Für die freie Grammatik- und Rechtschreibprüfung LanguageTool existieren eine Reihe von Add-ons, unter anderem für den Browser Firefox.
Standardmäßig nutzen diese Add-ons den vom Projekt bereitgestellten Server unter languagetool.org. Nicht jeder möchte seine Daten zur Korrektur an Dritte schicken und so besteht die Möglichkeit einen eigenen Server aufzusetzen. Dieser kann lokal betrieben oder auf einem eigenen Server installiert werden. In diesem Artikel soll die Installation unter Ubuntu beschrieben werden. Im ersten Schritt muss sich auf dem Server eingeloggt und dort ein neuer Nutzer angelegt werden:
adduser languagetool
su languagetool
cd
Nachdem der Nutzer angelegt wurde und in das entsprechende Home-Verzeichnis des Nutzers gewechselt wurde, kann das LanguageTool heruntergeladen und entpackt werden:
wget https://languagetool.org/download/LanguageTool-4.5.zip
unzip LanguageTool-4.5.zip
mv LanguageTool-4.5 server
rm LanguageTool-4.5.zip
Neben dem LanguageTool, werden noch sogenannte N-Gramme heruntergeladen. Diese dienen der Verbesserung der Erkennungsleistung des LanguageTool. Sie belegen knapp 27 GiB auf der Festplatte, müssen aber nicht zwingend installiert werden:
mkdir ngrams
wget https://languagetool.org/download/ngram-data/ngrams-de-20150819.zip
wget https://languagetool.org/download/ngram-data/ngrams-en-20150817.zip
wget https://languagetool.org/download/ngram-data/ngrams-es-20150915.zip
wget https://languagetool.org/download/ngram-data/ngrams-fr-20150913.zip
wget https://languagetool.org/download/ngram-data/ngrams-nl-20181229.zip
unzip ngrams-de-20150819.zip
unzip ngrams-en-20150817.zip
unzip ngrams-es-20150915.zip
unzip ngrams-fr-20150913.zip
unzip ngrams-nl-20181229.zip
rm ngrams-de-20150819.zip
rm ngrams-en-20150817.zip
rm ngrams-es-20150915.zip
rm ngrams-fr-20150913.zip
rm ngrams-nl-20181229.zip
Damit ist das LanguageTool installiert. Ein erster Test kann erfolgen, indem der Server mittels:
java -cp languagetool-server.jar org.languagetool.server.HTTPServer --port 8081
gestartet wird. Über Curl können erste Testdaten an den Server gesendet werden:
curl --data "language=en-US&text=a first test" http://localhost:8081/v2/check
In meinem Setup wird der Server auf dem Port 8081 (oder einem beliebigen anderen Port betrieben) und ist über einen Reverse Proxy, in diesem Fall Nginx, erreichbar. Dazu muss die Konfiguration angepasst werden:
nano /etc/nginx/sites-available/example
In der Nginx-Konfigurationsdatei wird nun folgende Konfiguration hinterlegt:
server {
listen 443 ssl;
listen [::]:443 ssl;
ssl_certificate /etc/letsencrypt/live/api.example.org/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/api.example.org/privkey.pem;
root /var/www/example/api;
index index.php index.html index.htm;
server_name api.example.org;
# proxy for languagetool
location /languagetool/ {
proxy_pass http://localhost:8081/v2/;
}
} Nachdem die Konfiguration für Nginx hinterlegt wurde, wird Nginx neugestartet:
nginx restart
Über den Browser kann die API nun getestet werden:
https://api.example.org/languagetool/check?language=en-US&text=Wong wong wong
Damit ist die Konfiguration des LanguageTool allerdings noch nicht abgeschlossen. Für den produktiven Betrieb wird eine Konfigurationsdatei unter /home/languagetool/server/ erstellt:
nano languagetool.cfg
Diese Datei wird mit folgendem Inhalt befüllt:
languageModel=/home/languagetool/ngrams
Damit der Service automatisch startet, wird eine systemd-Unit angelegt:
nano /etc/systemd/system/languagetool.service
Diese Datei wird mit folgendem Inhalt befüllt:
[Unit]
Description=LanguageTool
After=syslog.target
After=network.target
[Service]
Type=simple
User=languagetool
Group=languagetool
WorkingDirectory=/home/languagetool/server
ExecStart=/usr/bin/java -cp /home/languagetool/server/languagetool-server.jar org.languagetool.server.HTTPServer --config languagetool.cfg --port 3001 --allow-origin "*"
Restart=always
Environment=USER=git HOME=/home/languagetool
[Install]
WantedBy=multi-user.target
Nachdem die Datei angelegt wurde, wird sie aktiviert und anschließend der Service gestartet:
systemctl enable languagetool
service languagetool start
Zum Test der N-Gramme kann folgende URL aufgerufen:
https://api.example.org/languagetool/check?language=en-US&text=I%20want%20to%20go%20their.
werden. Wenn keine N-Gramme installiert oder konfiguriert sind, kommt ein relativ kurzes JSON als Antwort zurück:
{„software“:{„name“:“LanguageTool“,“version“:“4.5″,“buildDate“:“2019-03-26 11:37″,“apiVersion“:1,“premium“:false,“premiumHint“:“You might be missing errors only the Premium version can find. Contact us at supportlanguagetoolplus.com.“,“status“:““},“warnings“:{„incompleteResults“:false},“language“:{„name“:“English (US)“,“code“:“en-US“,“detectedLanguage“:{„name“:“English (US)“,“code“:“en-US“,“confidence“:0.9999997}},“matches“:[]}
Sind die N-Gramme erfolgreich installiert und konfiguriert, wird das LanguageTool mit einem längeren Response antworten:
{„software“:{„name“:“LanguageTool“,“version“:“4.5″,“buildDate“:“2019-03-26 11:37″,“apiVersion“:1,“premium“:false,“premiumHint“:“You might be missing errors only the Premium version can find. Contact us at supportlanguagetoolplus.com.“,“status“:““},“warnings“:{„incompleteResults“:false},“language“:{„name“:“English (US)“,“code“:“en-US“,“detectedLanguage“:{„name“:“English (US)“,“code“:“en-US“,“confidence“:0.9999997}},“matches“:[{„message“:“Statistics suggests that ‚there‘ (as in ‚Is there an answer?‘) might be the correct word here, not ‚their‘ (as in ‚It’s not their fault.‘). Please check.“,“shortMessage“:““,“replacements“:[{„value“:“there“,“shortDescription“:“as in ‚Is there an answer?'“}],“offset“:13,“length“:5,“context“:{„text“:“I want to go their.“,“offset“:13,“length“:5},“sentence“:“I want to go their.“,“type“:{„typeName“:“Other“},“rule“:{„id“:“CONFUSION_RULE“,“description“:“Statistically detect wrong use of words that are easily confused“,“issueType“:“non-conformance“,“category“:{„id“:“TYPOS“,“name“:“Possible Typo“}},“ignoreForIncompleteSentence“:false,“contextForSureMatch“:3}]}
Damit ist der Server komplett eingerichtet. Nun kann der eigene Server bei entsprechenden Add-ons eingerichtet und genutzt werden.
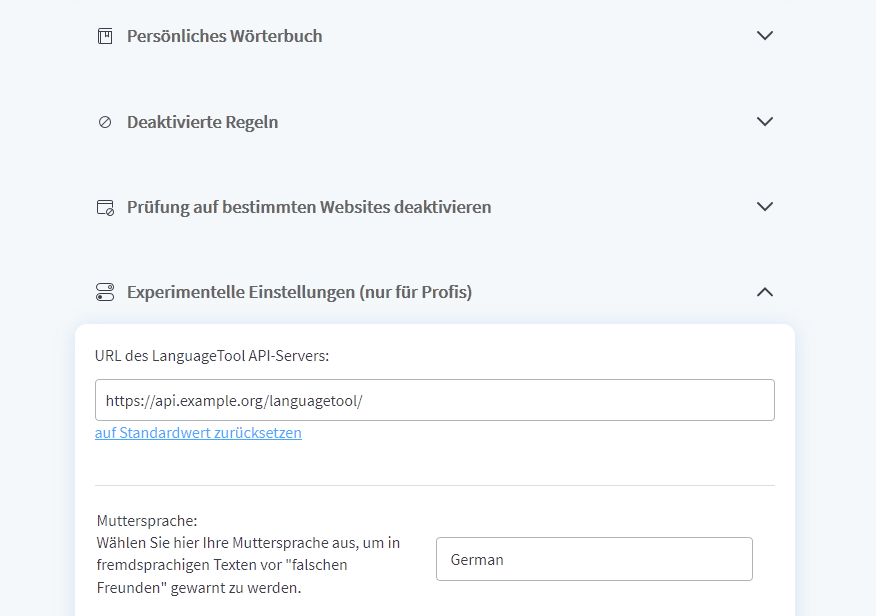
Nachdem der Server aufgesetzt wurde, können entsprechende Add-ons umgestellt werden
Das gleiche Setup kann natürlich genutzt werden, einen solchen Server lokal auf dem eigenen Ubuntu-Rechner zu installieren.
