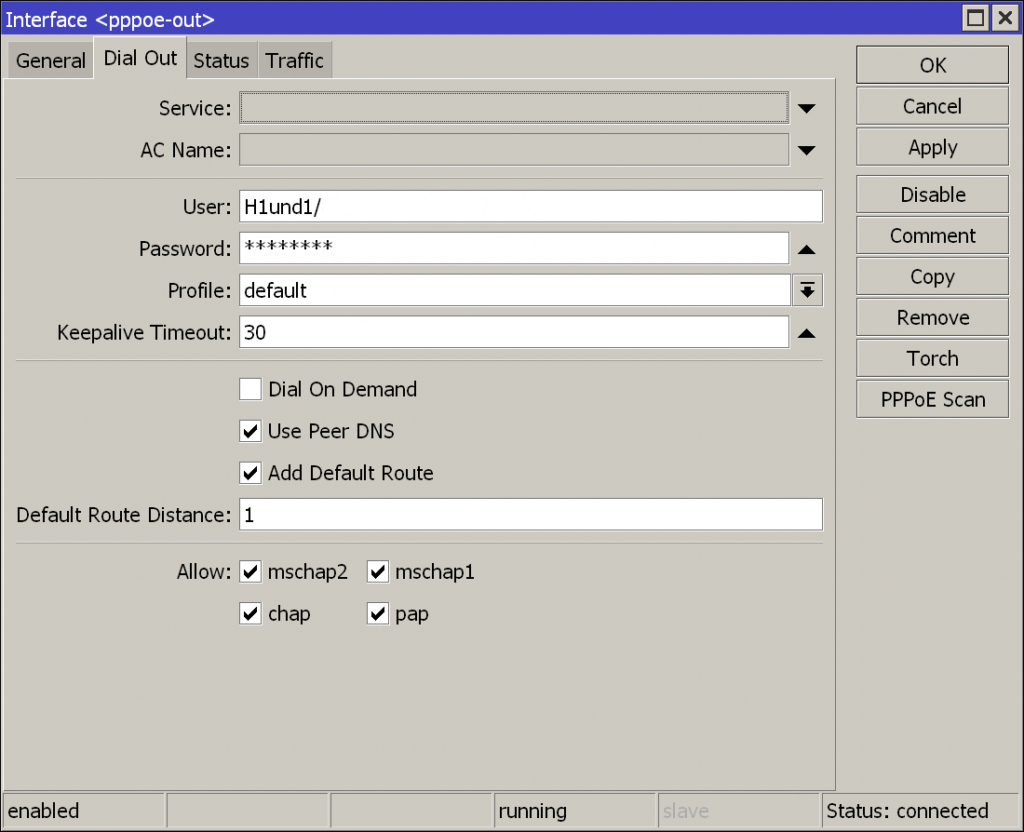
Das PPPoE Interface
Im Tab Dail Out müssen die Zugangsdaten von Internetanbieter eingetragen werden. Im Falle einiger Anbieter wie z.B. 1&1 kann es notwendig sein vor dem eigentlichen Nutzernamen ein H zu setzen, da dieser sonst nicht akzeptiert wird und der Authentifizierungsvorgang fehlschlägt. Damit ist das SFP-Modul eingerichtet und die Verbindung kann genutzt werden. Je nach genutztem Modell aus der MikroTik-Palette kann es sein, das nicht die volle Bandbreite genutzt werden kann. Das Problem ist in diesen Fällen meist die CPU-Auslastung durch die PPPoE-Verbindung da diese komplett durch die CPU verarbeitet werden muss. In einem solchen Fall kann zu den Cloud Core-Routern von MikroTik gegriffen werden.
Nachdem die Verbindung hergestellt war, stellte ich im Laufe eines längeren Testes allerdings fest, dass der PPPoE-Link in regelmäßigen Abständen nach 30 – 80 Minuten zusammenbrach und somit leider kein stabiles Internet lieferte. Vermutlich handelt es sich um ein Problem des SFP-Moduls im Zusammenhang mit dem DSLAM.
Eine domänenspezifische Sprache, kurz DSL, ist eine auf ein bestimmtes Problemfeld abgestimmte Sprache. Mit dem freien REST Assured existiert eine solche Sprache für den effektiven Test von REST-Schnittstellen. Genutzt wird REST Assured hauptsächlich unter Java und Groovy. Eine einfache Überprüfung des Statuscodes einer API-Anfrage würde in REST Assured wie folgt aussehen:
Daneben sind auch komplexe Tests wie die Auswertung von zurückgegebenen JSON-Strukturen und Daten, sowie die Verknüpfung unterschiedlicher Bedingungen ohne Probleme zu implementieren. Eine große Übersicht über die Möglichkeiten von REST Assured bietet der Usage-Guide des Projektes.
rest-assured.io
Die Projektseite von REST Assured ist unter rest-assured.io zu finden. Der unter der Apache Lizenz (Version 2.0) lizenzierte Quellcode kann auf GitHub gefunden werden.