Gestern warf ich einen ersten Blick auf die Beta von iOS 7. Das Update geht dabei problemlos von statten und danach wird man vom neuen Entspeerbildschirm begrüßt. Dieser lässt sich nun einfacher entsperren, da man nur irgendwo von links nach rechts auf dem Display wischen muss.
Für eine Beta läuft das ganze relativ stabil, allerdings kommen Abstürze ab und an vor. Das außert sich meist, in dem man unvermittelt das Apple Logo sieht, aber nach ein paar Sekunden ist die Oberfläche wieder da. Die PIN für die SIM-Karte muss dabei nicht noch einmal eingegeben werden. Was sich gut macht sind die Ordner für die Apps in welchen man nun die Seiten wechseln kann, wie es bei der entsprechenden Keynote gezeigt wurde. Auch die neue Optik von Siri macht etwas her, wobei die Beta augenscheinlich noch mit der alten Siri-Stimme arbeitet.
Eine sehr schöne Sache ist der Schnellzugriff, der aktiviert werden kann in dem man vom unteren Rand den Finger in das Bild schiebt. Hier kann man WLAN, Bluetooth, die Bildschirmorientierung und vieles mehr umschalten. Unter Android gibt es ähnliche Funktionen ja nun schon seit einer oder zwei Ewigkeiten. Als sehr praktisch erweisen sich die Schnellzugriffstasten für die Taschenlampe, den Wecker und Taschenrechner sowie die Kamera.
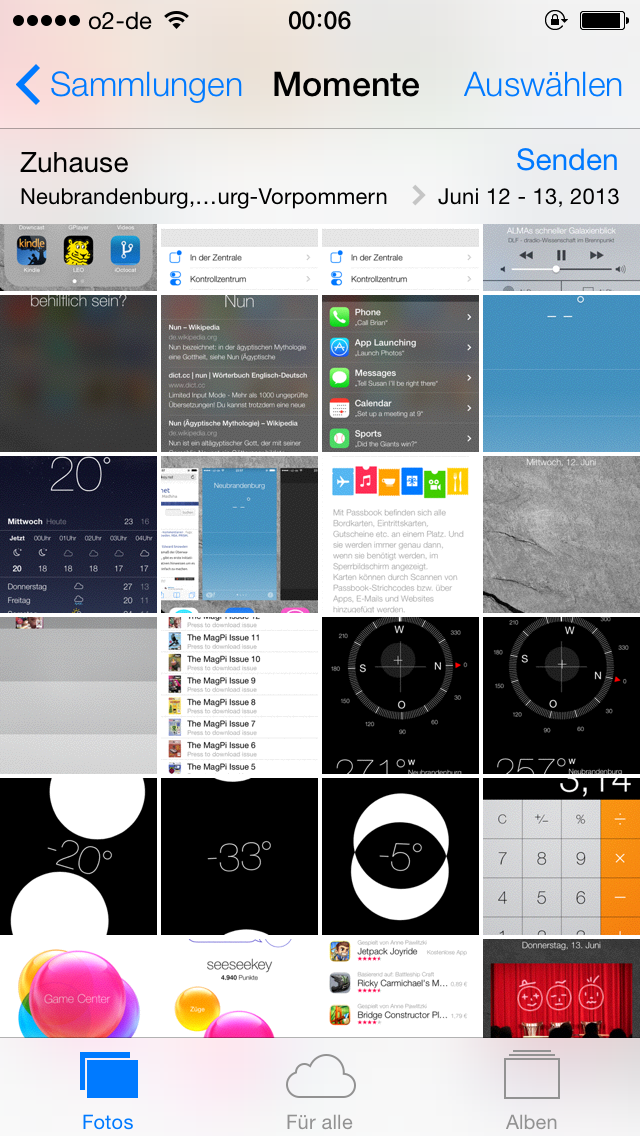
Die Sortierung in der Galerie nach Aufnahmeorten ist ganz annehmbar, positiv überrascht hat mich jedoch die extra Kategorie für die angefertigten Panoramen. In der Musik App gibt es bis auf das Facelift nicht neues zu entdecken, iTunes Radio ist zur Zeit noch nicht vorhanden. Das gleiche gilt für den Appstore der natürlich ebenfalls einem Facelift unterzogen wurde. Die Funktion „In der Nähe“ welche beliebte Apps in der Nähe anzeigen soll, funktioniert auch noch nicht.
Einige App Icons von 3rd Party Apps wie dem „AppTicker“ haben noch Probleme mit den Icons wie man in der Galerie sehen kann. Auch gibt es manchmal Probleme mit der Anzeige einiger Apps wie z.B. „Downcast“ und „1-Bit Camera“. Der „iA Writer“ lässt sich in der Betaversion garnicht zum Start bewegen. An einigen Stellen gönnt sich das System ab und an eine Gedenksekunde, aber alles in allem läuft es erfrischend flott. Zusammenfassend kann man sagen, das die Beta benutzbar ist und an vielen Stellen wie dem Schnellzugriff oder dem neuen Safari Spaß macht.