Bedingt durch die Kürzungen der US-Regierung, war es in den letzten Wochen durchaus denkbar, dass die CVE-Liste, mangels monetärer Mittel, ihre Arbeit hätte einstellen müssen. Das veranlasste die Agentur der Europäischen Union für Cybersicherheit (ENISA), ihre eigene Schwachstellen-Datenbank, die European Vulnerability Database (EUVD), früher vorzustellen. Neben der offiziellen Seite, wird auch eine API bereitgestellt.
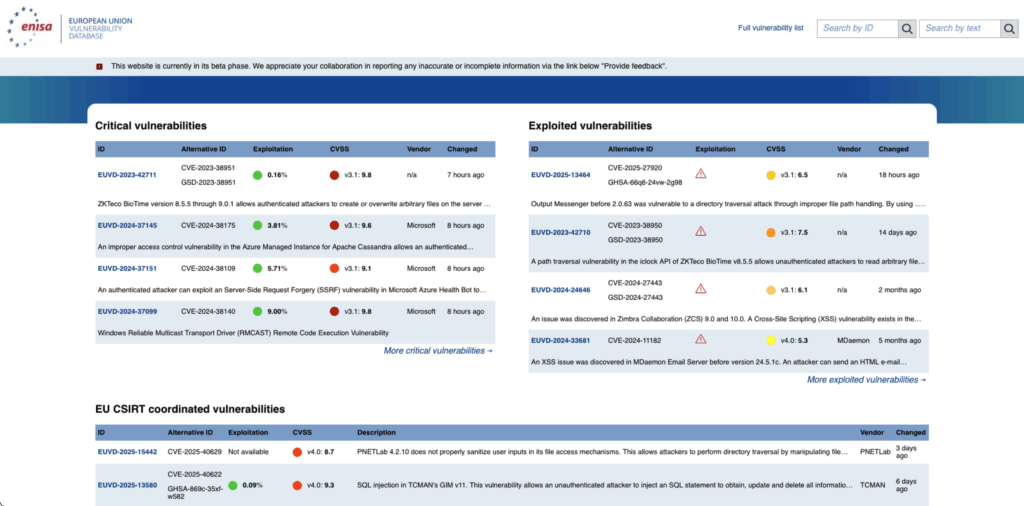
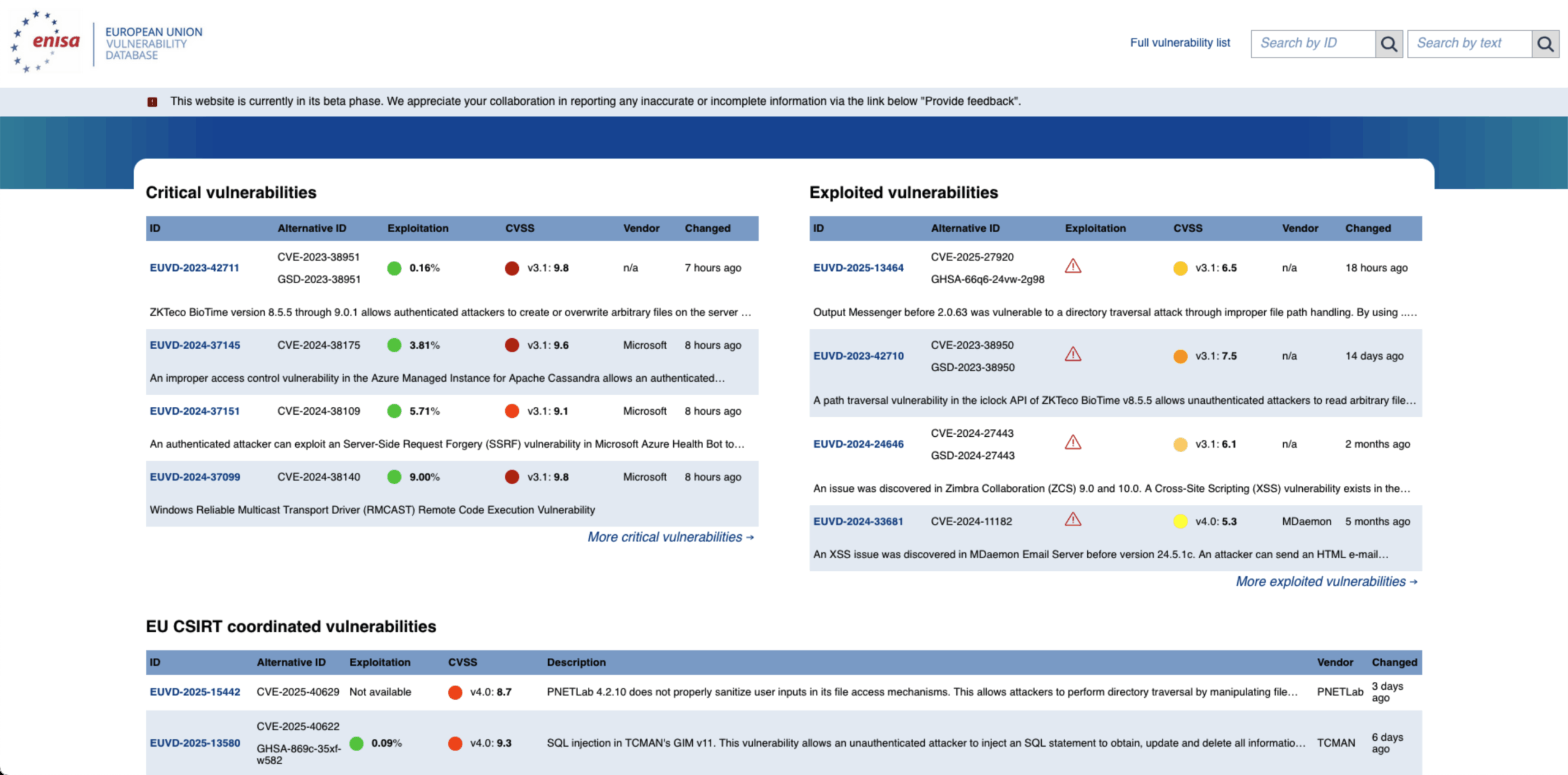
Das Webinterface der EUVD
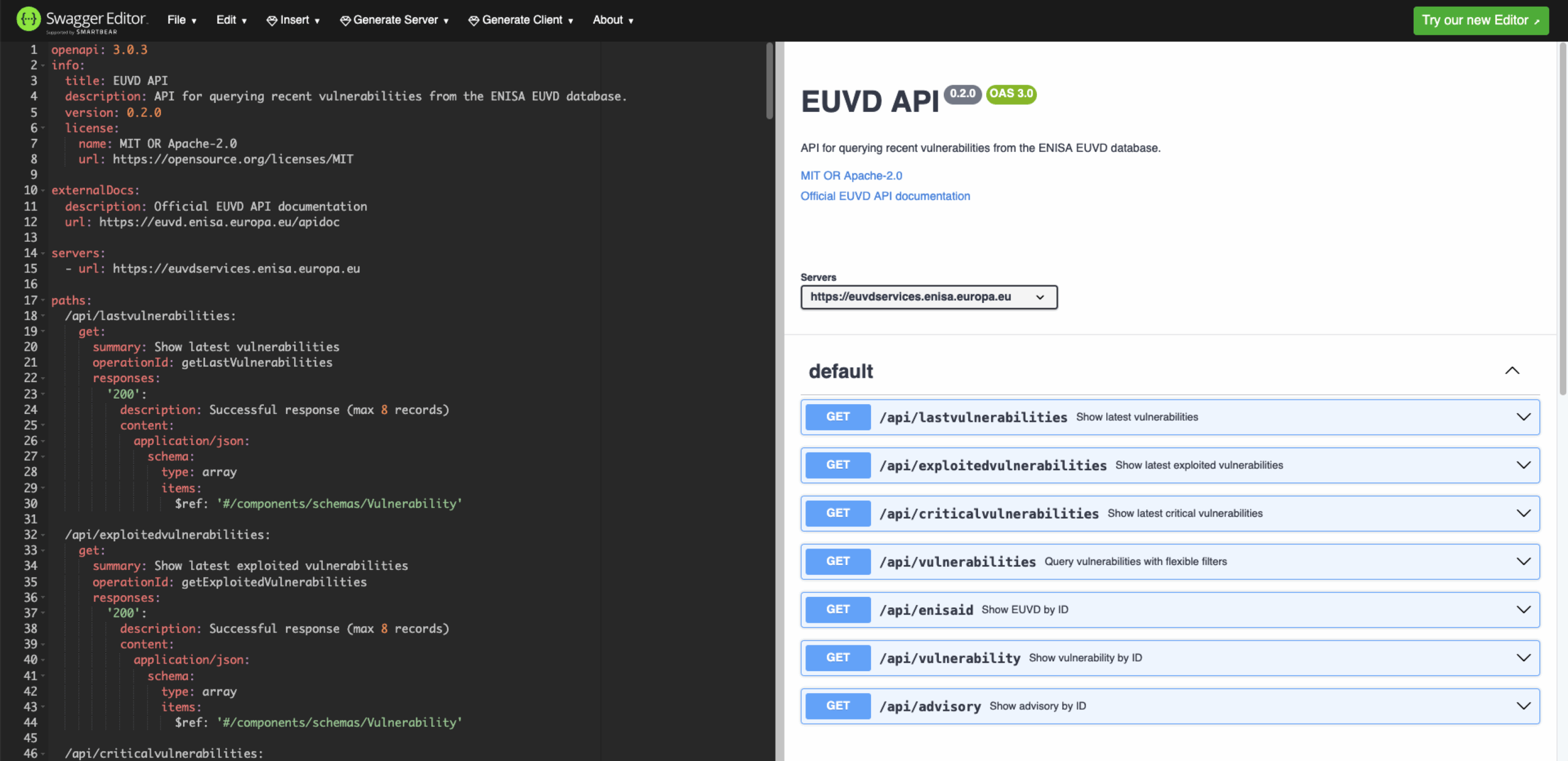
Mehrere spezialisierte Endpunkte stehen innerhalb der API zur Verfügung: /api/lastvulnerabilities, /api/exploitedvulnerabilities und /api/criticalvulnerabilities liefern jeweils bis zu acht aktuelle Einträge. Über /api/vulnerabilities lassen sich Schwachstellen detailliert nach Kriterien wie Score, EPSS-Wert, Veröffentlichungszeitraum, Hersteller oder Produktname filtern. Weitere Routen ermöglichen den Zugriff auf konkrete Einträge per ENISA-ID oder geben zugehörige Advisories aus.
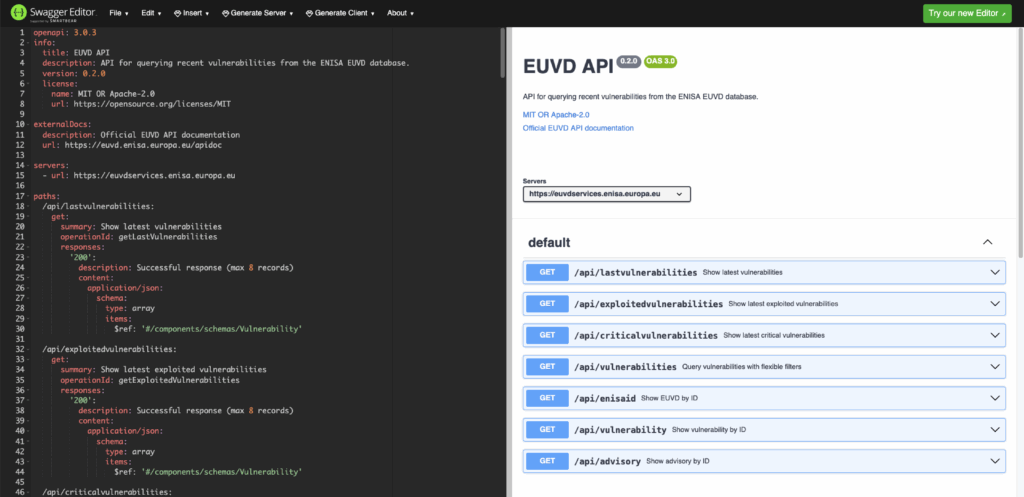
Die erstellte OpenAPI-Spezifikation
Die Dokumentation der API ist allerdings eher rudimentär und nicht wirklich strukturiert gehalten, so werden z.B. die Response-Objekte nirgendwo definiert. Da ich die API in Rust nutzen wollte, führte dies zur Entwicklung des Crates euvd. Passend dazu habe ich eine OpenAPI-Spezifikation erstellt, welche die API möglichst vollumfänglich abbildet. Damit können auch Clients abseits von Rust für die EUVD-API erzeugt werden.
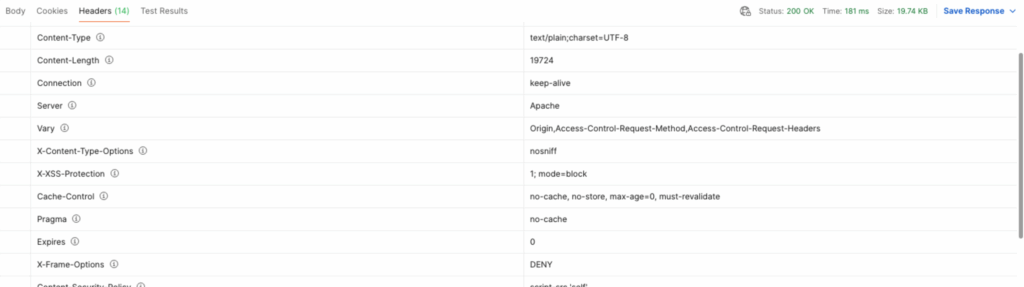
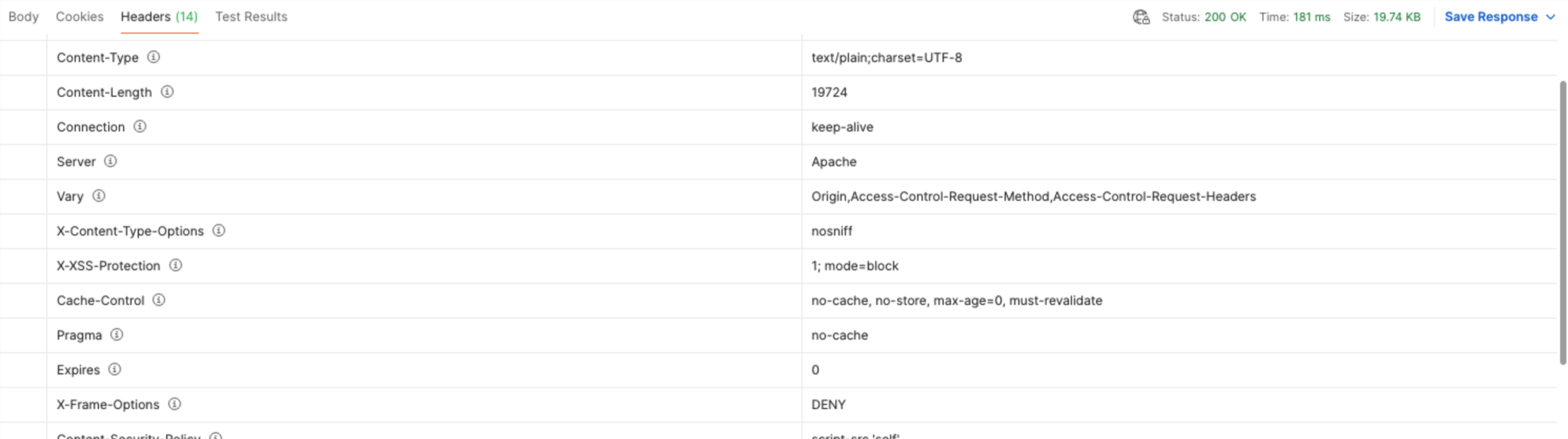
Der Content-Type ist text/plain
Die API selbst enthält noch einige Merkwürdigkeiten bzw. Inkonsistenzen. Dies fängt damit an, das JSON-Objekte zurückgegeben werden:
{
"id": "cisco-sa-ata19x-multi-RDTEqRsy",
"description": "Cisco ATA 190 Series Analog Telephone Adapter Firmware Vulnerabilities",
"summary": "Multiple vulnerabilities in Cisco ATA 190 Series Analog Telephone Adapter firmware, both on-premises and multiplatform, could allow a remote attacker to delete or change the configuration, execute commands as the root user, conduct a cross-site scripting (XSS) attack against a user of the interface, view passwords, conduct a cross-site request forgery (CSRF) attack, or reboot the device.\r\n\r\nFor more information about these vulnerabilities, see the Details [\"#details\"] section of this advisory.\r\n\r\nCisco has released firmware updates that address these vulnerabilities. There are no workarounds that address these vulnerabilities. However, there is a mitigation that addresses some of these vulnerabilities for Cisco ATA 191 on-premises firmware only.\r\n\r\n",
"datePublished": "Oct 16, 2024, 4:00:00 PM",
...
}
Der Content-Type seitens der API wird allerdings als text/plain;charset=UTF-8 definiert und entsprechend zurückgegeben. Dies führte unter anderem bei der Client-Generation zu Problemen, da der Text nicht standardmäßig in die bereitgestellten JSON-Objekte konvertiert wurde.
In den API-Objekten selbst wird mit Camel case gearbeitet, allerdings existieren aus Ausnahmen, wie die enisa_id, welche als Snake case geschrieben wird und die API an einigen Stellen etwas inkonsistent wirken lässt.
"enisa_id": "EUVD-2024-45012\n",
"assigner": "mitre",
"epss": 0.05,
"enisaIdProduct": [
...
An anderen Punkten wird wieder die Schreibweise in Camel case genutzt, wie z.B. beim enisaIdProduct-Feld. Auch eine Versionierung ist nicht zu erkennen, was die Frage nach dem genauen Updateprocedere der API aufwirft.
In Bezug auf digitale Souveränität fällt zudem auf, dass die API bei Azure gehostet wird, wie ein whois zeigt:
% IANA WHOIS server
% for more information on IANA, visit http://www.iana.org
% This query returned 1 object
refer: whois.arin.net
inetnum: 20.0.0.0 - 20.255.255.255
organisation: Administered by ARIN
status: LEGACY
whois: whois.arin.net
changed: 1994-10
source: IANA
# whois.arin.net
NetRange: 20.33.0.0 - 20.128.255.255
CIDR: 20.64.0.0/10, 20.128.0.0/16, 20.40.0.0/13, 20.34.0.0/15, 20.36.0.0/14, 20.33.0.0/16, 20.48.0.0/12
NetName: MSFT
NetHandle: NET-20-33-0-0-1
Parent: NET20 (NET-20-0-0-0-0)
NetType: Direct Allocation
OriginAS:
Organization: Microsoft Corporation (MSFT)
RegDate: 2017-10-18
Updated: 2021-12-14
Ref: https://rdap.arin.net/registry/ip/20.33.0.0
Dies lässt strategische Autonomie vermissen, wenn solche Dienste auf einer Infrastruktur betrieben werden, welche unter ausländischer Rechtshoheit steht.
Um die API bzw. den Client in Rust zu nutzen, muss im ersten Schritt das Crate ins eigene Projekt eingebunden werden:
cargo add euvd
Anschließend können die einzelnen Ressourcen aufgerufen werden:
use euvd::apis::configuration::Configuration;
use euvd::apis::default_api;
async fn get_last_vulnerabilities() {
// Preparation
let config = Configuration::default();
let result = default_api::get_last_vulnerabilities(&config).await;
// Print result if successful
if let Ok(response) = &result {
println!("Response received:");
for vuln in response {
println!("• ID: {:?}, Description: {:?}", vuln.id, vuln.description);
}
}
// Asserts
assert!(result.is_ok(), "API call failed: {:?}", result.err());
}
Weitere Beispiele zur Nutzung der API finden sich im Integrationstest. Der Client ist unter MIT- und Apache-Lizenz lizenziert und auf GitHub und crates.io zu finden.