Wer Text schreibt, kann dies mit unterschiedlichen Werkzeugen bewerkstelligen, vom WYSIWYG-Editor à la Word bis hin zum reinen Texteditor. Jede dieser Varianten wartet mit unterschiedlichen Vor- und Nachteilen auf.
Daneben hat in den vergangenen Jahren die Nutzung der Auszeichnungssprache Markdown zugenommen und diese an Beliebtheit gewonnen. Im Gegensatz zum What You See Is What You Get-Ansatz trennt Markdown die Struktur und Formatierung vom endgültigen Erscheinungsbild, indem es die Bedeutung des Inhaltes betont. Trotzdem lässt sich ein solcher Markdown-Text auch ohne weitere Kenntnisse problemlos lesen:
# Überschrift
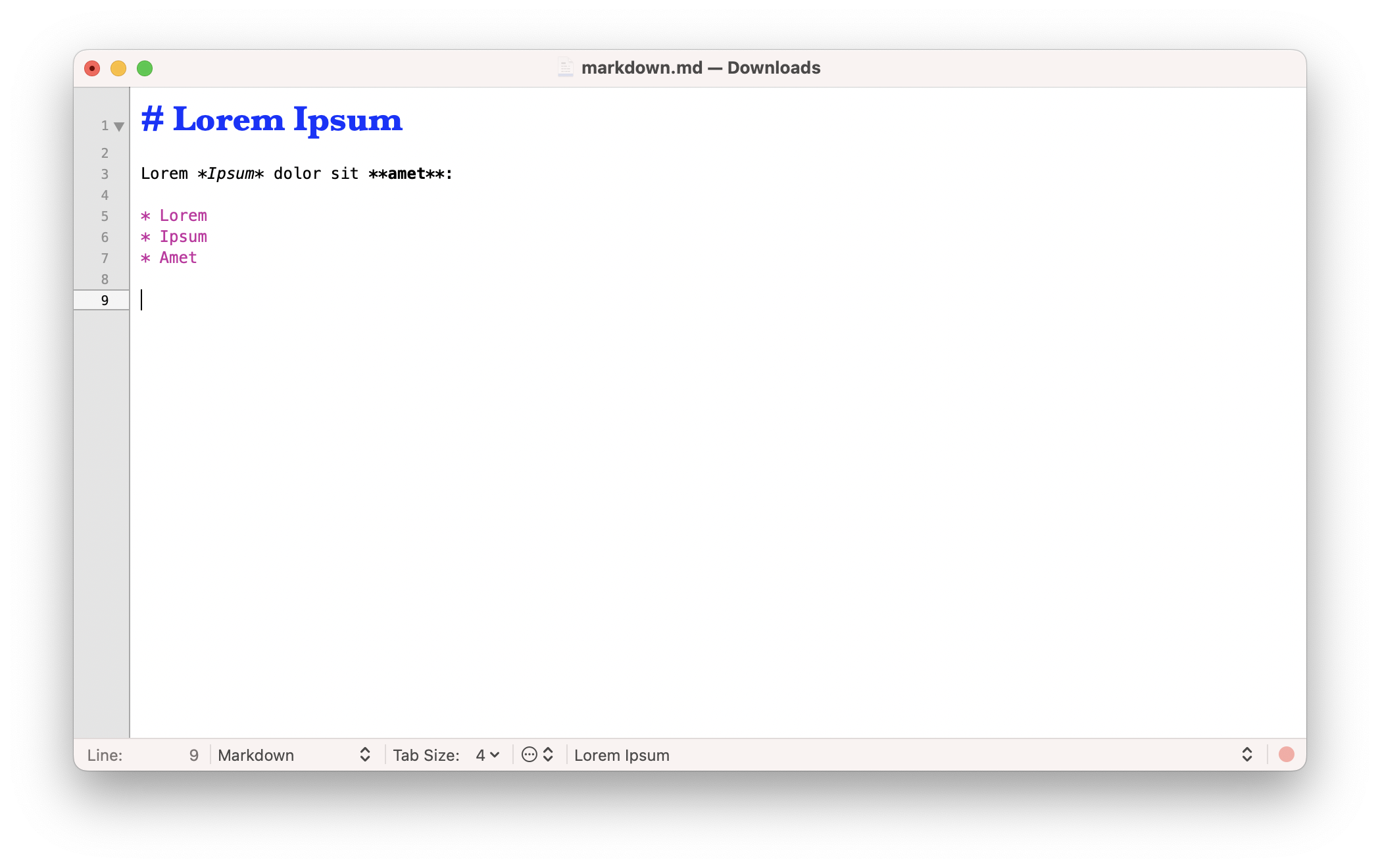
Lorem *ipsum dolor sit amet*, consectetur, adipisci
velit, ut aspernatur labore ad dolores quidem eos
architecto pariatur. Dolor asperiores commodi corrupti,
vel dignissimos velit, **labore aliquip voluptatem**:
* Lorem
* Ipsum
* dolor
## Noch eine Überschrift
Lorem ipsum dolor sit amet:
> Sequi quasi mollit dolor cupiditate in.
Somit stört Markdown den Lesefluss nicht und enthält doch Informationen über die Struktur des Dokumentes. Doch wie genau wird Markdown geschrieben, genutzt und wo finden sich seine Einsatzgebiete?
Auszeichnungssprachen
Markdown wird den Auszeichnungssprachen zugeordnet. Bei solchen Auszeichnungssprachen (engl. Markup language), handelt es sich um eine Sprache, die zur Strukturierung, Formatierung und Kennzeichnung von Texten und Daten verwendet wird.
Eine solche Sprache ermöglicht es, Textinhalte mit zusätzlichen Informationen zu versehen, die deren Struktur und Darstellung definieren. Diese zusätzlichen Informationen werden in Form von Tags oder Markierungen eingefügt, die wiederum von anderen Programmen, z. B. Browsern interpretiert werden können.
Zu den bekanntesten Auszeichnungssprachen gehört HTML:
<html>
<head>
<title>Beispielseite</title>
</head>
<body>
<h1>Lorem Ipsum</h1>
Lorem ipsum dolor sit amet.
</body>
</html>
Geschichte
Historisch gesehen geht die Entwicklung von Markdown auf das Jahr 2004 zurück, in welchem John Gruber und Aaron Swartz diese Entwicklung anstießen. Aaron Swartz hatte vorher mit atx eine eigene Auszeichnungssprache definiert, aus der unter anderem die Überschriften-Semantik in Markdown übernommen wurde.
Die Hauptidee hinter Markdown war es, eine einfache Möglichkeit zu schaffen, Text in HTML zu konvertieren, ohne dass der Nutzer umfangreiche HTML-Kenntnisse benötigt. Gruber und Swartz wollten damit eine Sprache schaffen, die leicht zu lesen und zu schreiben ist. John Gruber fasste dies mit der Aussage:
Markdown is intended to be as easy-to-read and easy-to-write as is feasible.
in der ursprünglichen Markdown-Spezifikation zusammen. Inspiriert wurde die Syntax und der Aufbau von Markdown von bereits vorher verwendeten Konventionen, wie der Textauszeichnung in E-Mails und anderen Auszeichnungssprachen wie Textile.
Neben der ursprünglichen Spezifikation wurde auch ein Perl-Skript mit dem Namen Markdown.pl entwickelt, welches Markdown in HTML konvertieren konnte. Das Skript und die dazugehörige Dokumentation wurden unter der 3-Klausel BSD-Lizenz veröffentlicht und sind damit freie Software. Die einfache Syntax und die Möglichkeit, Markdown-Dateien in verschiedenen Umgebungen zu verwenden, machten es schnell populär.
Ein wesentlicher Aspekt von Markdown ist seine Lesbarkeit. Die Syntax ist so gestaltet, dass der Text auch dann lesbar bleibt, wenn er nicht in HTML umgewandelt wird. Dies unterscheidet Markdown von anderen Auszeichnungssprachen wie LaTeX oder HTML, die ohne entsprechende Rendering-Tools oft schwer zu lesen sind. Diese Eigenschaft machte Markdown besonders attraktiv für Blogger, Autoren und Entwickler, die ihre Texte sowohl in Rohform als auch in gerenderter Form verwenden wollten.
Mit der Zeit entwickelte sich Markdown zu einem De-facto-Standard für Textformatierung im Web. Viele Blogging-Plattformen, Content-Management-Systeme und Plattformen wie GitHub begannen, Markdown zu unterstützen.
GitHub spielte eine entscheidende Rolle bei der Popularisierung von Markdown, indem es die Sprache für die Dokumentation von Projekten und das Schreiben von README-Dateien bzw. README.md-Dateien verwendete. Dies führte dazu, dass immer mehr Entwickler und Autoren Markdown in ihren Arbeitsabläufen integrierten.
Trotz seiner Popularität gab es keine offizielle Standardisierung von Markdown, was zu verschiedenen Dialekten und Implementierungen führte. Dadurch entstanden Kompatibilitätsprobleme, da verschiedene Systeme und Tools unterschiedliche Varianten von Markdown unterstützten. Um diesem Problem zu begegnen, wurde 2014 das Projekt CommonMark ins Leben gerufen. CommonMark zielt darauf ab, eine einheitliche Spezifikation für Markdown zu schaffen und so die Kompatibilität zwischen verschiedenen Implementierungen zu verbessern.
Nicht unerheblich für den Erfolg von Markdown war die Entwicklung von entsprechenden Konvertern. Software wie Pandoc ermöglichte es Benutzern, Markdown-Dokumente in verschiedene Formate zu konvertieren. Diese Werkzeuge erweiterten die Einsatzmöglichkeiten von Markdown erheblich, indem sie den Export von Markdown-Dokumenten in PDF-, Word- und andere Formate ermöglichten.
Die Flexibilität von Markdown führte zu seiner Verwendung in anderen Bereichen, wie z. B. in wissenschaftlichen Publikationen, technischen Dokumentationen und sogar in Präsentationen. Durch die Integration von Erweiterungen wie MathJax für mathematische Formeln konnte Markdown an die spezifischen Bedürfnisse verschiedener Benutzergruppen angepasst werden.
Syntax
Grundsätzlich handelt es sich um bei einem Markdown-Dokument um ein normales Textdokument, welches über verschiedene Zeichen strukturiert wird. So befinden sich im folgenden Dokument eine Überschrift der ersten Ebene und ein Text, in welchem ein Wort kursiv gestellt wird:
# Lorem Ipsum
Lorem Ipsum dolor *sit* amet.
In Markdown existieren verschiedene Arten von Blöcken, die zur Strukturierung und Formatierung von Text verwendet werden. Grundlegend können Blöcke in Markdown in zwei Typen unterteilt werden: Containerblöcke und Blattblöcke (engl. leaf blocks).
Containerblöcke dienen als übergeordnete Strukturen, die mehrere Elemente umfassen können. Blattblöcke hingegen sind Blöcke, die keine anderen Blöcke enthalten können. Sie sind die „Blätter“ der Dokumentstruktur und enthalten den eigentlichen Inhalt.
Zu den Containerblöcken gehören Absätze, Blockzitate, Listen und Codeblöcke. Zu den Blattblöcken gehören Überschriften, horizontale Linien, Inline-Code und HTML-Blöcke.
Eines der einfachsten Elemente in Markdown ist der Absatz. Dieser definiert sich als eine Ansammlung von Zeilen. Getrennt werden diese Absätze durch eine oder mehrere leere Zeilen. In der Denkweise von Markdown bedeutet dies, dass wenn die Zeile leer aussieht, sie leer ist. So würde eine Zeile gefüllt mit Leerzeichen oder Tabs als leer interpretiert werden.
Ein grundlegendes Merkmal von Markdown ist die Verwendung von Klartextzeichen, um Formatierungen zu definieren. Überschriften können etwa durch Voranstellen einer Raute erstellt werden.
Mit einer einzelnen Raute kann so eine Überschrift der ersten Ebene, mit zwei Rauten eine Überschrift der zweiten Ebene usw. definiert werden. Bei einer Konvertierung in HTML würde hierbei die Tags <h1> und <h2> generiert werden:
# Überschrift der ersten Ebene
## Überschrift der zweiten Ebene
### Überschrift der dritten Ebene
Diese Art der Überschriften wird auch atx-Überschrift genannt. Daneben werden in der ursprünglichen Markdown-Spezifikation auch Setext-Überschriften definiert. Setext-Überschriften werden durch das Unterstreichen des Überschriftentextes erzeugt:
Überschrift der ersten Ebene
============================
Überschrift der zweiten Ebene
-----------------------------
In der Praxis kommt heute zumeist die atx-Variante zum Tragen, mit welcher bis zu sechs Ebenen definiert werden können. Weniger bekannt ist, dass diese Art der Überschrift auch geschlossen existieren darf:
# Überschrift (Ebene 1) #
Lorem Ipsum dolor sit amet.
## Überschrift (Ebene 2) ##
Die Nutzung der schließenden Rauten ist hierbei rein kosmetischer Natur und hat sonst keinerlei Auswirkungen. Allerdings sollte beachtet werden, dass diese geschlossene Variante nur selten genutzt und von vielen Markdown-kompatiblen Werkzeugen in dieser Form nicht unterstützt wird.
Da Markdown ursprünglich zur Konvertierung in HTML gedacht war, dieses aber nicht ersetzen sollte, verfügt es über die Möglichkeit Inline-HTML zu nutzen:
# Hypergraphen
Ein Hypergraph ist eine Verallgemeinerung eines Graphen.
# Begrifflichkeiten
Folgende Begrifflichkeiten definieren einen solchen Graphen:
<table>
<tr>
<th>Eigenschaft</th>
<th>Beschreibung</th>
</tr>
<tr>
<td>Knoten</td>
<td>Die grundlegenden Einheiten eines Hypergraphen, ähnlich den Knoten in einem einfachen Graphen.</td>
</tr>
<tr>
<td>Kanten</td>
<td>Kanten in einem Hypergraphen, auch Hyperkanten genannt, können mehr als zwei Knoten verbinden.</td>
</tr>
</table>
Neben Hypergraphen ...
Sollen in Markdown Zeichen genutzt werden, welche durch die Markdown-Syntax vorbelegt sind, so müssen diese Zeichen maskiert werden. Dies geschieht mit dem Backslash:
\# Dies ist keine Überschrift
Für Hervorhebungen kennt Markdown die Möglichkeit, Text als fett und kursiv zu markieren. Um einen Text kursiv zu setzen, reicht es aus ihn in Sternchen zu setzen:
*kursiv*
Soll der Text hingegen fett gesetzt sein, so werden zwei Sternchen benötigt:
**fett**
Auch die Kombination aus Kursiv- und Fettschreibung ist möglich, indem drei Sternchen genutzt werden:
***kursivundfett***
Neben der Nutzung des Sternchens ist auch die Nutzung von Unterstrichen möglich. Allerdings wird dies in der Praxis seltener genutzt.
Neben diesen einfachen Formatierungen sind in Markdown Blöcke wie Zitate und Beispielcodeblöcke möglich. So beginnt ein Zitat in Markdown mit einer spitzen Klammer:
> There is no reason for any individual to have a computer in his home.
> Ken Olsen, 1977
Hierbei ist auch erlaubt, diese Blöcke ineinander zu verschachteln, sodass verschachtelte Zitate dargestellt werden können:
> Er pflegte es immer mit einem Zitat zu begründen:
> > Wenn Sterne tanzen, ihre Glut sich erhebt.
Codeblöcke können in Markdown ebenfalls abgebildet werden. Dazu muss der entsprechende Code mit vier Leerzeichen bzw. einem Tab eingerückt werden. Damit wird ein solcher Block als preformatierter Text betrachtet.
Alternativ kann ein Codeblock auch über drei Backticks erzeugt werden:
```
int number = 13052025;
if(isPrime(number)) {
...
}
```
Markdown unterstützt Listen. Hierbei wird zwischen ungeordneten und geordneten Listen unterschieden. Ungeordnete Listen können mit einem Sternchen erzeugt werden:
# Einkaufsliste
* Brot
* Marmelade
* Salat
Daneben können solche Listen auch mit einem Plus- oder einem Minus-Zeichen angelegt werden.
Für geordnete Listen muss eine Zahl vor den eigentlichen Listenpunkt geschrieben werden:
# Prioritäten
1. Rasen mähen
2. Einkaufen
3. Kochen
Die Zahlen zur Nummerierung müssen nicht unbedingt aufeinanderfolgen; dies dient nur der besseren Lesbarkeit. In der Theorie könnte eine solche Liste auch wie folgt aussehen:
# Prioritäten
1. Rasen mähen
1. Einkaufen
1. Kochen
Würde ein solches Markdown-Element in eine HTML-Datei konvertiert werden, so würde ein Dokument aus einem <ol>-Tag mit einer entsprechenden Liste bestehen. Die Nummern würden in diesem Fall bei der Konvertierung entfallen.
Markdown ermöglicht auch das Einfügen von horizontalen Linien, die als Trennlinien verwendet werden können. Dies geschieht durch mindestens drei Bindestriche, Sternchen oder Unterstriche in einer separaten Zeile. Diese Trennlinien sind nützlich, um verschiedene Abschnitte eines Dokumentes visuell und thematisch zu trennen.
Neben Formatierungen können in Markdown auch Verlinkungen und Bilder integriert werden. Ein Link wird durch eckige Klammern für den Linktext und runde Klammern für die URL definiert:
[Linktext](http://example.com)
Diese Links werden auch Inline-Links genannt. Markdown ermöglicht daneben, Links auf eine elegantere Weise zu verwalten, insbesondere wenn dieselbe URL mehrfach verwendet wird. Dies geschieht durch die Verwendung von Referenz-Links. Ein Referenz-Link wird in zwei Teilen geschrieben: Der erste Teil enthält den Link-Text und eine Referenz in eckigen Klammern:
[Beispiel-Link][1]
Nun muss dazu die entsprechende Referenz definiert werden:
[1]: https://www.example.com
Diese Methode verbessert die Lesbarkeit des Quelltextes und erleichtert die bessere Verwaltung von Links, da die URL nur einmal geändert werden muss, wenn sie aktualisiert wird.
Neben der Verlinkung zu externen Webseiten ermöglicht Markdown auch das Verlinken zu anderen Teilen desselben Dokumentes, was besonders nützlich für lange Texte oder Dokumentationen ist. Dies wird durch die Verwendung von Anker-Links erreicht. Ein Anker-Link verweist auf eine bestimmte Überschrift im Dokument. Beispielhaft könnte dies so aussehen:
[Einleitung](#einleitung)
Damit würde dieser Link auf die Überschrift Einleitung verweisen.
Eine eher selten genutzt Möglichkeit der Verlinkung sind sogenannte Autolinks. Damit können URLs und E-Mail-Adressen automatisch in Links umgewandelt werden. Dazu muss die betreffende URL oder E-Mail-Adresse in spitze Klammern gesetzt werden:
<example.com>
Die Syntax zur Einbindung von Bildern ähnelt der von Verlinkungen. Jedoch wird ein Ausrufezeichen vor der Definition genutzt:

Auch die Angabe eines Titels ist bei dieser Art der Definition möglich:

Daneben sind wie bei der Verlinkung auch bei der Definition von Bildern die Möglichkeiten von Referenzen gegeben.
Neben den klassischen Elementen, die in Markdown dargestellt werden können, existieren auch Elemente, welche durch verschiedene Erweiterungen bzw. Varianten, wie GitHub Flavored Markdown, zu Markdown kamen.
In diesen Erweiterungen können unter anderem Tabellen definiert werden. Tabellen können erstellt werden, indem Spalten durch senkrechte Striche und Zeilen durch Zeilenumbrüche getrennt werden. Die Kopfzeile wird durch eine Trennlinie aus Bindestrichen unterstrichen. Diese Syntax macht es einfach, strukturierte Daten darzustellen.
Eine solche Tabelle könnte beispielhaft wie folgt aussehen:
| Spalte 1 | Spalte 2 | Spalte 3 |
|----------|----------|----------|
| Inhalt 1 | Inhalt 2 | Inhalt 3 |
| Inhalt 4 | Inhalt 5 | Inhalt 6 |
Auch eine Syntax für Fußnoten ist im ursprünglichen Markdown nicht vorgesehen, wurde aber in unterschiedlichsten Varianten definiert:
Das ist ein Beispieltext mit einer Fußnote.[^1]
[^1]: Dies ist der Text der Fußnote.
Komplexer wird es bei der Integration von mathematischen Formeln in Markdown. Hier sind unterschiedliche Möglichkeiten gegeben, wie die Nutzung von MathJax oder direkte Unterstützung der LaTeX-Syntax für Formeln, die allerdings nur in bestimmten Varianten und Markdown-Werkzeugen unterstützt werden.
Geschmacksrichtungen
Standard-Markdown, oft einfach Markdown genannt, ist die ursprüngliche Version, die von John Gruber veröffentlicht wurde. Es bietet grundlegende Formatierungsoptionen wie Überschriften, Listen, Links, Bilder und Zitate.
Daneben existieren Markdown-Varianten, welche unterschiedlichste Formatierungsmittel und Möglichkeiten hinzufügen. Diese Varianten erweitern die ursprüngliche Markdown-Syntax und bieten zusätzliche Funktionen, um den unterschiedlichen Anforderungen der Benutzer gerecht zu werden. Jede Variante hat ihre eigenen spezifischen Anwendungsfälle und wird in verschiedenen Kontexten bevorzugt.
Zu den häufigsten Varianten zählen GitHub Flavored Markdown, CommonMark, Markdown Extra, MultiMarkdown und die Pandoc-Markdown-Variante, wobei CommonMark im Verlauf des Artikels noch separat betrachtet werden soll.
Varianten unter der Lupe
GitHub Flavored Markdown ist eine erweiterte Version von Markdown, die von GitHub entwickelt wurde. Sie fügt zusätzliche Funktionen hinzu, die speziell auf die Bedürfnisse von Entwicklern und die Nutzung auf GitHub zugeschnitten sind. Zu den Erweiterungen gehören Tabellen, erweiterte Listen, Inline-Code, Codeblöcke mit Syntaxhervorhebung und Task-Listen.
Markdown Extra ist eine Erweiterung, die von Michel Fortin entwickelt wurde. Es fügt zusätzliche Funktionen wie Definition Lists, Fußnoten, Abkürzungen und Tabellen hinzu.
MultiMarkdown wurde von Fletcher Penney entwickelt und erweitert die Fähigkeiten von Markdown um Funktionen wie Tabellen, Fußnoten, Referenzen und mathematische Unterstützung. Es ist besonders nützlich für wissenschaftliche und technische Dokumentationen.
Neben diesen Varianten existieren weitere Markdown-Varianten, wie RMarkdown und kramdown, welche hier allerdings nicht weiter behandelt werden sollen.
Standardisierung
Die ursprüngliche Markdown-Spezifikation von John Gruber kämpft mit einigen Mehrdeutigkeiten. Daneben wurden im Laufe der Zeit, wie oben beschrieben, eigene Varianten und Erweiterungen von Markdown entwickelt. Diese Varianz führte zu Problemen beim Teilen und Verarbeiten von Markdown-Dokumenten.
Im Jahr 2012 initiierte eine Gruppe von Personen, zu der Jeff Atwood und John MacFarlane gehörten, eine Standardisierungsinitiative. Eine Community-Website wurde erstellt, um eine Vielzahl von Werkzeugen und Ressourcen zu dokumentieren, die Autoren von Dokumenten und Entwicklern verschiedener Markdown-Implementierungen zur Verfügung stehen sollten.
Im September 2014 äußerte Gruber Bedenken hinsichtlich der Nutzung des Namens Markdown für diese Initiative, woraufhin sie in CommonMark umbenannt wurde.
CommonMark veröffentlichte mehrere Versionen einer Spezifikation, einer Referenzimplementierung und einer Testsuite und plant eine endgültige 1.0-Spezifikation vorzustellen. Diese 1.0-Spezifikation wurde jedoch bisher nicht veröffentlicht, da noch wichtige Probleme ungelöst sind.
Einige Projekte haben mittlerweile die Definition von CommonMark übernommen darunter Discourse, GitHub, und Stack Exchange.
Vom CommonMark-Projekt werden unterschiedlichste Parser angeboten, wie commonmark-java, welche wiederum Erweiterungen unterstützen. Daneben existieren andere Parser, welche ebenfalls die CommonMark-Spezifikation implementieren, z. B. markdown-it.
Auch wenn sich CommonMark in vielen Bereichen durchgesetzt hat, ist die Vielfalt und Unterschiedlichkeit der Markdown-Derivate, schon im Ursprung von Markdown angelegt, neben den anderen Problemen, welche oft mit der Definition eines Standards eingehen.
RFCs
Daneben fand Markdown auch bereits Erwähnung in einigen RFCs. Im März 2016 wurden zwei relevante RFCs veröffentlicht: RFC 7763 führte den MIME-Typ text/markdown ein, und RFC 7764 diskutierte unter anderem die Varianten MultiMarkdown, GitHub Flavored Markdown, Pandoc und Markdown Extra.
Markdown in der Praxis
Doch wie sieht die Nutzung von Markdown in der Praxis aus? Hier haben sich in den vergangenen Jahren viele Gebiete gefunden, in denen Markdown genutzt wird.
Texteditoren und IDEs
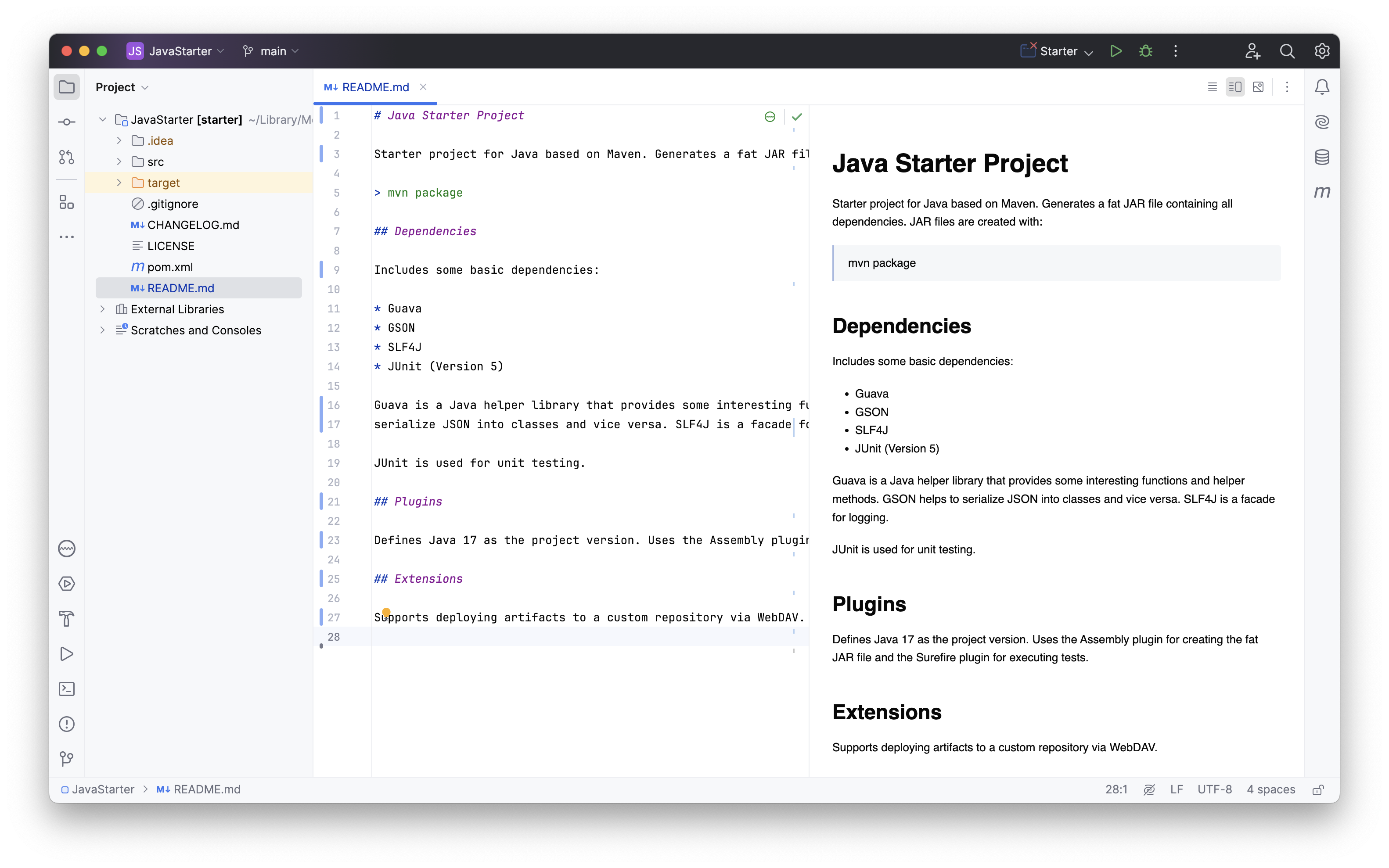
Viele Entwicklungsumgebungen und Texteditoren unterstützen Markdown mittlerweile von Haus aus. Dies bedeutet meist ein (optionales) Rendering und eine Hervorhebung der Formatierungselemente, wie bei der Fett- und Kursivstellung von Texten. Im Rahmen von Textdateien wird als Endung für Markdown-Dateien überwiegend die Endung .md genutzt.
Markdown-Editor in IntelliJ IDEA
So unterstützen IDEs wie die JetBrains IDEs und Editoren wie Atom, Visual Studio Code oder auch Texteditoren wie Notepad++, Sublime Text oder TextMate Markdown.
Markdown-Unterstützung in TextMate
Daneben existieren mit Editoren wie MarkText, Anwendungen welche speziell auf Markdown geeicht sind. Dieser Editor bietet eine Echtzeit-Vorschau, Unterstützung für CommonMark und GitHub Flavored Markdown sowie eine Vielzahl von Themes und Tastenkombinationen.
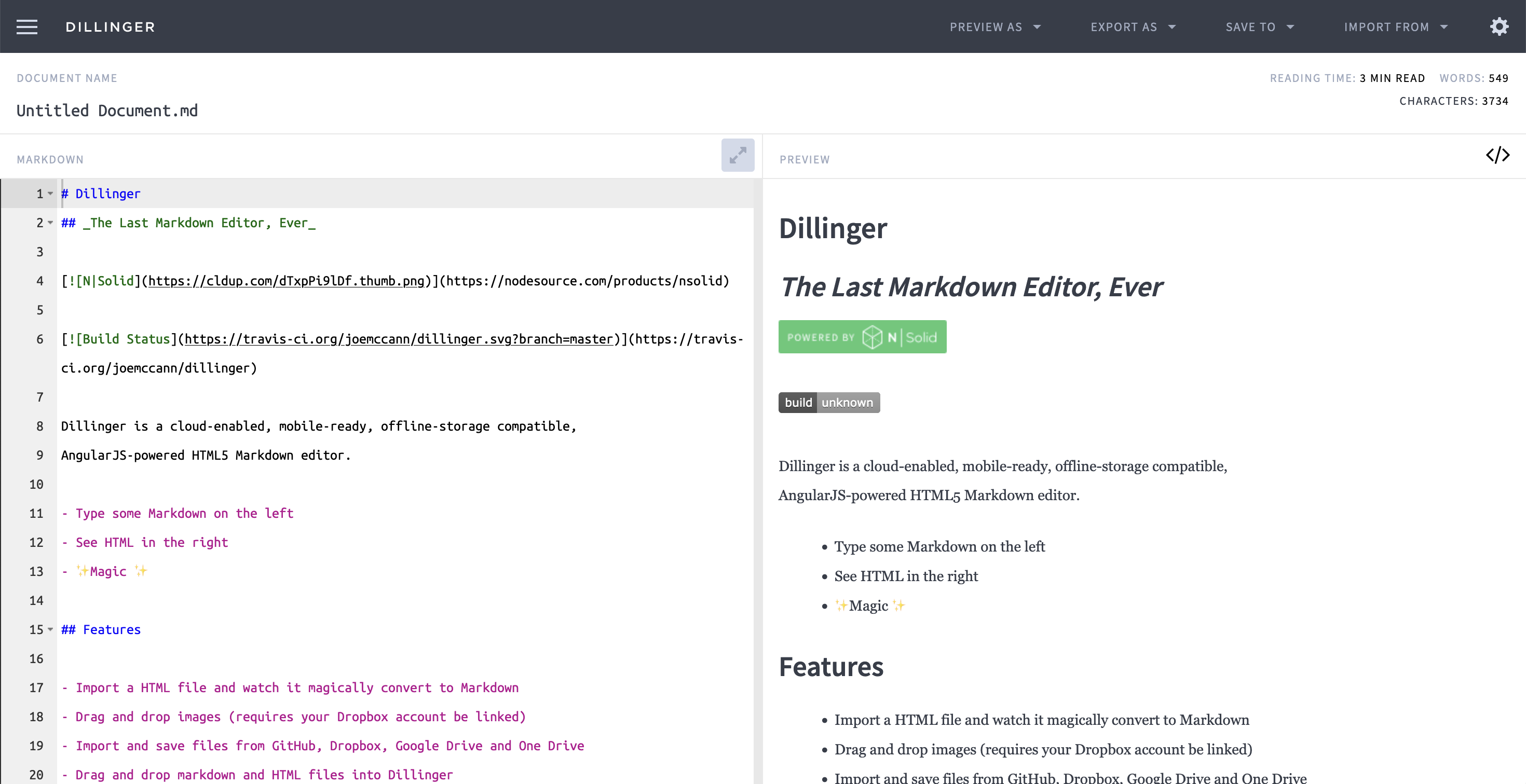
Zusätzlich zu den beschriebenen Texteditoren existieren auch webbasierte Markdown-Editoren wie Dillinger.
Der Markdown-Editor Dillinger
Auch dieser Editor bietet eine Echtzeit-Vorschau und die Möglichkeit, Dokumente in unterschiedliche Formaten zu exportieren.
Notiz-Applikationen
Neben reinen Texteditoren und IDEs haben sich mittlerweile auch viele Notiz-Applikationen für Markdown erwärmt.
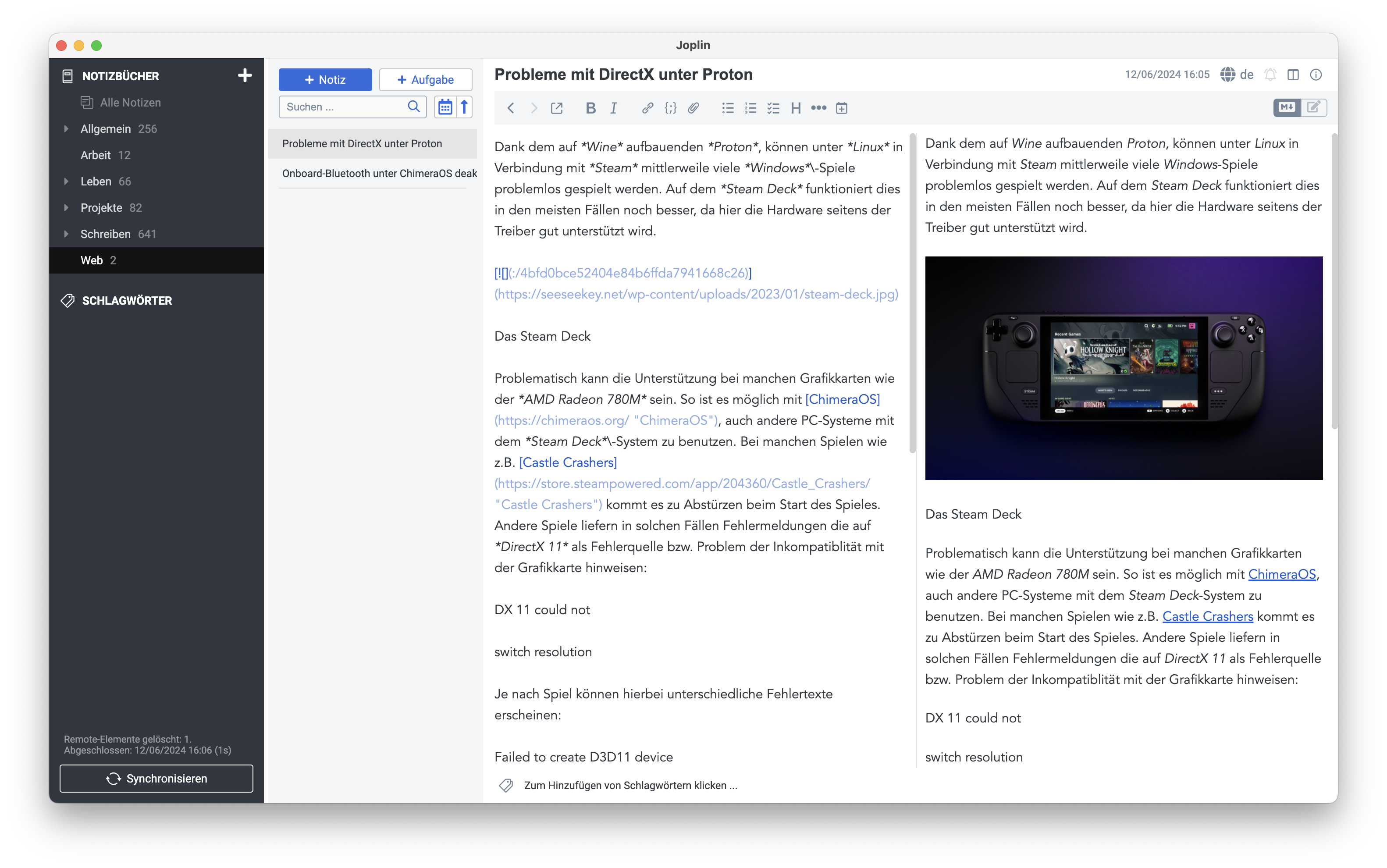
Während die Unterstützung bei Apps wie Evernote und OneNote eher eingeschränkt ist, oder nur durch Plugins ermöglicht wird, existieren andere Applikationen wie Bear, Joplin oder Obsidian, die sich weitgehend auf Markdown stützen.
Joplin nutzt Markdown als Basis
Markdown dient hier als schneller und unkomplizierter Weg, Informationen zu erfassen. Je nach Applikation werden unterschiedliche Ansichten auf die Markdown-Dokumente geliefert, wie zum Beispiel das Quelldokument und das entsprechende Rendering. Bei Joplin werden auch Webseiten in Markdown konvertiert, wenn sie mit dem Webclipper gespeichert wurden.
Blogging und Content Management
Viele Blogging-Plattformen wie WordPress, Ghost und Jekyll unterstützen Markdown, was es Autoren ermöglicht, sich auf das Schreiben zu konzentrieren, ohne sich um die Formatierung zu sorgen.
Da Markdown-Dateien ursprünglich darauf angelegt waren, einfach in HTML umgewandelt zu werden, vereinfacht dies die Veröffentlichung im Web.
Je nach verwendetem System werden hier, wie im Falle von WordPress, Plugins für die Unterstützung benötigt. Andere Systeme wie Ghost und Jekyll unterstützen Markdown nativ.
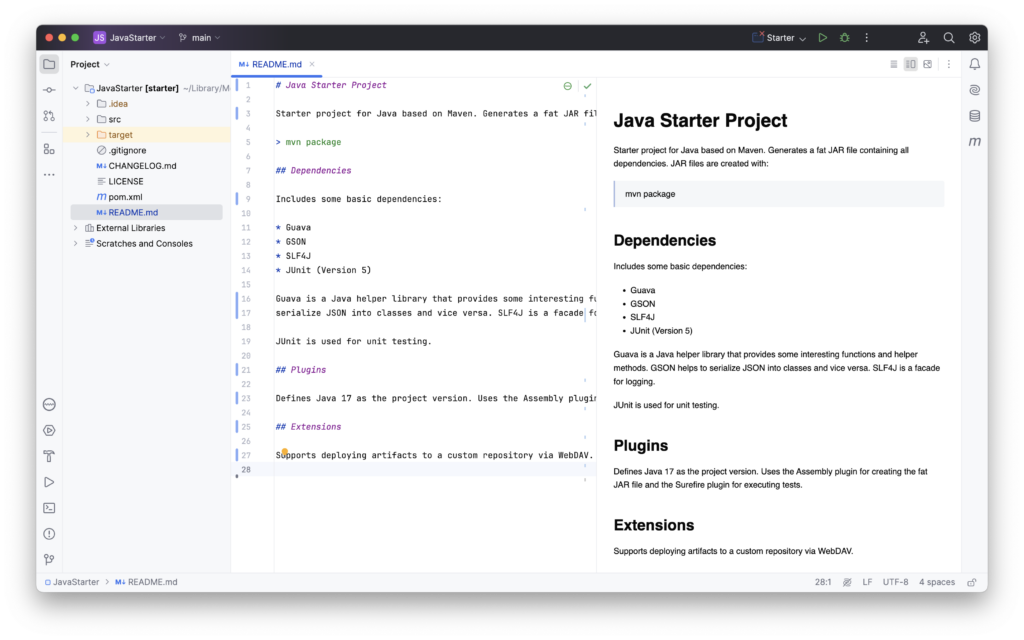
Dokumentation und technisches Schreiben
Besonders beliebt ist Markdown in der Softwareentwicklung für die Erstellung von Dokumentationen.
Plattformen wie GitHub verwenden Markdown für README-Dateien, die Projektdetails und Anweisungen enthalten. Mit Markdown können Entwickler schnell und effizient Dokumentationen erstellen und aktualisieren.
# Java Starter Project
Starter project for Java based on Maven. Generates a fat JAR file containing all dependencies. JAR files are created with:
> mvn package
## Dependencies
Includes some basic dependencies:
* Guava
* GSON
* SLF4J
* JUnit (Version 5)
...
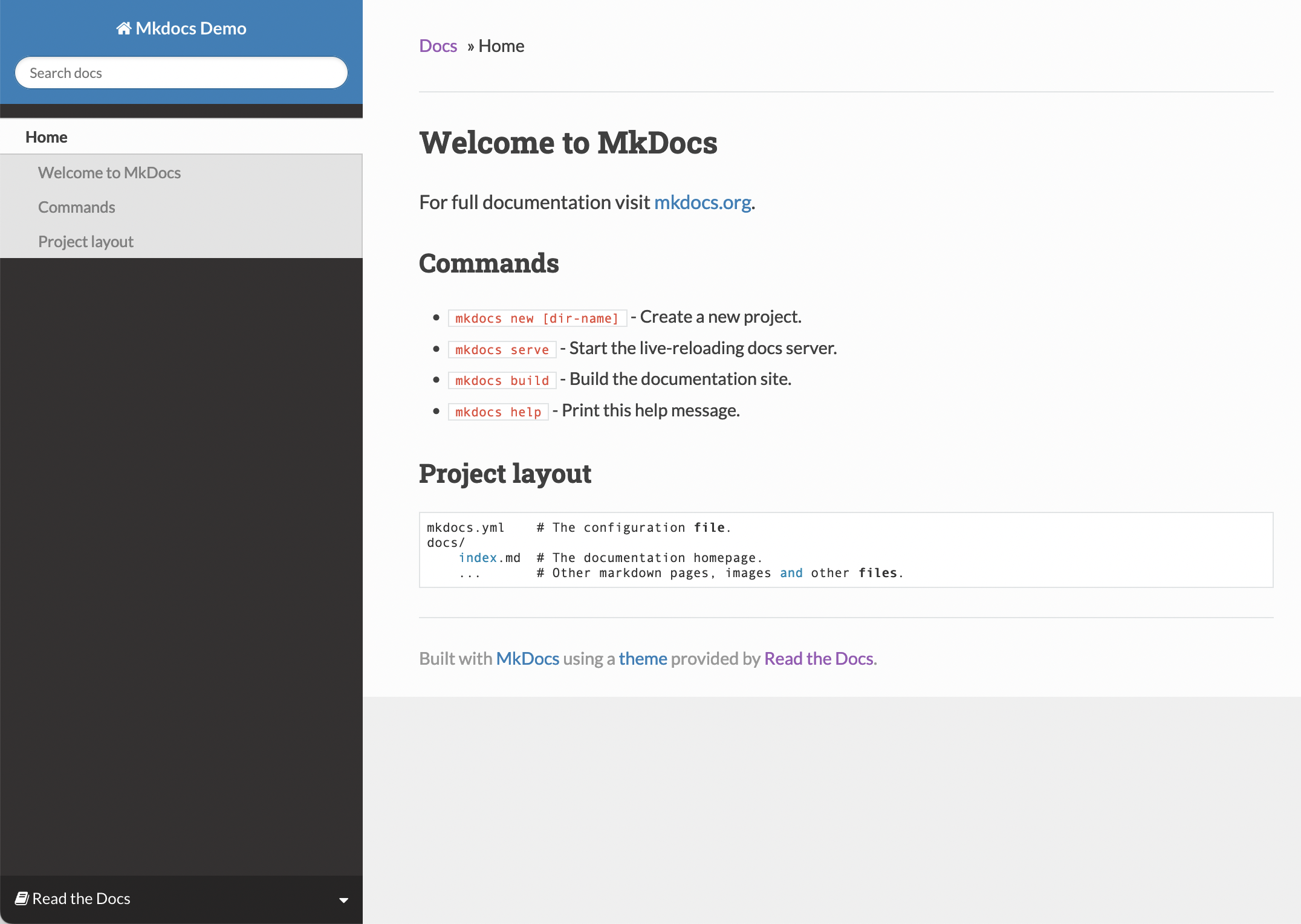
Neben der Dokumentation in Softwareprojekten existieren eine Reihe von Dokumentationstools.
Eine aus Markdown erzeugte Mkdocs-Dokumentation
So setzen Werkzeuge wie MkDocs und Sphinx auf Markdown und auch Plattformen wie ReadTheDocs unterstützen Markdown.
E-Mails und Kommunikation
Markdown kann zum Schreiben von E-Mails verwendet werden, um Text klar und strukturiert zu formatieren. Einige E-Mail-Clients unterstützen Markdown direkt. So existieren Clients wie MailMate, die Markdown nativ zum Schreiben von E-Mails unterstützen.
Auch etablierte Mail-Clients wie Thunderbird können über Add-Ons wie Markdown Here mit einer entsprechenden Funktionalität nachgerüstet werden.
Präsentationen
Mittels entsprechender Frameworks und wie reveal.js können auch Präsentationen über Markdown erstellt werden.
Reveal.js ist ein Open-Source-Framework zur Erstellung von Präsentationen im Webbrowser. Entwickelt von Hakim El Hattab, ermöglicht es Nutzern, ansprechende und interaktive Präsentationen mit HTML, CSS und JavaScript, aber auch mit Markdown zu gestalten.
Dadurch kann sich der Ersteller einer Präsentation auf die Inhalte konzentrieren, ohne sich mit Designfragen auseinandersetzen zu müssen.

Eine reveal.js Präsentation
Dazu müssen die Markdown-Dateien nur innerhalb der Index-Datei der reveal.js-Präsentation eingebunden werden:
<div class="slides">
<section data-markdown="markdown/intro.md"
data-separator="^-----\n"
data-separator-vertical="^---\n"
data-separator-note="^Note:"
data-charset="utf-8">
</section>
<section data-markdown="markdown/webservices.md"
data-separator="^-----\n"
data-separator-vertical="^---\n"
data-separator-note="^Note:"
data-charset="utf-8">
</section>
...
Aussehen würde eine beispielhafte Slideabfolge einer Sektion dabei wie folgt:
## OpenAPI
aka Swagger
Note:
* maschinenlesbare Interfacedefinitionen
* Contract-First-Gedanke
* betreut von der OpenAPI Initative
---

Note:
* Atlassian
* Google
* Paypal
* SAP
...
Damit lassen sich über Markdown schnell Präsentationen erzeugen, welche den Fokus auf den Inhalt, anstelle der mühsamen Gestaltung legen.
Schreiben
Neben den vorgestellten Texteditoren, existieren eine Reihe von Werkzeugen, welche sich auf den Aspekt des Schreibens längerer Werke, mittels Markdown konzentrieren.
So existiert mit iA Writer ein minimalistischer Texteditor, der sich besonders an Autoren, Journalisten und andere Schreibende richtet, die eine ablenkungsfreie Umgebung schätzen.
Speziell zu iA Writer existieren Open Source-Alternativen, wie FocusWriter, welche sich ebenfalls ablenkungsfreies Schreiben auf die Fahnen geschrieben haben.
Ulysses
Eine weitere auf Markdown zentrierte Schreibanwendung ist Ulysses, die speziell für Autoren und Schriftsteller entwickelt wurde. Sie bietet eine ablenkungsfreie Benutzeroberfläche und eine Vielzahl von Werkzeugen, die das Schreiben und Organisieren von Texten erleichtern.
Ulysses unter macOS
Die App basiert auf Markdown, und die erzeugten Dokumente können in unterschiedliche Ausgabeformate exportiert werden.
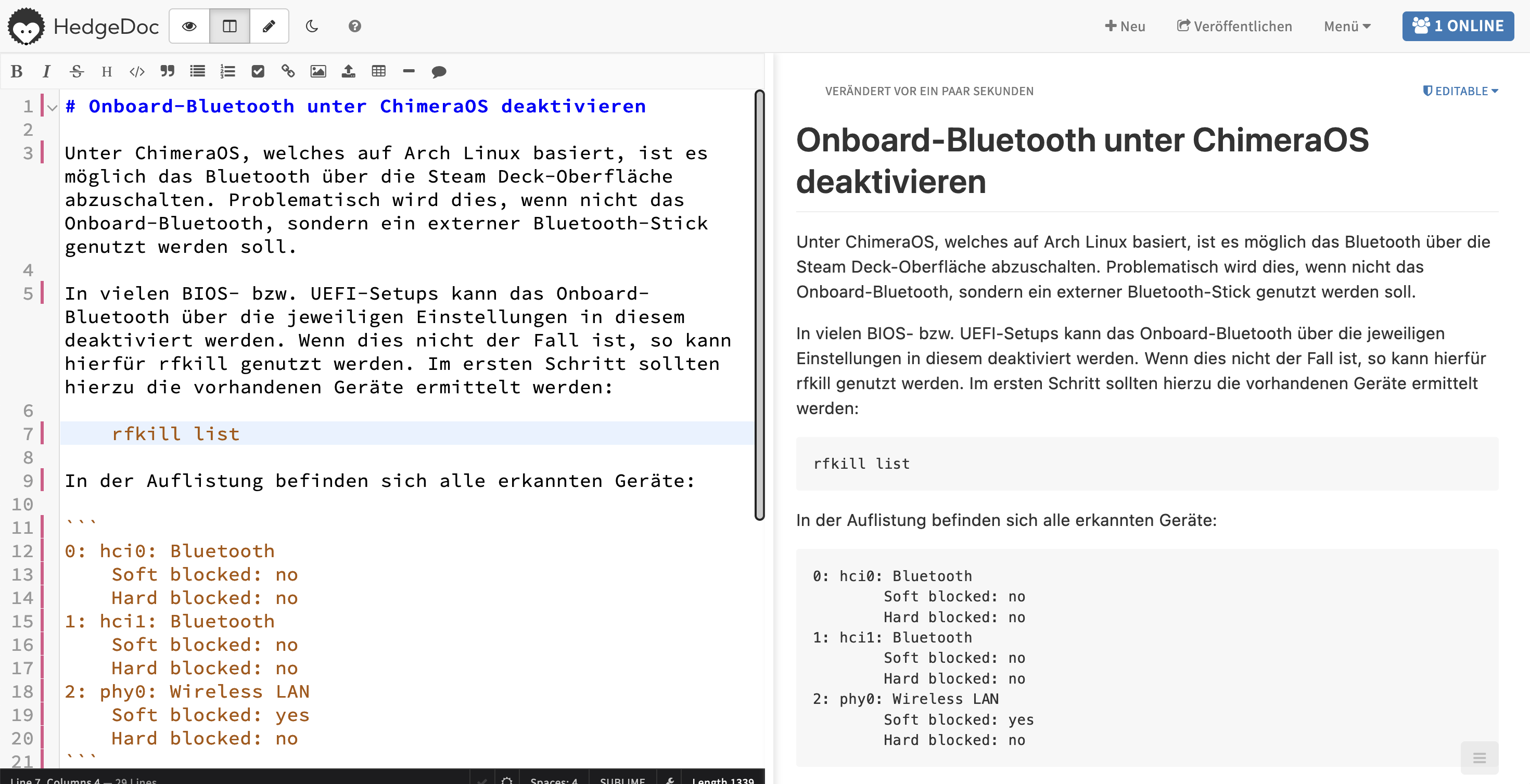
Kollaboratives Schreiben
Neben dem Schreiben als Einzelperson existieren etliche Werkzeuge für kollaboratives Schreiben, wie zum Beispiel die unterschiedlichsten Varianten von EtherPad. Mit HedgeDoc existiert ein solcher webbasierter Editor mit Markdown-Unterstützung.
HedgeDoc als kollaborativer Markdown-Editor
Ursprünglich als CodiMD bekannt, bietet die Anwendung eine benutzerfreundliche Oberfläche, die sowohl für Einzelpersonen als auch für Teams geeignet ist. Die Markdown-Unterstützung orientiert sich an CommonMark und dem GitHub Flavored Markdown.
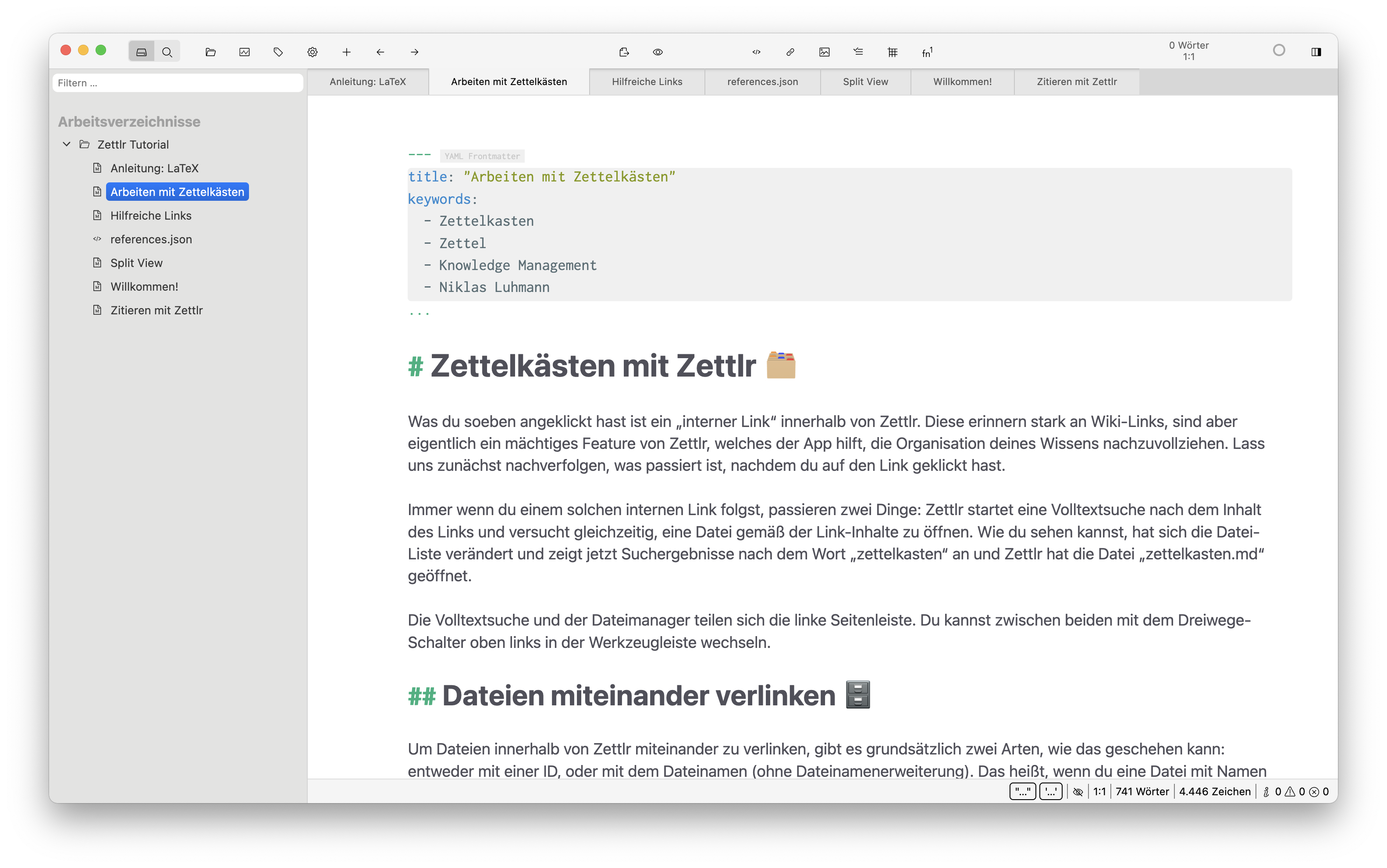
Zettlr
Zettlr ist eine freie Software, die darauf abzielt, das Schreiben und Verwalten von Texten zu unterstützen. Hier liegt der Fokus auf wissenschaftlichem Arbeiten. Die Anwendung bietet Funktionen zur Erstellung von Markdown-Dokumenten und zur Organisation von Notizen.
Zettlr unter macOS
Zudem ist sie mit Referenzverwaltungstools wie Zotero kompatibel, was die Verwaltung von Literaturquellen erleichtert. Zettlr ermöglicht den Export von Dokumenten in verschiedene Formate wie PDF und Word.
Im weiten Web
Grundsätzlich findet sich Markdown-Unterstützung in vielen webbasierten Systemen, wie Wikis, Diskussionsplattformen und vielen weiteren.
Foren wie Reddit und Stack Overflow unterstützen Markdown, um Benutzern das Formatieren ihrer Beiträge zu erleichtern. Durch die einfache Syntax können auch Nutzer ohne größere technische Vorkenntnisse ihre Beiträge sinnvoll gestalten.
Konverter
Neben dem Schreiben in Markdown ist oft auch der Export in andere Formate gewünscht. Während viele Applikationen dies von sich aus beherrschen, gibt es auch spezialisierte Software wie Pandoc, für solche Zwecke.
Pandoc ist ein Werkzeug zur Konvertierung von Dokumenten zwischen verschiedenen Formaten. Es unterstützt die Konvertierung von Markdown in HTML, PDF, DOCX, LaTeX und viele andere Formate.
Pandoc nutzt hierbei seinen eigenen Markdown-Dialekt und ist freie Software.
Ressourcen und Dokumentation
Neben Dokumenten wie der ursprünglichen Spezifikation und CommonMark existieren es eine Reihe von Ressourcen, die in Markdown einführen, wie der Markdown Guide.
Dieser bietet eine umfangreiche Ressource rund um Markdown, führt in die Syntax ein und pflegt eine Liste von Markdown-Tooling.
Auch existieren unzählige Cheat Sheets und Tutorials für Markdown und ermöglichen es Einsteigern schnell in der Markdown-Welt anzukommen.
Fazit
Markdown wurde ursprünglich mit einem minimalistischen Ansatz entwickelt und hat sich schnell eine breite Anhängerschaft aufgebaut. Während die unterschiedlichen Varianten etwas Verwirrung stiften können, ist der Kern von Markdown wohl definiert.
Selbst ohne spezielle Tools lässt sich Markdown problemlos lesen und verstehen, was es ideal für die Erstellung von Dokumentationen, Notizen und Texten macht.
Mittels Markdown können elegant und schnell Texte geschrieben werden, ohne dass sich in Formatierungsoptionen und Designfragen verloren wird. Damit bietet es im Zusammenhang mit entsprechenden Applikationen eine ablenkungsfreie und effiziente Schreibumgebung.
Überdies bietet Markdown bzw. die Werkzeuge rund um Markdown die Flexibilität, ansprechend formatierte Dokumente zu exportieren. Diese Kombination aus Einfachheit und Vielseitigkeit machte Markdown zu einem unverzichtbaren Werkzeug.
Neben dem reinen Schreiben hat sich Markdown darüber hinaus viele weitere Anwendungsgebiete erobert und wird uns sicherlich auch in Zukunft begleiten.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.