In den letzten Tagen erreichte mich der Picoboy Color, nachdem ich schon einige Zeit im Besitz eines Picoboy war. Neben den üblichen Spielereien war ich daran interessiert die beiden Geräte mittels Rust zum Laufen zu bekommen. Also warf ich einen Blick auf das vorhandene Tooling und am Ende entstanden zwei Crates, zur Anbindung der Picoboys an Rust.
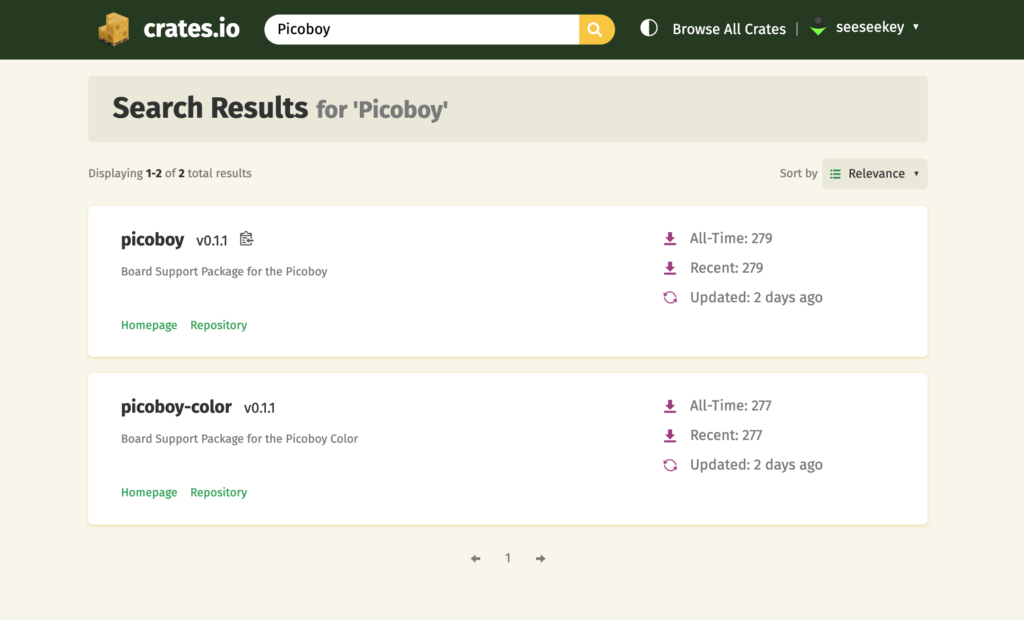
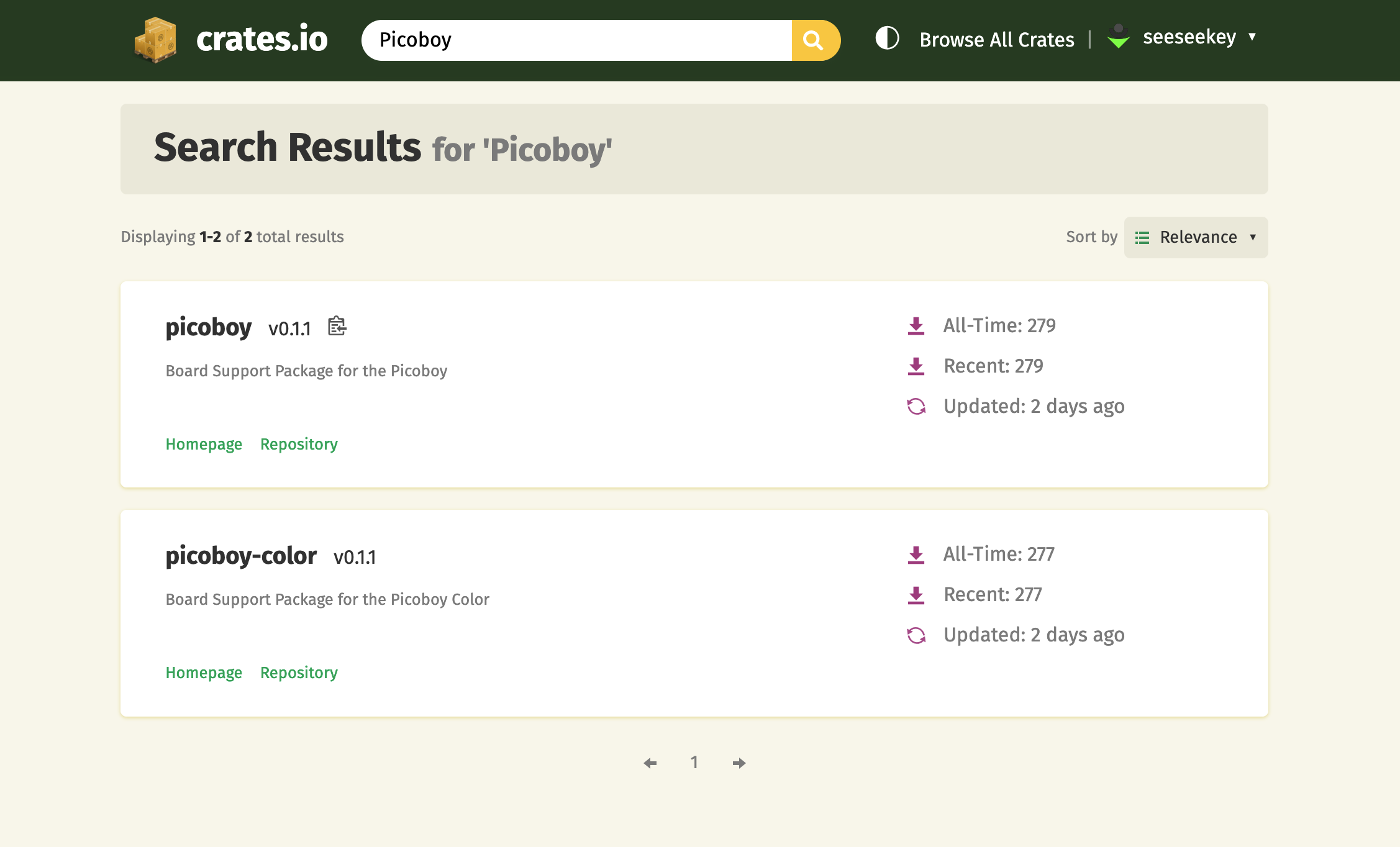
Die entstandenen Crates
Auf Basis der rp-rs-Projekte entstanden, neben den Board Support Packages auch neue Templates zum Start neuer Projekte. Die einzelnen Repositorys sind hierbei picoboy-hal-boards, picoboy-project-template und picoboy-color-project-template. Sie sind jeweils under der Apache- und der MIT-Lizenz lizenziert.

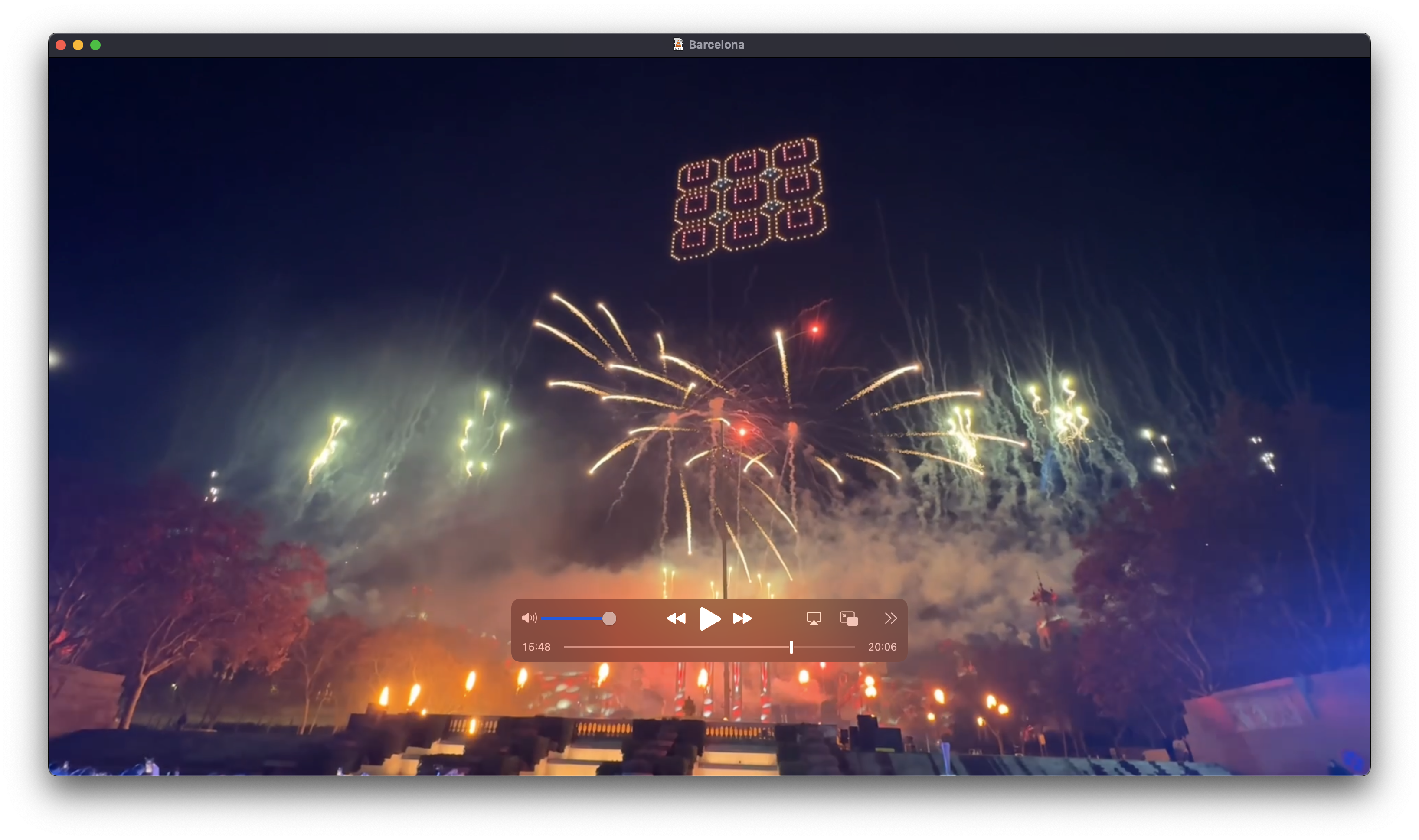
Der Picoboy und der Picoboy Color, mittels Rust programmiert
Über das Rust-Werkzeug cargo-generate, welches mittels:
cargo install cargo-generate
installiert werden kann, können neue Projekte über die bereitgestellten Templates angelegt werden. Für den Picoboy wäre dies:
cargo generate --git https://github.com/seeseekey/picoboy-project-template.git
Analog dazu für den Picoboy Color:
cargo generate --git https://github.com/seeseekey/picoboy-color-project-template.git
Die Beispiele zeigen die Nutzung der Steuerung, das Zeichnen auf dem Display und einige weitere Kleinigkeiten. Hier ist an einigen Stellen durchaus noch Verbesserungsbedarf gegeben, so können z. B. die Abhängigkeiten angepasst werden, sobald die Basisbibliotheken von rp-rs auf die aktuellen Versionen aktualisiert wurden. Auch ein Upgrade der st7789-Bibliothek auf den Nachfolger mipidsi wäre dann denkbar.
Das Zeichnen auf dem Display erfolgt im Moment noch direkt, hier ließe sich die Performance durch die Nutzung von embedded-graphics-framebuf verbessern. Ebenfalls denkbar wäre eine weitere Modularisierung, so könnte z. B. die Controller- und Display-Initialisation in separate Rust-Module ausgelagert werden.