Gestern schrieb ich einen Artikel über die Möglichkeiten ein Element aus einer Liste unter Java zu ermitteln. Dort wurde unter anderem eine Lösung mittels der Stream-API aufgezeigt. In einem Kommentar zu dem Artikel kam die Frage nach der Performance dieser Methode auf. Aus diesem Grund habe ich einen kleinen Benchmark geschrieben, welcher die Unterschiede in der Performance ermitteln sollte. Der Testfall bestand daraus ein Element aus einer Liste zu ermitteln. Dazu wird eine Liste mit knapp 125.000 Elementen erzeugt. Nun wurde mit unterschiedlichen Methoden versucht das entsprechende Element zu ermitteln. Das gesuchte Element befindet sich in den Testfällen immer an der Position 75.004 der Liste. Erzeugt wird die Liste mit der Methode getElements:
private List<Element> getElements() {
List<Element> elements = new ArrayList<>();
// Add 75000 elements
for (int i = 0; i < 75000; i++) {
elements.add(new Element(String.valueOf(i), String.valueOf(i)));
}
elements.add(new Element("Suppe", "Löffel"));
elements.add(new Element("Wasser", "Flüssigkeit"));
elements.add(new Element("Käse", "Gelb"));
elements.add(new Element("Huhn", "Ei"));
// Add 50000 elements
for (int i = 0; i < 50000; i++) {
elements.add(new Element(String.valueOf(i), String.valueOf(i)));
}
return elements;
}
Vom Gefühl her hätte ich vermutet, das die Stream-API immer langsamer ist als die klassische Iteration durch die Liste. Vier unterschiedliche Methoden wurden für das Benchmark implementiert. Beim Benchmark Iterate list wird die Liste über eine foreach-Schleife iteriert und beim entsprechenden Element abgebrochen:
for (Element element : elements) {
if ("Huhn".equals(element.Key)) {
specificElement = element;
break;
}
}
Die nächste Variante iteriert die Liste ebenfalls durch, nutzt aber die klassische Variante über den Index:
for (int j = 0; j < elements.size(); j++) {
Element element = elements.get(j);
if ("Huhn".equals(element.Key)) {
specificElement = element;
break;
}
}
Anschließend folgt eine Variante über die Stream-API, bei welcher die Methode findFirst genutzt wird:
specificElement = elements.stream() .filter(element -> "Huhn".equals(element.Key)) .findFirst() .orElse(null);
Bei der letzten Variante wird ebenfalls die Stream-API genutzt, nur diesmal wird findAny genutzt:
specificElement = elements.stream() .filter(element -> "Huhn".equals(element.Key)) .findAny() .orElse(null);
Die Idee bei der Nutzung der Methode findAny ist, dass diese schneller ist, da die Suche theoretisch parallelisiert werden kann. Im JavaDoc zu der Methode wird das Ganze so beschrieben:
The behavior of this operation is explicitly nondeterministic; it is
* free to select any element in the stream. This is to allow for maximal
* performance in parallel operations; the cost is that multiple invocations
* on the same source may not return the same result.
Der Benchmark selber führt für jeden Testfall 75.000 mal durch, damit sich Ungenauigkeiten bei einzelnen Läufen wegmitteln und etwaige Optimierung zum tragen kommen können. Wird die Ausführungszeit über alle 75.000 Durchläufe betrachtet ergibt sich folgendes Bild:
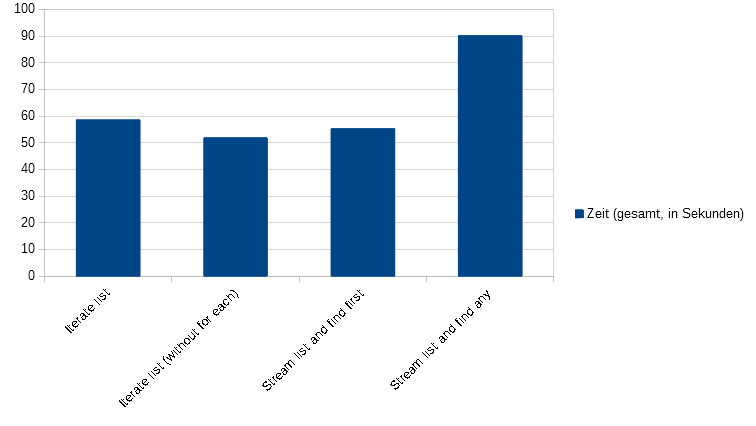
Die Durchführungszeiten über alle Durchläufe
Bei der Betrachtung der einzelnen Durchläufe ergibt sich ein ähnliches Bild:
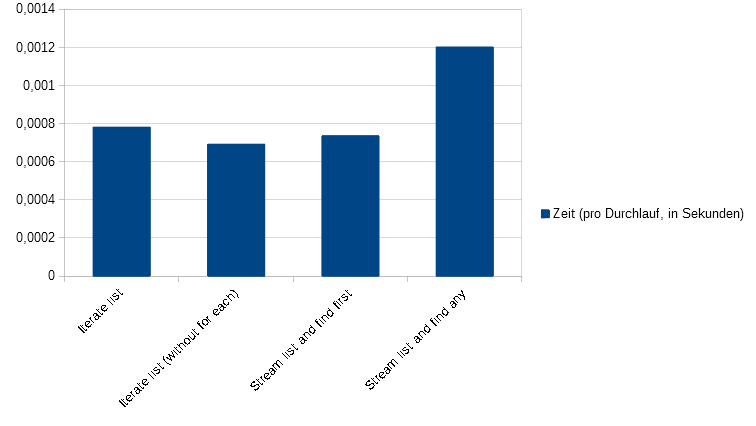
Die Durchführungszeiten pro Durchlauf
Die ermittelten Werte sehen wie folgt aus:
Iterate list Time in seconds (total): 58.621323501 Time in seconds (per run): 0.00078161764668 Iterate list (without for each) Time in seconds (total): 51.9264994 Time in seconds (per run): 0.0006923533253333333 Stream list and find first Time in seconds (total): 55.3019915 Time in seconds (per run): 0.0007373598866666667 Stream list and find any Time in seconds (total): 90.196209799 Time in seconds (per run): 0.0012026161306533333
Die schnellste Variante scheint die klassische Iteration über den Index zu sein, anschließend folgt die Variante mit der Stream-API und der Methode findFirst. Danach kommt die Iteration mittels einer foreach-Schleife und am Ende folgt weit abgeschlagen die Stream-API-Variante mit der Methode findAny. Das diese so schlecht abschneidet hat mich überrascht. Natürlich sollten Zahlen aus einem Benchmark immer mit Vorsicht genoßen werden, da es sich immer um eine künstliche Gegenüberstellung handelt. Das komplette Benchmark befindet sich auf GitHub und ist unter der MIT-Lizenz lizenziert und damit freie Software.
Hi, könntest du den Test mit einem weiteren Testfall anreichern: parallelStream() statt stream(). Vielleicht geht da ja noch was mit der Performance.
Ich habe die beiden Testfälle zum Benchmark hinzugefügt und einen neuen Durchlauf gemacht:
Die parallelen Varianten zeigen nochmal signifikante Performancegewinne.
Ah OK mit parallel an dürfte sich das bei größeren listen echt lohnen. Dann behalte ich das mal im Hinterkopf