Heute ist das dreißigjährige Jubiläum des GameBoy. Da wird der eine oder andere sicherlich nostalgisch an die gute alte Zeit zurückdenken. Nun kann auf dem GameBoy nicht nur gespielt werden was die Hersteller damals veröffentlichten, sondern auch eigene Entwicklungen für den GameBoy erstellt werden.
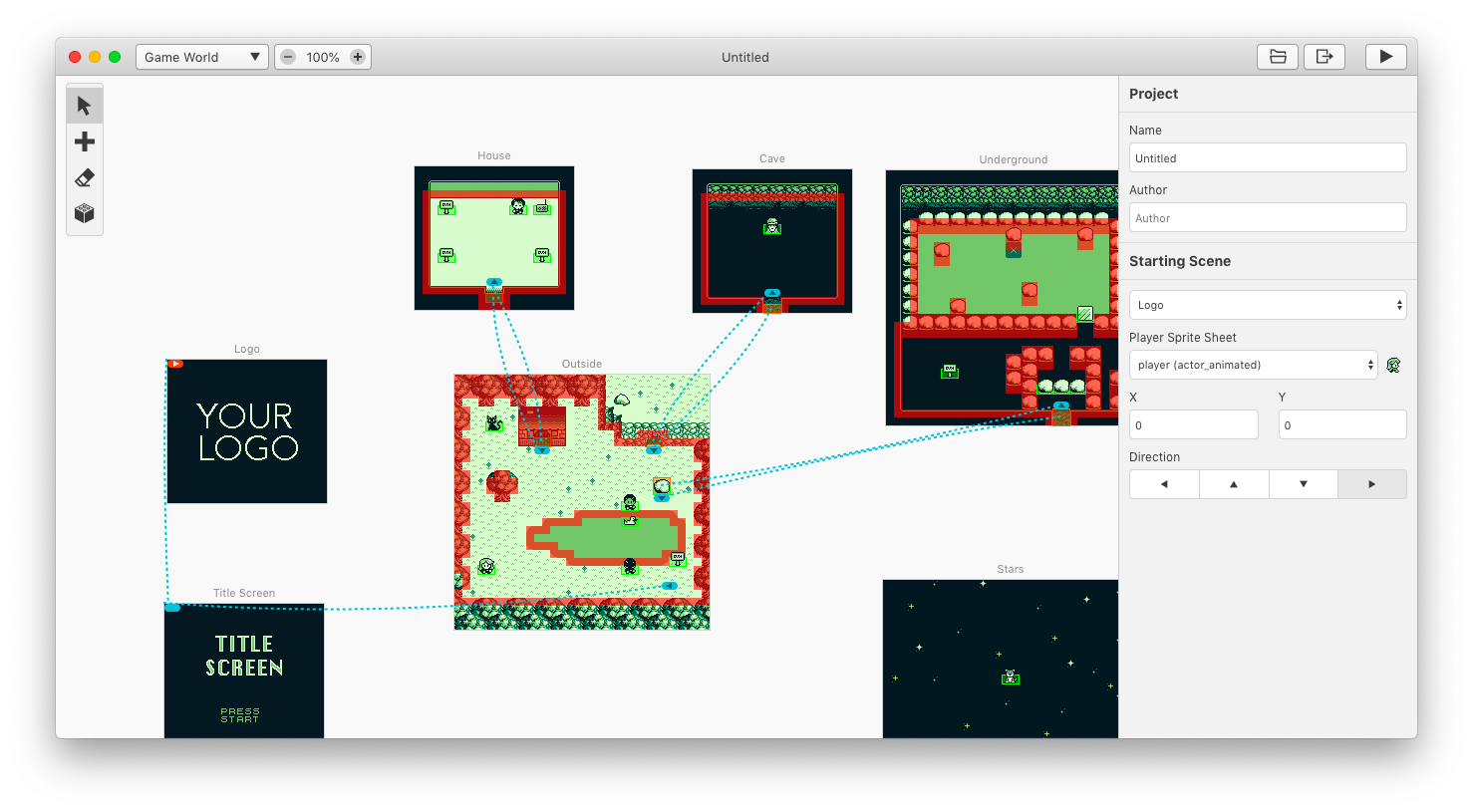
Das GB Studio unter macOS
Den meisten dürfte dies allerdings zu kompliziert sein. Schließlich ist der GameBoy aufgrund seiner begrenzten Ressourcen keine sonderlich einfache Umgebung. Mit dem GB Studio soll die Entwicklung trotzdem einfach möglich sein. Mithilfe des GB Studios ist es möglich grafische Adventure schnell und unkompliziert im Stil eines Game Makers zu erzeugen. Als Export-Formate werden ROMs und ein Web-Export unterstützt.
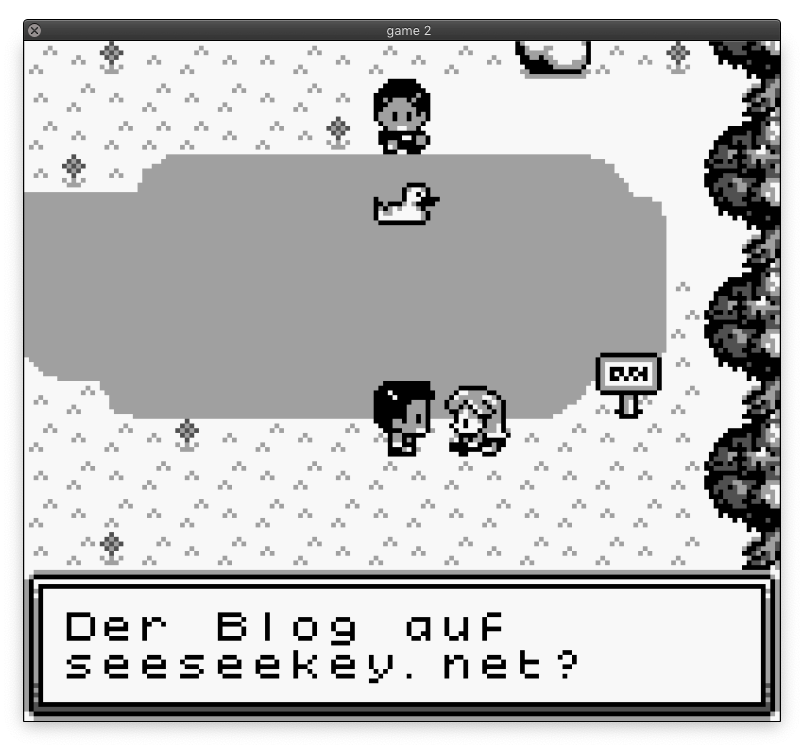
Das Spiele-ROM läuft im Emulator
Lizenziert ist GB Studio unter der MIT Lizenz. Da es auf Electron aufbaut, existieren Versionen für macOS, Linux und Windows. Der Quelltext des Projektes ist auf GitHub gehostet. Er ist unter der MIT-Lizenz lizenziert und damit freie Software. Die offizielle Seite des Projektes, auf der unter anderem die Dokumentation zu finden ist, ist unter gbstudio.dev zu finden.