Die Entwicklung von Software zeichnet sich in der heutigen Welt oft dadurch aus, dass sie unter Mitwirkung unterschiedlichster Entwickler bewerkstelligt wird. Im Rahmen einer solchen Entwicklung kommt es darauf an, bestimmte Standards und Best Practices einzuhalten.
Neben dem passenden Workflow kommen hier Coding Conventions zum Tragen und bilden einen wichtigen Baustein um Quelltext effizienter, lesbarer und zuverlässiger zu gestalten.
Was sind Coding Convention?
Eine Coding Convention definiert sich über bestimmte Stilregeln und Best Practices, bezogen auf eine Programmiersprache. Innerhalb der Konvention werden viele Aspekte der Programmiersprache und ihrer sprachlichen Elemente behandelt. Dies fängt bei Regeln zur Formatierung an, führt sich fort mit der Benamung von Variablen und anderen Strukturen und erstreckt sich auch auf andere Bereiche, wie Reihenfolgen und Zeilenlängen.
Warum werden sie benötigt?
Nun kann sich natürlich die Frage gestellt werden, warum eigentlich Coding Conventions benötigt werden?
Neben offensichtlichen Gründen, dass sie vielleicht eine Anforderung des Kunden sind, gibt es auch andere Gründe für diese Konventionen. So werden die meisten Projekte nicht von einer einzelnen Person betreut und für die Entwickler eines Produktes ist es einfacher, wenn der Quelltext nach identischen Standards entwickelt wurde. Dies ermöglicht eine schnellere Einarbeitung und hilft auch bei anderen Dingen, wie der Verminderung von Merge-Konflikten bei der Arbeit mit Versionskontrollsystemen.
Damit tragen diese Konventionen dazu bei, die Zusammenarbeit zwischen Entwicklern zu erleichtern, indem sie eine einheitliche und konsistente Basis schaffen.
Eine Welt ohne Coding Conventions
Natürlich können Programme auch ohne Coding Conventions geschrieben werden. Dies kann zu interessanten Programmen führen:
#include... yeet Yeet Yeeet yeeeT Yeeeet yEet yEEt yeEt yyeet yeett yeetT yeeT yet yeetT yeeeeT
Bei diesem Programm stellen sich bei der Betrachtung mehrere Fragen. In welcher Sprache ist es geschrieben? Ist es überhaupt lauffähig? Und was ist der eigentliche Zweck des Quelltextes?
In diesem Beispiel wurde das C-Programm so gestaltet, dass es möglichst unlesbar ist, indem mit entsprechenden Definitionen gearbeitet wurde, welche anschließend im Quelltext genutzt werden.
#define yeet int
#define Yeet main
#define yEet std
#define yeEt cout
#define yeeT return
#define Yeeet (
#define yeeeT )
#define Yeeeet {
#define yeeeeT }
#define yyeet <<
#define yet 0
#define yeett "Yeet!"
#define yeetT ;
#define yEEt ::
Es zeigt auf, dass ohne einheitliche Coding Conventions im besten Fall Chaos droht. Auf die Spitze treibt das auch der International Obfuscated C Code Contest, bei welchem es darum geht, Quelltext möglichst so zu verschleiern, dass nur schwer zu erraten ist, welche Funktion dieser am Ende in sich trägt.
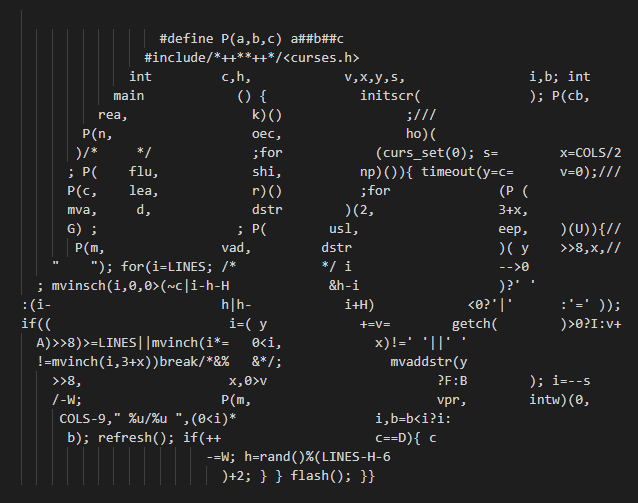
Eine Implementation des zcat-Kommandos
In diesem Beispiel wird der Befehl zcat zur Darstellung mittels gz-komprimierter Daten implementiert. Auch ohne solche Extrembeispiele würde in einer Welt ohne Coding Conventions eine Menge an inkonsistentem Code entstehen:
int counterServer = 1 ; int counterClient = 2 ; int counterDevice = 3 ; int test1 = 4 ;
Natürlich kann ein Quelltext so formatiert werden, aber in den meisten Fällen erschwert dies die Lesbarkeit des Quelltextes enorm. Auch die Nutzung von Whitespaces und falscher Einrückung kann zu Problemen führen:
if (system==true) {
doSomething() ;
doFoobar ();
}
Auch Richtlinien über Komplexität sind ein wichtiger Bestandteil, solcher Konventionen. Gegeben sei folgendes Programm:
#includemain(){ int x=0,y[14],*z=&y;*(z++)=0x48;*(z++)=y[x++]+0x1D; *(z++)=y[x++]+0x07;*(z++)=y[x++]+0x00;*(z++)=y[x++]+0x03; *(z++)=y[x++]-0x43;*(z++)=y[x++]-0x0C;*(z++)=y[x++]+0x57; *(z++)=y[x++]-0x08;*(z++)=y[x++]+0x03;*(z++)=y[x++]-0x06; *(z++)=y[x++]-0x08;*(z++)=y[x++]-0x43;*(z++)=y[x]-0x21; x=*(--z);while(y[x]!=NULL)putchar(y[x++]); }
Bei diesem handelt es sich um ein einfaches Hello World-Programm, aber das Verständnis wird durch die Umsetzung, genauer gesagt dessen unnötige Komplexität, sehr erschwert.
Auch wenn sich auf Einrückungen geeinigt wird, ist dies nicht immer sinnvoll:
function f() {
doThings();
doMoreThings();
}
Bei diesem Beispiel wird eine Einrückung genutzt, welche ungebräuchlich ist und bei den meisten Entwicklern wahrscheinlich auf Ablehnung stoßen wird und nicht dazu führt, dass der Quelltext übersichtlicher wird.
Die Benamung von Elementen ist ein wichtiger Teil von Coding Conventions:
void doSomeTHING() {
int test1 = 1;
int TEST2 = 2;
int teST3 = 3;
}
void DoSomething() {
int tEST4 = 4;
}
Wird bei dieser nicht auf Konsistenz geachtet, trägt dies nicht zum besseren Verständnis bei. Auch Kommentare, bzw. das Schreiben derselben sind eine Aufgabe, bei der sorgfältig gearbeitet werden sollte:
try {
...
} catch(Exception e) {
// Gotta Catch 'Em All
}
Natürlich ist Humor im echten Leben wichtig, aber in einem Quelltext sollte er nichts zu suchen haben. Stattdessen sollte sich hier auf die Fachlichkeit bezogen werden.
Auch die Nutzung unüblicher Vorgehensweisen bzw. das Verstecken bestimmter Operationen erschwert das Verständnis eines Quelltextes:
int main() {
String helloWorld = "Hello World!";
cout << helloWorld << endl;
String hello = (helloWorld, 5);
cout << hello << endl;
system("pause");
return 0;
}
Ohne weitere Informationen ist es relativ schwer herauszufinden, was in diesem Beispiel passiert. Hier werden die ersten fünf Stellen der Zeichenkette Hello World! zurückgegeben. In diesem Fall geschieht dies über die Überladung des Komma-Operators:
using namespace std;
#define String string
String operator,(String lhs, int rhs) {
lhs.erase(lhs.begin() + rhs, lhs.end());
return lhs;
}
Auch eine schlechte Benennung und ein Sprachmischmasch kann das Verständnis des Quelltextes erschweren:
#includegibHalloWeltAus() { // use cout for output cout << "Hello World!" << endl; // Rückgabereturn return 0; }
Ziele von Coding Conventions
Wenn sich diese Beispiele aus der Welt ohne Coding Conventions angeschaut werden, können aus diesen einige Ziele für entsprechende Konventionen abgeleitet werden.
Es geht darum, dass Coding Conventions bewährte Praktiken abbilden und für einen lesbaren und verständlichen Quelltext sorgen. Sie sollen die Zusammenarbeit im Team erleichtern und eine gewisse Einheitlichkeit herstellen.
Daneben sind Coding Conventions und das Konzept von Clean Code miteinander verbunden. Clean Code ist ein Konzept, das sich auf die Softwareproduktion und das Programmierdesign bezieht. Es legt fest, dass Quelltext so geschrieben werden sollte, dass er einfach zu lesen, zu verstehen und zu warten ist. Die Einhaltung von Coding Conventions kann dazu beitragen, diese Kriterien einzuhalten.
Elemente von Coding Conventions
Doch woraus genau bestehen Coding Conventions im Einzelnen? Im ersten Schritt sollte sich bewusst gemacht werden, dass sich solche Konventionen von Sprache zu Sprache unterscheiden. Auch wenn sich im Laufe der Zeit einige Standards herauskristallisiert haben, können diese nicht immer eins zu eins auf die eigenen Anforderungen angewendet werden.

Unterschiedliche Elemente von Coding Conventions
Im Einzelnen setzen sich Coding Conventions aus Elementen zusammen, welche im folgenden genauer besprochen werden sollen.
Benamung
Ein essenzielles Element ist die Benamung innerhalb eines Entwicklungsprojektes. Dies fängt bei Dateinamen und Verzeichnissen an, zieht sich hin zu Bezeichnern, wie den Namen von Variablen, Klassen und vielen anderen Elementen.
Grundsätzlich sollte bei der Benamung von Elementen immer so viel wie nötig und so wenig wie möglich benannt werden.
Dateinamen
Da Coding Conventions sich von Sprache zu Sprache unterscheiden, existieren bereits Unterschiede auf Ebene der Dateinamen. Während Dateien von C-Programmen meist in Kleinschreibung benannt werden:
main.c tilerenderer.c
sieht dies bei Java-Applikationen anders aus:
Main.java TileRenderer.java
Neben den Dateinamen bezieht sich dies auch auf die Benamung und Struktur von Verzeichnissen. In C würde dies wie folgt aussehen:
src engine renderer utils
während in Java meist die Struktur des Packages abgebildet wird. Bei dem Package com.example.transformer.html würde die entsprechende Verzeichnisstruktur wie folgt aussehen:
src
main
java
com
example
transformer
html
markdown
test
Eine weitere Eigenart von Java ist, dass die Namen der Packages eine Domain-Struktur abbilden und z. B. mit der Domain der Firma beginnen.
Neben den Coding Conventions für die jeweilige Sprache gehen bei der Strukturierung des Projektes auch noch andere Aspekte ein. Wird z. B. mit dem Build-Werkzeug Maven gearbeitet, so gilt dort Konvention vor Konfiguration.
Bei Maven bedeutet dies, dass eine Reihe von Standardregeln existieren, die vom Benutzer des Werkzeuges befolgt werden müssen, um ein Projekt erfolgreich zu erstellen. So muss ein Projekt in einer bestimmten Struktur organisiert sein, damit Maven es erfolgreich verarbeiten kann. Diese Standards erleichtern es, ein Projekt mit Maven zu erstellen, da der Benutzer nicht jeden einzelnen Schritt konfigurieren muss.
Sprechende Namen
Auch bei der Benamung sollten gewissen Standards eingehalten werden:
int a = getSum();
In diesem Fall wird eine Methode mit dem Namen getSum aufgerufen und das Ergebnis in der Variable a gespeichert. Hier sollte mit sprechenden Namen gearbeitet werden. Solche Namen zeichnen sich dadurch aus, dass sie beim Lesen bereits Aufschluss über ihre Fachlichkeit und deren Bedeutung geben:
int sum = getSum();
Damit wird klar, dass sich in der Variable sum eine entsprechende Summe befindet. Theoretisch kann die Benennung natürlich noch weiter spezifiziert werden:
int sumArticles = getSum();
Unter Umständen können Namen hierbei etwas länger werden, aber dafür wird Klarheit gewonnen. Diese Art der Benamung sollte nicht nur für Variablen, sondern generell für Bezeichner, wie Klassennamen gelten.
Allerdings keine Regel ohne Ausnahme, z. B. bei Exceptions unter Java:
try {
// Try some funky stuff
} catch(Exception e) {
// Handle exception
}
Dort hat es sich eingebürgert, einer Exception den Namen e bzw. ex zu geben. Sind solche Konventionen vorhanden und weitverbreitet, sollten diese entsprechend eingehalten werden. Auch hier dient das Einhalten dieser Regeln dazu, die Lesbarkeit und Wartbarkeit des Quelltextes zu erhöhen.
Verbotene Bezeichner
Es gibt eine Reihe von Bezeichnungen, welche in der Theorie, je nach verwendeter Sprache, verwendet werden können, es aber nicht sollten.
So ist es in Sprachen wie C# möglich, mit einem vorgestellten At-Zeichen Schlüsselwörter der Sprache als Bezeichner verwenden zu können. Um Verwirrung und darauf aufbauende Probleme zu vermeiden, sollte dies unterlassen werden.
Andere Bezeichner, wie handle, sollten nur in einem eng begrenzten Kontext oder einer entsprechenden Fachlichkeit benutzt werden.
Auch die Nutzung von Variablen mit dem Namen temp oder tmp sollte unterlassen werden, da meist eine entsprechend sinnvollere fachliche Benamung möglich ist.
Schleifen und Benamung
Wie bei Exceptions haben sich auch bei Schleifen bestimmte Konventionen zur Benamung eingebürgert, an welche sich gehalten werden sollte:
for(int i = 0; i < 10; i++) {
for(int j = 0; j < 10; j++) {
// Do stuff
}
}
So wird die Zählervariable bei Schleifen mehrheitlich mit dem Namen i benannt und wenn in der Schleife weitere Schleifen geschachtelt werden, so werden diese fortlaufend mit j, k und so weiter benannt.
Aber auch hier kann in Ausnahmen davon abgewichen werden. Ein Beispiel hierfür wäre z. B. die Verarbeitung eines Bildes:
for(int y = 0; y < image.height; y++) {
for(int x = 0; x < image.width; x++) {
// Do image stuff
}
}
Hier wird sich auf die x- und y-Achse des Bildes bezogen und durch die entsprechende Benamung kann sinnvoll mit diesen in der eigentlichen Logik der Schleife gearbeitet werden.
Kamele, Dromedare und Schlangen
Bezeichner können wie bei obigem Beispiel einfache Namen bestehend aus einem Wort sein, bestehen aber in vielen Fällen aus mehreren Wörtern.

Unterschiedlichste Schreibvarianten bei zusammengesetzten Bezeichnern
Um diese sinnvoll miteinander zu verbinden werden je nach Sprache unterschiedliche Varianten von Binnenmajuskeln benutzt, welche je nach Verwendung treffende Namen wie CamelCase und Ähnliche tragen. Diese Schreibweise sorgt letztlich für eine bessere Lesbarkeit, da sie einzelne Wörter sinnvoll voneinander abgrenzt.
Binde- und Unterstriche
Neben der Schreibweise mittels Binnenmajuskeln existieren auch andere Schreibweisen, was sich im Beispiel wie folgt darstellt:
do_things_fast(); do-things-fast();
So wird in Sprachen wie C und Perl auch auf Unterstriche zurückgegriffen und auch in PHP war dies bis zur Version 4 der Fall. Die Schreibweise mit dem Bindestrich, welche auch als lisp-case bekannt ist, wurde unter anderem in COBOL und Lisp genutzt.
Auch bei Rust wird teilweise auf Unterstriche als auch auf CamelCase gesetzt.
Ausnahmen bei der Benamung
Je nach Sprache wird damit meist eine bestimmte Schreibweise für Bezeichner wie den Namen von Variablen genutzt, allerdings existieren hiervon auch Ausnahmen bzw. Abweichungen, wie bei der Definition von Konstanten:
public static final String SECRET_TOKEN = "X7z4nhty3287";
Diese werden in vielen Fällen komplett großgeschrieben und meist mit Unterstrichen unterteilt. Auch hier gilt wieder, dass solche Konstanten möglichst sprechend benannt werden sollten und auf Abkürzungen und Ähnliches verzichtet werden sollte.
Prä- und Suffixe
In der Vergangenheit wurden an Bezeichner teilweise Prä- und Suffixe mit angetragen. Begründet war dies mit den damaligen Compilern und der fehlenden Unterstützung in der Entwicklungsumgebung. Durch die Nutzung eines Präfixes konnte so z. B. der Typ einer Variable aus dem Namen ermittelt werden.
Die sicherlich bekannteste Notation ist die Ungarische Notation. Hier werden die Bezeichner aus einem Präfix für die Funktion, einem Kürzel für den Datentyp und einem Bezeichner zusammengesetzt.
Ein Beispiel für einen solchen Namen wäre die Variable idValue, welche anzeigt, dass es sich um einen Index vom Typ Double handelt, welcher den Namen Value trägt.
Mittlerweile wird diese Notation in der Praxis nur noch selten genutzt. Auch Linus Torvalds hatte sich dazu geäußert:
Encoding the type of a function into the name (so-called Hungarian notation) is brain damaged – the compiler knows the types anyway and can check those, and it only confuses the programmer.
Neben der besseren Unterstützung der IDEs gibt es andere Gründe, welche gegen eine Nutzung der ungarischen Notation sprechen. So kann z. B. bestehender Quelltext schlechter migriert werden, wenn sie die Namen nicht ändern dürfen, aber die Typen dies tun. Dies war z. B. der Fall bei der Umstellung der WinAPI auf eine 64-Bit fähige API, bei dem Namen nun nicht mehr auf den korrekten Datentyp hinweisen.
Einrückungen
Neben der Benennung von Bezeichnern ist auch die Einrückung ein unter Umständen recht emotionales Thema.
Dabei geht es hauptsächlich darum, ob Leerzeichen oder Tabulatoren für die Einrückungen genutzt werden. Aus pragmatischer Sicht sollte hier insbesondere die Mischung dieser beiden Varianten verhindert werden.
Für Leerzeichen spricht, dass die Einrückungen bei allen Nutzern identisch aussehen. Im Gegensatz zu Tabulatoren benötigen Leerzeichen, mehr Speicher. Vier Leerzeichen belegen 4 Byte, ein Tabulator nur ein Byte.
Bei Tabulatoren kann der Einzug in der Entwicklungsumgebung individuell konfiguriert werden, was aber gleichzeitig den Nachteil ergibt, dass der Quelltext bei unterschiedlichen Mitarbeitenden anders aussehen kann.
Persönlich würde der Autor an dieser Stelle immer Leerzeichen empfehlen. Damit ist ein Quelltext gewährleistet, welcher bei jedem Entwickler identisch aussieht. Der zusätzliche Speicherbedarf kann hierbei vernachlässigt werden.
Einrückungstiefen
Bei der Frage der Leerzeichen stellt sich auch die Frage, mit wie vielen Leerzeichen soll ein Block eingerückt werden. Hier ergibt sich die Möglichkeit, dies mit zwei Leerzeichen je Block zu machen:
void main() {
doSomething();
}
Der Standard bei vielen Projekten sind hingegen vier Leerzeichen:
void main() {
doSomething();
}
Allerdings sind auch acht Leerzeichen gebräuchlich, z. B. beim Linux-Kernel. Wirklich bemerkbar wird dies allerdings erst dann, wenn mehrere Blöcke ineinander verschachtelt werden:
void main() {
for(int i = 0; i < 10; i++) {
for(int j = 0; j < 10; j++) {
doSomething();
}
}
}
Je nach Ausgabeformat, z. B. beim Ausdruck oder in Präsentationen ist es sinnvoll auf zwei Leerzeichen zu setzen, aber im Allgemeinen sollten vier Leerzeichen genutzt werden.
Whitespaces und Leerzeilen
Neben der Einrückung sind auch die Whitespaces im Quelltext selbst, sowie Leerzeilen ein Element zur Strukturierung des Quelltextes.
Leerzeilen stellen ein wichtiges Element zur Strukturierung dar. Natürlich kann ein Quelltext ohne Leerzeilen geschrieben werden und leider ist dies in der Praxis oft zu sehen. Sinnvoll ist es aber, den Quelltext etwas weiträumiger zu gestalten:
int getResult(int a, int b) {
int sum = getSum();
int ret = 0;
for(int i = 0; i < 10; i++) {
ret += sum;
}
return ret;
}
Die Trennung einzelner Bestandteile des Quelltextes durch Leerzeilen sollte anhand der funktionalen Blöcke bzw. nach der Fachlichkeit vorgenommen werden.
Neben den Leerzeilen, sind auch Whitespaces ein essenzieller Teil der Formatierung eines Quelltextes. Whitespaces definieren sich allgemein als Leerstellen in Text, Code oder Schrift, die zwischen Zeichen, Wörtern, Zeilen oder Absätzen liegen. In der Programmierung werden Whitespaces auch als Formatierung verwendet, um den Quelltext leserlicher zu machen und den Code übersichtlicher zu strukturieren.
Whitespaces verbessern die Sichtbarkeit und das Verständnis der Syntax:
int sum=a+b;
for(int i=0;i<10;i++) {
doSomething();
}
Bei diesem Beispiel wäre es wesentlich sinnvoller, Leerzeichen zum Strukturieren zu nutzen und dem Quelltext eine gewissen Luftigkeit zu geben:
int sum = a + b;
for(int i = 0; i < 10; i++) {
doSomething();
}
Dies erhöht die Lesbarkeit und sorgt letztlich für ein besseres Verständnis. Natürlich kann auch an dieser Stelle übertrieben werden:
for ( int i = 0; i < 10; i++ ) {
doSomething ( ) ;
}
So werden hier auch Leerzeichen rund um die Klammern gesetzt, was im Normalfall nicht sonderlich hilfreich ist und deshalb unterlassen werden sollte.
Blockklammern
In vielen Programmiersprachen wird mit Blöcken gearbeitet. Ein Block definiert sich als eine Gruppe von Anweisungen, die als eine Einheit behandelt werden. So wird über den Block z. B. der Gültigkeitsbereich von Variablen definiert. Ein Block beginnt normalerweise mit einer öffnenden geschweiften Klammer und endet mit einer schließenden Klammer gleichen Typs.
Beispielsweise kann ein Block zu einer if-Anweisung gehören, in der eine Reihe von Anweisungen ausgeführt werden, wenn die Bedingung wahr ist. Hier kann natürlich die Frage nach der Notwendigkeit gestellt werden, wie in diesem Stück Java-Code:
if(something == true)
doFooBar();
So würde dieses Beispiel ohne Probleme kompilieren und wenn die Bedingung zutrifft, die Methode doFooBar aufgerufen werden. Problematisch wird dieses Konstrukt allerdings dann, wenn der Quelltext an dieser Stelle erweitert wird:
if(something == true)
doAnotherThing();
doFooBar();
Nun würde nur noch die Methode doAnotherThing ausgeführt werden. Die andere Methode hingegen nicht mehr. Aus dem Quelltext ist dies allerdings nicht ohne Weiteres ersichtlich. Aus diesem Grund sollte immer mit Blockklammern gearbeitet werden, auch wenn nur eine einzelne Anweisung folgt:
if(something == true) {
doFooBar();
}
Dadurch werden Fehler vermieden und die Intention des Quelltextes wird sofort ersichtlich.
Position der Klammern
Für die Positionierung der geschweiften Blockklammern gibt es in der Praxis zwei verbreitete Varianten, diese zu setzen. Bei der ersten Variante sind sie beide auf der gleichen Ebene zu finden:
boolean get()
{
int a = 7;
int b = 42;
int result = doFooBar(7, 42);
if(result == 23)
{
return false;
}
return true;
}
Der Vorteil an dieser Variante ist, dass sofort zu sehen ist, wo ein Block beginnt und wo sich die entsprechende schließende Klammer des jeweiligen Blockes befindet. Als Nachteil wird bei dieser Variante oft aufgeführt, dass damit etwas Platz verschwendet wird.
Bei der anderen gebräuchlichen Variante wird die öffnende Klammer eines Blockes direkt hinter die Anweisung gesetzt, welche zum öffnenden Block gehört:
boolean get() {
int a = 7;
int b = 42;
int result = doFooBar(7, 42);
if(result == 23) {
return false;
}
return true;
}
Dies erschwert zwar die Zuordnung zwischen dem Beginn des Blockes und dem Ende, allerdings zeigen die meisten modernen IDEs diese Zuordnung prominent an.
In der Theorie wird bei dieser Variante eine Zeile eingespart, allerdings ist es sinnvoll nach der öffnenden Blockklammer eine Leerzeile zu setzen, um die Übersichtlichkeit zu erhöhen.
Häufig wird noch ein Unterschied zwischen einzeiligen und mehrzeiligen Blöcken gemacht:
if(something == true) {
doFooBar();
}
Dort wird die Leerzeile weggelassen, während sie bei mehrzeiligen Blöcken immer eingefügt wird:
if(something == true) {
doFooBar();
doSomething();
for(int i = 0; i < 10; i++) {
doThings();
}
}
Blöcke per Einrückung
Neben Sprachen mit solchen Blockklammern existieren auch Sprachen wie Python, welche andere Wege zur Strukturierung von Blöcken nutzen:
import sys
import random
running = True
while running:
randomNumber = random.randint(0,8)
if randomNumber == 0:
break;
else:
print(randomNumber)
Hier wird die Zuordnung zu einem Block über die entsprechende Einrückung vorgenommen. Damit entfällt die Frage nach der Position der Blockklammern.
Reihenfolgen
In vielen Programmiersprachen gibt es Schlüsselwörter, wie Modifikatoren für die Sichtbarkeit. Für diese empfiehlt es sich auch eine entsprechende Reihenfolge zu definieren und diese einzuhalten.
Am Beispiel von Java wäre dies die Sichtbarkeit, dann eine eventuelle static-Definition gefolgt von einer final-Definition und am Ende der eigentlichen Definition:
public int a = 7; public final int b = 24; public static final int c = 42;
Auch bei Systemen zur statischen Codeanalyse, wie Sonarlint, sind solche Regeln hinterlegt.
Reihenfolge im Quelltext
Neben den Namen der Bezeichnern sind je nach Sprache auch bestimmte Reihenfolgen der einzelnen Elemente gewünscht. Unter Java ist dies vornehmlich folgende Reihenfolge: Konstanten, private Variablen, private Methoden, Getter und Setter und anschließend öffentliche Methoden.
Allerdings kann es valide sein, Public-Methoden und Private-Methoden zusammenzuhalten, wenn diese z. B. nach Funktionalität gruppiert sind.
Zeilenlänge und Umbrüche
Früher gab es relativ strenge Regeln, was die maximale Zeilenlänge innerhalb eines Quelltextes anging. Meist waren dies 80 Zeichen pro Zeile, bedingt durch die 80 Spalten in der Hollerith-Lochkarte von IBM. Daneben haben sich mittlerweile Zeilenlängen von 80 über 100 bis zu 120 Zeichen pro Zeile eingebürgert.
Auch in Zeiten größerer Bildschirme und höherer Auflösungen, sollten Zeilen trotzdem nicht unendlich lang gestaltet werden, sondern mit Zeilenumbrüchen gearbeitet werden. Für solche Umbrüche existieren unterschiedliche Variante, welche in gewisser Hinsicht Geschmacksache sind.
public int calculate(int valueA,
int valueB,
int valueC,
int valueD,
int valueE,
int valueF,
int valueG) {
return 0;
}
Grundsätzlich sollten keine Umbrüche mitten in einer Parameterliste vorgenommen werden, sondern die Parameter einzeln umgebrochen werden. Auch bei Fluent Interfaces wird mit Zeilenumbrüchen gearbeitet:
CarBuilder carBuilder = new CarBuilder()
.withWheels(4)
.withEngine(400, Fuel.DIESEL)
.withWindows(5)
.build();
Die Umbrüche verbessern, richtig eingesetzt, die Lesbarkeit und Verständlichkeit des Quelltextes.
Kommentare
Für einen verständlichen Quelltext sind in vielen Fällen Kommentare in diesem nötig und wichtig.
Je nach Sprache werden unterschiedliche Möglichkeiten für Kommentare bereitgestellt. Vorwiegend sind dies Zeilenkommentare und Blockkommentare.
Blockkommentare sind eine Reihe von Kommentaren, die durch ein vorangestelltes /* und ein abschließendes */ angezeigt werden, sodass mehrere Zeilen Text zusammen kommentiert werden können. Zeilenkommentare sind Kommentare, die nur eine einzelne Zeile betreffen und mit // beginnen. Sie können am Ende einer Codezeile oder auf einer eigenen Zeile platziert werden. Beide Kommentartypen sind nützlich, um das Verständnis des Codes zu erleichtern, indem sie Erklärungen zu bestimmten Codeabschnitten bereitstellen.
In den meisten Fällen sollten innerhalb eines Quelltextes den Zeilenkommentaren der Vorrang eingeräumt werden, entweder zum Auskommentieren von Quellcode oder zum Dokumentieren innerhalb des Codes:
// Create system temporary directory Path tmpdir = null; // log.error(tmpdir);
Block-Kommentare werden oft für die Dokumentation von Methoden, z. B. mittels JavaDoc genutzt:
/** * This method returns an Optional that holds a String containing * the file extension of the passed filename. * @param filename The file name whose extension is to be determined. * @return Optional filled with a String with the file extension if * the file has an extension, or an empty optional if it has no extension. */
Grundsätzlich gilt bei Kommentaren, dass sie fachlicher Natur sein sollten und dass nicht unnötig kommentiert wird. Als Sprache bietet sich hier wie bei der Benamung von Bezeichnern Englisch als kleinster gemeinsamer Nenner an. Unnötige Kommentare sollten vermieden werden:
// Calculate sum and store in sum int sum = getSum(a, b);
Der Inhalt des Kommentars ergibt sich bereits aus der sprechenden Bezeichnung der Variablen und der dazugehörigen Methode, sodass dies nicht noch einmal mit einem Kommentar untermauert werden muss.
Interessanter wäre es hier, wenn der Kommentar noch etwas zur Fachlichkeit beiträgt:
// Calculate sums of base articles int sum = getSum(a, b);
Auch das beliebte Auskommentieren von Code wird mittels der Sprachmittel des Kommentars ermöglicht. Im Normalfall sollte auskommentierter Quellcode am Ende immer entfernt werden und nicht im Quelltext verbleiben.
Allgemeine Regeln
Neben Regeln für spezielle Konstrukte existieren eine Reihe von allgemeinen Regeln, welche auch in Coding Conventions Einzug gefunden haben.
So gilt, dass pro Zeile genau eine Anweisung bzw. ein Statement kodiert wird, eine Funktion bzw. eine Methode genau eine Aufgabe erledigen und Klassen und Methoden eine gewisse Größe nicht überschreiten sollten.
Bei Klassen definiert sich hier meist eine maximale Größe von 2000 Zeilen, während bei Methoden gerne gesagt wird, dass eine Methode als Ganzes auf den Bildschirm passen sollte.
Aufgaben für Methoden
Auch die Beschränkung von Methoden auf eine Aufgabe ist eine sinnvolle Regel. So verheißt eine Methode mit dem Namen doItAll() schon wenig Gutes. Hingegen definiert folgende Methode:
int getSum(int a, int b)
schon anhand ihres Namens klar, welche Aufgabe sie wahrnimmt und mit welchem Ergebnis zu rechnen ist.
Dadurch, dass Funktionen bzw. Methoden sich nur auf eine Aufgabe beschränken, sind sie besser wiederverwendbar und verhindern in vielen Fällen doppelten Quelltext. Auch das Review solcher fachlich eng abgestimmten Methoden ist einfacher möglich, da die Komplexität verringert ist.
Coding Conventions
Während bis hierhin viele einzelne Elemente beschrieben wurden, sollen diese nun zu einer Coding Convention zusammengeführt werden. Solche Coding Conventions sind relativ umfangreiche Werke. In vielen Fällen ist es nicht nötig das Rad neu zu erfinden, da für viele Sprachen Standard-Konventionen existieren, welche genutzt werden können.
Alternativ sollte sich zumindest an diesen Konventionen orientiert werden. Auch die jeweiligen Entwicklungsumgebungen, setzten über die Code-Formatierung gewisse Teile von Coding Conventions direkt um.
Sprachspezifische Konventionen
Wer sich umschaut, wird feststellen, dass eine Reihe von Coding Conventions für unterschiedliche Sprachen existieren. Dies sind unter anderem die .NET: Microsoft Coding Conventions, für Java die Code Conventions for the Java Programming Language und für PHP: PSR-1 und PSR-2.
Allerdings werden manche dieser Konventionen wie für Java mittlerweile als veraltet angesehen und büßen damit auch an Verbindlichkeit ein. Bei anderen Styles wie PSR-2 werden diese direkt für die Entwicklung des Frameworks genutzt und sind somit verbindlich.
Übergreifende Konventionen
Daneben existieren noch andere Coding Conventions wie die Apple Coding Convention und der Google Style Guide.
Der Google Style Guide deckt Konventionen für unterschiedlichste Sprachen, wie C++, Objective-C, Java, Python, R, HTML, JavaScript und weitere ab und kann online eingesehen werden.
Lizenziert ist der Google Style Guide unter der Creative-Commons-Lizenz CC-BY. Neben der eigentlichen Beschreibung werden auch Dateien mit den entsprechenden Konfigurationen für die Entwicklungsumgebung mitgeliefert.
Dokumentation
Auch wenn ein Hauptaugenmerk bei Coding Conventions auf dem Quelltext liegt, sollte die Dokumentation ebenfalls beachtet werden. So sollte nur das notwendige dokumentiert und tote und inkorrekte Dokumentation gelöscht werden.
Auch hat es sich eingebürgert, eine entsprechende Datei ins Wurzelverzeichnis des Projektes zu legen. Diese trägt meist den Namen README bzw. README.md
In diesem Dokument wird erklärt, um welches Projekt es sich handelt und ein kurzer Überblick über das Projekt gegeben. Daneben werden weiterführende Links bereitgestellt und erklärt, wie das Projekt gebaut werden kann.
# WordPress2Markdown
WordPress2Markdown is a tool that convert WordPress eXtended RSS (WXR) into markdown. Export the WordPress site via
backend and use the WordPress eXtended RSS (WXR) with this tool.
## Usage
WordPress2Markdown is a command line tool.
> java -jar WordPress2Markdown.jar -i wordpress-export.xml -s DATETIME -o /home/seeseekey/MarkdownExport
### Parameter
The options available are:
[--author -f value] : Filter export by author
[--authors -a] : Export authors
[--help -h] : Show help
[--input -i value] : Input path
[--output -o value] : Output path
[--scheme -s /POST_ID|DATETIME/] : Scheme of filenames
## Conversion
WordPress2Markdown converted the following html and other tags:
* \<em\>
* \<b\>
* \<blockquote\>
* \<pre\>
* \<img\>
* \<a\>
* Lists
* WordPress caption blocks ()
All other tags are striped.
## Developing
Project can be compiled with:
> mvn clean compile
Package can be created with:
> mvn clean package
## Authors
* seeseekey - https://seeseekey.net
## License
WordPress2Markdown is licensed under AGPL3.
Eine weitere wichtige Datei ist das Changelog, bzw. die Datei CHANGELOG.md. Diese Datei dokumentiert Änderungen am Projekt und informiert den Leser somit über Änderungen, neue Funktionalität und Ähnliches.
# Changelog This changelog goes through all the changes that have been made in each release. ## [1.2.0-SNAPSHOT]() - 2022-03-04 ### Added * Implement simple conversion for CSV files ### Changed * Update project to Java 17 * Rework changelog * Update dependencies * Change license from GPL3 to AGPL3 ### Fixed * Fix some SonarLint code smells * Small optimizations ## [1.1.0](https://github.com/seeseekey/Convert2Markdown/releases/tag/v1.1) - 2019-10-13 ### Added * Implement conversion of MediaWiki dump files * Add statistical information for export * Add support for exporting author (#1) * Add filter to export only a specific author ### Changed * Rename tool to Convert2Markdown * Update documentation * Rebuild HTML to markdown conversion with HTML parser ## [1.0.0](https://github.com/seeseekey/Convert2Markdown/releases/tag/v1.0) - 2019-03-26 * Initial release
Versionierung
Im weiteren Sinne gehört auch die Versionierung des Projektes zu den Coding Conventions. Gerne genutzt wird hierbei die semantische Versionierung. Dabei liegen den Zahlen der Versionnummer z. B. 2.4.7 eine bestimmte Bedeutung zugrunde.
So handelt es sich bei der ersten Zahl um die Major-Version, welche nur dann erhöht wird, wenn zur Vorgängerversion inkompatible Änderungen oder andere signifikanten Änderungen vorgenommen wurden.
Die zweite Zahl ist die sogenannte Minor-Version, welche meist bei neuer Funktionalität hochgezählt wird. Die letzte Zahl bezeichnet die Bugfix-Version und wird bei entsprechenden Fehlerbereinigungen hochgezählt.
Daneben existieren auch andere Versionierungen, wie das relativ beliebte Schema Jahr.Monat z. B. 2023.04 als Versionnummer, welche bei neuen Releases basierend auf der Version gerne um eine dritte Nummer erweitert werden z. B. 2023.04.1.
Umsetzung
Neben der eigentlichen Definition einer Coding Conventions ist es wichtig, dass diese im Entwicklungsalltag berücksichtigt und genutzt wird. Hier stellt sich dann die Frage nach der organisatorischen Umsetzung.
Grundlegend sind es einige Schritte auf dem Weg bis zu Nutzung und Umsetzung. So sollte sich im ersten Schritt auf eine Coding Convention geeinigt werden. Nachdem dies geschehen ist, mitsamt aller diesbezüglicher Regeln, wie zur Benennung oder der gewünschten Komplexität, müssen diese Coding Conventions entsprechend kommuniziert werden.
So ist es problemlos möglich, entsprechende Templates für die Einstellungen der jeweiligen IDEs zur Verfügung zu stellen. Auch sollte die Überprüfung der Coding Conventions beim Review kontrolliert werden.
Daneben können die entsprechenden Coding Conventions auch per Software überprüft und z. B. das Pushen in ein entferntes Git-Repository nur erlaubt werden, wenn die Coding Conventions eingehalten wurden. Allerdings sollte auch nicht versucht werden, soziale Probleme, welche sich bei der Einführung der Konventionen ergeben, durch rein technische Ansätze zu lösen.
Umstellung
Eine weitere Frage ist die Umstellung der bestehenden Projekte auf neue Coding Conventions. Bestimmte Dinge wie die Formatierung des Quelltextes können meist automatisch auch für größere Projekte bewerkstelligt werden.
Daneben sollte bestehender Code Stück für Stück auf die Konventionen angepasst werden, z. B. bezüglich der Benamung. Dies kann immer dann geschehen, wenn an einer entsprechenden Stelle im Rahmen einer Anforderung gearbeitet wird.
Probleme
Natürlich kann es bei der Nutzung und Einführung von Coding Conventions Probleme geben. Dies kann sich in Widerstand aus der Entwicklerschaft oder in Problemen mit der technischen Seite wie unterschiedlicher IDEs ausdrücken.
Vor allem bei einer Neueinführung kann es schwierig sein, sich an entsprechende Konventionen und Regeln zu gewöhnen, wenn vorher ohne gearbeitet wurde. Das Gleiche gilt, wenn eine Konvention nicht den eigenen Präferenzen entspricht.
Es kann passieren, dass einige Zeit dafür aufgebracht werden muss, die Konventionen zu verinnerlichen und umzusetzen. Deshalb ist es wichtig, die Konventionen klar zu kommunizieren, ihre Nutzung verpflichtend zu machen und dies im Entwicklungsprozess wie beim Review auch zu beachten.
Fazit
Coding Conventions sind ein wesentlicher Bestandteil der Softwareentwicklung und bieten viele Vorteile. Sie helfen dabei, Quelltexte einfacher lesbar, verständlich und wiederverwendbar zu machen. Dadurch wird die Wartbarkeit verbessert und die Qualität der Software erhöht. Dies kann zu einer höheren Produktivität und einem schnelleren Entwicklungsprozess führen.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.


