Da der Google Reader ja bald eingestellt wird, sollte man sich langsam darüber Gedanken machen, wie es weitergeht. Natürlich kann man auf fremde Dienste wie Feedly wechseln. Allerdings behagt dieser Gedanke nicht jedem, da man wieder an einen bestimmten Anbieter gebunden ist. Eine Abhilfe schafft hier die Software „Tiny Tiny RSS“ welcher auf PHP und MySQL (wahlweise auch PostgreSQL aufsetzt). Die Software selbst steht dabei unter der GPLv2.

Probleme bei der Installation
Nachdem man die Software heruntergeladen hat und auf seinen Webspace kopiert hat, kann es auf einigen Systemen beim Test der Konfiguration zu Problemen mit der Einstellung „open_basedir“ kommen. Hat man hier keine Möglichkeit dies umzustellen oder möchte dies nicht, so muss man einige kleinere Anpassungen am Quelltext von „Tiny Tiny RSS“ vornehmen. Dazu wird in den Dateien „include/sanity_check.php“ und „install/index.php“ der Absatz:
if (ini_get("open_basedir")) {
array_push($errors, "PHP configuration option open_basedir is not supported. Please disable this in PHP settings file (php.ini).");
}
auskommentiert. Danach sollte die Installation gelingen. Nach der Installation kann man sich mit den Standardnutzerdaten „admin“ und „password“ anmelden. Das Passwort sollte man anschließend sofort ändern. In den Einstellungen wird unter Benutzer ein neuer Nutzer angelegt, damit man nicht mit einem administrativen Account arbeiten muss.
Wenn man seine Daten mittels Google Takeout exportiert hat, kann man die „subscriptions.xml“ aus dem Export in „Tiny Tiny RSS“ importieren. Dazu geht man in den Einstellungen auf den Tab „Feed“ und dort auf „OPML“. Dann kann man die entsprechende Datei importieren.
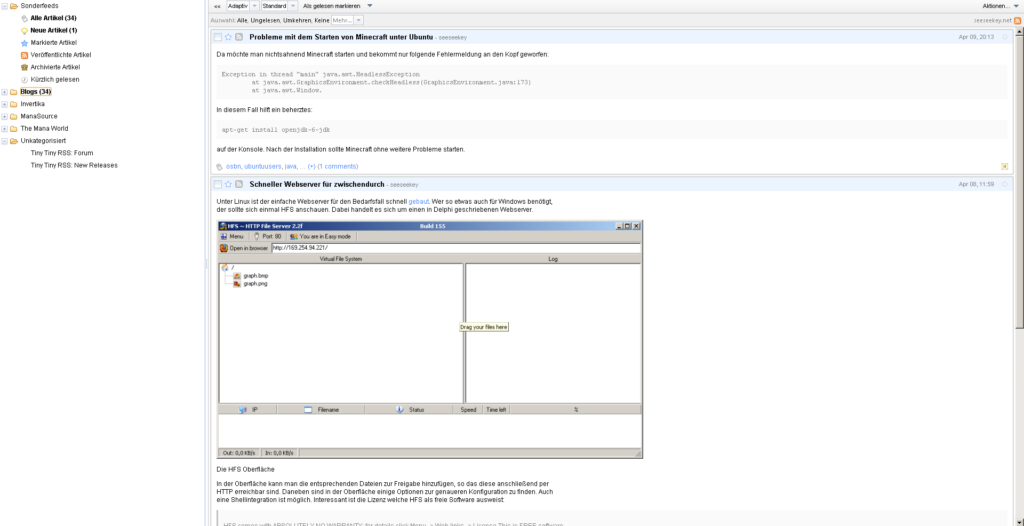
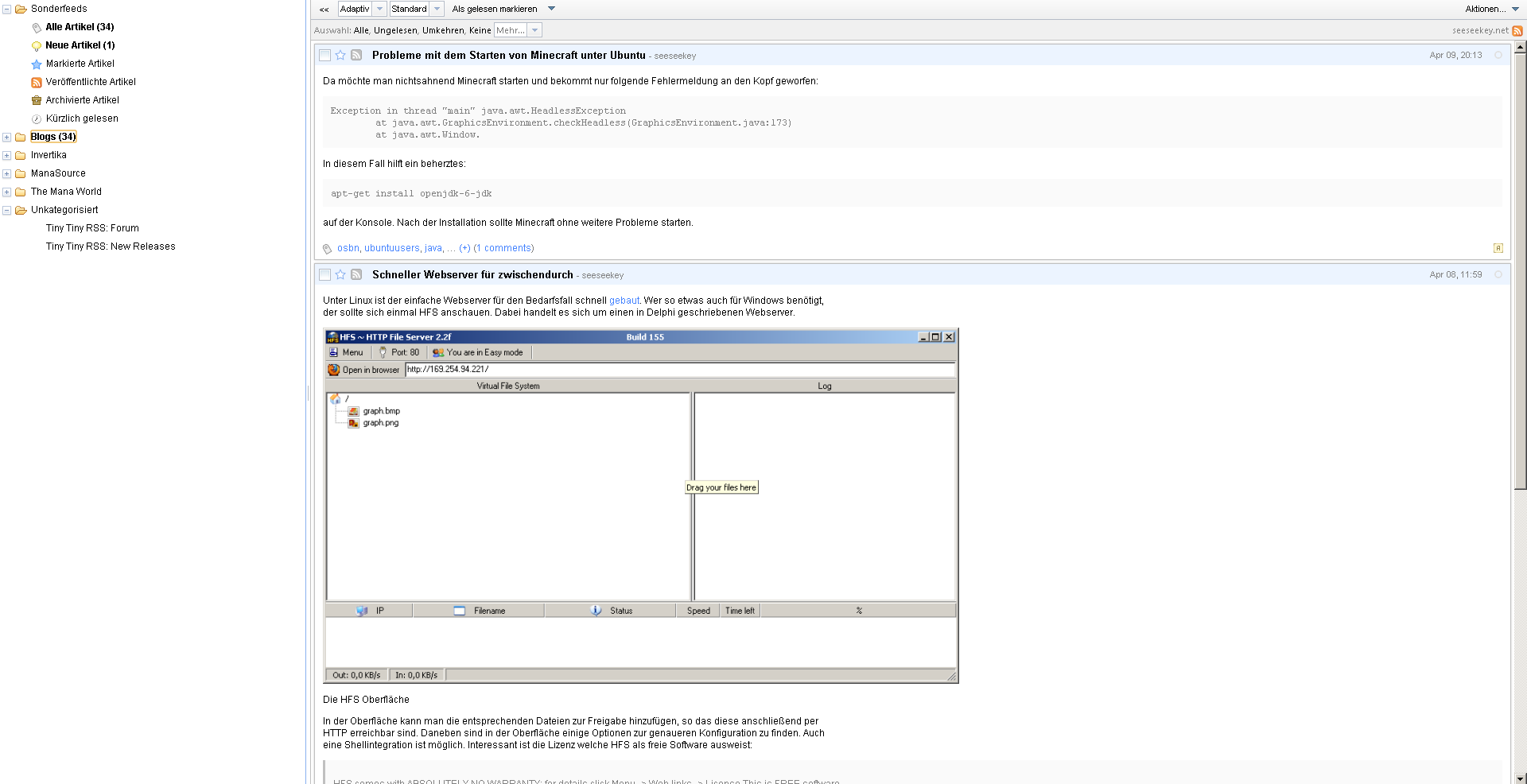
Tiny Tiny RSS in Aktion
Danach kann man seine Feeds in der Oberfläche bewundern. Die erste (manuelle) Aktualisierung kann dabei durchaus einige Zeit in Anspruch nehmen. Nun gilt es die automatische Aktualisierung der Feeds mittels eines Cronjobs in Angriff zu nehmen. Dazu wird ein Cronjob erstellt welcher alle 15 Minuten die URL:
http://example.org/ttrss/backend.php?op=globalUpdateFeeds&daemon=1
aufruft, wobei der Teil „http://example.org/tsrss/“ natürlich durch die eigene URL ersetzt werden muss. Die Webapplikation stellt auf Wunsch (in den Einstellungen konfigurierbar), eine API zur Verfügung, so das man auch Apps mit ihr betreiben kann. So gibt es für Android einen Client mit dem selben Namen.
Für iOS scheint es da noch keine adäquate Lösung zu geben wobei ich mir wünschen würde, das Mr.Reader das ganze in eine neue Version integrieren würde.
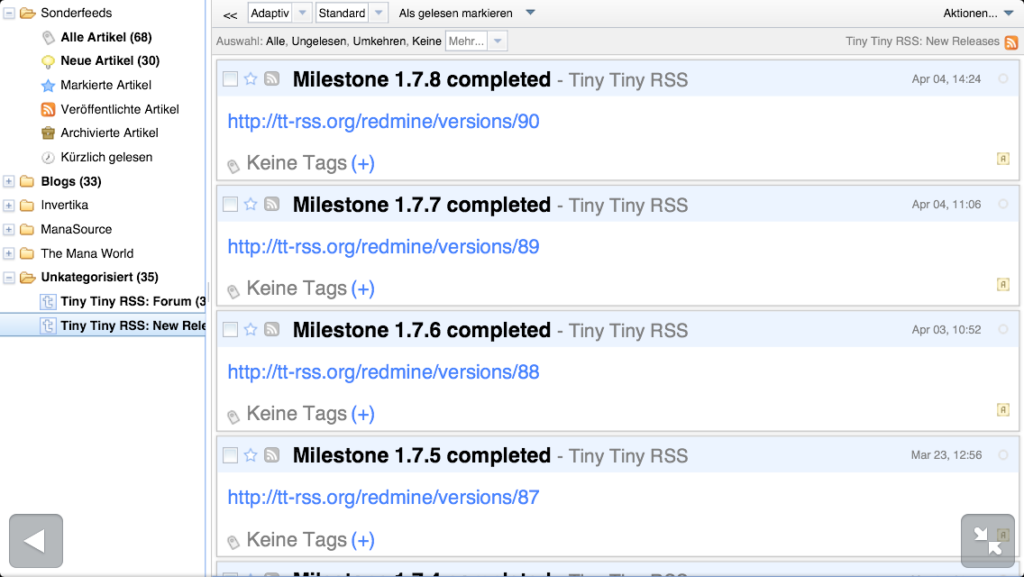
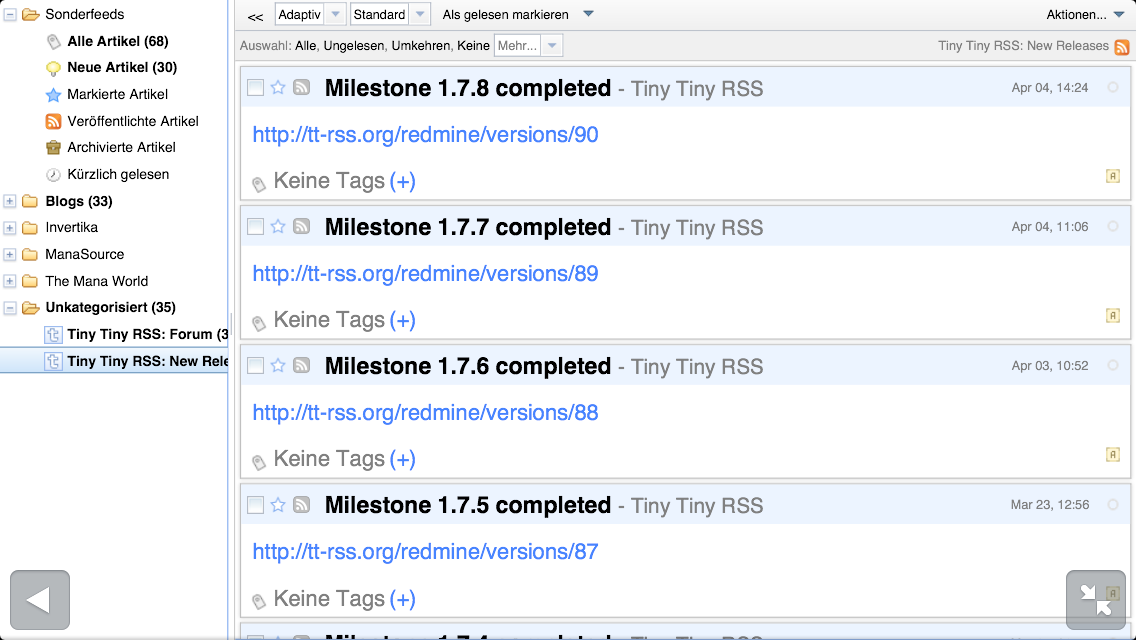
Die Mobilansicht von Tiny Tiny RSS
Die Mobilansicht auf entsprechenden Geräten ist leider etwas fummelig, wobei es sich nicht um die richtige Mobilansicht handelt, sondern um die normale Ansicht. Die mobile Ansicht kann über das System Plugin „mobile“ aktiviert werden. Allerdings wird sie nicht mehr gewartet und ist wohl auch nicht der Weisheit letzter Schluss.
Abhilfe schafft hier ttrss-mobile welches über die API mit dem Hauptsystem kommuniziert. Nachdem man die Software auf seinen Webspace hochgeladen hat, muss man noch die Pfade in der „conf.js“ anpassen. Anschließend kann man sich mit seinen Zugangsdaten einloggen.
In den Einstellungen gibt es auch einige interessante Nutzerplugins wie z.B. „mail“ mit welchem man Artikel per Mail versenden kann. Alles in allem ist „Tiny Tiny RSS“ ein robustes Stück Software, welches nach der Installation genau das macht was es soll. Die offizielle Seite der Software ist dabei unter http://tt-rss.org zu finden.
Weitere Informationen gibt es unter:
http://michaelsonntag.net/tiny-tiny-rss-tutorial-1-installation-konfiguration/
http://michaelsonntag.net/tiny-tiny-rss-tutorial-2-optische-anpassungen-und-plugins/
http://michaelsonntag.net/tiny-tiny-rss-tutorial-3-artikel-feiner-strukturieren/
http://michaelsonntag.net/tiny-tiny-rss-tutorial-4-noch-ein-paar-kleinigkeiten/
http://www.linux.com/learn/tutorials/322446-weekend-project-replacing-google-reader-with-tiny-tiny-rss