Im Versionsverwaltungssystem Git existieren im Repository sogenannte Packfiles. Diese werden genutzt um mehrere Objekte, wie z.B. Commits, Trees, Blobs oder Tags, als einzelne Dateien abzulegen. Damit fasst Git viele Objekte zu einer einzelnen komprimierten Datei zusammen. Ergänzt wird das ganze durch einen Index, um einen schnellen Zugriff zu ermöglichen. Dabei nutzt Git Delta-Kompression, indem es ähnliche Objekte, z. B. verschiedene Versionen derselben Datei, nicht vollständig speichert, sondern nur die Unterschiede.
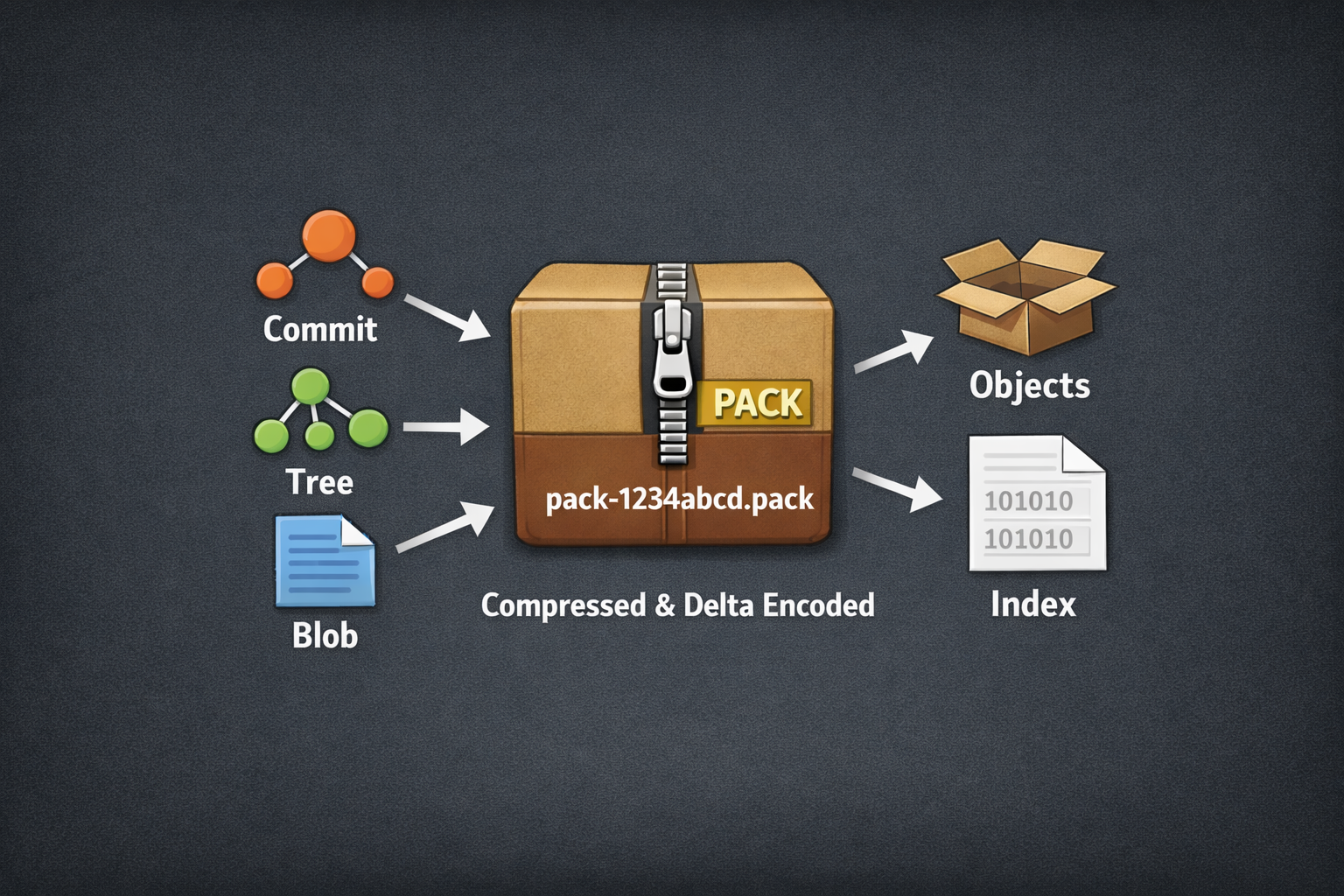
Eine Git-Pack-Datei im Schema
Dies reduziert die Repository-Größe erheblich, kann aber bei ungünstigen Repositorys mit vielen Binärdaten zu Repositorys führen, welche mehrere dutzend Gigabyte große Pack-Dateien besitzen. Eine Steuerung ist über den Konfigurationsparameter pack.packsizelimit möglich:
git config pack.packsizelimit 5g
Damit würde diese Einstellung für das aktuelle Repository gesetzt werden. Wer das Ganze global benötigt, kann dies ebenfalls einstellen:
git config --global pack.packsizelimit 5g
Allerdings gilt diese Einstellung nicht sofort, stattdessen muss für ein Repack gesorgt werden:
git repack -Ad --max-pack-size=5g
Anschließend kann die Größe der Packs kontrolliert werden:
ls -lh .git/objects/pack
Allerdings sollte beachtet werden, das die Option grundsätzlich nur in Ausnahmefällen sinnvoll ist:
Note that this option is rarely useful, and may result in a larger total on-disk size (because Git will not store deltas between packs) and worse runtime performance (object lookup within multiple packs is slower than a single pack, and optimizations like reachability bitmaps cannot cope with multiple packs).