Der Begriff des Fluent Interface hat mittlerweile knapp zwei Jahrzehnte auf dem Buckel und solche Schnittstellen sind mittlerweile auch in größerem Umfang in der Praxis angekommen und werden dort vielfältig genutzt. Trotzdem scheint es manchmal schwer zu fallen genau zu definieren, was ein solches Fluent Interface ist, was es auszeichnet und wie es in der Praxis sinnvoll genutzt werden kann.
Herkunft
Fluent Interfaces, welche wohl holprig mit einer fließenden Schnittstelle übersetzt werden könnten, sind eine Begrifflichkeit, welche in dieser Form erstmals 2005 von Martin Fowler und Eric Evans definiert wurden.
Martin Fowler ist bekannt für seine Arbeit, am Manifest für Agile Softwareentwicklung und seine Bücher, welche unter anderem das Code-Refactoring in die breite Öffentlichkeit trugen und populär machten.
Eric Evans ist vorwiegend für seine Beiträge rund um das Domain-Driven Design bekannt, dessen Gedanken er erstmals im gleichnamigen Buch Anfang der 2000er-Jahre zusammenfasste und somit den Begriff prägte.
Sinnvoller wäre für Fluent Interfaces allerdings die Bezeichnung als sprechende Schnittstelle, welcher eher der Idee im Kern entspricht. Bezugnehmend auf die Wortherkunft aus dem englischen to be fluent in a language, kann allerdings auch im Deutschen von Fluent Interfaces gesprochen werden.
Ideen des Fluent Interfaces
Dem Namen entsprechend ist eines der Ziele eines Fluent Interfaces, APIs besser lesbar und verstehbarer zu gestalten. Daneben soll die API Funktionalitäten passend zum Objekt bereitstellen können.
Bei Betrachtung einer solchen sprechenden Schnittstelle, soll der Quellcode sich wie eine natürliche Sprache bzw. ein Text in einer solchen anfühlen, anstatt eine Reihe von abstrakten Anweisungen darzustellen. Martin Fowler definierte auch ein Maß für diese Fluidität:
The key test of fluency, for us, is the Domain Specific Language quality. The more the use of the API has that language like flow, the more fluent it is.
Ein schönes Beispiel für die Nutzung einer solchen sprechenden Schnittstelle ist die Anwendung des Mock-Frameworks Mockito:
when(uuidGenerator.getUUID()).thenReturn(15);
Auch ohne genauere Kenntnisse über Mockito kann der Programmierer aus diesem Beispiel herauslesen, dass wenn die Methode getUUID angefordert wird, im Rahmen des Mocks immer der Wert 15 zurückgegeben wird.
Die Zeile kann mit sprachlichen Mitteln einfach gelesen werden und verrät dem Nutzer etwas über die dahinterliegende Funktionalität. Das Ziel, die entsprechenden Schnittstellen einfach lesbar und benutzbar zu machen, wird sich dadurch erkauft, dass es meist aufwendiger ist, solche Schnittstellen zu designen und zu entwickeln.
Dies bedingt sich durch das vorher zu durchdenkende Design und einem Mehraufwand beim Schreiben des eigentlichen Quellcodes, unter anderem in Form zusätzlicher Methoden und anderen Objekten zur Abbildung des Fluent Interface.
Zur Implementierung von Fluent Interfaces werden unterschiedliche Techniken wie das Method Chaining genutzt. Daneben werden häufig Elemente wie statische Factory-Methoden und entsprechende Imports, sowie benannte Parameter genutzt.
Sprechende Schnittstellen ermöglichen es auch Personen einen Einblick in den Quellcode zu geben, welche nicht mit den technischen Details desselben vertraut sind. Auch bei der Abbildung von fachlicher Logik helfen Fluent Interfaces, z. B. über entsprechende Methodennamen, welche sich auf die Fachlichkeit der Anwendung beziehen.
Method Chaining
Eine der Techniken zur Erstellung von sprechenden Schnittstellen ist das Method Chaining, welches im Deutschen treffend mit Methodenverkettung übersetzt werden kann.
Methodenketten sind eine Technik, bei der mehrere Methoden aufeinanderfolgend aufgerufen werden, um ein Ergebnis zu erhalten. Beispielsweise könnte ein Entwickler mehrere Methoden aufrufen, um einen bestimmten Wert aus einem Array zu extrahieren oder einen Alternativwert bereitzustellen. Die Methodenketten ermöglichen es dem Entwickler, mehrere Aufgaben in einer Kette zu erledigen, anstatt sie auf getrennte Statements zu verteilen.
Das bedeutetet allerdings im Umkehrschluss nicht, dass die Verkettung von Methoden gleich einem Fluent Interface entspricht, sodass an dieser Stelle immer differenziert werden sollte.
Am Ende einer Methodenkette wird das benötigte Objekt zurückgegeben oder die gewünschte Aufgabe ausgeführt. Aussehen könnte eine solche Methodenkette, in diesem Fall am Beispiel der Stream-API, wie folgt:
User nathalie = Arrays.stream(users)
.filter(user -> "Nathalie".equals(user.getForename()))
.findFirst()
.orElse(null);
Bei solchen Methodenketten gilt es zu berücksichtigen, dass bestimmte Methoden innerhalb der Kette im schlimmsten Fall null zurückgeben oder Exceptions auslösen. Je nach genutztem Interface müssen diese Fälle entsprechend beachtet werden.
Interessanterweise brechen Methodenketten mit einigen älteren Konventionen. So würden z. B. Setter in einem Builder-Pattern:
User.Builder.newBuilder()
.name("Mustermann")
.forename("Max")
.username("maxmustermann")
.build();
einen Wert zurückgeben, in diesem Beispiel das Builder-Objekt. Im Normalfall würde der Setter stattdessen keinen Rückgabeparameter aufweisen. Er wäre in einem gewöhnlichen Objekt wie folgt definiert:
public void setName(String name) {
this.name = name;
}
Diese Konvention rührt vom Command-Query-Separation-Pattern, welches besagt, dass entweder Kommandos oder Queries definiert werden sollten. Abfragen als solche, dürfen keinerlei Auswirkungen am Zustand der Klasse haben, während bei Kommandos entsprechende Auswirkungen explizit erwünscht sind. Dies ist z. B. dann der Fall, wenn Daten geändert werden.
Method Nesting
Eine weitere Technik, welche für die Nutzung und das Design von Fluent Interfaces benutzt wird, ist das Method Nesting bzw. das Verschachteln von Methoden. Ein Beispiel hierfür liefert die Java-Bibliothek REST Assured, welche eine domänenspezifische Sprache zur Abfrage und Validierung von REST-Services darstellt:
when()
.get("https://api.pi.delivery/v1/pi?start=0&numberOfDigits=100").
then()
.statusCode(200)
.body("content", startsWith("31415926535897932384"));
Neben der Verkettung von Methoden werden hier auch Methoden ineinander verschachtelt. In diesem Fall wird die startWith-Methode innerhalb der body-Methode geschachtelt, was dafür sorgt, dass beim Lesen ein besseres Verständnis entsteht, was im Quellcode passiert.
Die startWith-Methode stammt hierbei aus dem Hamcrest-Framework, welches viele solcher Methoden, unter anderem zur Nutzung in Unit-Tests, bereitstellt.
Statische Imports
Damit die Sprachelemente der Bibliothek im obigen Beispiel nicht immer voll referenziert werden müssen, werden statische Imports genutzt:
import static io.restassured.RestAssured.*; import static org.hamcrest.Matchers.*;
Damit kann eine statische Methode ohne ihren Klassennamen referenziert und genutzt werden. Ohne diesen statischen Import würde obiges Beispiel etwas umfangreicher aussehen:
RestAssured.when()
.get("https://api.pi.delivery/v1/pi?start=0&numberOfDigits=100").
then()
.statusCode(200)
.body("content", Matchers.startsWith("31415926535897932384"));
Damit wird über den Mechanismus der statischen Importe sichergestellt, dass der Quelltext, im Rahmen der Philosophie der sprechenden Schnittstellen, möglichst lesbar bleibt.
Object Scoping
Vor allem in Programmiersprachen mit einem globalen Namensraum und echten Funktionen können Funktionen, welche einzelne Bestandteile einer domänenspezifischen Sprache darstellen, in diesem globalen Namensraum angelegt werden.
Allerdings ist dies in den meisten Fällen unerwünscht, sodass die Bestandteile der domänenspezifischen Sprache, wie im Beispiel REST Assured in entsprechende Objekte verpackt werden und damit den globalen Namensraum entlasten. Dieses Vorgehen trägt den Namen Object Scoping.
Anwendung
Doch wozu können solche Fluent Interfaces in der Praxis genutzt werden? Unterschiedlichste Szenarien werden immer wieder angesprochen, wenn es um die Nutzung dieser Technik geht.
Eine häufigere Anwendung ist das Builder-Pattern und die Nutzung in Form domänenspezifischer Sprachen kurz DSLs bzw. im englischen Original Domain Specific Languages.
Eine solche domänenspezifische Sprache ist eine Programmiersprache, welche für ein bestimmtes Feld, besagte Domäne, entwickelt wird. Häufig werden sie verwendet, um komplexe Aufgaben zu vereinfachen, indem eine auf die Domäne und die zu lösenden Probleme angepasste Syntax genutzt wird, welche meist große Schnittmengen mit der Fachlichkeit der Domäne beinhaltet.
Fluent Interfaces in der Java-Welt
Auch in der Java Class Library existieren APIs, welche als Fluent Interface angelegt sind. Ein prominentes Beispiel hierfür ist die Stream-API:
User aMustermann = Arrays.stream(users)
.parallel()
.filter(user -> "Mustermann".equals(user.getName()))
.findAny()
.orElse(null);
Über die Stream-API können unterschiedlichste Anforderungen abgebildet werden. In diesem Fall wird ein Array mit Objekten vom Typ User durchsucht und parallel ein Nutzer mit dem Nachnamen Mustermann gesucht. Dieses Objekt wird dann zurückgegeben. Wird kein solches Objekt gefunden, so wird stattdessen null zurückgegeben.
Auch in anderen Frameworks wie Mocking-Frameworks oder solchen Bibliotheken, welche domänenspezifische Sprachen abbilden, wird intensiv Gebrauch von Fluent Interfaces gemacht.
Frameworks, wie Spring, nutzen ebenfalls interne DSLs, um bestimmte Anforderungen und Möglichkeiten zur Konfiguration abzubilden.
Fluent Interfaces im Builder-Pattern
Eine weitere Anwendung für Fluent Interfaces im weiteren Sinne ist das sogenannte Builder-Pattern. Bei diesem existiert eine Klasse und ein dazugehöriger Builder, welcher dazu dient das Objekt zu konstruieren.
Hier wird ersichtlich, dass dies auf den ersten Blick mehr Aufwand bei der Implementation bedeutet. Allerdings müssen „Standardaufgaben“, wie das Erstellen eines Builders nicht unbedingt von Hand erledigt werden, da es für unterschiedlichste IDEs entsprechende Unterstützung in Form von Erweiterungen gibt. Für IntelliJ IDEA wäre ein Plugin für diese Aufgabe der InnerBuilder von Mathias Bogaert.
Ein Plugin für die einfache Erzeugung von Buildern in IntelliJ IDEA
Mithilfe dieser Plugins können Builder-Klassen schnell erstellt und bei Änderungen der eigentlichen Basisklasse angepasst werden, indem die Builder-Klasse über das Plugin neu generiert wird. Dies ermöglicht eine unkomplizierte Änderung von Klassen samt ihrer dazugehörigen Builder.
Manchmal wird beim Builder-Pattern infrage gestellt, ob es sich bei diesem wirklich um ein Fluent Interface handelt. Dabei wird die Unterscheidung getroffen, dass Fluent Interfaces sich mehr auf die Manipulation und Konfiguration von Objekten konzentrieren, während Builder den Fokus auf die Erzeugung von Objekten legen.
Es stellt sich allerdings die Frage, inwiefern diese Gedanken akademischer Natur, in der Praxis relevant sind, da auch Builder sich aus Sicht des Lesers des Quellcodes gut als Fluent Interfaces erschließen lassen.
Builder-Pattern im Beispiel
Wie könnte ein solches Builder-Pattern nun an einem einfachen Beispiel aussehen? Gegeben sei folgende Klasse:
public class User {
private String name;
private String forename;
private String username;
public User() {
}
}
Die Klasse mit dem Namen User enthält drei Felder in welchen der Name, Vorname und der Nutzername des Nutzers gespeichert werden. Um die Felder der Klasse zu befüllen, existieren unterschiedliche Möglichkeiten.
So könnte ein entsprechender Konstruktor definiert werden, welcher diese Felder setzt:
public User(String name, String forename, String username) {
this.name = name;
this.forename = forename;
this.username = username;
}
Dieser könnte nun aufgerufen werden, um eine Instanz der Klasse zu erstellen und die Felder zu füllen:
User max = new User("Mustermann", "Max", "maxmustermann");
Soll jedoch ein Wert nicht gesetzt werden, kann dieser auf null gesetzt werden. Allerdings kann es hier auch den Fall geben, dass mit NotNull-Annotationen und einer entsprechenden Validation gearbeitet wird:
public User(@NotNull String name, @NotNull String forename, @NotNull String username)
Durch die Annotation soll verhindert werden, dass die entsprechenden Felder mit dem Wert null initialisiert werden können. In einem solchen Fall ist für die entsprechenden Felder auch die Anwendung des Builder-Patterns nur schwer vorstellbar, z. B. über das Setzen der Werte in der newBuilder-Methode.
Sind solche Einschränkungen nicht vorhanden, könnte alternativ mit unterschiedlichen Konstruktoren gearbeitet werden, in welchen jeweils nur einige der Felder gesetzt werden können.
Spätestens bei komplexeren Objekten wird auffallen, dass diese Methode eher ungeeignet ist. Der klassische Weg ist es hier entsprechende Getter und Setter zum Abrufen und Setzen der Eigenschaften bereitzustellen:
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getForename() {
return forename;
}
public void setForename(String forename) {
this.forename = forename;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
Zwar können Getter und Setter auch über Annotationen, z. B. mithilfe der Bibliothek Lombok, vor dem Compile-Vorgang, generiert werden, allerdings hält der Autor nicht sonderlich viel von dieser Art von „Präprozessor-Magie“.
Hierbei werden unnötige Abhängigkeiten für doch recht simple Aufgaben, an das Projekt angehangen, welche wiederum bestimmte Funktionsweisen vor dem Entwickler verstecken. Vor allem, wenn der Entwickler nicht mit dem Projekt vertraut ist, kann dies das Verständnis erschweren.
Unter Nutzung der Setter kann ein Objekt nun feingranular mit den gewünschten Werten befüllt werden:
User user = new User();
user.setName("Mustermann");
user.setForename("Max");
user.setUsername("maxmustermann");
Soll z. B. der Vorname nicht gesetzt werden, so kann die entsprechende Zeile einfach weggelassen werden. Diese Nutzung bzw. Schreibweise wird manchmal unter dem Namen Method Sequencing zusammengefasst.
An dieser Stelle könnte stattdessen ein Builder genutzt werden. Bei diesem würde das Ganze wie folgt aussehen:
User user = User.Builder.newBuilder()
.name("Mustermann")
.forename("Max")
.username("maxmustermann")
.build();
Bei dieser Schreibweise wird der Builder genutzt, um das Objekt zu erstellen und mit seinen Werten zu befüllen. Der Builder liefert dazu die benötigen Methoden:
public static final class Builder {
private String name;
private String forename;
private String username;
private Builder() {
}
public static Builder newBuilder() {
return new Builder();
}
public Builder name(String name) {
this.name = name;
return this;
}
public Builder forename(String forename) {
this.forename = forename;
return this;
}
public Builder username(String username) {
this.username = username;
return this;
}
public User build() {
return new User(this);
}
}
In vielen modernen Implementationen des Pattern wird meist auf das Präfix set für die Setter verzichtet und stattdessen nur der Name des Feldes als Methode definiert. Alternativ wird häufig auch das Präfix with genutzt.
Beim Quelltext wird ersichtlich, dass jede Methode, bis auf die build-Methode, eine Instanz des Builders zurückgibt und damit die Verkettung der unterschiedlichen Methoden erlaubt.
Fluent Interfaces zur Definition einer DSL nutzen
Neben dem Entwicklungsmuster des Builders können mithilfe von Fluent Interfaces domänenspezifische Sprachen (DSLs) erstellt werden.
Bei solchen Sprachen handelt es sich um speziell für ein bestimmtes Anwendungsgebiet entwickelte Programmiersprachen. Sie sind oft einfacher und leichter zu verstehen als allgemeine Programmiersprachen und ermöglichen es Entwicklern bzw. den Anwendern der Sprache, effizienter und präziser zu programmieren.
DSLs werden häufig in bestimmten Bereichen wie der Finanzbranche, der Medizin, der Luftfahrtindustrie, der Spieleentwicklung und der Datenanalyse eingesetzt. Sie können dazu beitragen, Prozesse zu automatisieren und zu vereinfachen und ermöglichen Entwicklern, komplexe Aufgaben in kürzerer Zeit zu erledigen.
Zu den bekanntesten domänenspezifischen Sprachen gehört SQL und auch reguläre Ausdrücke können als DSL gesehen werden. Grundsätzlich werden domänenspezifischen Sprachen in externe und interne Sprachen unterteilt.
Bei den internen DSLs wird eine Wirtssprache, in diesem Beispiel Java, genutzt, um die DSL abzubilden. Externe DSLs hingegen stehen für sich allein und nutzen keinerlei Wirtssprache. Deshalb sind sie auf eigens dafür entwickelte Compiler oder Interpreter angewiesen.
Im folgenden Beispiel soll eine DSL für HTML entwickelt und anhand dieser sollen einige Konzepte der sprechenden Schnittstellen in Zusammenhang gebracht werden. Die HTML-DSL soll dazu genutzt werden, HTML-Dokumente zu bauen. Ein Aufruf dieser DSL könnte wie folgt aussehen:
String html = new Html()
.head()
.meta("UTF-8")
.meta("keywords", "fluent, interface")
.title("Fluent interfaces")
.finalise()
.body()
.text("Fluent interfaces")
.br()
.finalise()
.generate();
Während bei einem einfachen Builder immer der Builder als solcher zurückgegeben wird, wird in diesem Fall nicht immer das Hauptobjekt, die Klasse Html, zurückgegeben. Stattdessen werden teilweise sogenannte Intermediate-Objekte zurückgegeben. Diese haben außerhalb der DSL keinerlei sinnvolle Funktionalität, sondern dienen dazu nur die Methoden anzubieten, welche im Kontext von HTML erlaubt sind.
Über Intermediate-Objekte lassen sich somit auch bestimmten Reihenfolgen erzwingen. Damit kann der Compiler zumindest zur partiellen Überprüfung der Anweisungen benutzt werden und dem Anwender bzw. Entwickler werden nur die Funktionalitäten zur Verfügung gestellt, welche im entsprechenden Kontext sinnvoll sind.
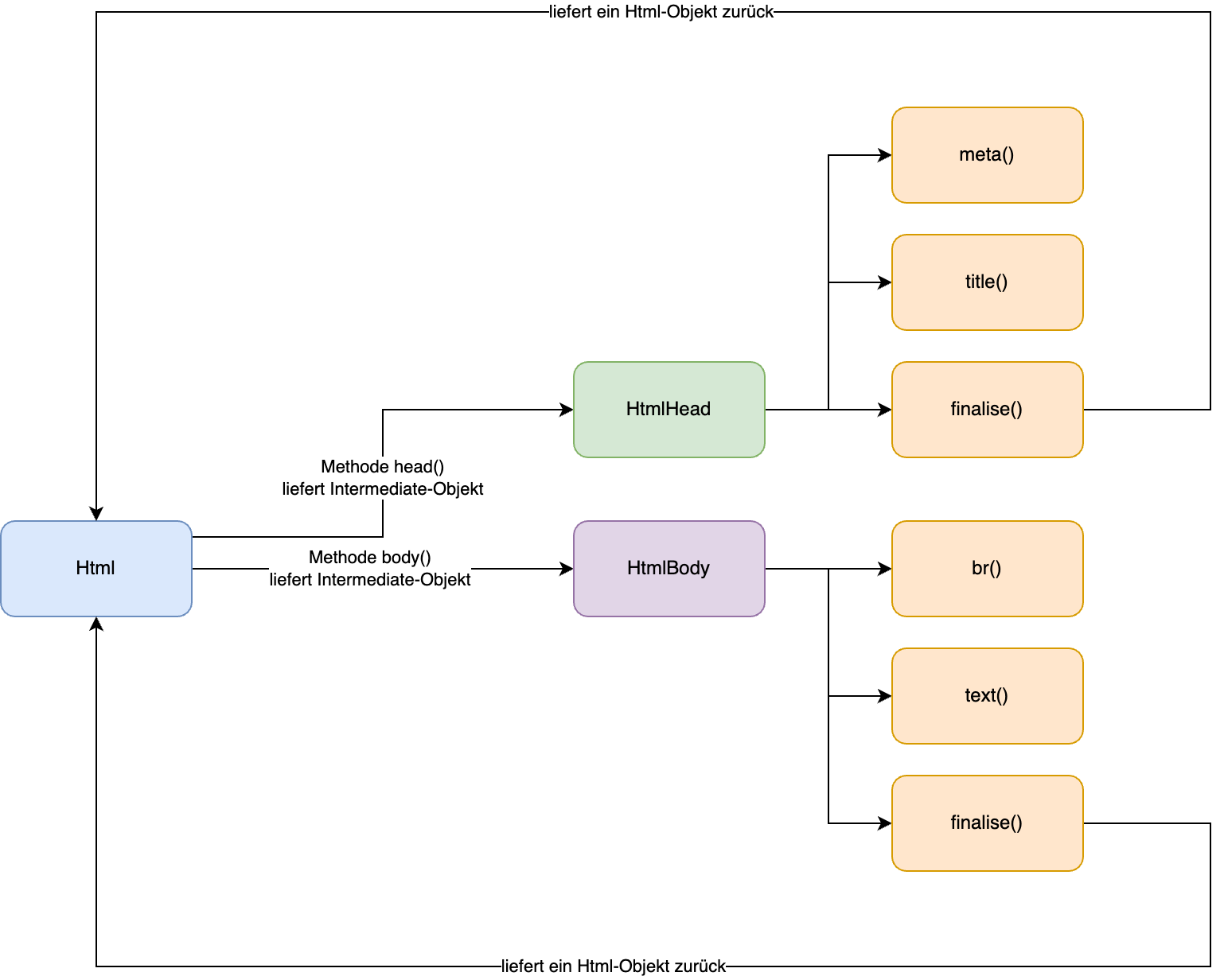
Über die Intermediate-Objekte werden die entsprechenden Methoden zur Verfügung gestellt
Unterstützt wird der Entwickler daneben durch die Autovervollständigung der IDE, welche die Methoden des jeweiligen Intermediate-Objektes darstellen kann. Anschließend dient die Methode finalise dazu, wieder eine Ebene höher in der Hierarchie der Intermediate-Objekte zu wandern.
In der Theorie könnten die entsprechende Verschachtelung beliebig komplex gestaltet werden. So können div-Blöcke als Elemente genutzt werden und innerhalb des Intermediate-Objektes für den div-Block stehen dann ausschließlich solche Elemente, welche im Rahmen eines div-Blockes genutzt werden können.
Bei der Nutzung einer solchen domänenspezifischen Sprache ist es wichtig, dass der jeweilige Aufruf auch sinnvoll beendet werden muss. So kann es bei falscher Nutzung durchaus passieren, dass der Entwickler, wenn er entsprechende Aufrufe vergisst, ein Intermediate-Objekt als Rückgabe am Ende erhält, mit welchem er nicht viel anfangen kann. Dieses Problem wird auch als Finishing-Problem bezeichnet.
Beim Design einer DSL muss immer sichergestellt werden, dass es einen Aufruf in den jeweiligen Intermediate-Objekten gibt, welcher dafür sorgt am Ende ein sinnvolles Ergebnis zu erhalten bzw. wieder zum eigentlichen Objekt zurückführt.
Automatische Generation von sprechenden Schnittstellen
Viele domänenspezifische Sprachen werden von Hand geschrieben, allerdings existieren durchaus Ansätze solche Sprachen auch über eine entsprechende definierte Grammatik zu generieren.
Auch Codegeneratoren wie z. B. für GraphQL-Schnittstellen erzeugen unter Umständen Fluent Interfaces, welche dann genutzt werden können:
return new ProductResponseProjection()
.categoryId()
.categoryName()
.issuingCountry();
In diesem Fall wird aus dem GraphQL-Schema eine entsprechende API plus das dazugehörige Modell generiert, welches sich dann nach Außen hin als Builder– bzw. Fluent Interface darstellt.
Ob und wieweit die Generierung von sprechenden Schnittstellen automatisiert werden kann, hängt immer sehr stark vom jeweiligen Anwendungsfall ab.
Fazit
Fluent Interfaces sind ein Begriff, der nun schon eine Weile durch die Welt geistert und wahrscheinlich finden sich in den Köpfen unterschiedliche Vorstellung davon.
Teilweise ist es schwierig, eine harte Definition von sprechenden Schnittstellen zu finden, wie der StringBuilder unter Java zeigt:
String abc = new StringBuilder()
.append("ABC")
.append("DEF")
.append("GHJ")
.toString();
Die append-Methode stellt hier eine Art Builder-Pattern in Form einer sprechenden Schnittstelle zur Verfügung und kann damit im Kleinen als solche gesehen werden. Die Bandbreite von Fluent Interfaces im Kleinen, wie dem Builder-Pattern, bis zu ausgewachsenen domänenspezifischen Sprachen mit eigenen Grammatiken ist groß.
Alles in allem spielen sprechende Schnittstellen vorwiegend bei komplexen Objekten und entsprechenden Use Cases ihre Stärken aus. Sie sorgen für mehr Verständnis und nutzen die Möglichkeiten des Compilers und der IDE zur Unterstützung aus.
Trotz der Vorteile, welche solche sprechenden Schnittstellen bieten, sollte vor der Implementation immer genau überlegt werden, ob für den jeweiligen Anwendungszweck wirklich ein solche benötigt wird. Hier sollte die erhöhte Komplexität in der Implementation und Pflege mit der Notwendigkeit abgewogen werden.
Der Quellcode der einzelnen vorgestellten sprechenden Schnittstellen kann über GitHub eingesehen und ausprobiert werden.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.