Unter Mac OS X ist ein Backup schnell eingerichtet – Time Machine, die dafür zuständige Applikation wird bei Inbetriebnahme des Mac eingerichtet und verrichtet ihren Dienst anschließend im Hintergrund. Backups werden nun regelmäßig auf ein entsprechendes Medium geschrieben.
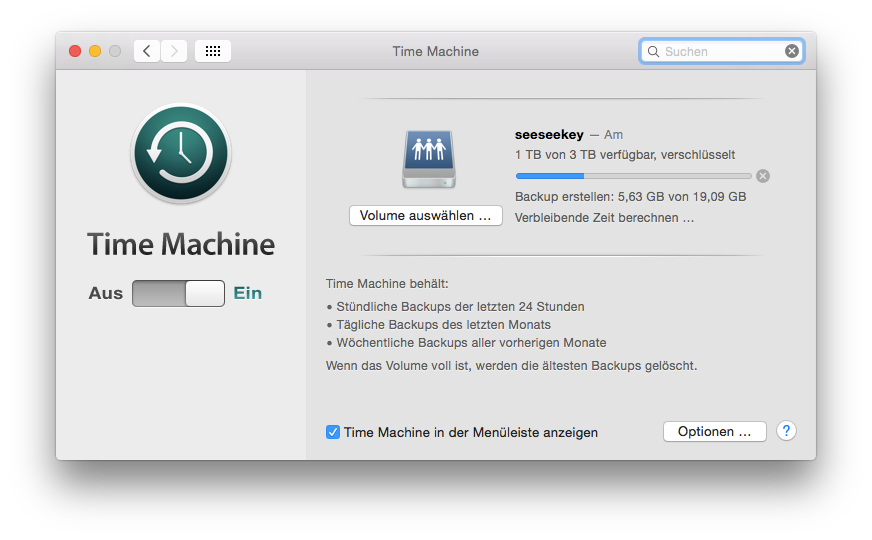
Time Machine sichert die Daten
Interessant ist nun, welche Dateien Time Machine sichert – so wird nicht das gesamte Systeme gesichert, sondern nur bestimmte Dinge wie die Programme und Anwendungen des Nutzers. Cache-, Logdateien, der Papierkorb und das eigentliche Betriebsystem werden nicht gesichert. Bei einer vollständigen Wiederherstellung wird stattdessen das System neu installiert und anschließend das Time Machine-Backup wieder eingespielt. Das führt unter anderem dazu das installierte MacPorts, nach dem Rückspielen des Dateisystems nicht mehr vorhanden sind.