Wer Daten von A nach B übermitteln möchte, hat unzählige Möglichkeiten dies zu tun. Je nach Anforderung und Anwendungsfall sieht die ideale Möglichkeit der Datenübermittlung anders aus. Für die Kommunikation zwischen Sensoren und im IoT-Bereich hat das Protokoll MQTT den Standard gesetzt. Immer dort wo verteilte Systeme miteinander kommunizieren müssen, eignet sich MQTT. MQTT steht für Message Queue Telemetry Transport und ist architektonisch relativ einfach aufgebaut. MQTT ist Nachrichten-orientiert und zentralisiert.
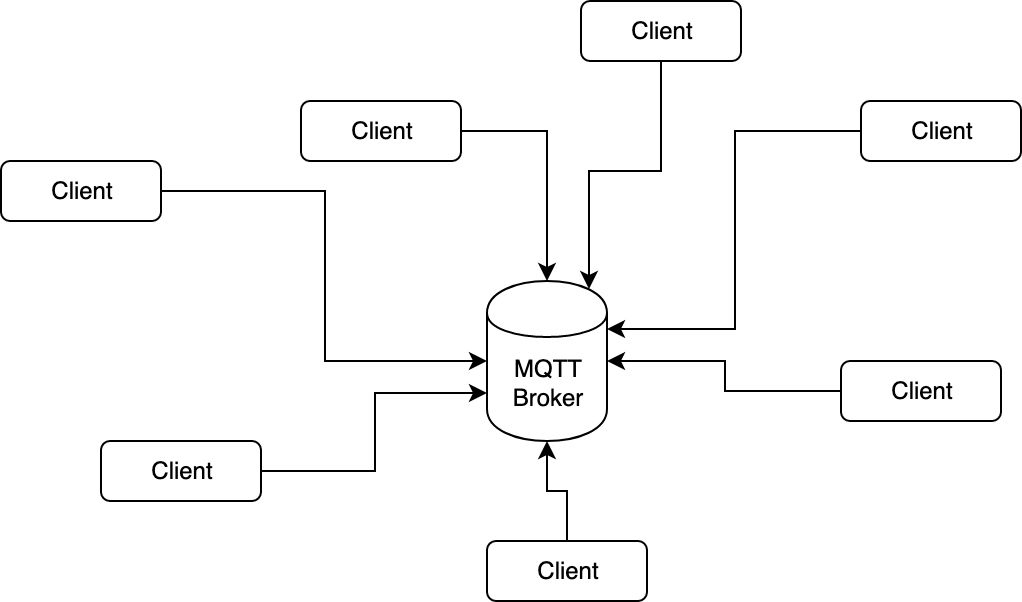
Die MQTT-Architektur
Für MQTT wird ein Broker benötigt, die zentrale Instanz an welche alle Clients ihre Nachrichten senden und sie von diesem Broker empfangen. Im Umkehrschluss bedeutet dies, das sich die Clients untereinander nicht kennen. Die gesamte Kommunikation läuft über dem Broker ab. Die Nachrichten werden nicht einfach wahllos an den Broker geschickt, sondern an ein sogenanntes Topic, ein Thema z.B. bad/lichtsensor1. Diese Topics sind hierarchisch aufgebaut und werden wie ein Pfad, mit einem Slash als Trennzeichen, definiert. Die Topics können von anderen Clients abonniert werden, so das diese bei einer neuen Nachricht betreffend des Topics informiert werden. Durch den hierarchischen Aufbau ist es möglich alle Topics einer bestimmten Hierarchieebene zu abonnieren. So würde der Topic:
bad/#
alle Untertopics von bad abonnieren. Eine weitere Möglichkeit ist es an einer bestimmten Stelle im Pfad das Sonderzeichen Plus zu benutzen:
+/lautsprecher/
In diesem Beispiel würden alle Lautsprecher aller Zimmer abonniert, so wären bad/lautsprecher als auch wohnzimmer/lautsprecher abgedeckt.
Nach der Verbindung mit einer CONNECT-Nachricht antwortet der Broker mit einer CONNACK-Nachricht. Damit ist die Verbindung etabliert. Der Client abonniert in dem Beispiel (siehe Bild) den Topic bad/lichtsensor1. Nun kann der Broker den Client über Nachrichten dieses Topic betreffend informieren. Wenn eine solche Nachricht eingeht, reagiert der Client, indem er auf dem Topic bad/lautsprecher die Nachricht bzw. den Wert on hinterlässt. Soll die Verbindung später wieder beendet werden, so wird eine DISCONNECT-Nachricht gesendet.
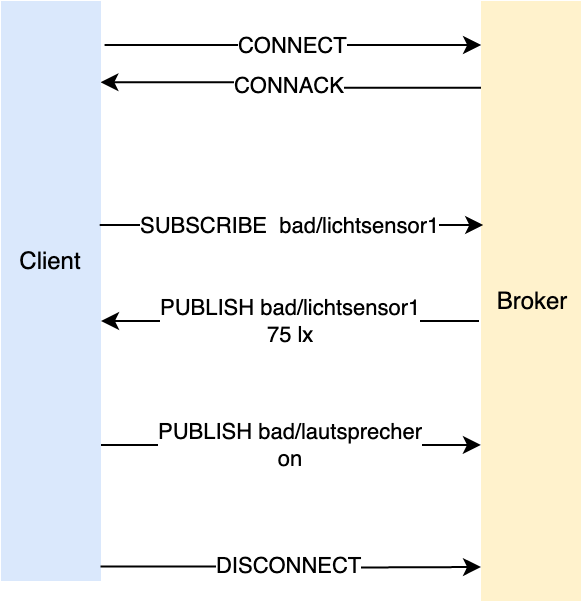
Die Kommunikation zwischen Client und Broker
Wenn ein Client keine aktive Verbindung zum Broker hat und eine neue Nachricht auf einem Topic aufläuft, auf welches der Client ein Abonnement hält, so verpasst er diese Nachricht. Anders sieht es aus, wenn der Sender beim Senden der Nachricht das sogenannte Retain-Flag für die Nachricht gesetzt hat. In diesem Fall stellt der Broker die Nachricht später noch zu.
Für den Fall, das die Verbindung vom Client nicht beendet wird bzw. beendet werden kann, existiert in MQTT ein sogenanntes Testament. So kann es bei Sensoren, die über Batterien gespeist sind durchaus vorkommen, dass die Verbindung plötzlich abbricht. Deshalb kann ein Client ein Testament, eine Nachricht auf ein Topic, hinterlegen, welche im Falle des Verbindungsabbruches vom Broker über das Topic versendet wird.
In der Praxis existieren zwei Versionen von MQTT: MQTT 3 welches die größte Basis besitzt und MQTT 5, welches mit einigen Neuerungen aufwarten kann, um das Protokoll fit für die Zukunft zu machen. Spezifiziert wird MQTT von OASIS, der Organization for the Advancement of Structured Information Standards. Die größten Unterschiede zwischen der letzten 3er-Version 3.1.1 und 5 sind Shared Subscriptions, welche Load Balancing auf Clientseite erlauben, Negative Acks eine Art Statuscodes ähnlich den HTTP-Statuscodes und User Properties, bei denen es sich um die Entsprechung zu den HTTP-Headern handelt. Diese können unter anderem für Metadaten genutzt werden. Ergeben haben sich diese Neuerungen hauptsächlich durch die Rückmeldungen aus der Community über die letzten Jahre.
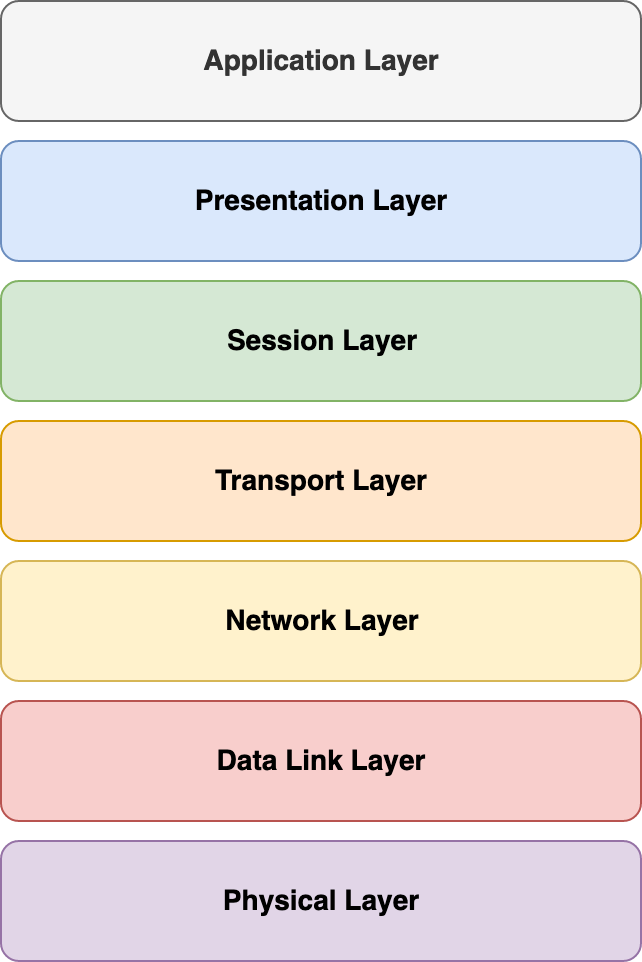
Das OSI-Modell
Technisch basiert das MQTT-Protokoll auf TCP/IP. Dabei werde die Ports 1883 und 8883 genutzt. Der erste Port ist für die unverschlüsselte, der zweite Port für die verschlüsselte Kommunikation reserviert. Im OSI-Schichtenmodell befindet sich MQTT, wie HTTP auf dem Application Layer (OSI Layer 7). Im Gegensatz zu HTTP ist MQTT bleibt die Verbindung bei MQTT auch bestehen, wenn keine Daten übertragen werden.
Gestartet wird die Kommunikation des Clients mit einer CONNECT-Nachricht, woraufhin der Broker das Ganze mit einer CONNACK-Nachricht bestätigt. Nun kann der Client Topics abonnieren und Informationen zu einem Topic senden (PUBLISH).
MQTT beherrscht drei verschiedene Stufen des Quality of Service (QoS). Stufe 0 ist vom Modell her Fire-and-Forgot; die Nachricht wird einmal versendet und danach vom Broker vergessen. Ob sie ankommt, ist auf dieser QoS-Stufe nicht relevant. Bei Stufe 1 garantiert der Broker das die Nachricht mindestens einmal zugestellt wird, sie kann aber durchaus auch mehrfach bei den Clients ankommen. Stufe 2 hingegen garantiert, dass die Nachricht exakt einmal ankommt. Offiziell sind die QoS-Stufen wie folgt benannt:
At most once (0)
At least once (1)
Exactly once (2)
Je nach gewählter QoS-Stufe kommt es zu vermehrter Kommunikation über das MQTT-Protokoll. Bei Stufe 1 würde die Gegenstelle nach einer PUBLISH-Nachricht mit einer PUBACK-Nachricht antworten. Ohne eine solche Nachricht wird bei Stufe 1 der Sendevorgang so lange wiederholt, bis er von der Gegenseite bestätigt wurde. Deshalb ist nicht sichergestellt das die Nachricht nur einmal ankommt.
Wenn dies nicht gewünscht ist, kann stattdessen die QoS-Stufe 2 genutzt werden. Hier wird in der PUBLISH-Nachricht vom Sender eine ID mitgegeben. Nach dem Empfang wird die Nachricht gespeichert, aber noch nicht verarbeitet. Der Empfänger sendet eine PUBREC-Nachricht mit der ID an den Sender. Erhält der Sender diese Nachricht, sendet er eine Release-Nachricht (PUBREL), an den Empfänger. Als letzte Aktion sendet Empfänger ein PUBCOMP-Nachricht an den Sender und verarbeitet anschließend die Nachricht. Der Sender löscht beim Empfang der PUBCOMP-Nachricht die Nachricht.
Hintergrund für die unterschiedlichen Qualitätsstufen ist der Ressourcenverbrauch; je niedriger die QoS-Stufe um so weniger Ressourcen wie Zeit, Speicher und CPU, werden benötigt, um die Nachricht zu verarbeiten.
An Brokern und Client-Bibliotheken mangelt es MQTT nicht. Zu den bekanntesten Brokern gehören Mosquitto, HiveMQ und VerneMQ. Im Produktivbetrieb muss auf eine Absicherung der Topics geachtet werden. So ist es je nach Broker möglich das diese eine Authentifizierung der Clients verlangen und erst dann den Zugriff auf die Topics erlauben. Client-Bibliotheken für MQTT gibt es wie Sand am Meer, für unterschiedlichste Systeme wie Arduino, C, Java, .NET, Go und viele weitere Sprachen und Frameworks.
MQTTBox unter macOS
Daneben existieren grafische Client, welche die Nachrichten auf dem Broker anzeigen und die Interaktion mit einem Broker ermöglichen. Zu diesen Clients gehören unter anderem MQTT.fx, mqtt-spy und MQTTBox.