Bei der Entwicklung von Software wird in den meisten Fällen ein wie auch immer gearteter Editor bzw. eine IDE genutzt. Innerhalb dieser IDE ist zur Darstellung des Quelltextes eine Monospace-Schriftart gesetzt. In einer solchen Schriftart sind alle Zeichen gleich breit. In folgendem Beispiel wird das deutlich:
www iii
Sowohl das w als auch das i haben in einer Monospace-Schriftart die gleiche Breite. Bei der Entwicklung ist dies natürlich sehr praktisch, da dadurch der Quelltext an Übersichtlichkeit gewinnt. Jede IDE liefert in der Voreinstellung eine bestimmte Monospace-Schriftart mit. Soll diese Voreinstellung geändert werden, so findet sich eine große Auswahl an freien Monospace-Schriftarten im Netz. Die Programming Fonts-App erleichtert die Auswahl der passenden Schriftart.
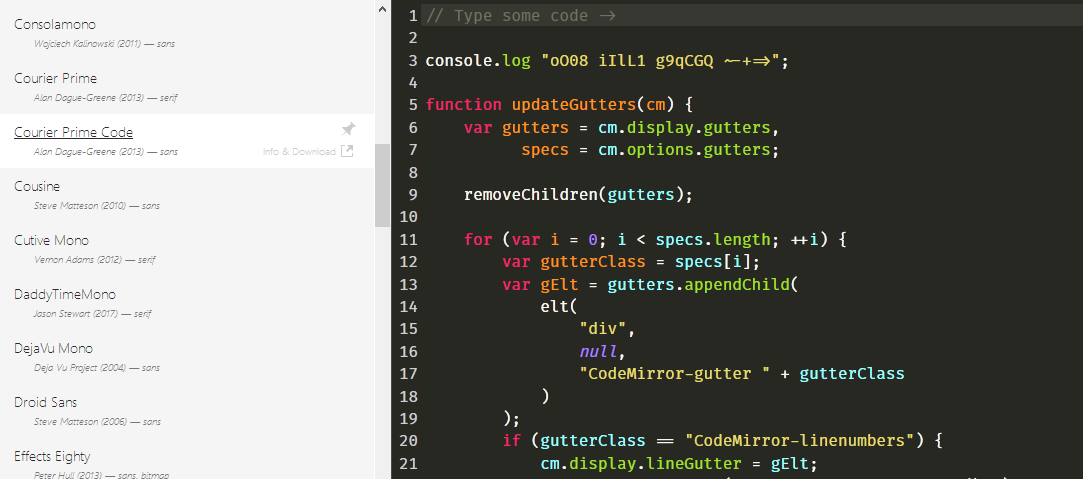
In der App konnten die unterschiedlichen Schriftarten ausprobiert werden
In dieser App können die unterschiedlichen Fonts ausgewählt werden und in einem Editor schnell auf ihre Eignung geprüft werden. Der Quelltext der App ist auf GitHub zu finden. Lizenziert ist das Ganze unter der MIT-Lizenz und damit freie Software.