Die Java-IDE IntelliJ IDEA verfügt über eine Reihe von Refactoring-Methoden. So können Variablen umbenannt, Methoden extrahiert und vieles mehr mit Hilfe der Refactoring-Werkzeuge bewerkstelligt werden. Manchmal schießt die IDE beim Refactoring über das Ziel hinaus. So kann es passieren, das bei der Umbenennung einer Variable nicht nur diese, sondern auch Zeichenketten mit dem gleichen Namen umbenannt werden.
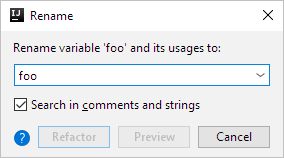
Der Rename-Dialog der IDE
Verantwortlich hierfür ist eine optionale Funktionalität in der Rename-Funktionalität. Um diese zu deaktivieren muss der Rename-Dialog geöffnet werden. Dies geschieht indem die Tastenkombinationen Shift + F6 knapp eine habe Sekunde gedrückt wird, bis der entsprechende Dialog erscheint. In diesem Dialog muss nun die Checkbox mit der Beschreibung Search in comments and strings deaktiviert werden. Anschließend werden nur noch die gewünschten Strukturen im Quellcode umbenannt, ohne dass sich die Umbenennung auf weitere Zeichenketten auswirkt.