In der IT-Welt gibt es zahlreiche Fälle, in denen Platzhalterwerte für Dokumentationen, Tests und Simulationen benötigt werden. Diese Werte sollen realistisch erscheinen, dürfen aber nicht zu echten, existierenden Daten führen.
Auch über die IT-Welt hinaus werden solche Werte hier und da verwendet, sei es in Film und Fernsehen, in Spielen oder anderen Medien.
Natürlich können sich solche Beispielwerte einfach ausgedacht werden. Bei zugeteilten Ressourcen, wie Domains, Telefonnummern oder IP-Adressen kann dies allerdings zu Problemen führen.
Der Missbrauch echter Domains oder IP-Adressen kann dort zu technischen Problemen, Datenschutzverletzungen oder rechtlichen Konsequenzen führen.
In diesem Artikel werden die Hintergründe, die technischen Standards und die Best Practices im Umgang mit solchen Ressourcen, wie Beispieldomains, IP-Adressen und anderen reservierten Werten behandelt.
Nutzung
Im ersten Moment stellt sich vielleicht die Frage, wo solche Beispieldaten bzw. Ressourcen benötigt werden.
In Dokumentationen und Handbüchern oder auch Anleitungen für unterschiedlichste Netzwerkgeräte oder Software werde Dinge wie IP-Adressen oder URLs gezeigt. Wünschenswert ist es, bei solchen Beispielen keine echten Ressourcen zu involvieren.
In der Softwareentwicklung und beim Testen von Anwendungen setzen Entwickler gezielt Beispiel-Adressen ein. Diese Praxis dient dazu, sicherzustellen, dass Quellcode-Beispiele und Testumgebungen niemals versehentlich mit Produktivressourcen interagieren. So kommen in Unit-Tests oder Konfigurationsdateien oft Dummy-Domains wie example.org oder test.example zum Einsatz.
Auch IP-Adressen werden bewusst gewählt, um reale Systeme nicht zu beeinflussen.
Das Gleiche gilt für Telefonnummern, wer hier auf einer Visitenkartenvorlage eine Nummer zeigt, möchte sicherstellen, dass diese nicht genutzt wird oder Unbeteiligte belästigt werden.
In Produktdemos oder Marketingmaterial befinden sich oft Platzhalter. Etwa Screenshots einer CRM-Software zeigen Max Mustermann – +1 555 0176 als Kontakt, um realistische Daten vorzuführen, ohne echte Personen und Nummern preiszugeben.
Oder ein Cloud-Anbieter demonstriert eine Konsole mit einem fiktiven Server server.example.com und der IP 203.0.113.42, um die Oberfläche exemplarisch darzustellen.
In der Systemadministration werden separate Testumgebungen mit Dummy-Daten betrieben. Beispielsweise könnte ein E-Mail-System auf einer internen Domain test.example laufen, damit Test-E-Mails nicht in die Außenwelt gelangen. Datenbanken in Staging-Systemen enthalten Telefonnummern aus einem Pool von Beispielnummern, damit keine versehentlichen SMS oder Anrufe an echte Kunden herausgehen.
In all diesen Fällen dienen die Beispielwerte dazu, realitätsnahe Situationen nachzustellen, ohne reale Adressen, Telefonnummern oder weitere zugeteilten Ressourcen zu benutzen. Dadurch können Lernende, Entwickler oder Nutzer gefahrlos experimentieren und die Beispiele nachvollziehen, ohne unbeabsichtigte Seiteneffekte in der realen Welt.
Unberechtigte Nutzung reservierter Ressourcen
Oft jedoch werden solche reservierten Ressourcen verwendet, ohne auf deren Verfügbarkeit zu achten. Ein Beispiel für eine solche Nutzung ist die E-Mail-Adresse , welche insbesondere vor einigen Jahren gerne und häufig als Absender-Adresse für Newsletter oder Support-E-Mails verwendet wurde.
Mit dem notwendigen Kleingeld kann auch als E-Mail-Adresse genutzt werden
Derjenige der die Kontrolle über die Domain noreply.com ausübt, kann diese dazu nutzen, E-Mails, welche auf solchen E-Mail-Adressen auflaufen zu empfangen und damit potenziell missbräuchlich nutzen.
Eine fiktive und doch reale Domain aus dem Spiel „Do Not Feed the Monkeys“
Auch in anderen Medien, wie Spielen, sind immer wieder Domains zu finden, welche im besten Fall dem Spieleproduzenten gehören, im schlimmsten Fall aber andere Eigentümer haben.
Die Domain steht zum Verkauf
Was auf den ersten Blick harmlos erscheint, kann zu Problemen und ernsthaften Konsequenzen führen.
Risiken und Nebenwirkungen
Zu den Risiken und Nebenwirkungen der Verwendung solcher Ressourcen, welche nicht im Eigentum liegen, oder für den Beispielgebrauch vorgesehen sind, zählen unter anderem juristische Konsequenzen. Die unberechtigte Nutzung einer existierenden Telefonnummer oder IP-Adresse oder Domain kann zu rechtlichen Problemen führen.
Leser oder Anwender können der Versuchung erliegen, eine beispielhafte Telefonnummer anzurufen oder eine Kreditkarten-Testnummer als reale Nummer zu verwenden.
Das geschieht öfter als gemeinhin angenommen, z. B. mit amerikanischen Sozialversicherungsnummern. 1938 verwendete ein Geldbörsenhersteller, die E. H. Ferree Company, für Werbezwecke die echte Social Security Number der Sekretärin des Vizepräsidenten, Hilda Schrader Whitcher, auf einer Musterkarte, die in jede verkaufte Brieftasche eingelegt wurde. Trotz Aufdrucken wie Specimen und rotem Druck hielten viele Käufer die Karte für echt und übernahmen die Nummer als ihre eigene.
Zum Höhepunkt im Jahr 1943 nutzten über 5.700 Menschen diese Nummer. Insgesamt haben sie über 40.000 Menschen genutzt. Selbst 1977 benutzten noch zwölf Personen diese Sozialversicherungsnummer. Die Social Security Administration musste die Nummer für ungültig erklären und breit kommunizieren, dass sie nicht verwendet werden darf. Whitcher selbst wurde wegen des Vorfalls sogar vom FBI befragt, empfand den ganzen Trubel aber eher als Ärgernis.
Neben diesem Vorfall gab es immer wieder ähnliche Vorfälle auch mit anderen gefälschten oder illustrativen Sozialversicherungsnummern — unter anderem veröffentlichte das Social Security Board selbst 1940 ein Heft mit einer Fantasienummer (219-09-9999), die später ebenfalls von echten Personen beansprucht wurde.
In der IT verhindern reservierte Adressen, dass Testsoftware Schaden anrichtet. Ohne Beispieladressen könnte es passieren, dass ein Entwickler, natürlich nur zum Test, hart kodierte IP-Adressen oder Domains einbaut, die zufällig jemandem gehören. Im schlimmsten Fall sendet eine solche Software dann Daten an Unbefugte oder beeinträchtigt fremde Systeme.
Mit Beispiel-IPs wie 192.0.2.42 sind solche Kollisionen absichtlich ausgeschlossen. Auch werden potenzielle Konflikte mit künftigen echten Zuweisungen vermieden – ein wichtiger Grund, der auch in der RFC 2606 genannt wird. Niemand muss befürchten, dass etwa die Domain example.com nächstes Jahr von einer Firma registriert oder gekauft wird und plötzlich von bestehender Nutzung real angesprochen wird. Die Domain ist fest als reserviert vorgesehen und dadurch, besser als gewöhnliche Domains, abgesichert.
Insgesamt sind Risiken vorhanden, die von möglichen Belästigungen Unbeteiligter über potenzielle Datenlecks bis hin zu rechtlichen Fragen reichen.
Daher gilt: Real existierende Telefonnummern, Domains oder IP-Adressen haben in Publikationen und Tests nichts verloren, sofern sie nicht ausdrücklich zur Demonstration ausgewählt und genehmigt wurden und sich idealerweise im Eigentum des Nutzers befinden.
Domains
Wer eine Domain als Beispiel nutzen möchte, sollte im einfachsten Fall darauf achten, dass diese Domain im eigenen Besitz und entsprechende Kontrolle über die Domain vorhanden ist.
Dann wäre es kein Problem, eine E-Mail-Adresse wie zu nutzen. Werden Domains allerdings nur als Beispiel benötigt, so kann sich mit einer Beispiel-Domain wie example.com beholfen werden.
Solche Beispieldomains werden in einer Reihe von RFCs, wie der RFC 2606, definiert.

Die Domain example.com ist als Beispieldomain verfügbar
Dort sind die Domains example.com, example.net und example.org als Beispiel-Domains definiert.
In Dokumentation und Beispielen sollten solche Domains verwendet werden, anstatt auf beliebte echte Domains wie yourdomain.com, noreply.com oder im deutschsprachigen Raum auf beispiel.de zu verweisen.
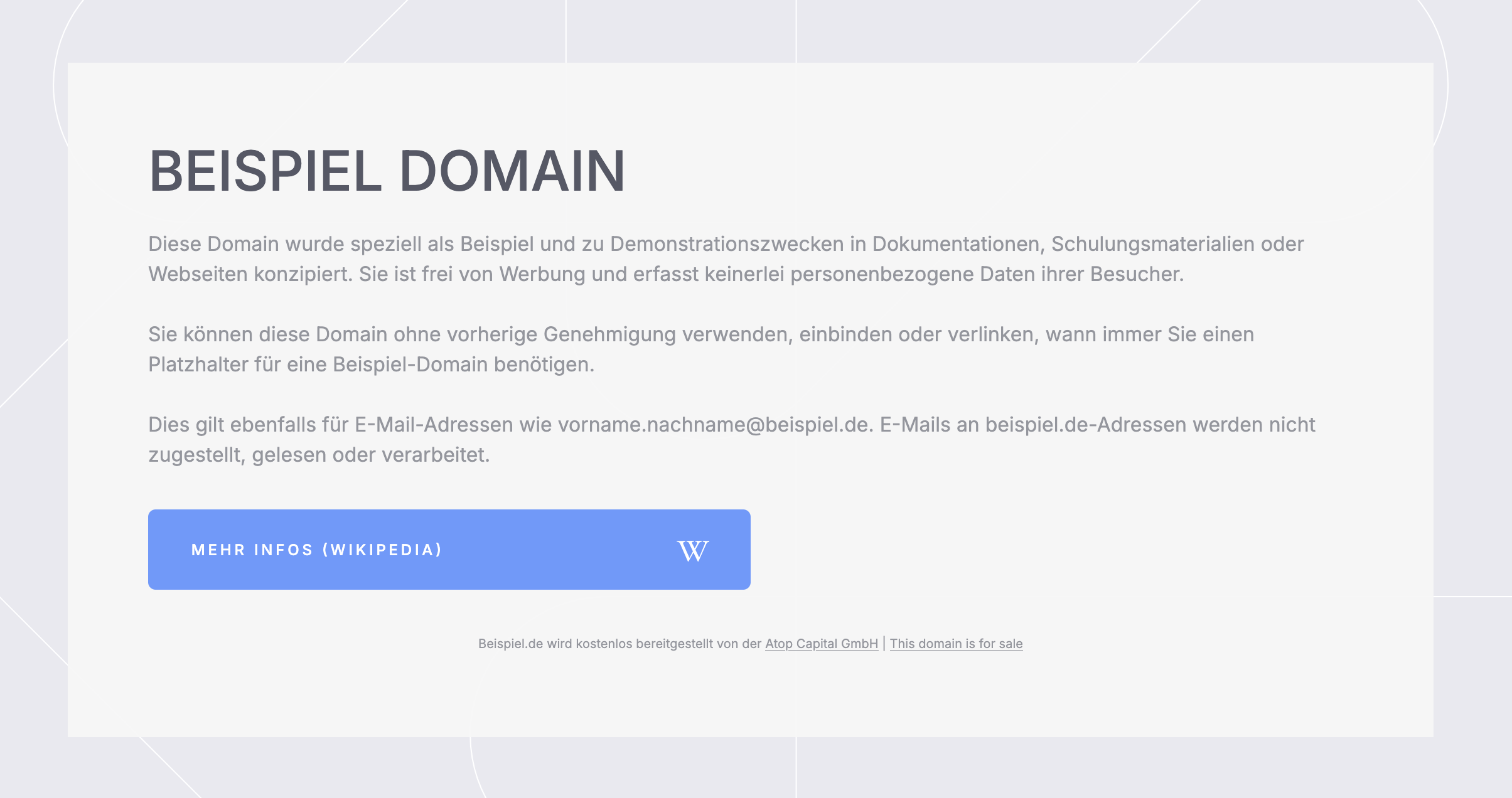
beispiel.de versteht sich als Beispiel-Domain
Auch wenn sich die Domain beispiel.de als Beispiel-Domain versteht, so trägt sie doch keinen offiziellen Status und sollte deshalb nicht als Beispiel für eine solche in Betracht gezogen werden.
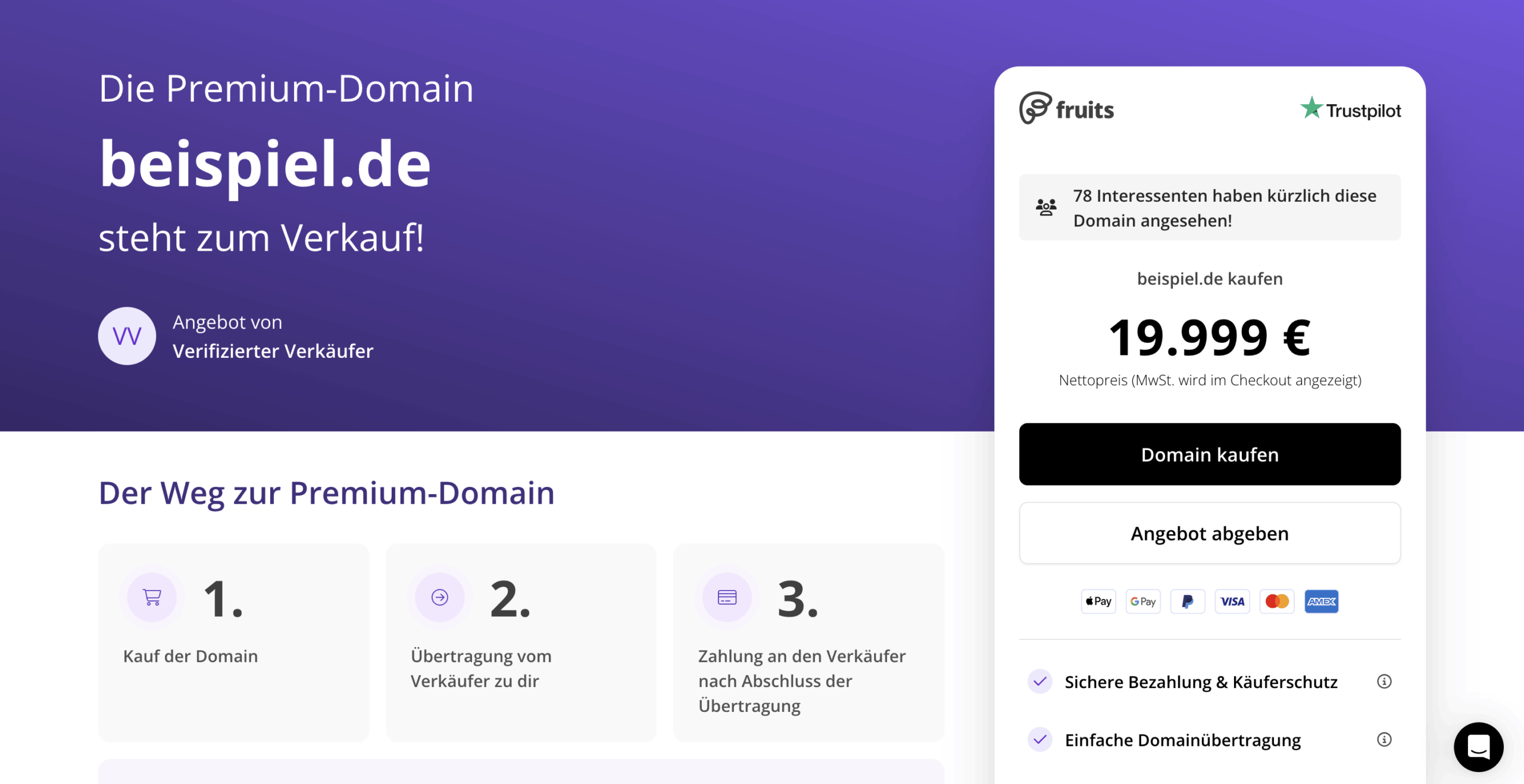
Beispiel.de steht ebenfalls zum Verkauf
So steht die Domain mittlerweile zum Verkauf und kann in Zukunft eine andere Nutzung erfahren, die mit dem Beispielzweck nicht übereinstimmt.
Vor allem in TV und Film wurden in der Vergangenheit auch gerne Domains mit ungültigen Top-Level-Domains wie z. B. der .web-Domain verwendet. So tauchte im James-Bond-Film Skyfall die Webadresse www.868000.web auf, während im Film Next Day Air die Domain www.nda.web auftauchte.
Das wird spätestens zu einem Problem, wenn die Top-Level-Domain .web in Zukunft eventuell angeboten wird. Ein vergleichbarer Fall ereignete sich 2024 bei AVM mit der Domain fritz.box.
Neben diesen konkreten Domains sind spezielle Top-Level-Domains für Beispiele reserviert. Diese sind in der RFC 2606 definiert worden. Hierzu gehören die Endungen .test, .example, .invalid und .localhost.
Die Top-Level-Domain .test wird für Tests von aktuellem oder neuem DNS-bezogenem Code empfohlen, während .example bevorzugt in Dokumentationen oder als Beispiel verwendet werden sollte.
Die Top-Level-Domain .invalid ist für solche Domains vorgesehen, die als sicher ungültig erkannt werden sollen.
Zudem wurde die TLD .localhost traditionell in DNS-Implementierungen statisch definiert, um einen A-Record auf die Loopback-IP-Adresse zu verweisen. Sie ist ausschließlich für diesen Zweck reserviert, da jede andere Nutzung mit weitverbreitetem Code in Konflikt geraten würde, der von dieser spezifischen Verwendung ausgeht.
IP-Adressen
Auch bei IP-Adressen kann die Nutzung falscher Beispiele zu Problemen führen. In Film und Fernsehen sind manchmal interessante Kombinationen wie 138.168.212.473 zu sehen, bei welcher es sich um eine ungültige IP-Adresse handelt.
Auch die Nutzung bekannter IP-Adressen, wie der 8.8.8.8 des Google Public DNS-Services, sollte nicht als Beispiel-IP-Adresse eingesetzt werden.
Besser und sicherer ist es hier dafür speziell vorgesehene Bereiche für Dokumentationszwecke zu nutzen. Definiert werden diese für IPv4-Adressen in der RFC 5737. Dabei sind mehrere Bereiche vorgesehen:
192.0.2.0/24 198.51.100.0/24 203.0.113.0/24
Die Blöcke tragen hierbei die Namen TEST-NET-1 (192.0.2.0/24), TEST-NET-2 (198.51.100.0/24) und TEST-NET-3 (203.0.113.0/24).
Gemäß der RFC sollen diese Blöcke von Adressen nicht im Internet auftauchen und in Netzwerken sollten diese Adressblöcke in die Liste der nicht routingfähigen Adressräume aufgenommen werden.
Damit gehören diese Adressbereiche nicht zu realen Netzwerken und können sicher in Handbüchern, Dokumentationen und Beispielen verwendet werden.
Natürlich könnten in der Theorie auch andere Bereiche genutzt werden, wie einer der privaten Adressbereiche wie 192.168.0.0/16. Somit wäre eine IP-Adresse wie 192.168.1.1 auf den ersten Blick unbedenklich. Allerdings werden diese IP-Adressen in internen Netzen produktiv genutzt und fallen damit als Beispiele in vielen Fällen weg.
Für besagte Dokumentationszwecke sind somit die oben genannten TEST-NET-Adressen vorzuziehen, weil sie global eindeutig als Beispieladressen kenntlich sind und nicht mit realen Netzen kollidieren.
Für IPv6 wurde ebenfalls ein Bereich bzw. ein Präfix für Dokumentationszwecke vorgegeben. Definiert ist dieses Präfix in der RFC 3849. Der für Dokumentationszwecke reservierte /32-Bereich lautet: 2001:0DB8::/32.
Jede IPv6-Adresse, die mit 2001:DB8 beginnt, ist somit als fiktiv für Dokumentations- und ähnliche Zwecke ausgewiesen.
Zusätzlich existiert für spezielle Protokoll-Demonstrationen ein reservierter IPv4-Multicast-Adressbereich mit dem Namen MCAST-TEST-NET (233.252.0.0/24), der in RFC 5771 definiert ist. Dieser Bereich ist für Demonstrations- und Beispielzwecke vorgesehen, doch im Alltag sind hauptsächlich die oben genannten Adressbereiche relevant.
Telefonnummern
Eine weitere zugeteilte Ressource sind Telefonnummern. Welche Folgen die unbedachte Verwendung realer Nummern haben kann, zeigt der Song Skandal im Sperrbezirk der Spider Murphy Gang. Dort heißt es im Songtext:
Ja, Rosi hat ein Telefon
Auch ich hab ihre Nummer schon
Unter zwounddreißig sechzehn acht
Herrscht Konjunktur die ganze Nacht
Die dort besungene Telefonnummer 32 16 8 sollte angeblich einer älteren Dame gehören, allerdings erzählte der Sänger Günther Sigl in einem Interview eine andere Geschichte dazu:
Richtig, 32168 war auf einmal die berühmteste Telefonnummer Deutschlands. In München hatten wir die Nummer gecheckt, die gab’s da damals nicht. In anderen Städten aber schon. Einige Jugendliche haben sich da einen Spaß gemacht, angerufen und blöd dahergeredet. Naja, wir haben damals einige Rufnummernänderungen bezahlt und zahlreiche Blumensträuße als Entschuldigung quer durch Deutschland geschickt.
Seit 2006 ist der Rufnummernblock (0)89 32168 000 bis (0)89 32168 999 der Telefónica zugewiesen.
Statt echter Nummern können zu diesem Zweck reservierte Bereiche, sogenannte Drama Numbers, genutzt werden. Im deutschen Raum sind diese über die Amtsblatt-Mitteilung 148/2021 definiert.
In der Amtsblatt-Mitteilung wurden für einige Ortsnetze im Festnetz bestimmte Nummernbereiche zur freien Verwendung definiert:
Berlin: (0)30 23125 000 bis 999 Frankfurt am Main: (0)69 90009 000 bis 999 Hamburg: (0)40 66969 000 bis 999 Köln: (0)221 4710 000 bis 999 München: (0)89 99998 000 bis 999
Wer diese Nummern anruft, wird per Ansage erfahren, dass die Rufnummer nicht erreichbar ist. Interessierte haben die Möglichkeit, dies selbst zu testen, da dies der Zweck der reservierten Nummern ist.
Somit können diese Nummern gefahrlos in Medienproduktionen oder als Beispiel genutzt werden. Neben Festnetznummern sind auch eine Reihe von Mobilfunknummern in den deutschen Netzen freigegeben:
(0)152 28817386 (0)152 28895456 (0)152 54599371 (0)171 39200 00 bis 99 (0)172 9925904 (0)172 9968532 (0)172 9973185 (0)172 9973186 (0)172 9980752 (0)174 9091317 (0)174 9464308 (0)176 040690 00 bis 99
Die Rufnummern des Blockes (0)171 39200 00 bis 99 gehören hierbei der Deutschen Telekom, die des Blockes (0)176 040690 00 bis 99 zu Telefónica, während die restlichen Nummern im Vodafone-Netz liegen.
Internationale Telefonnummern
Ähnlich wie in Deutschland existieren auch international spezielle Rufnummernblöcke für Beispielzwecke. Zu den bekanntesten Nummern zählen sicherlich die Telefonnummern aus dem amerikanischen Raum, die mit der Ziffernfolge 555 beginnen.
In Nordamerika ist seit den 1960er Jahren die Vorwahl 555 für fiktive Nummern gebräuchlich. Telefongesellschaften und Filmstudios einigten sich darauf, diese Vorwahl in Fernsehen und Film zu nutzen.
Tatsächlich sind die nur Nummern 555-0100 bis 555-0199 für rein fiktive Zwecke reserviert – wenn solche Nummern im Film gewählt werden, ist sichergestellt, dass kein tatsächlicher Anschluss existiert. Definiert sind diese Nummern im 555 NXX Line Number Reference Document (ATIS-0300115). Dort heißt es:
With the sunset of the 555 NXX Assignment Guidelines, a block of one hundred (100) 555 line numbers will remain reserved as fictitious, non-working numbers for use by the entertainment and advertising industries. These specific numbers are 555-01XX, i.e., numbers between and including 555-0100 and 555-0199.
In der Kinofassung von Bruce Allmächtig (im Origial: Bruce Almighty), wurde die Nummer von Gott als 776-2323 angegeben. In Buffalo, wo der Film spielte, war die Nummer nicht belegt, aber in vielen anderen Vorwahlbereichen existierte die Nummer. So wurde sie für die DVD, HD-DVD und Bluray-Fassungen schließlich in 555 geändert.
Video-Link: https://www.youtube.com/watch?v=mbZibNULsxI
Auch in britischen Produktionen kamen häufig Telefonnummern zum Einsatz, die sich nur bedingt als Beispiele eignen. Sehr bekannt ist sicherlich die „neue“ Notrufnummern. Anstatt der 999 soll in der Welt von IT Crowd nur noch die Nummer 0118 999 881 999 119 725 3 gewählt werden.
Video-Link: https://www.youtube.com/watch?v=HWc3WY3fuZU
Der Sketch spielt auf eine wahre Gegebenheit an: Im Jahr 2003 hatte Großbritannien sein traditionelles Auskunftssystem umgestellt, bei dem früher einfach die 192 gewählt wurde, um eine Telefonnummer zu erfragen. Nach der Liberalisierung mussten Anrufer stattdessen eine der neuen, kommerziellen 118-Nummern wählen, wobei insbesondere die leicht einprägsame 118 118, auch aufgrund einer allgegenwärtigen Werbekampagne, schnell Berühmtheit erlangte.
Zwar existiert der Bereichscode 0118, aber der Rufnummernblock beginnend mit der 999 wird nicht weitergeleitet, sodass zumindest keine Gefahr bestand, hier wirklich jemand zu erreichen.
Allerdings existieren auch in Großbritannien entsprechende Nummern für die Nutzung in fiktivem Kontext. Diese wurde zuletzt 2019, von der britischen Medienaufsicht, dem Office of Communications, veröffentlicht. So könnte das Torchwood-Institut in Cardiff, vielleicht die Telefonnummer 029/20180000 nutzen.
Daneben existieren in vielen anderen Ländern wie Australien, Irland, Südkorea, Schweden oder Frankreich Regelungen und Freigaben für jeweils auf die Länder zugeschnittene Drama Numbers.
Weitere zugeteilte Ressourcen
Neben den genannten Anwendungsfällen, wie Telefonnummern, Domains und IP-Adressen, gibt es weitere Ressourcen, für die gegebenenfalls Beispiele und Testdaten benötigt werden.
Für Kreditkarten wird z. B. von VISA die Testkreditkartennummer 4111 1111 1111 1111 bereitgestellt. Dies ist auch für viele andere Kreditkarten der Fall, hängt aber in der konkreten Ausprägung auch vom jeweiligen Zahlungsdienstleister ab. Gültig sind diese Nummern, dann meist nur in den jeweiligen Testsystemen der Dienstleister.
Auch für Kontonummern, wie IBANs existieren entsprechende Testnummern, welche genutzt werden können.
Best Practices
In der Praxis ist es ratsam, Beispiele klar als solche zu kennzeichnen, um Missverständnisse zu vermeiden. Dies kann durch Kommentare im Quellcode, Fußnoten in Dokumentationen oder spezielle Formatierungen geschehen.
Dokumentationen sollten klar kennzeichnen, dass verwendete Werte nur Beispiele sind. In Software sollte sichergestellt werden, dass Testwerte nicht versehentlich in Produktionsumgebungen gelangen.
Wenn die existierenden Beispieldaten nicht ausreichen, kann in bestimmten Fällen nachgeholfen werden – beispielsweise durch die Nutzung von Subdomains:
api.example.com blog.example.com shop.example.com
So bleibt die Beispielhaftigkeit gewahrt. Auch bieten die Beispiel-Top-Level-Domains die Möglichkeit viele Testdaten zu generieren z. B. shop.example, system.example.
Softwareentwickler sollten Mechanismen implementieren, die verhindern, dass echte Daten versehentlich in Testumgebungen verwendet werden. Skripte und Produktionscode können etwa prüfen, ob eine verwendete IP-Adresse oder Domain tatsächlich für Tests vorgesehen ist.
Auch der umgekehrte Fall gilt. In Produktivsystemen können auch Prüfungen eingebaut werden, ob in Feldern wie Telefonnummern oder Domains nur Beispielwerte eingegeben und diesen dann abgelehnt werden.
Daneben sollte man darauf verzichten, für Beispiele Templates aus echten Daten zu erstellen. Es mag verlockend sein, z. B. einen echten Konfigurationsausschnitt aus einem System als Grundlage für eine Dokumentation zu nutzen.
Hier besteht jedoch immer die Gefahr, einen Wert zu übersehen und reale Details abzubilden. Besser ist, von Anfang an eine künstliche Beispielumgebung aufzusetzen. So sollte ein Demo-Account mit Beispielnamen und -kontakten verwendet werden, statt eines echten Accounts.
Bei der Nutzung in Produktivumgebungen, wie als E-Mail-Absender, sollten die eigenen Domains genutzt werden. So kann sichergestellt werden, dass auch Rückläufer für noreply-Adressen nicht ins Leere laufen oder unbeabsichtigt Dritte erreichen.
Fazit
Beispiel ist nicht gleich Beispiel. Bei der Nutzung von Beispielen in Dokumentationen, anderen Texten, Medien oder Applikationen sollte Vorsicht geboten sein.
Handelt es sich um Beispiele, oder fiktive Werte, so sollten dafür vorgesehenen Varianten, wie z.B. Drama Numbers, verwendet werden.
Durch die Nutzung von Beispiel-IP-Adressen wird vermieden, dass Beispiel-Skripte, Konfigurationen oder Tutorien ungewollt fremde Rechner scannen oder ansprechen. Auch wenn ein Nutzer einen in einer Anleitung gezeigten Befehl kopiert, sind diese Adressen harmlos, da sie ins Leere führen oder nur lokale Wirkung haben.
Von inoffiziellen Beispieldomains wie beispiel.de sollte abgeraten werden, da hier keine Kontrolle darüber besteht, wie lange sie noch ihrer Funktion als Beispiel entspricht. Bei den hierfür offiziell reservierten Ressourcen kann hingegen von einer gewissen Kontinuität ausgegangen werden.
Beispieldomains, reservierte IP-Adressen und Drama Numbers sind essenziell für sichere und verständliche Dokumentationen sowie Testumgebungen. Durch die Verwendung standardisierter Werte können Fehler vermieden, Datenschutzrisiken minimiert und die Konsistenz in technischen Dokumentationen gewährleistet werden.
Die Einhaltung der entsprechenden RFCs und Best Practices hilft, Missverständnisse und missbräuchliche Nutzungen zu vermeiden.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.