Für wahrscheinlich jede Programmiersprache existieren mehr oder weniger viele Frameworks, welche dem Entwickler bestimmte Aufgaben abnehmen und somit die Entwicklung beschleunigen. Neben den größeren Framework existieren auch eine Reihe von Frameworks mit einem minimalistischeren Ansatz. Eines dieses sogenannten Microframeworks ist Slim. Entwickelt wird und wurde Slim für PHP.
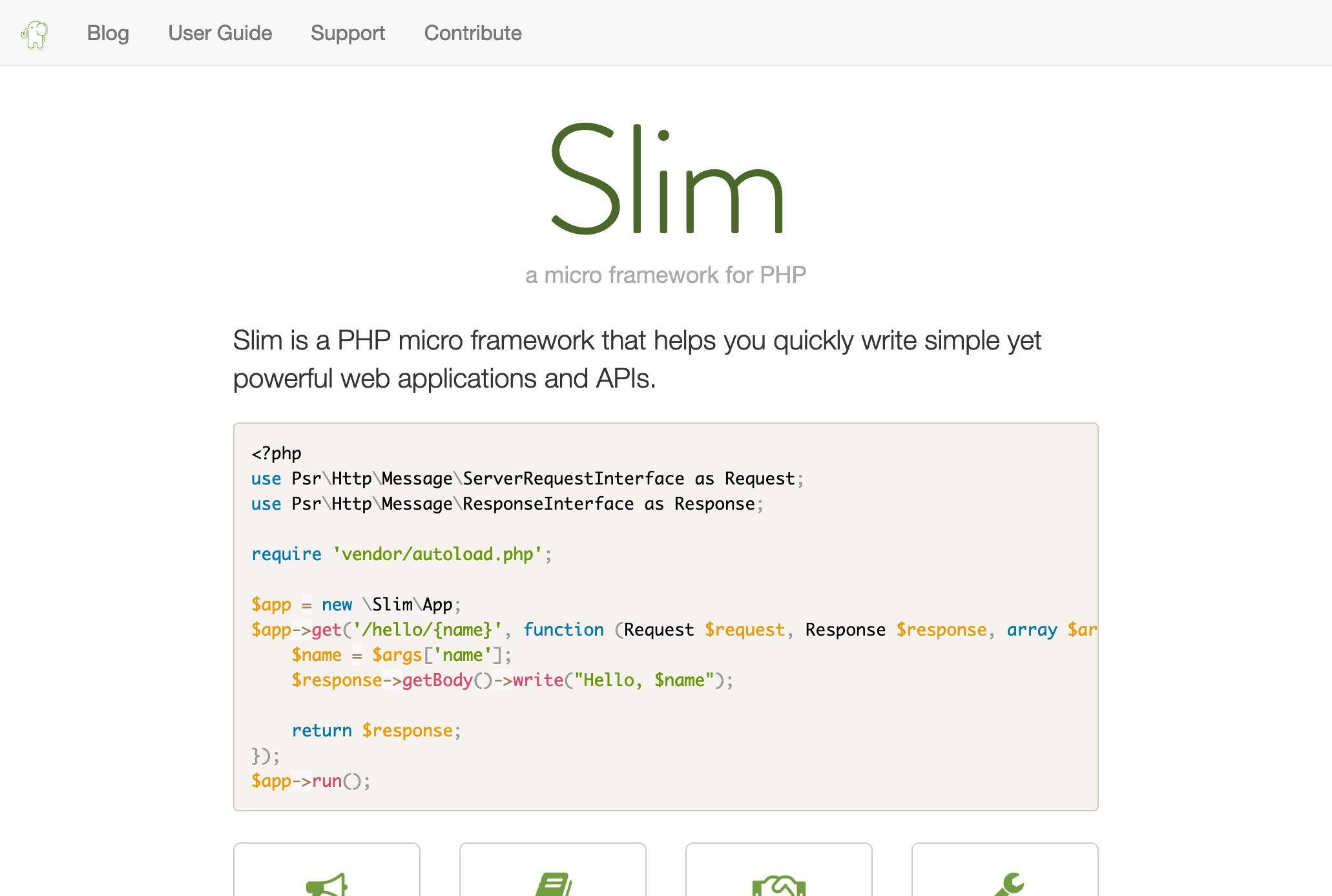
slimframework.com
Slim eignet sich sehr gut für die Umsetzung für REST-APIs bzw. RESTful Webservices. Um ein Projekt zu erstellen, kann der Paket- bzw. Dependency-Manager Composer genutzt werden:
composer create-project slim/slim-skeleton exampleapp
Damit wird ein Grundprojekt angelegt mit welchem gearbeitet werden kann. Auch von seitens des Swagger-Toolings wird Slim unterstützt. So kann eine API über den Swagger-Editor definiert werden und anschließend für das Slim-Framework exportiert werden. Der Quelltext des Frameworks ist auf GitHub zu finden. Es ist unter MIT-Lizenz lizenziert und damit freie Software. Die offizielle Seite des Projektes ist unter slimframework.com zu finden.