Wer kennt das nicht, man schaut einen Film und in diese Film wird ein Hacker dargestellt. Und wie sich das für einen Hacker gehört haut er in die Tasten als ob es kein Morgen gäbe. Und egal auf welche Tasten der Filmhacker drückt, am Ende kommt sinnvoller Quelltext oder ähnliches heraus.
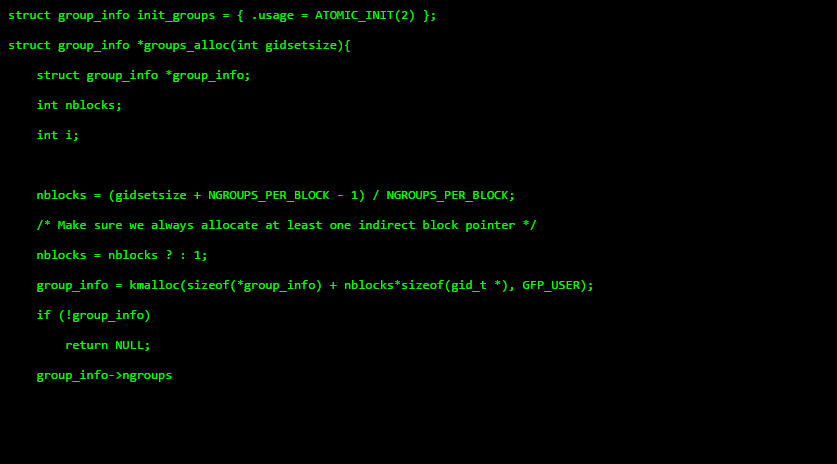
hackertyper.net
Damit man das ganze für den Hausgebrauch nutzen kann, gibt es die Webseite Hacker Typer. Die Webseite stellt einen Editor bereit – es müssen nur noch einige Tasten auf der Tastatur gedrückt werden und schon erscheint der Quelltext auf dem Schirm. Natürlich ist das ganze im besten Konsolenstil gehalten, schließlich sollen keine Erwartungshaltungen enttäuscht werden. Entwickelt wurde die Seite von Simone Masiero und ist unter der Creative Commons Lizenz CC-BY-NC-SA 3.0 lizenziert.