Vor ein paar Tagen war ich auf der Suche nach einer lokalen Suchmaschine, mit der ich einen größeren Datenbestand durchsuchen wollte. Fündig geworden bin ich bei FESS, welches sich selbst als Enterprise Search Server beschreibt. Einen solchen wollte ich im Rahmen einer Testinstallation unter Ubuntu aufsetzen. Im ersten Schritt wird dazu der entsprechende Nutzer angelegt und in diesen gewechselt:
adduser --disabled-password --gecos "" fess
su fess
cd
Anschließend wird das aktuelle Release heruntergeladen und entpackt:
wget https://github.com/codelibs/fess/releases/download/fess-13.10.2/fess-13.10.2.zip
unzip fess-13.10.2.zip
mv fess-13.10.2 fess
rm fess-13.10.2.zip
Danach kann FESS testweise gestartet werden:
cd fess/bin/
./fess
Der Server hört anschließend auf dem Localhost auf Port 8080. Über die entsprechende URL:
http://localhost:8080
kann FESS dann aufgerufen werden. Soll FESS über Nginx als Reverse Proxy angesteuert werden, so muss unter Nginx eine entsprechende Konfiguration für die Seite angelegt werden:
nano /etc/nginx/sites-available/example
In dieser Datei wird nun die Konfiguration hinterlegt:
server {
listen 443;
listen [::]:443 default_server;
ssl on;
ssl_certificate /etc/letsencrypt/live/example.org/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/example.org/privkey.pem;
server_name example.org;
location / {
proxy_pass http://localhost:8080;
}
} Nach einem Neustart von Nginx mittels:
service nginx restart
ist der Service über die gewünschte URL erreichbar. FESS arbeitet in Verbindung mit Elasticsearch; für den produktiven Einsatz, sollte eine entsprechende Instanz installiert und für die Zusammenarbeit mit FESS konfiguriert werden. Wird dies nicht getan, läuft FESS mit einer Embedded-Variante von Elasticsearch. Für erste Gehversuche und Tests reicht dies aber völlig aus.
Die Oberfläche von FESS im Entwicklermodus
Soll FESS als Service laufen, muss eine entsprechende systemd-Unit angelegt werden.
nano /etc/systemd/system/fess.service
Diese Unit wird nun wie folgt definiert:
[Unit]
Description=FESS Server
After=network.target
[Service]
Type=simple
User=fess
Group=fess
WorkingDirectory=/home/fess/fess/bin
ExecStart=/home/fess/fess/bin/fess
Restart=always
Environment=USER=fess HOME=/home/fess
[Install]
WantedBy=multi-user.target
Nachdem die Unit gespeichert wurde, kann sie aktiviert und gestartet werden:
systemctl enable fess
systemctl start fess
Über die Oberfläche kann sich als Administrator angemeldet werden. Die Standardzugangsdaten lauten:
Nutzername: admin
Passwort: admin
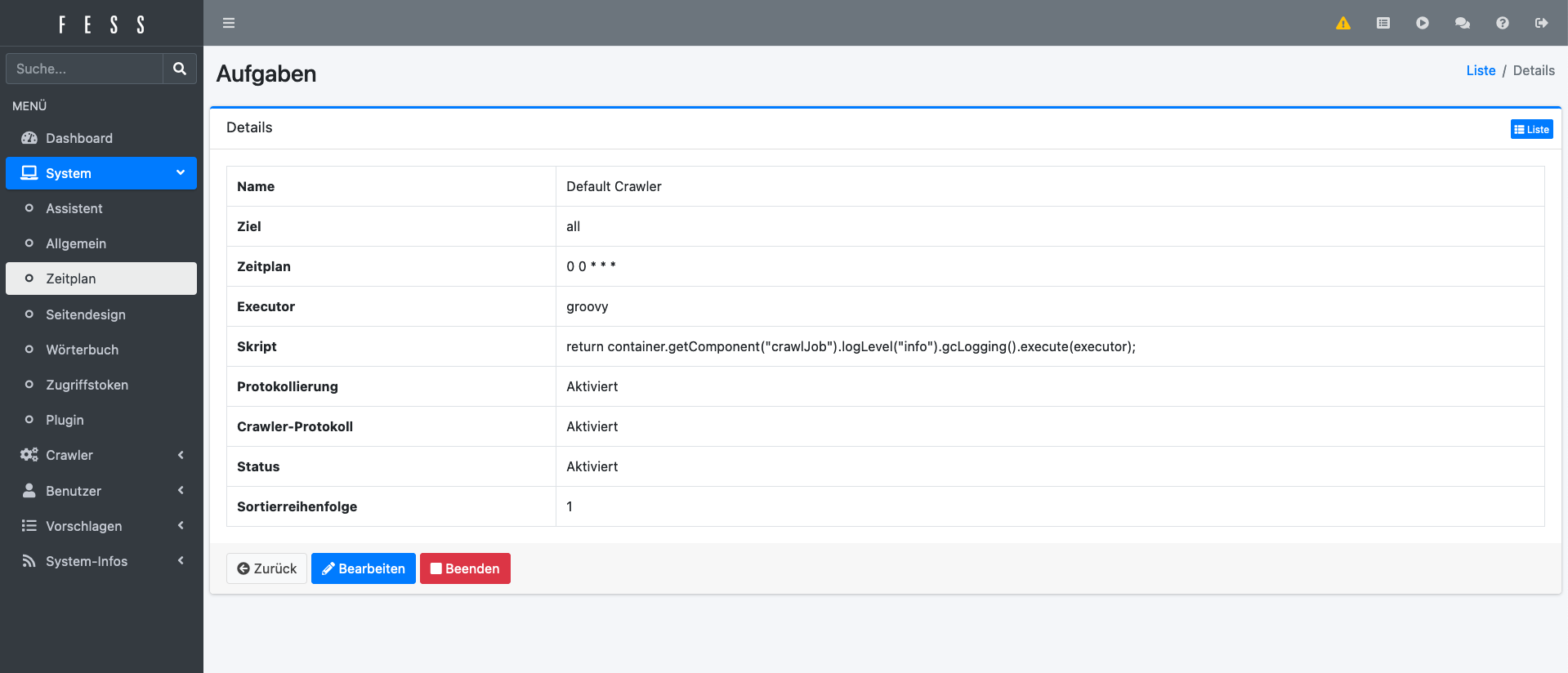
Nach dem ersten Login müssen diese geändert werden. Für einen ersten Testlauf kann in den Einstellungen unter Crawler -> Web oder Crawler -> Dateisystem ein erstes Ziel definiert werden. Anschließend kann der Vorgang manuell über die Symbolleiste oben rechts gestartet werden. Nachdem der Vorgang abgeschlossen ist, kann über das Frontend von FESS gesucht werden.
Die administrative Oberfläche von FESS
Die offizielle Seite des Projektes ist unter fess.codelibs.org zu finden. Das Projekt ist unter der Apache License lizenziert und damit freie Software.