Für den Datentransfer zwischen Systemen existieren in der IT-Welt unzählige Protokolle und Verfahren. Mit MQTT existiert ein Protokoll, welches sich unter anderem für Kommunikation im IoT-Bereich gut eignet.
Zugutekommt MQTT hier, dass es unter anderem für die Nutzung über Verbindungen mit geringen Datenraten, z. B. die Nutzung über Satellitensysteme, optimiert wurde.
Neben den Grundlagen und einem Verständnis für das Protokoll, ist auch die Nutzung interessant. Aus diesem Grund soll im Rahmen dieses Artikels, eine kleine MQTT-Umgebung unter Verwendung von Java implementiert werden und mit dieser einige Konzepte und Möglichkeiten rund um MQTT dargestellt und erläutert werden.
Das große Ganze
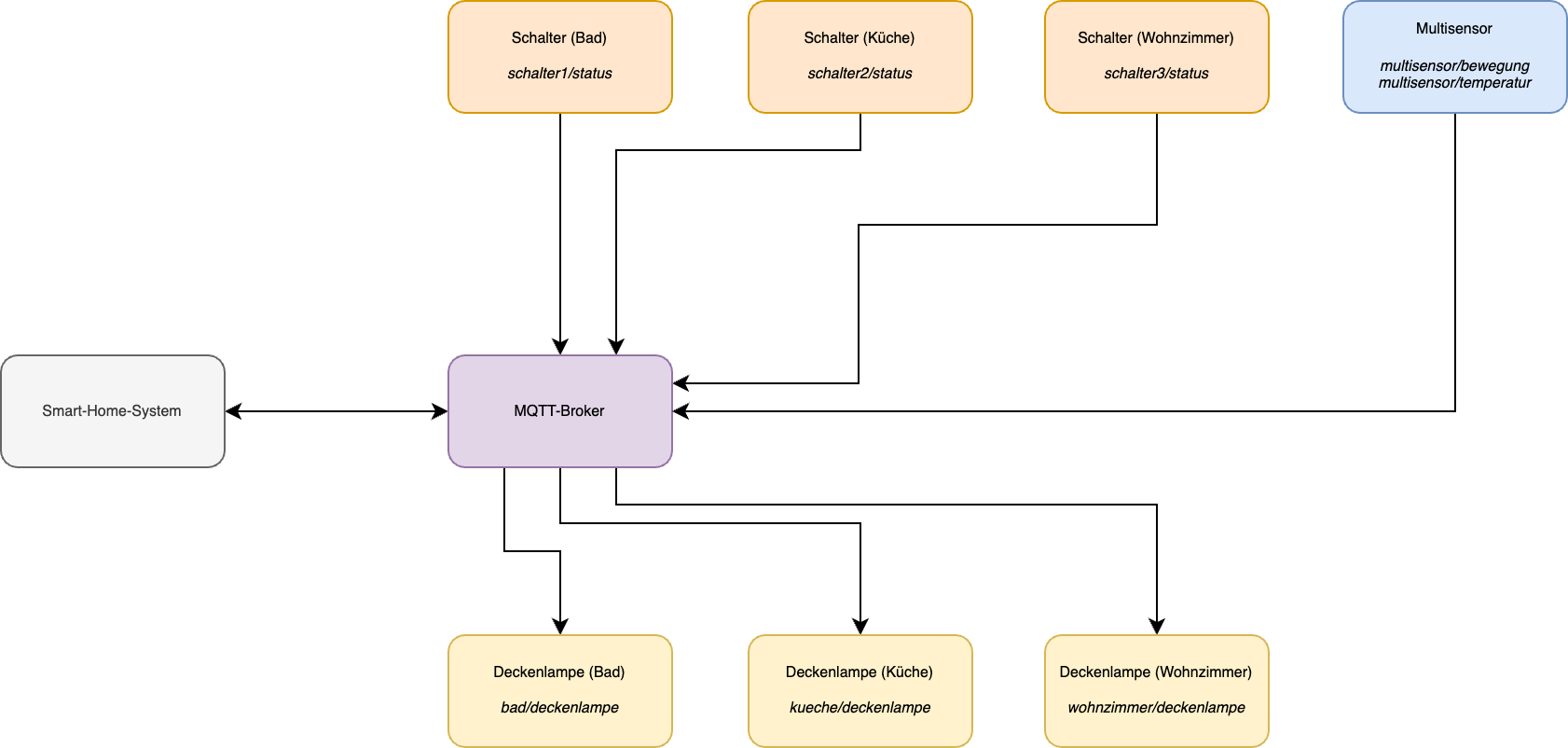
Als Szenario für eine beispielhafte Implementation wird ein Smart-Home-System angenommen.

Die Räumlichkeiten für das Smart-Home-Szenario
In diesem Szenario existieren Räume, in diesen ein paar Lampen, einige Sensoren und Schalter. All diese Geräte kommunizieren über MQTT mit einem Broker und sind so miteinander verbunden. Auch das Steuerungssystem des Smart-Home-Systems ist per MQTT über den Broker angebunden.
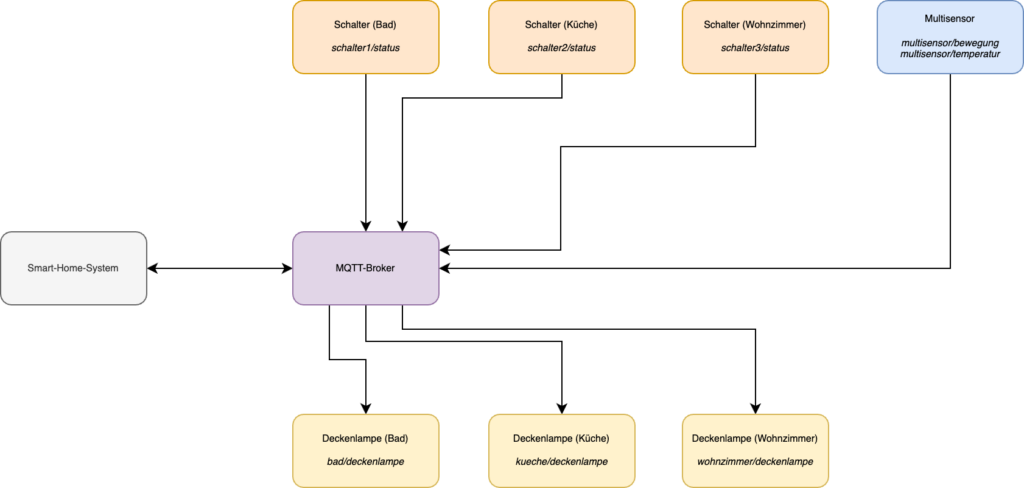
Die Struktur des MQTT-Clients und des Brokers untereinander
Am Ende steuert das Smart-Home-System anhand von Eingaben, z. B. der Nutzung eines Schalters, die entsprechenden Deckenlampen.
Abgebildet werden die Geräte über die entsprechenden Topics im MQTT-Broker. Ein solches Topic könnte z. B. bad/deckenlampe sein und adressiert somit eine Nachrichtenquelle bzw. einen Empfänger.
Das Smart-Home-System abonniert einen Großteil dieser Topics und erhält damit die Daten der Geräte und kann basierend darauf neue Nachrichten an den MQTT-Broker und die entsprechende Topics verschicken.
Broker
Für MQTT zwingend notwendig ist ein Broker. Dieser bildet das zentrale Herzstück für die MQTT-Kommunikation. Er stellt Topics bereit, welche abonniert werden können und zu welchen Nachrichten gesendet werden können. Diese Funktionalitäten hören im MQTT-Kontext auf die Namen Subscribe und Publish. Jeder Client, welcher ein solches Topic abonniert, enthält anschließend die entsprechenden Nachrichten.
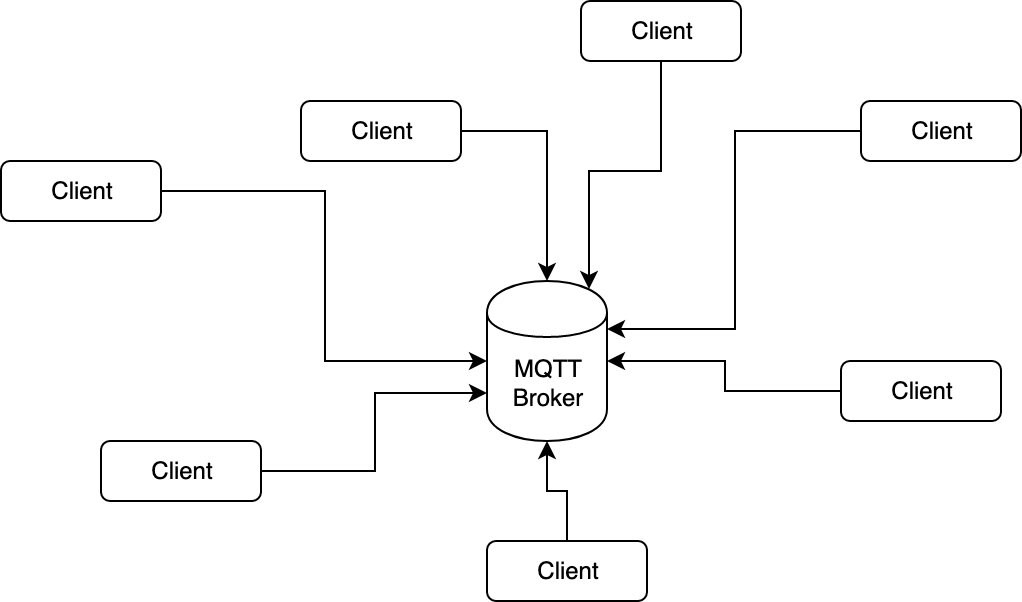
Alle Clients sind mit dem Broker verbunden
Auf dem Markt existieren eine Reihe von Brokern z. B. HiveMQ oder Mosquitto. Bei diesen Brokern handelt es sich meist um dedizierte Applikationen. In den meisten real existierenden Szenarien wird ein solcher zentraler Broker aufgesetzt und genutzt.
Daneben existieren auch Broker, welche direkt in eine Applikation integriert werden können, wie Mosquette; welches im beschriebenen Szenario zur Anwendung kommt.
Szenario
Als Anwendungsszenario des fiktiven MQTT-Systems soll besagtes virtuelles Smart-Home-System erstellt werden. In diesem existieren unterschiedlichste Endgeräte, welche mit dem Broker kommunizieren und entsprechende Topics abonnieren bzw. ihre Nachrichten an ein solches Topic senden.
Im Großen und Ganzen werden dazu drei kleine Projekte erstellt, ein Gerätesimulator, welcher die MQTT-Nachrichten der Sensoren und Schalter simuliert, ein MQTT-Broker und das Smart-Home-System, welches die entsprechende Steuerung vornimmt.
Broker selbst gebaut
Da es in diesem Artikel um die Einführung in die Nutzung von MQTT unter Java gehen soll, wird auf den Aufbau eines größeren Services verzichtet und stattdessen mit einem relativ minimalen Starterprojekt begonnen.
Bei diesem Projekt handelt es sich um ein minimales Java-Projekt, welches einige häufig genutzten Abhängigkeiten mitbringt und uns als Startpunkt dienen soll. Es setzt auf Java 17 auf und nutzt Maven als Build-Werkzeug und für das Paketmanagement.
Die drei Projekte sollen die Namen Broker, Devices und System tragen. Im ersten Schritt wird mit dem Broker-Projekt ein Projekt für den MQTT-Broker erstellt. Genutzt wird hierfür Moquette, welcher embedded genutzt werden kann.
Zu Beginn wird die pom.xml des Projektes um eine neue Abhängigkeit erweitert:
<!-- MQTT broker for communication -->
<dependency>
<groupId>io.moquette</groupId>
<artifactId>moquette-broker</artifactId>
<version>0.16</version>
</dependency>
Diese neue Abhängigkeit wird im Dependencies-Block der Datei eingetragen. Damit wurde der Moquette-Broker eingebunden, welcher direkt im Projekt integriert ist und es uns damit ermöglicht seine Funktionalität zu nutzen.
Einbindung
Nachdem die Abhängigkeit eingebunden wurde, kann damit begonnen werden, die Broker-Funktionalität zu nutzen. Dazu wird eine Klasse namens Broker erstellt, in der der Broker mitsamt weiterer Funktionalität gekapselt wird.
Neben der Instanz der Klasse Server, für den MQTT-Broker ist das Herzstück der Klasse die Methode startServer:
public void startServer() {
// Load class path for configuration
IResourceLoader classpathLoader = new ClasspathResourceLoader();
final IConfig classPathConfig = new ResourceLoaderConfig(classpathLoader);
// Start MQTT broker
LOG.info("Start MQTT broker...");
List userHandlers = Collections.singletonList(new PublisherListener());
try {
mqttBroker.startServer(classPathConfig, userHandlers);
} catch (IOException e) {
LOG.error("MQTT broker start failed...");
}
// Publishing topics
LOG.info("Pushing topics...");
List lines = Resources.getLines("config/topics.conf");
for(String line: lines) {
pushTopic(line);
}
LOG.info("Topics pushed...");
}
Bei der Bereitstellung der Konfiguration wird ein InterceptHandler mit dem Namen PublisherListener definiert. Dieser verfügt über keinerlei Funktionalität für die Nutzung des Brokers, sondern dient dazu, entsprechende Meldungen über empfangende Payloads der MQTT-Nachrichten im Log des Brokers anzuzeigen:
INFO org.example.broker.mqtt.PublisherListener - Received on topic: multisensor/temperatur / Content: {"temperature":15.7,"unit":"°C"}
Anschließend wird der Broker gestartet und die Topics werden geladen und an den Broker gepusht, ergo erstellt. Hierfür dient die Methode pushTopic:
public void pushTopic(String topic) {
LOG.info("Push topic: {}", topic);
MqttPublishMessage message = MqttMessageBuilders.publish()
.topicName(topic)
.retained(true)
.qos(MqttQoS.EXACTLY_ONCE)
.payload(Unpooled.copiedBuffer("{}".getBytes(UTF_8))).build();
mqttBroker.internalPublish(message, "INTRLPUB");
}
In dieser Methode wird eine MQTT-Nachricht erstellt und mit dieser Nachricht wird das entsprechende Topic über die interne Publishing-Methode an den Broker versendet.
Konfiguration für den Broker
Damit der Broker erfolgreich hochfahren kann, wird eine entsprechende Konfiguration benötigt. Eine minimale Konfiguration könnte hierbei wie folgt aussehen:
##############################################
# Moquette configuration file.
#
# The syntax is equals to mosquitto.conf
#
##############################################
port 1883
host 0.0.0.0
allow_anonymous true
Neben dem zu nutzenden Port, wird eine IP-Adresse definiert, an welche sich der Broker binden soll, sowie der anonyme Zugriff erlaubt.
Diese Konfiguration wird im Pfad src/main/resources/config des Broker-Projektes in der Datei moquette.conf hinterlegt. Im gleichen Pfad wird ebenfalls eine Datei mit dem Namen topics.conf erstellt.
Diese erhält die Topics, welche der Broker anlegen soll:
bad/deckenlampe
kueche/deckenlampe
wohnzimmer/deckenlampe
multisensor/temperatur
multisensor/bewegung
schalter1/status
schalter2/status
schalter3/status
Shutdown-Handler und Einsprungspunkt
In der main-Methode der Klasse Starter, welche unseren Einsprungspunkt für die Broker-Applikation darstellt, wird die Broker-Klasse instanziiert, der Broker gestartet und ein Shutdown-Hook definiert.
public static void main(String[] args) {
// Init and start broker
LOG.info("Init broker...");
Broker broker = new Broker();
broker.startServer();
// Bind a shutdown hook
LOG.info("Bind shutdown hook...");
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
LOG.info("Stopping broker...");
broker.stopServer();
}));
}
Der Shutdown-Hook dient dazu, es zu ermöglichen, den Broker wieder sauber herunterzufahren. In der Konsole kann dies z. B. durch einen Druck auf die Tasten Strg + C ausgelöst werden. Damit würde der Broker entsprechend gestoppt und die Applikation beendet.
Erster Test
Damit ist der Broker im Grunde, dank der Nutzung von Moquette, fertiggestellt und kann einem ersten Test unterzogen werden.
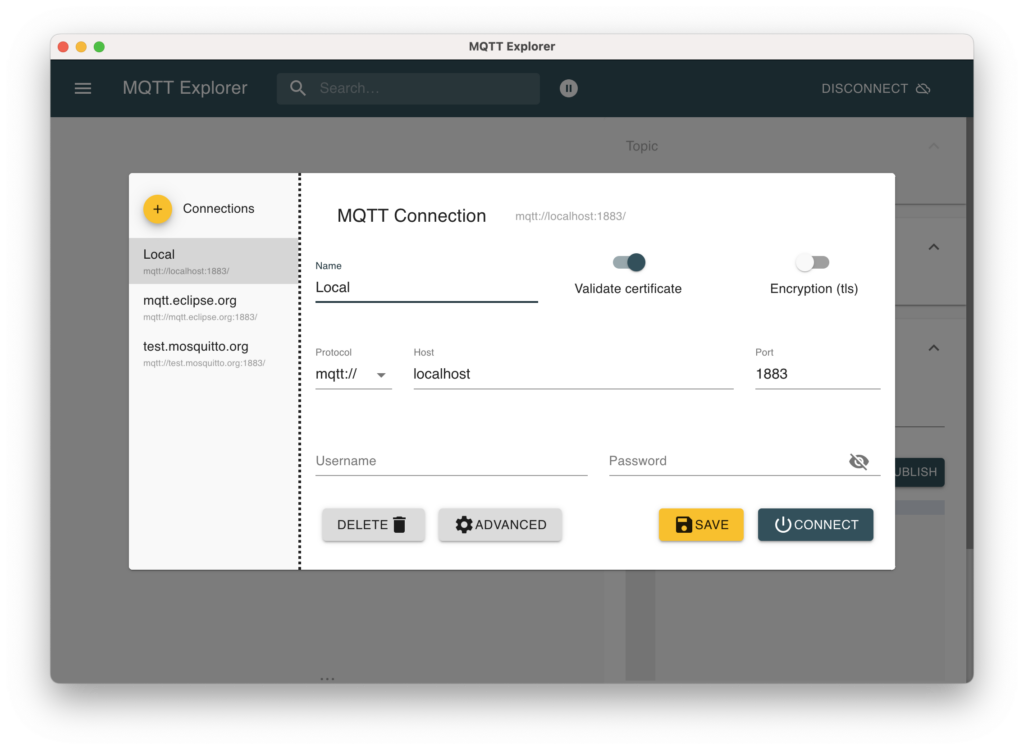
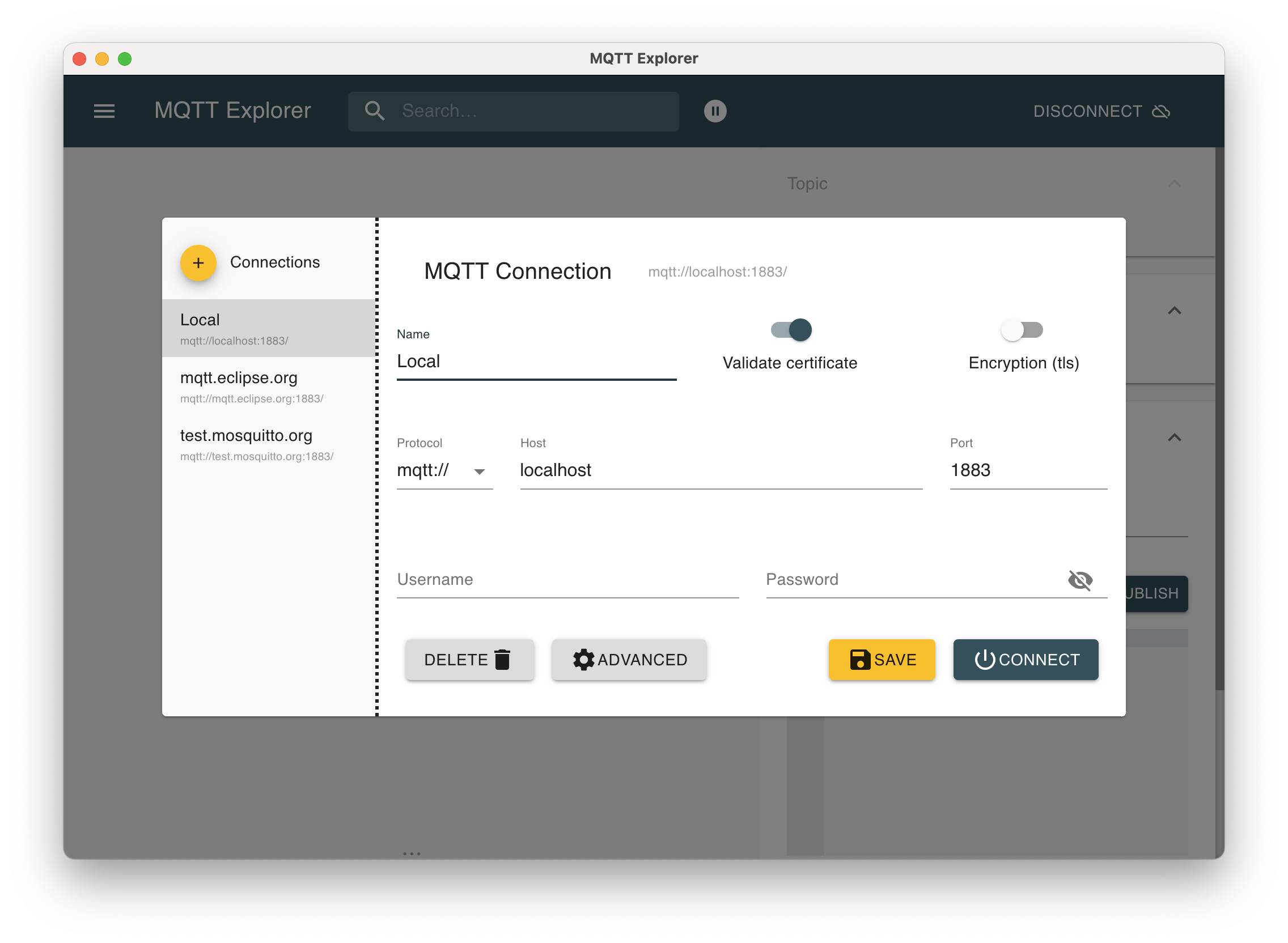
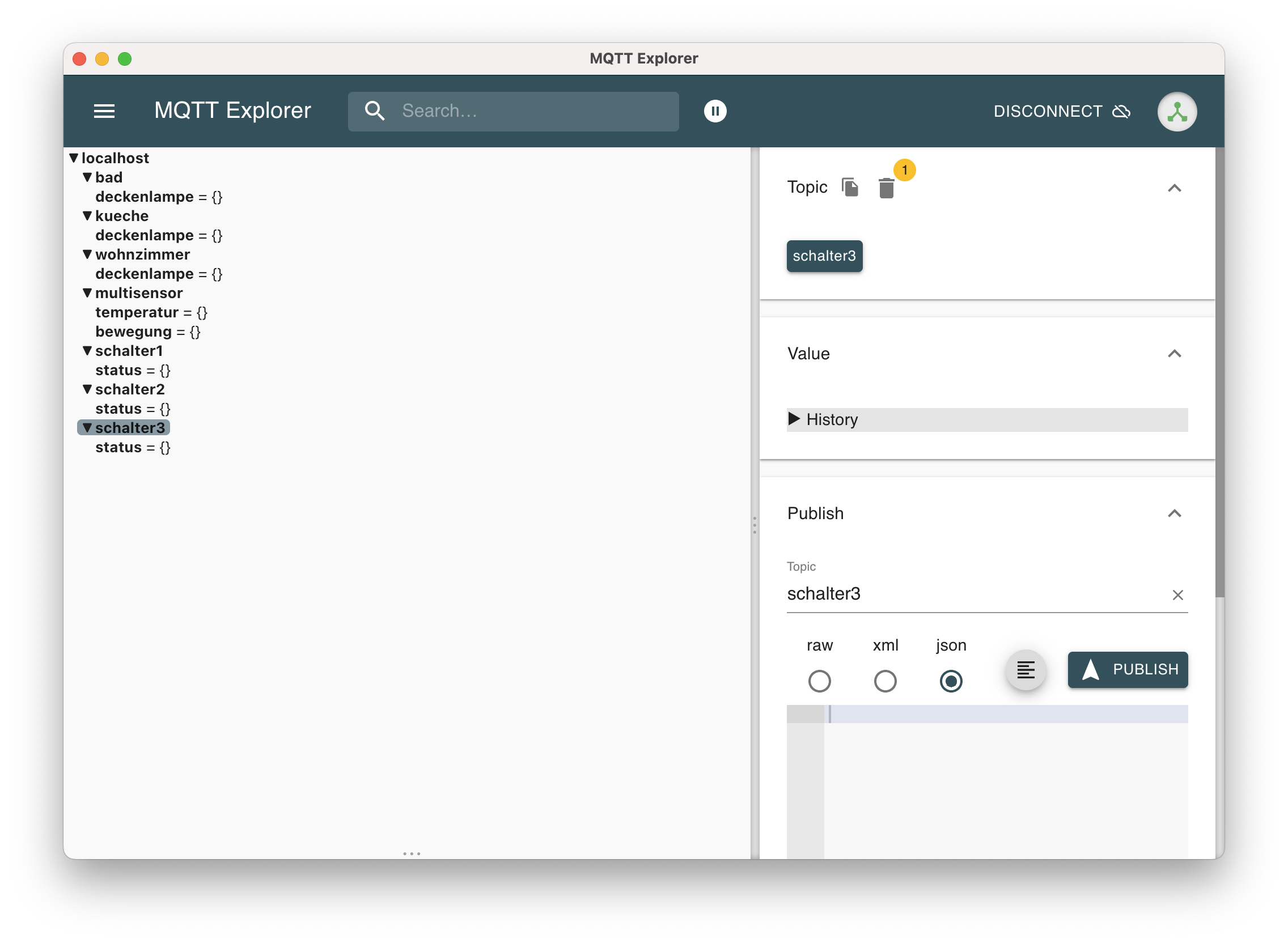
Über MQTT Explorer wird sich mit dem Broker verbunden
Für diesen Test kann MQTT Explorer verwendet werden, um einen ersten Request per MQTT zum neuen System zu senden. Nachdem sich mit dem Broker über MQTT-Explorer verbunden wurde, können die Topics in diesem eingesehen werden.
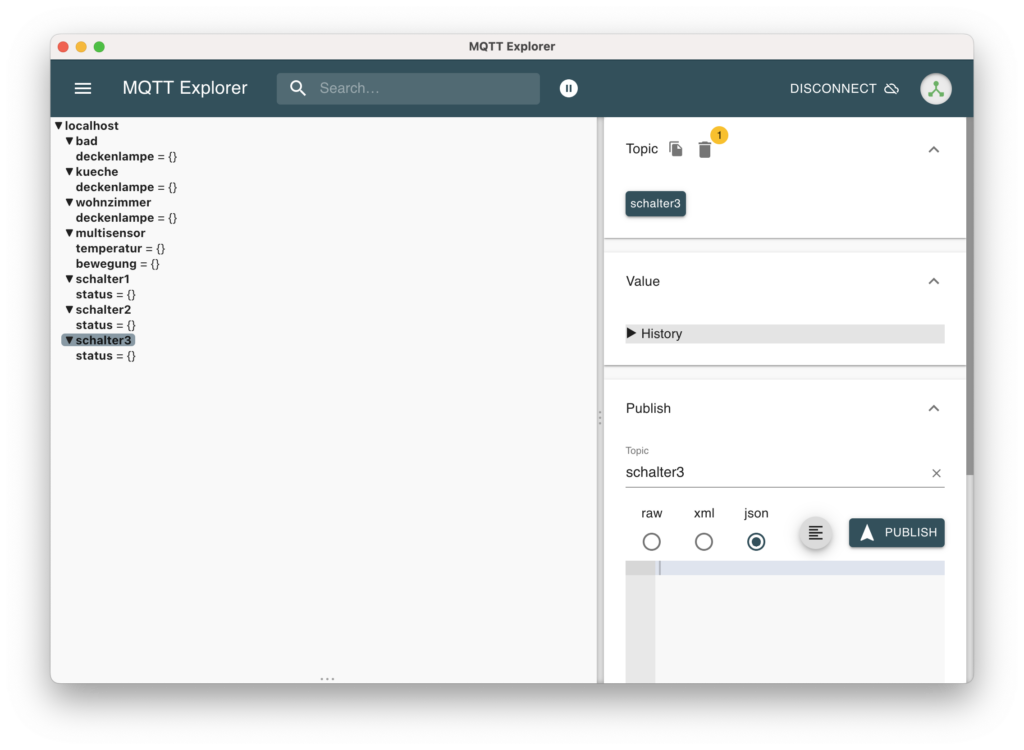
Nach der erfolgreichen Verbindung können die Topics des Brokers eingesehen werden
Auch lassen sich über den MQTT Explorer Nachrichten an die entsprechenden Topics senden. Allerdings ist dies wenig zielführend, da im Moment, bis auf MQTT Explorer, niemand die Topics abonniert.
Gerätesimulation
Damit die Topics, welche der Broker bereitstellt bespielt werden, soll im nächsten Schritt ein Projekt aufgesetzt werden, welches dies bewerkstelligt.
Im Rahmen des Szenarios, einer Smart-Home-Umgebung, werden hierbei einige Schalter und ein Multisensor simuliert. Im Einstiegspunkt des Projektes Devices sieht, das Ganze wie folgt aus:
public static void main(String[] args) throws InterruptedException {
LOG.info("Init Dummy device simulator...");
// Create list of Dummy devices
List devices = new ArrayList<>();
devices.add(new Multisensor("multisensor/bewegung", "multisensor/temperatur"));
devices.add(new Switch("schalter1/status"));
devices.add(new Switch("schalter2/status"));
devices.add(new Switch("schalter3/status"));
while(true) {
LOG.info("Send dummy data...");
for(Device device: devices) {
device.sendData();
}
// Sleep 15 seconds
Thread.sleep(15000);
}
}
Im Grunde werde einige virtuelle Geräte definiert, welche entsprechend mit ihren Topics verbunden werden und an diese Topics jeweils eine Payload senden sollen. Dies geschieht für die Simulation alle 15 Sekunden.
Schon an dieser Stelle fällt auf, dass die Schalter hier nur ein Topic benötigen, während an den Multisensor mehrere Topics übergeben werden.
Hier wird sich der hierarchische Aufbau der Topics in MQTT zunutze gemacht. Technisch wäre es kein Problem nur das Topic multisensor zu definieren und an dieses eine entsprechende Payload auszuliefern:
{
motion: true,
temperature: 24.6,
unit: "°C"
}
Stattdessen werden in diesem Szenario die Topics:
multisensor/temperatur
multisensor/bewegung
definiert. Dadurch können Applikationen genau auf die Topics zugreifen, die sie interessieren. So kann ein Gerät, welches mehrere Funktionalitäten vereint, diese über separate Topics einzeln zur Verfügung stellen.
In der Praxis sollte sich das Design der Topics an den Anwendungsfällen orientieren. Werden die Daten für Bewegung und Temperatur immer in Verbindung benötigt, so könnten sie auch über ein Topic ausgeliefert werden.
MQTT-Client unter Java
Damit die virtuellen Geräte ihre Daten an den Broker senden können, wird ein entsprechender MQTT-Client benötigt. Auch hier ist die Auswahl groß.
In diesem Beispiel wird der HiveMQ-Client genutzt, da er neben dem etablierten MQTT-Protokoll in Version 3 auch die relative neue Version 5 unterstützt. Nachdem die entsprechende Abhängigkeit in der pom.xml definiert wurde:
<!-- MQTT-Client -->
<dependency>
<groupId>com.hivemq</groupId>
<artifactId>hivemq-mqtt-client</artifactId>
<version>1.3.0</version>
</dependency>
kann der Client genutzt werden. Der Client unterstützt blockierende und asynchrone APIs. Im Falle der Gerätesimulationen wird auf die blockierende API mit der MQTT-Version 3 gesetzt.
Die simulierten Geräte implementieren ein Interface mit dem Namen Device, welches eine entsprechende Methode mit dem Namen sendData vorschreibt. In der Klasse, welche für Schalter zuständig ist, ist diese wie folgt implementiert:
public void sendData() {
if (client == null) {
// Create MQTT client
client = Mqtt3Client.builder()
.identifier(UUID.randomUUID().toString())
.serverHost("localhost")
.buildBlocking();
client.connect();
}
client.publishWith()
.topic(topic)
.qos(MqttQos.AT_LEAST_ONCE)
.payload(getSwitchPayload().getBytes())
.send();
}
In der Theorie könnte der Client für alle Geräte global definiert werden, dies wird hier aber aus einer Erwägung, auf welche später noch eingegangen wird, nicht getan. Stattdessen verfügt jedes simulierte Gerät über einen einzelnen MQTT-Client.
Dieser wird beim erstmaligen Aufruf instanziiert und verbindet sich anschließend mit dem entsprechenden Server, welcher auf Localhost lauscht. Anschließend wird mit der publishWith-Methode des Clients eine Nachricht erzeugt, diese mit einem Topic und einer Quality of Service-Stufe versehen.
MQTT beherrscht drei verschiedene Stufen des Quality of Service (QoS). Stufe 0 ist vom Modell her Fire-and-Forget; die Nachricht wird einmal versendet und danach vom Broker vergessen. Ob sie ankommt, ist auf dieser QoS-Stufe nicht relevant. Bei Stufe 1 garantiert der Broker, dass die Nachricht mindestens einmal zugestellt wird, sie kann aber auch mehrfach bei den Clients ankommen. Stufe 2 hingegen garantiert, dass die Nachricht exakt einmal ankommt. Bei den QoS-Stufen muss beachtet werden, dass jede Stufe mehr Overhead erzeugt als die vorherige Stufe.
Nachdem die Payload erzeugt und übergeben wurde, wird die entsprechende Nachricht an den Broker und dort an das gewählte Topic versendet. Die Payload ist in diesem Fall eine JSON-Struktur:
{
"enabled":false
}
In der Payload einer MQTT-Nachricht können beliebige Daten versendet werden, von Text bis zu Binärdaten. Grundsätzlich sollten hier die Limits von MQTT berücksichtigt werden, so ist die Länge eines Topics auf 64 Kilobyte beschränkt und die Länge der Payload ist auf 256 Megabyte beschränkt.
Dabei handelt sich allerdings nur um theoretische Werte, gemäß der Spezifikation, welche im jeweils gewählten Broker bzw. dessen Einstellungen abweichen könnten. Die Payload sollte hier nach der Faustregel, so viel wie nötig, so wenig wie möglich designt werden.
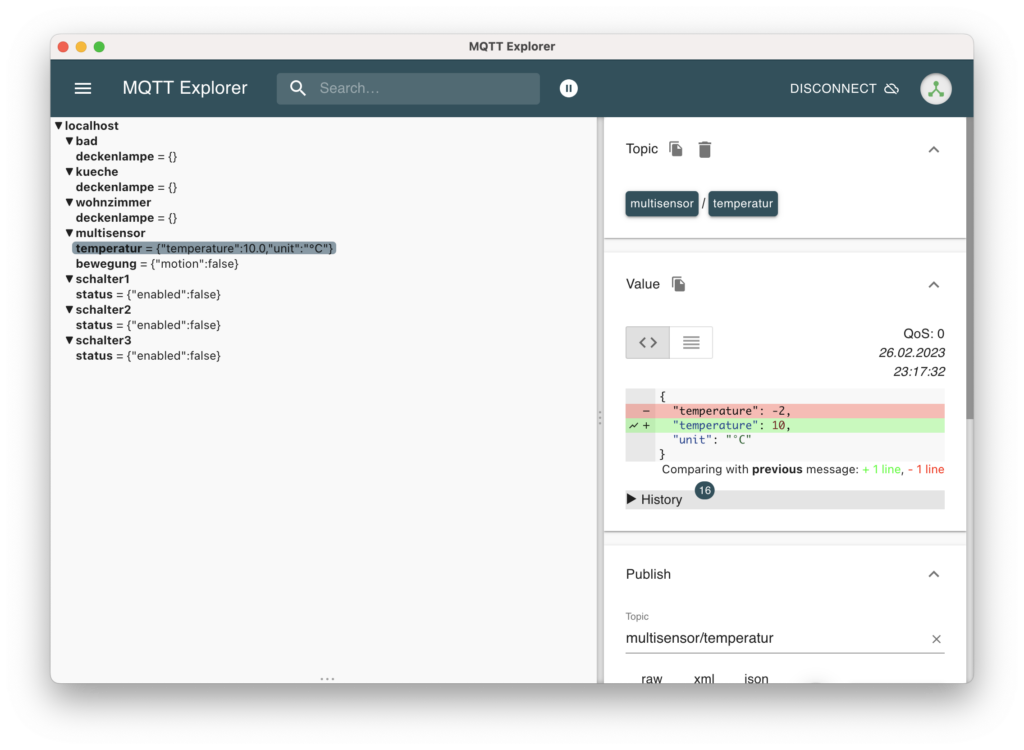
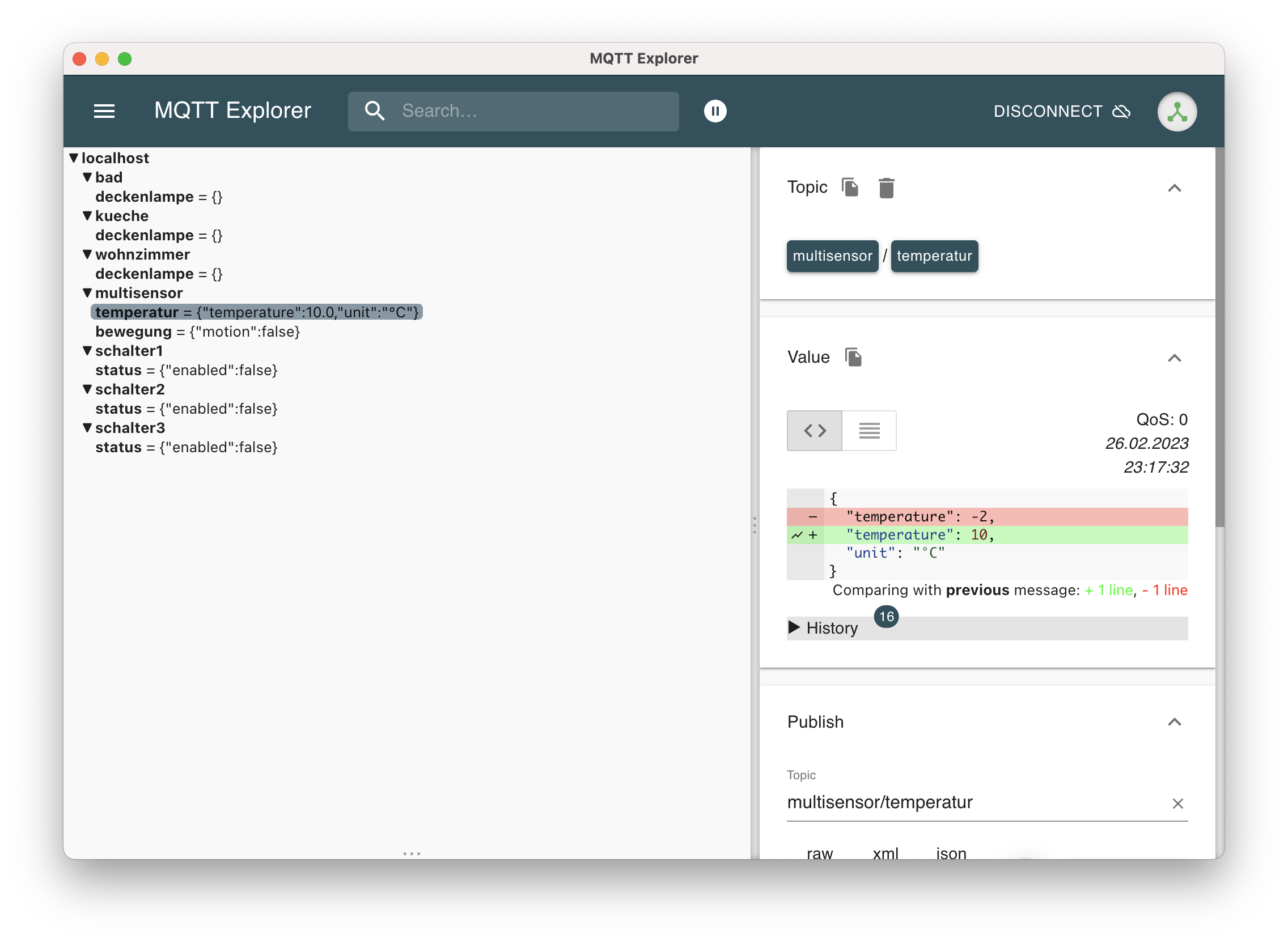
Die Topics werden von der Gerätesimulation befüllt
Damit ist die Gerätesimulation implementiert und die entsprechenden Topics werden nun mit sinnvollen Werten befüllt. Damit wird der Broker zwar genutzt, aber die entsprechenden Topics werden bisher nur geschrieben, niemand abonniert diese bisher.
Smart-Home-System
Im letzten Schritt soll das Smart-Home-System implementiert werden. Dieses abonniert Topics und führt basierend auf diesen Topics Aktionen durch. Während diese bei einem praxisnahen System konfigurierbar wären, sind sie in diesem Beispiel fest kodiert.
Auch in diesem Projekt wird wieder der HiveMQ-Client genutzt und entsprechend als Abhängigkeit dem Projekt hinzugefügt. Nachdem dort der Client erstellt wurde, kann die Verbindung aufgebaut werden:
client = Mqtt3Client.builder()
.identifier(UUID.randomUUID().toString())
.serverHost("localhost")
.buildBlocking();
// Connect to MQTT server
client.connect();
Anschließend werden bestimmte Topics abonniert, das bedeutet, die Nachrichten der Topics werden vom Broker empfangen und sollen anschließend verarbeitet werden:
// Subscribe to topics
client.toAsync().subscribeWith()
.topicFilter("schalter1/status")
.qos(MqttQos.AT_LEAST_ONCE)
.callback(Starter::switchMessageReceived)
.send();
client.toAsync().subscribeWith()
.topicFilter("schalter2/status")
.qos(MqttQos.AT_LEAST_ONCE)
.callback(Starter::switchMessageReceived)
.send();
client.toAsync().subscribeWith()
.topicFilter("schalter3/status")
.qos(MqttQos.AT_LEAST_ONCE)
.callback(Starter::switchMessageReceived)
.send();
client.toAsync().subscribeWith()
.topicFilter("multisensor/bewegung")
.qos(MqttQos.AT_LEAST_ONCE)
.callback(Starter::multisensorMotionMessageReceived)
.send();
In diesem Fall sind es die Topics für die drei Schalter sowie das Topic für die Bewegung im Multisensor. Jedem Topic, welches abonniert wird, wird eine entsprechende Callback-Methode mitgegeben. Für den Multisensor wäre dies z. B. der Callback zur Methode multisensorMotionMessageReceived:
private static void multisensorMotionMessageReceived(Mqtt3Publish mqtt3Publish) {
LOG.info("Receive message: {}", mqtt3Publish);
String payload = getPayloadAsString(mqtt3Publish.getPayload().get());
LOG.info("Payload: {}", payload);
if (payload.length() <= 2) { // Ignore empty JSONs, from publishing topic
return;
}
Motion motion = new Gson().fromJson(payload, Motion.class);
client.publishWith()
.topic("bad/deckenlampe")
.qos(MqttQos.AT_LEAST_ONCE)
.payload(getLampPayload(motion.motion).getBytes())
.send();
}
In dieser Callback-Methode wird die Payload mittels der Methode getPayloadAsString entpackt:
private static String getPayloadAsString(ByteBuffer buffer) {
byte[] payload = new byte[buffer.remaining()];
buffer.get(payload);
return new String(payload, StandardCharsets.UTF_8);
}
Hier wird der ByteBuffer genauer gesagt sein Inhalt, welcher vom Client geliefert wird, in einen String konvertiert. Anschließend wird aus der Payload über die Serialisierungs- und Deserialisierung-Bibliothek Gson, ein Java-Objekt aus der Payload erzeugt und mit diesem weitergearbeitet.
In diesem Beispiel wird der Wert des Bewegungsmelders weitergeleitet an den Topic bad/deckenlampe, um damit die Deckenlampe zu schalten.
Bei den Schaltern wird ähnlich verfahren, allerdings wird hier für alle Schalter die gleiche Callback-Methode genutzt:
private static void switchMessageReceived(Mqtt3Publish mqtt3Publish) {
LOG.info("Receive message: {}", mqtt3Publish);
String payload = getPayloadAsString(mqtt3Publish.getPayload().get());
LOG.info("Payload: {}", payload);
if (payload.length() <= 2) {// Ignore empty JSONs
return;
}
Switch switchStatus = new Gson().fromJson(payload, Switch.class);
// Define link between switch and lamp
String targetTopic;
switch (mqtt3Publish.getTopic().toString()) {
case "schalter1/status" -> {
targetTopic = "bad/deckenlampe";
}
case "schalter2/status" -> {
targetTopic = "kueche/deckenlampe";
}
case "schalter3/status" -> {
targetTopic = "wohnzimmer/deckenlampe";
}
default -> {
LOG.info("Ignore unknown topic...");
return;
}
}
client.publishWith()
.topic(targetTopic)
.qos(MqttQos.AT_LEAST_ONCE)
.payload(getLampPayload(switchStatus.enabled).getBytes())
.send();
}
Stattdessen wird in der Methode das Topic extrahiert und anhand dieses eine Entscheidung zum passend verknüpften Zieltopic getroffen und an dieses eine neue Nachricht geschickt.
Der letzte Wille
Die Geräte, wie Schalter und der Multisensor, senden Nachrichten an den MQTT-Broker und diese Topics werden von unserem Smart-Home-System abonniert.
Nun könnte in einem beispielhaften Fall einer der Schalter die Nachricht an das Topic senden, dass der Schalter aktiviert wurde. Damit würde dann über das Smart-Home-System die entsprechende Lampe eingeschaltet werden.
Wenn dieser Schalter jedoch keine Verbindung mehr mit dem MQTT-Broker aufnehmen kann oder schlicht und ergreifend defekt ist, würde das Licht in diesem Szenario immer aktiv blieben.
Hier bietet MQTT, ein Feature, das sogenannte Testament bzw. den letzten Willen. Meldet sich ein Gerät bzw. allgemeiner ein Client beim Broker an, kann dieser ein solches Testament hinterlegen. Infolgedessen erhielten die virtuellen Geräte im Gerätesimulator jeweils ihren eigenen Client. Im Kontext der Switch-Klasse im Gerätesimulator würde dies wie folgt aussehen:
// Create MQTT client
client = Mqtt3Client.builder()
.identifier(UUID.randomUUID().toString())
.serverHost("localhost")
// Last will
.willPublish()
.topic(topic)
.payload(getSwitchPayload(false).getBytes())
.applyWillPublish()
.buildBlocking();
client.connect();
Beim Testament wird ein Topic gesetzt und eine entsprechende Payload. Im Fall des Schalters würde somit die Payload, welche signalisiert, dass der Schalter abgeschaltet wurde, an die Clients geschickt, welche das entsprechende Topic abonniert haben.
Das Testament wird hierbei nicht bei einer normalen und gewünschten Trennung der Verbindung gesendet, sondern nur im Falle einer ungewollten Trennung des Clients.
Diese kann auftreten, wenn der Broker nicht mehr mit dem Client kommunizieren kann oder die Netzwerkverbindung getrennt wird, bevor eine entsprechende DISCONNECT-Nachricht beim Broker eingetroffen ist.
Was in dem Beispielszenario eher geringere Auswirkungen hat, kann in industriellen Anwendungen von Belang sein, da hier über das Testament Geräte, im Falle von Problemen, in definierte Zustände gebracht werden können.
Jenseits von Java
Nachdem bisher alle Beispiele für das Smart-Home-System in Java umgesetzt worden sind, kann das MQTT-Protokoll auch auf vielen anderen Geräten und Sprachen genutzt werden.
So könnte z. B. eines der virtuellen Geräte mit einem Arduino nachgebaut und dort die Daten des Gerätes per MQTT an den Broker gesendet werden. Hierfür stehen für unterschiedlichste Sprachen und Umgebungen entsprechende Bibliotheken zur Verfügung.
MQTT 5
Daneben wurde die etablierte Version 3 von MQTT in diesem Beispiel genutzt, da Moquette aktuell noch an einer Umsetzung für MQTT 5 arbeitet. 2019 wurde die Spezifikation für die Version 5 von MQTT ratifiziert und sollte, wenn möglich, in neuen Projekten genutzt werden.
In die Version 5 sind Verbesserungen eingeflossen, die unter anderem für eine Verbesserung bei der Skalierbarkeit sorgen, der Erkennung der Fähigkeiten des Servers dienen, sowie Erweiterungsmechanismen im Rahmen des Protokolls beinhalten.
Sollte es sich also anbieten, sollten Projekte idealerweise mit der Unterstützung für MQTT in Version 5 begonnen werden.
Retained Messages
Auch könnte das gezeigte System um weitere Möglichkeiten von MQTT erweitert werden. Es ist es z. B. möglich vom Broker eine Nachricht zu erhalten, sobald ein Topic abonniert wird.
So könnte für den Multisensor die Temperatur als Retained Message bereitgestellt werden. Damit erhält der Client, welcher das Topic abonniert, sofort einen Status für das entsprechende Topic und muss nicht erst auf eine neue Meldung des Temperatursensors warten.
Erstellt wird eine solche zurückbehaltende Nachricht, indem bei der Erstellung der Nachricht, das Retain-Flag gesetzt wird:
client.publishWith()
.topic(temperatureTopic)
.retain(true)
.qos(MqttQos.AT_LEAST_ONCE)
.payload(getTemperaturePayload().getBytes())
.send();
Wichtig ist es zu beachten, dass immer nur eine Retained Message pro Topic erlaubt ist und eine neue Nachricht mit dem Retain-Flag eine alte Nachricht ersetzt.
Fazit
Im Rahmen eines fiktiven Beispiels wurde ein Broker aufgesetzt und im Zusammenspiel mit virtuellen Geräten ein minimales Smart-Home-System implementiert. Damit wurde die Zusammenarbeit zwischen den Subscribern und den Publishern in einem MQTT-System gezeigt. Der Quellcode der kompletten Projekte kann über GitHub eingesehen und ausprobiert werden.
Allerdings ist MQTT nicht auf solche Anwendungsszenarien beschränkt. So kann es z. B. auch als Event-System genutzt werden, um z. B. Exporte zu triggern, welche, sobald auf dem Topic zu Einlieferung neue Daten auftauchen, diese in andere Formate exportieren und wiederum eine entsprechende Nachricht versenden.
Auch sind Sicherheitsaspekte in diesem Szenario nicht weiter bedacht. So können z. B. neue Topics von jedem Client angelegt werden. Daneben bietet MQTT noch weitere Features, welche je nach Einsatzzweck genutzt werden können. Dazu gehören persistente Sessions, welche unter anderem verhindern, dass Nachrichten verloren gehen, wenn der Client zum Zeitpunkt der Nachricht nicht mit dem Broker verbunden war.
MQTT bzw. der nachrichtenbasierende Workflow kann genutzt werden, um Systeme voneinander zu entkoppeln und bietet für zukünftige Erweiterungen Platz. Je nach Anwendungszweck sollten die Möglichkeiten von MQTT möglichst sinnvoll in eigenen Projekten genutzt werden.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.