Das altehrwürdige Domain Name System ist seit mittlerweile fast vierzig Jahren einer der Grundpfeiler des Internets. Daneben erblicken neue Technologien rund um das DNS das Licht der Welt und entsprechende Unterstützung zieht in die Betriebssysteme ein.
Einleitung
Damit Pakete für das Internetprotokoll in Version 4 und 6 durch das Internet versendet werden können, sind Endpunkte, wie Clients und Server, mit Adressen versehen.
Über diese Adressen können die Dienste eines Servers abgerufen werden, so z. B. der Aufruf einer Webseite. Während IPv4-Adressen wie 192.168.15.15 noch übersichtlich scheinen, sieht es bei IPv6-Adressen wie der Adresse 2001:0db8:3c4d:0015:0000:1507:1503:1a2b anders aus.
Menschen sind nicht sonderlich gut darin, sich Zahlen zu merken, sodass eine andere Adressierung für die entsprechenden Endpunkte geschaffen werden musste. Gelöst wurde das Problem durch das Domain Name System, welches gerne als Telefonbuch des Internets bezeichnet wird.
Damit können Domains wie example.org auf eine entsprechende IP-Adresse abgebildet werden. Durch dieses Mapping vereinfacht sich die Nutzung und Adressierung im Internet.
Hierarchie im System
Wird eine Domain wie example.org aufgerufen, so wird ein DNS-Server abgefragt, der einem daraufhin den Domainnamen zu einer IP-Adresse auflöst.
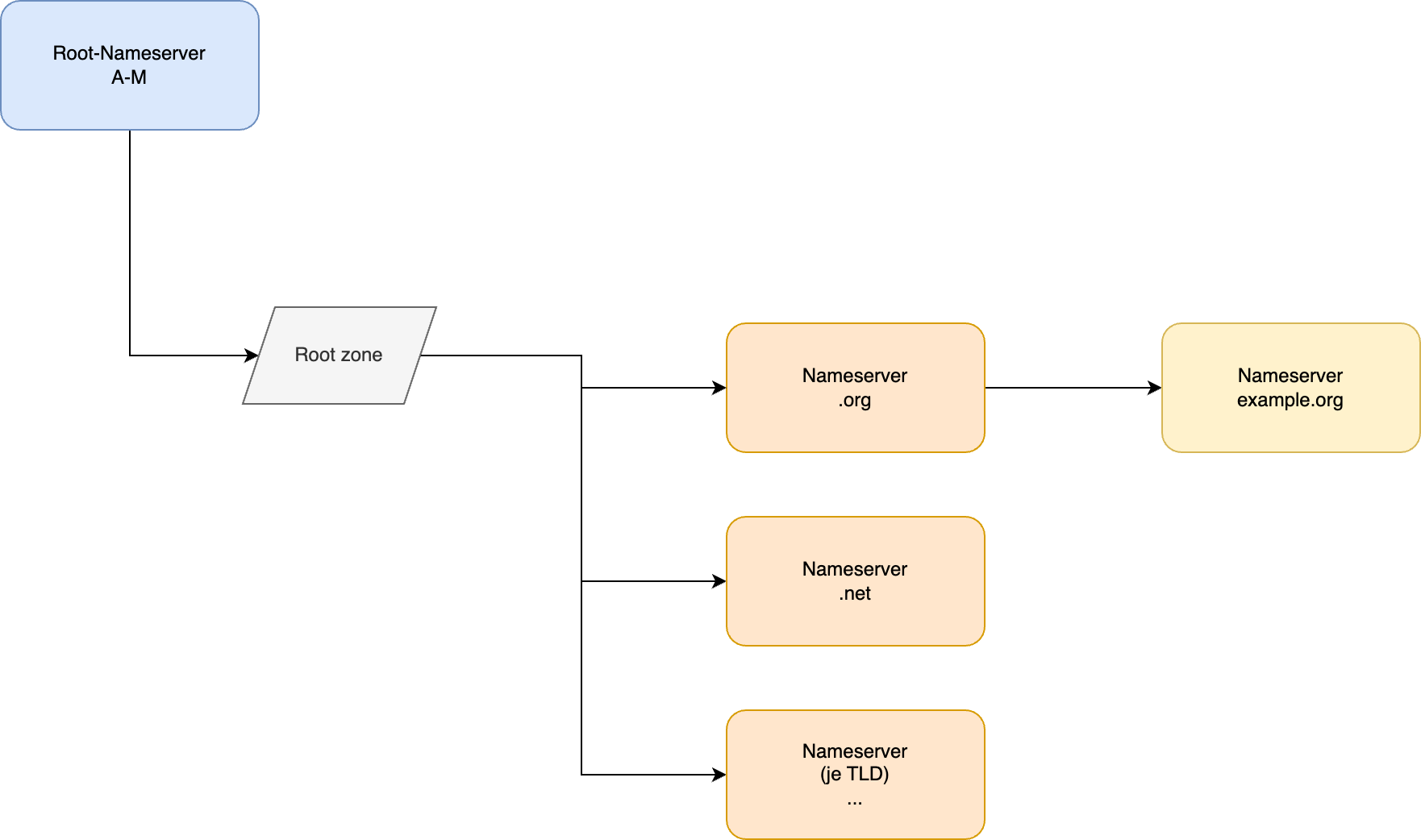
Das gesamte Domain Name System ist hierarchisch aufgebaut. Auf der obersten Ebene befinden sich die autoritativen Nameserver für die Root-Zone. Diese sind dreizehn an der Zahl und tragen die Namen A bis M. Sie liefern die entsprechende Root-Zone aus, bei welcher es sich um einen knapp 2 MB großen Datenblob handelt.
In diesem enthalten ist eine Liste der autoritativen Nameserver für jede Top-Level-Domain. Damit verweist die Root-Zone auf DNS-Server, welche für einzelne Top-Level-Domains wie .de, .org oder .net zuständig sind.
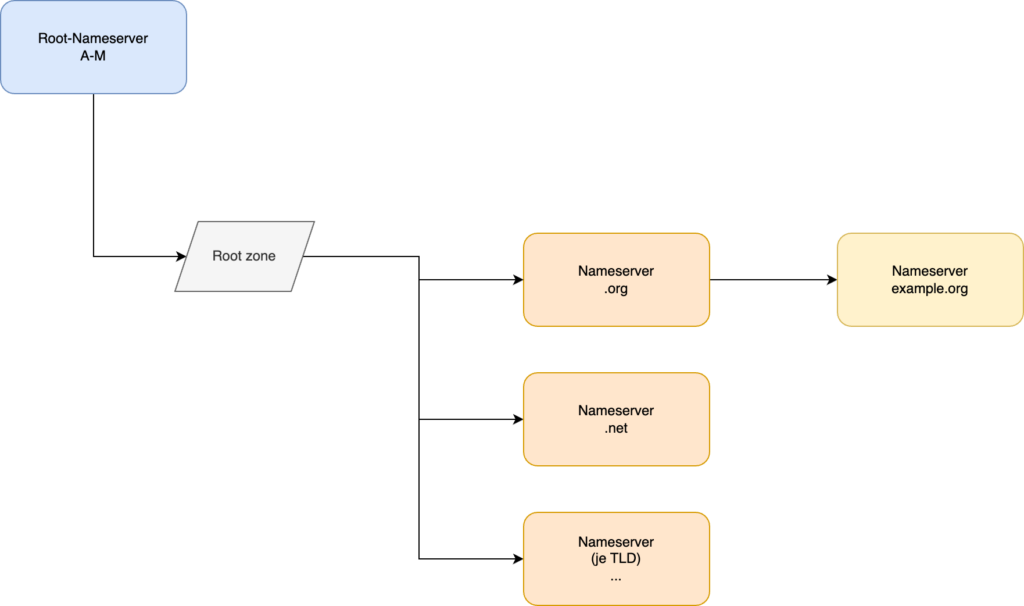
Die Hierarchie im Domain Name System
Die Nameserver für die einzelnen Top-Level-Domains verweisen für eine angefragte Domain wiederum auf autoritative Nameserver, welche für diese Domain zuständig sind. In der Theorie kann diese Hierarchie mit jeder Ebene einer Domain, wie z. B. Subdomains, fortgesetzt werden.
Autoritative und cachende Nameserver
Besagte autoritative Nameserver sind dafür verantwortlich, verbindliche Aussagen zu einer Zone, wie einer Domäne oder einer ganzen Top-Level-Domain zu treffen. Was der autoritative Nameserver mitteilt, ist die objektive Wahrheit im Domain Name System.
Da es aus Gesichtspunkten wie der Lastverteilung und der Antwortgeschwindigkeit eher unpraktikabel ist, alle Anfragen zu einer bestimmten Zone nur von den autoritativen Nameservern beantwortet zu lassen, existieren cachende Nameserver.
Diese Nameserver, stehen z. B. beim Internet Service Provider und beantworten die DNS-Anfragen der Kunden. Kann eine solche DNS-Anfrage nicht aus dem Cache beantwortet werden, so wird wiederum der autoritative Nameserver angefragt und das Ergebnis für weitere Anfragen im Cache gehalten.
Nach Ablauf der Time to Live (TTL), welche in der Zone definiert ist, wird der Cache invalidiert und bei der nächsten Anfrage wieder der autoritative Nameserver befragt.
Zonen im Detail
In einer Zone können unterschiedlichste sogenannte Resource Records, kurz Records angelegt werden. Eine Zone, welche die entsprechende Konfiguration enthält, könnte wie folgt aussehen:
$ORIGIN example.org.
$TTL 3600
; SOA Records
@ IN SOA dns.example.org. 2022061900 86400 10800 3600000 3600
; NS Records
@ IN NS ns-1.example.org.
@ IN NS ns-2.example.org.
@ IN NS ns-3.example.org.
; MX Records
@ IN MX 10 mail.example.org.
; A Records
@ IN A 10.1.1.1
; AAAA Records
@ IN AAAA 2001:db8:123:4567::1
; CNAME Records
api IN CNAME www
www IN CNAME example.org.
In der Zonen-Datei sind eine Reihe von Resource Record-Typen definiert, welche bestimmten Zwecken dienen. Von diesen Typen ist eine größere Anzahl definiert, von denen hier ein auszugsweiser Überblick gegeben werden soll.
A
Der A-Record definiert die IPv4-Adresse des Hosts. Mit diesem wird der Hostname schlussendlich der entsprechenden IPv4-Adresse zugeordnet.
AAAA
Wie beim A-Record ordnet auch der AAAA-Record dem Host eine IP-Adresse zu. In diesem Fall wird allerdings eine IPv6-Adresse zugeordnet.
CNAME
Bei CNAME handelt es sich um die Abkürzung für Canonical Name record. Mit diesem Record kann einer Domain ein weiterer Name zugeordnet werden. Dies kann genutzt werden, um Subdomains wie api.example.org anzulegen.
In einer beispielhaften Konfiguration würde dies dann wie folgt aussehen:
$ORIGIN example.org.
info IN CNAME www
www IN A 192.168.1.1
www IN AAAA 2a01:4f8:262:5103::1
Hier wird die Subdomain info.example.org per CNAME auf die Subdomain www.example.org verwiesen, welche wiederum per A- und AAAA-Record auf die entsprechenden IP-Adressen des Hosts verweist.
MX
Der MX-Record ist ein wichtiger Record-Typ im Domain Name System, weil er dafür sorgt, dass E-Mails den entsprechenden Empfänger erreichen. Dazu definiert er den entsprechenden Mailserver, welcher für eine Domain zuständig ist:
; MX Records
@ IN MX 10 mail.example.org.
Damit kann per DNS ermittelt werden, wie der Mailserver erreichbar ist und die entsprechende E-Mail zugestellt werden.
NS
Der NS-Record bzw. die NS-Records definieren die für die Domain zuständigen Nameserver. Bei einem bei Hetzner gehosteten Server, könnte das Ganze wie folgt aussehen:
; NS Records
@ IN NS helium.ns.hetzner.de.
@ IN NS hydrogen.ns.hetzner.com.
@ IN NS oxygen.ns.hetzner.com.
Die dort angegebenen Server sind die autoritativen Nameserver, da die entsprechenden Auskünfte, die diese Server erteilen, für die konfigurierte Domain verbindlich sind.
PTR
Ein PTR-Record, kurz für Pointer record, dient dazu, ein Reverse DNS Lookup zu ermöglichen. Das bedeutet, dass zu einer IP-Adresse der entsprechende DNS-Name ermittelt wird.
Wichtig ist diese Art der Konfiguration unter anderem bei der Bereitstellung von Mailservern.
SOA
SOA-Records, welche ein Kürzel für Start Of Authority darstellen, dienen der Darstellung bestimmter Informationen wie der primären Nameserver oder der Bereitstellung von Informationen, wie der TTL, für andere DNS-Server.
; SOA Records
@ IN SOA hydrogen.ns.hetzner.com. dns.hetzner.com. 2022121602 86400 10800 3600000 3600
TXT
Der TXT-Record ist ein relativ universeller Record im Domain Name System, mit welchem maschinenlesbare Daten im DNS hinterlegt werden können:
; TXT Records
@ IN TXT "v=spf1 redirect=example.org"
Genutzt wird diese Möglichkeit für unterschiedliche Techniken, wie im E-Mail-System mit DMARC oder dem Sender Policy Framework (SPF).
Probleme im Domain Name System
Das Domain Name System funktioniert in den Grundzügen, so wie es seit 1983 definiert wurde. Allerdings wirft diese Architektur auch einige Probleme auf.
In der klassischen DNS-Variante über UDP oder TCP, findet die komplette Kommunikation unverschlüsselt statt und stellt somit auch aus Sicht des Datenschutzes bzw. der Privatsphäre ein Problem dar.
Daneben sind die DNS-Responses nicht vor Änderungen geschützt und können somit ohne Wissen des Empfängers manipuliert werden.
Auch DDoS-Attacken in Form einer DNS Amplification Attack lassen sich bedingt durch die Gegebenheiten im Domain Name System durchführen. Hierbei wird die Zieladresse mit Datenverkehr von DNS-Servern belastet. Dies funktioniert, da der Angreifer eine DNS-Anfrage mit einer gefälschten IP-Adresse stellt und die Antwort somit beim eigentlichen Ziel der Attacke aufläuft. Der Angreifer benötigt in einem solchen Fall wenig Bandbreite, da die Antwort des DNS-Servers meist wesentlich größer ausfällt, als die Anfrage.
Ein weiteres Problem sind sogenannte Broken Resolvers. Dies ist insbesondere bei einigen Internet Service Providern der Fall, bei denen Dinge wie die TTL, also die Gültigkeit einer DNS-Antwort nicht berücksichtigt werden. Daneben existieren auch solche Resolver, die bei nicht vorhanden Domains nicht mit NXDOMAIN antworten, sondern stattdessen auf eine eigene Webseite umleiten.
Dieses Problem kann schon mit dem ursprünglichen Domain Name System verhindert, werden, indem alternative DNS-Server genutzt werden. Grundsätzlich erschweren solche Broken Resolvers die Fehlerfindung und beeinflussen die Funktionalität des Domain Name System.
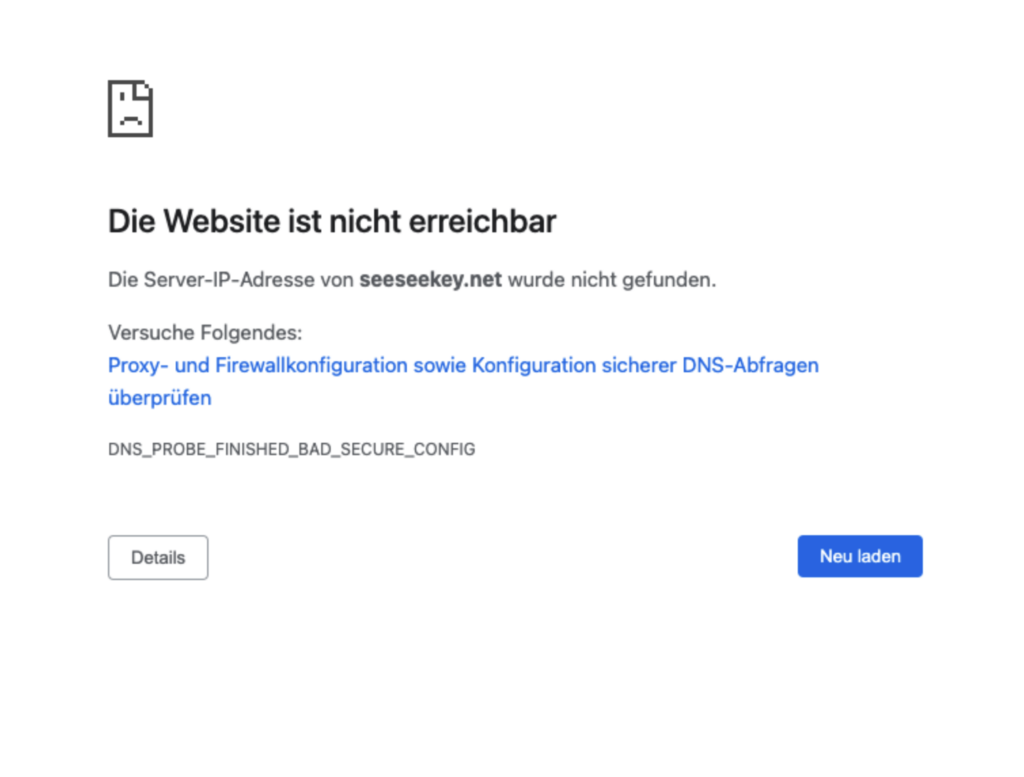
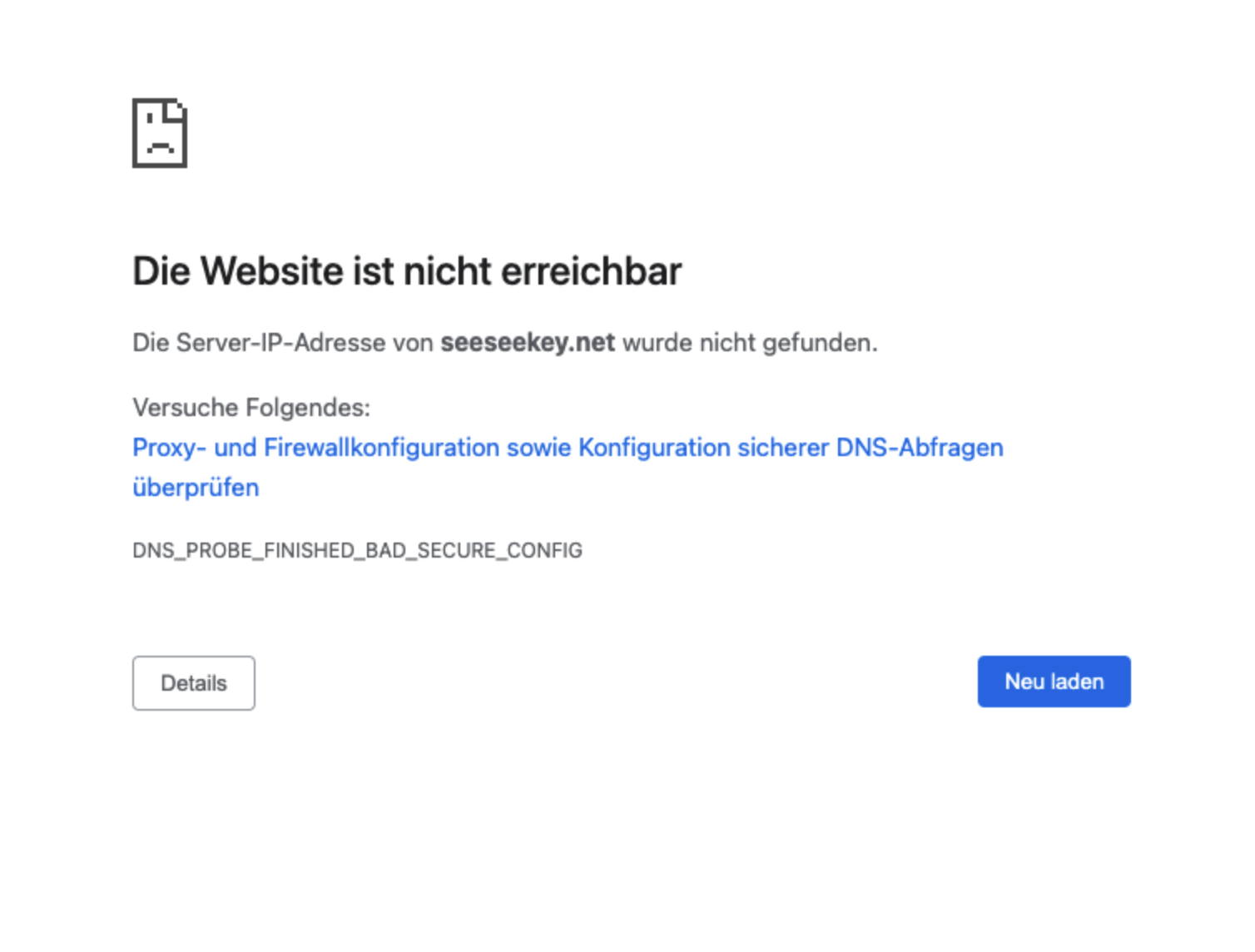
Eine Fehlermeldung in Chrome, welche auf Probleme mit der DNS-Konfiguration hinweist
Interessant ist hier die Unterstützung durch Browser, wie Chrome, welcher bei Inkonsistenzen mit dem DNS-Server entsprechende Hinweise in Form einer spezifischen Fehlermeldung gibt.
Verbesserungen am System
Die Schwächen des Domain Name Systems sind nicht unberücksichtigt geblieben und so gab es im Laufe der Zeit immer wieder Verbesserungen, um das eine oder andere Problem zu beseitigen und das Domain Name System zu verbessern.
Dies fing schon in der Frühzeit des DNS an, als neben der ursprünglichen Möglichkeit per UDP Anfragen zu stellen, dies auch per TCP abgewickelt werden sollte. Hintergrund war es hier unter anderem DNS-Responses, welche größer als 512 Byte sind, versenden zu können.
Daneben wurde zur Erweiterung der DNS-Responses über UDP der Extension Mechanismus for DNS, kurz EDNS, definiert. Über diesen Mechanismus ist es möglich, mehr als 512 Byte per UDP zu übertragen. Genutzt wird dies unter anderem bei DNSSEC.
Bei der gewöhnlichen Nutzung wird in den meisten Fällen, aufgrund des geringeren Overheads, UDP genutzt. Nur in Fällen, in denen z. B. größere Datenmengen im Spiel sind, wird TCP genutzt.
TSIG und DNSSEC
Eine Sicherheitstechnologie in Bezug auf DNS ist TSIG, welches mit der RFC 2845 spezifiziert wurde. Das Kürzel steht für Transaction Signatures und ist ein Verfahren zur Absicherung von DNS-Updates z. B. bei dynamischem DNS.
Eine weitere Erweiterung des DNS sind die Domain Name System Security Extensions kurz DNSSEC. Mittels DNSSEC soll die Authentizität und Integrität von DNS-Daten gewährleistet werden.
Das bedeutet bei DNSSEC, dass die Übertragung selbst nicht verschlüsselt ist, sondern nur sichergestellt wird, dass die enthaltenden Daten korrekt und unverändert sind. Die Verbreitung von DNSSEC hat dabei in den vergangenen Jahren zugenommen.
Technologien für neue Anforderungen
Während Technologien wie DNSSEC und TSIG, bestimmte Anwendungszwecke im Auge haben, ist das Bewusstsein für Datenschutz und Privatsphäre im Laufe der letzten Jahre und Jahrzehnte gewachsen, sodass Lösungen entwickelt wurden, welche unverschlüsseltes DNS ersetzen oder ergänzen sollen.
Die neu entwickelten Protokolle und Technologien, welche in den vergangenen Jahren entwickelt wurden, hören auf so illustre Kürzel wie DoT, DoH oder DoQ.

Die unterschiedlichen DNS-Varianten im Laufe der Zeit
Interessant ist hier ein kurzer Rückblick auf die Geschichte des DNS-Protokolls. Als dieses ursprünglich zum Einsatz kam, setzte das Protokoll auf UDP auf, sodass die erste DNS-Version als DNS over UDP bezeichnet werden kann.
Mit der RFC 1123 aus dem Jahre 1989 wurde schließlich begonnen TCP für DNS-Anfragen zu nutzen, sodass DNS over TCP geboren war. Sowohl die UDP als auch die TCP Variante nutzen den Port 53.
DNS over TLS
DNS over TLS, kurz DoT, wurde im Mai 2016 im Rahmen der RFC 7858 standardisiert und wird genutzt, um DNS-Abfragen mittels TLS zu verschlüsseln. Es handelt sich hierbei nur um eine Transport- und um keine Ende-zu-Ende-Verschlüsselung.
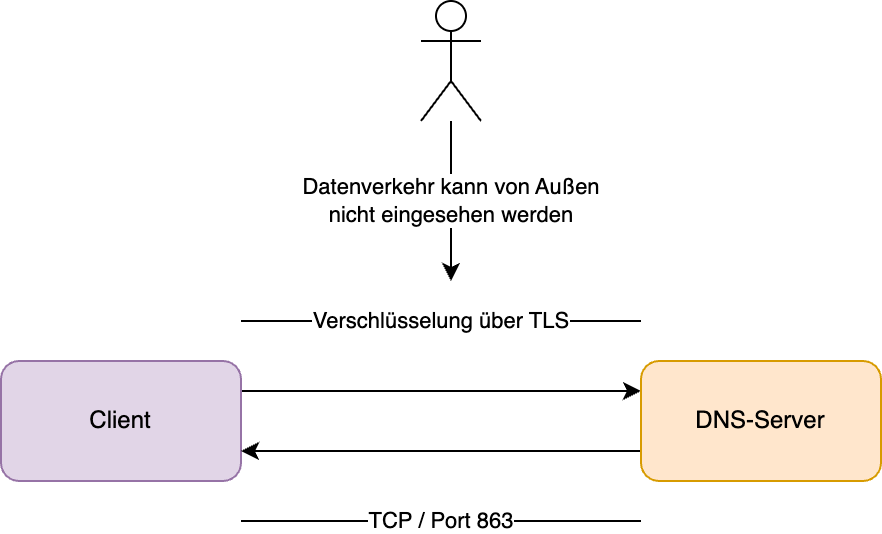
DNS über TLS
Bei DoT wird zu dem DNS-Server eine Verbindung über TCP aufgebaut und diese mittels TLS abgesichert. Bedingt durch die Transportverschlüsselung können die DNS-Einträge nicht mehr zwischen den Knoten manipuliert werden. Der standardmäßig vorgesehene Port für DoT ist 853.
Wie auch bei DNS over HTTPS, werden bei dieser Variante DNS-Verstärkungsangriffe weitestgehend unterbunden.
Gegenüber unverschlüsseltem DNS erzeugt die Verschlüsslung per TLS einen gewissen Overhead, welcher sich auf die Geschwindigkeit der DNS-Anfrage auswirkt.
Im Gegensatz zu DNS über HTTPS soll diese Variante in der Praxis schneller sein. Allerdings gibt es je nach Implementierung unter Umständen Probleme, die meist von einem nicht korrekt implementierten Standard herrühren.
Bedingt durch den fest definierten Standardport für DoT (853), lässt sich dieses Protokoll relativ einfach blockieren. In einem solchen Fall kann auf andere DNS-Protokolle geschwenkt oder alternativ auf unverschlüsseltes DNS gesetzt werden.
DNS over HTTPS
Eine weitere Variante, welche ähnlich dem DNS over TLS funktioniert, ist DNS over HTTPS. Dieses wurde in der RFC 8484 standardisiert.
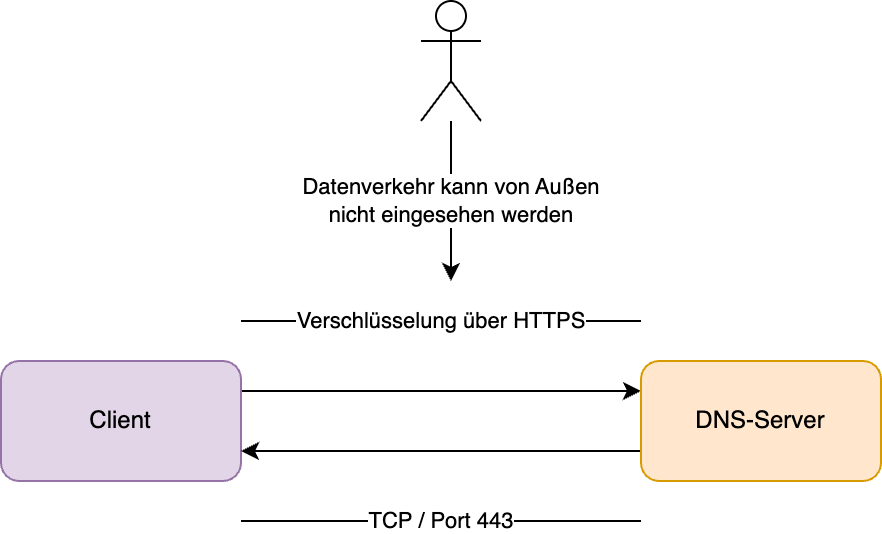
DNS über HTTPS
DoH läuft über den gleichen Port, wie gewöhnliches HTTPS, den Port 443. Damit kann von Außen keine Unterscheidung getroffen werden, ob es sich um DNS-Anfragen oder normalen HTTPS-Datenverkehr handeln.
Der Grund hierfür ist darin zu suchen, dass der Datenverkehr bzw. die Informationen der DNS-Abfrage über das Hypertext Transfer Protocol gesendet werden.
Damit wird eine Blockierung entsprechender DNS-Abfragen über dieses Verfahren erschwert. Allerdings leidet auch hier wieder die Performanz im Vergleich zu gewöhnlichem unverschlüsselten DNS.
Eine Spielart von DNS over HTTPS ist das relativ neue DNS-over-HTTP/3 kurz DoH3, welches wie HTTP/3 als Transportprotokoll QUIC anstatt von TCP nutzt. Dies darf allerdings nicht mit DNS over QUIC verwechselt werden.
DNS over QUIC
Zu den neueren Ideen bzw. Technologien bei der DNS-Abfrage gehört DNS over QUIC. Ziel von DoQ ist es, die Latenzen zu verringern, bei gleichzeitiger Nutzung einer verschlüsselten Verbindung.
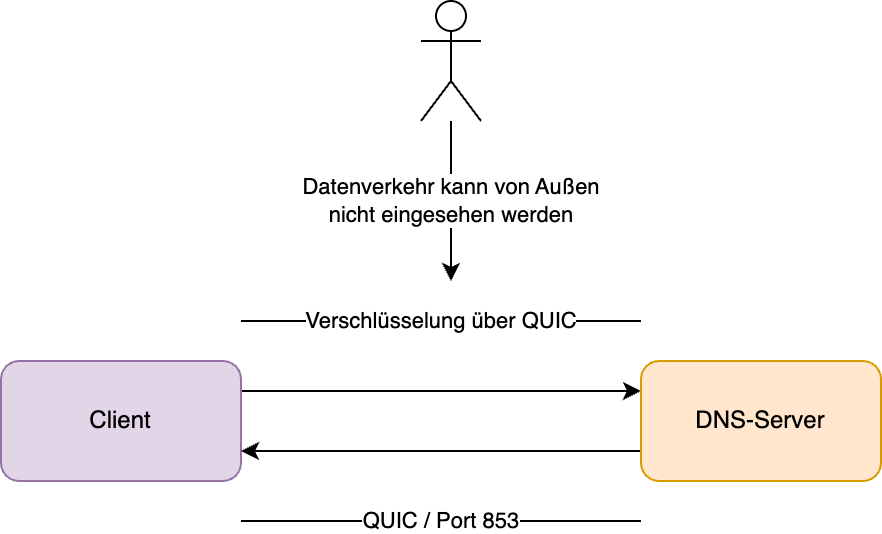
DNS über QUIC
Definiert ist DoQ in der RFC 9250. Grundlage für das Protokoll ist QUIC, welches als Transportschicht TCP ersetzt und in dieser Form auch bei HTTP/3 genutzt wird.
Ziel von DoQ ist, dass dieses Protokoll auch für autoritative Nameserver verwendet werden kann. Damit soll eine möglichst breite Anzahl an Nutzungsmöglichkeiten im Zusammenhang, mit dem Domain Name System abgebildet werden können.
Da DoQ über den zugewiesenen Port 853 läuft, ist auch hier technisch gesehen eine einfache Blockierung möglich. Allerdings definiert die RFC hier im Abschnitt Port Selection:
In the stub to recursive scenario, the use of port 443 as a mutually agreed alternative port can be operationally beneficial, since port 443 is used by many services using QUIC and HTTP-3 and is thus less likely to be blocked than other ports
Unterstützung auf Serverseite
Damit DNS-Dienste, über welche Protokolle auch immer, im Internet genutzt werden können, muss die entsprechende Server-Software die gewünschten Protokolle unterstützen.
Neben BIND, dem Platzhirsch unter den DNS-Server, existieren noch weitere DNS-Server von denen bezüglich ihrer Fähigkeiten noch Unbound und der Windows Server kurz beleuchtet werden sollen.
|
DNS over TLS |
DNS over HTTPS |
DNS over QUIC |
| BIND |
ab Version 9.17 |
ab Version 9.17 |
– |
| Unbound |
ab Version 1.7.3 |
ab Version 1.12.0 |
– |
| Windows Server (DNS) |
– |
ab Windows Server 2022 |
– |
Bei BIND zogen mit der Version 9.17, welche im Jahr 2020 erschien, der Support für DoT und DoH (in einer experimentellen Version) ein. Eine Unterstützung für DNS over QUIC, steht im Moment noch aus.
Unbound liefert seit der im Juni 2018 erschienen Version 1.7.3 eine Unterstützung für DNS over TLS aus. Mit der im Oktober 2020 erschienen Version 1.12.0 wurde die Unterstützung für DNS over HTTPS implementiert. An der Umsetzung von DNS over QUIC in Unbound wird im Moment noch gearbeitet.
Ab dem Windows Server 2022 wird DNS over HTTPS offiziell unterstützt. Bei DNS over TLS und DNS over QUIC ist bisher keine Unterstützung im Windows Server vorhanden.
Linux
Neben der Unterstützung auf Serverseite ist auch die Unterstützung auf Client-Seite, in Form von Betriebssystemen auf dem Desktop, als auch im Bereich der mobilen Betriebssysteme wichtig.
In den meisten Linux-Distributionen, welche Systemd nutzen, kann dies über systemd-resolved erledigt werden. Dieser unterstützt ab der Version 239 opportunistisches DNS over TLS und ab der Version 243 striktes DNS over TLS.
Hier kann z. B. unter Ubuntu in der Konsole die entsprechende Konfigurationsdatei editiert werden:
nano /etc/systemd/resolved.conf
Dort sollte die Einstellung:
DNSOverTLS=yes
hinzugefügt werden. Anschließend können über den normalen Netzwerkdialog, DoT-fähige DNS-Server eingetragen werden:
9.9.9.9, 149.112.112.112
In diesem Fall sind es die DNS-Server von Quad9. Anschließend laufen die DNS-Abfragen per DoT über die gewählten DNS-Server.
macOS
Seit macOS 11, welches mit dem Namen Big Sur auf den Markt kam, unterstützt macOS neben DNS over TLS auch DNS over HTTPS.
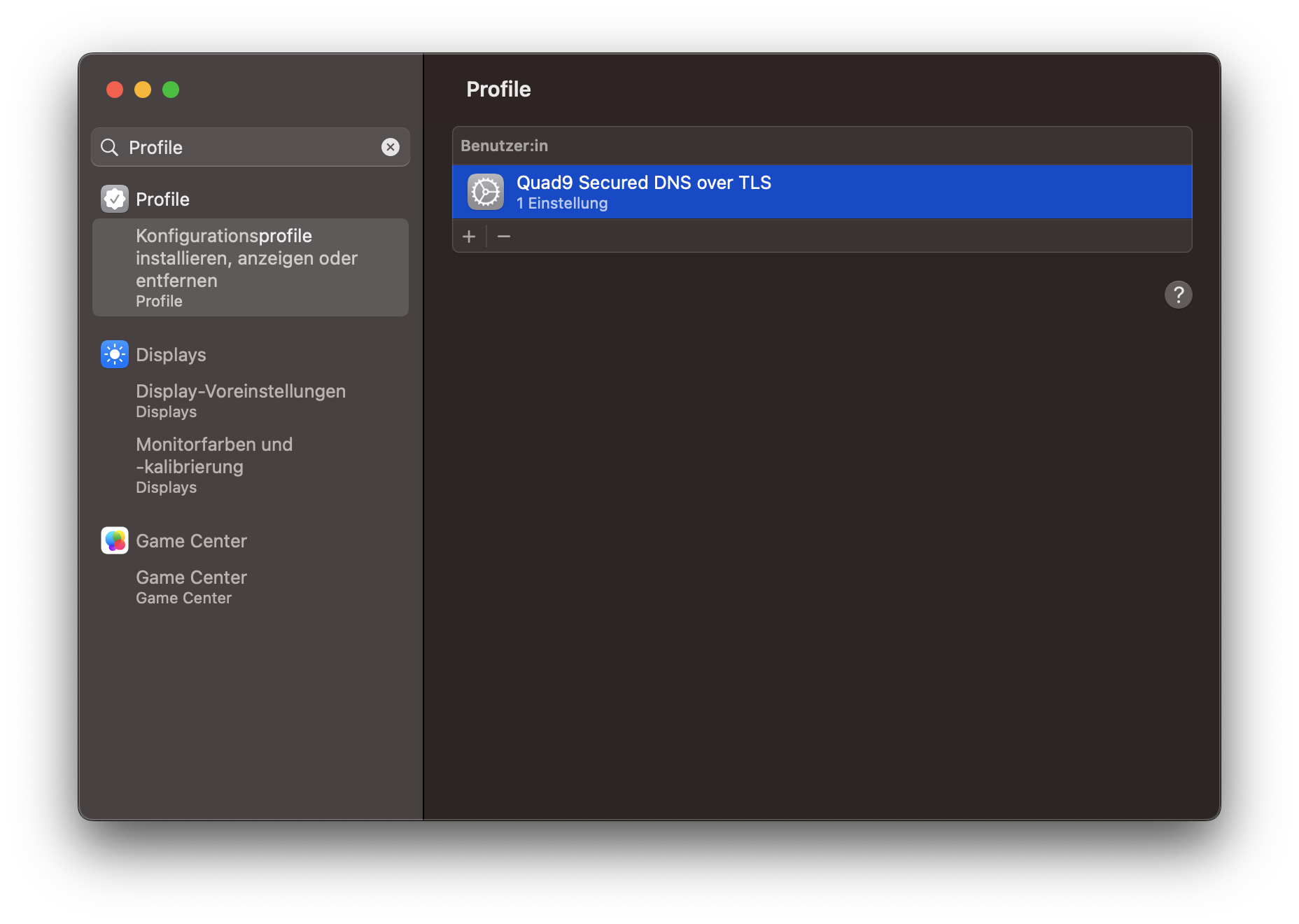
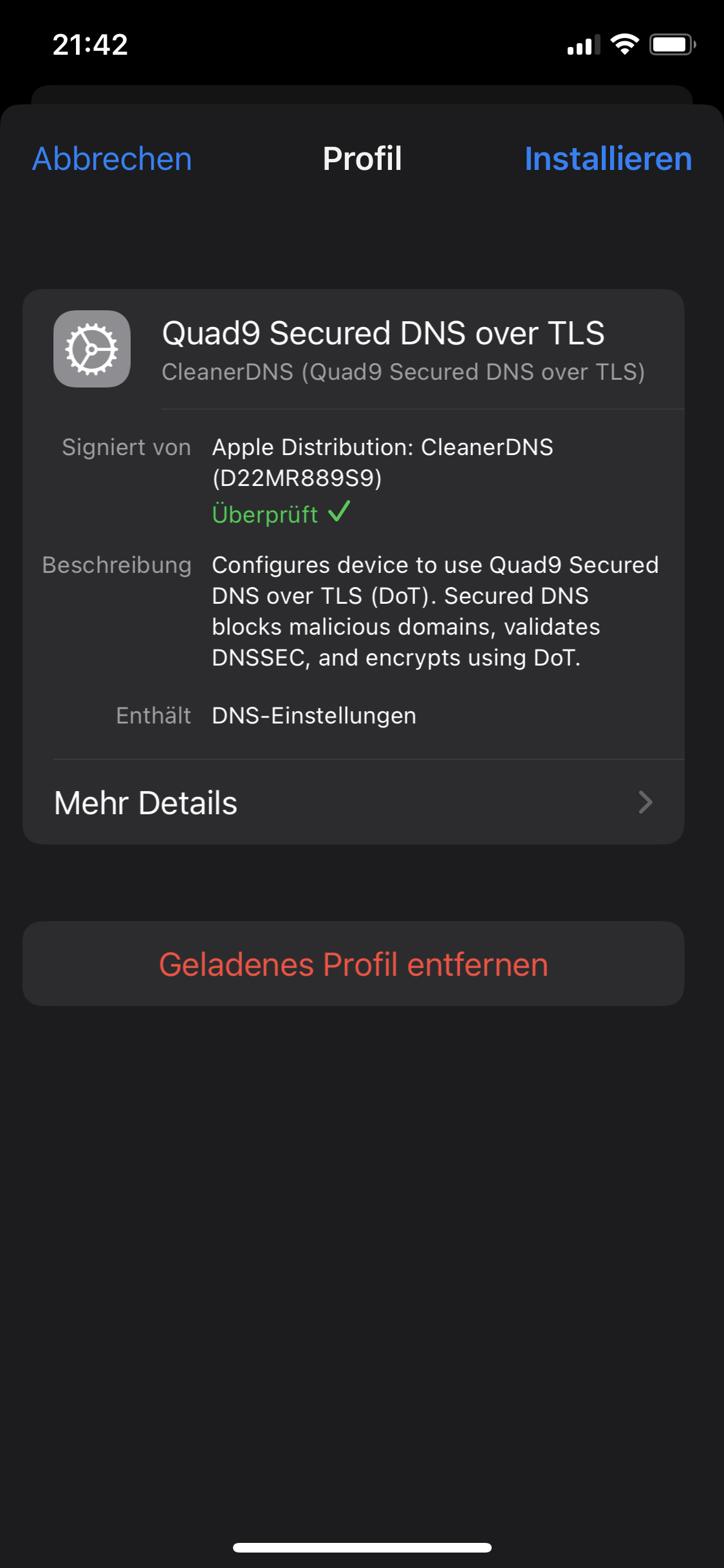
Aktiviert werden können die gewünschten Einstellungen über Konfigurationsprofile. Dazu muss ein entsprechendes Profil heruntergeladen und anschließend installiert werden.
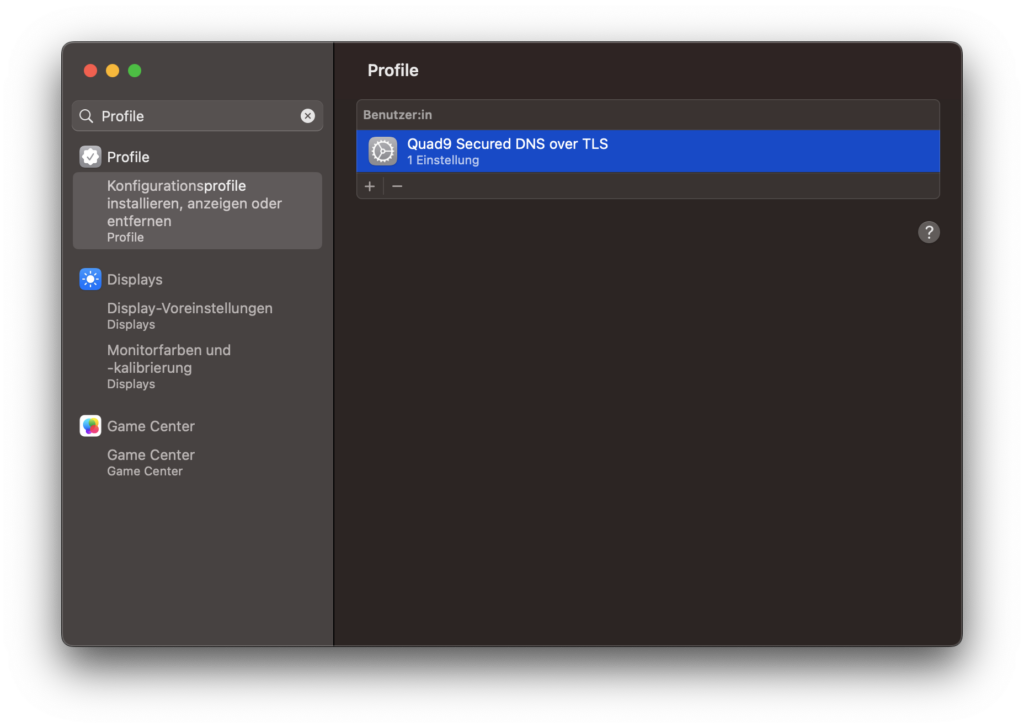
Das Profil unter macOS
Die Konfigurationsprofile befinden sich in den Systemeinstellungen unter macOS. Nach der Aktivierung kann über das Terminal überprüft werden, ob die entsprechenden Einstellungen aktiv sind:
sudo tcpdump -i any "port 853 and host 9.9.9.9 or host 149.112.112.112"
Bei der Nutzung von DoH sollte der Port im Befehl auf 443 geändert werden. Nachdem der Befehl abgesetzt wurde, sollte Netzwerkverkehr zu dem Quad9-DNS-Server im Dump auftauchen.
Windows
Unter Windows 10 wird, seit dem Build 19628, DNS over HTTPS unterstützt. Dazu muss in der Registry der Pfad:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Dnscache\Parameters
aufgerufen werden und dort ein Parameter vom Typ DWORD erstellt werden. Dieser trägt den Namen EnableAutoDoh sowie den Wert 2. Anschließend sollte ein Neustart des Rechners durchgeführt werden.
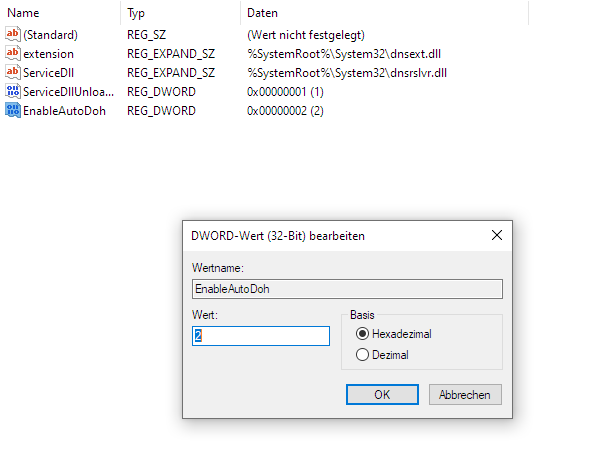
Die Einstellungen im Registrierungs-Editor
Nun können in den Einstellungen für den jeweiligen Netzwerkadapter die passenden DNS-Server mit einer entsprechenden Unterstützung für DoH eingestellt werden:
9.9.9.9, 149.112.112.112
Unter Windows 11 können die Einstellungen für DoH bequem über die Netzwerkeinstellungen eingestellt werden, nachdem dort die passenden DNS-Server hinterlegt sind, kann dort unter DNS over HTTPS das Feature aktiviert werden.
Neben DoH unterstützt Windows 11 auch DNS over TLS. Dazu werden in den Netzwerkeinstellungen die entsprechenden DNS-Server hinterlegt und das DNS over HTTPS-Feature deaktiviert.
Nun muss die Kommandozeile geöffnet werden und dort müssen die Befehle:
netsh dns add global dot=yes
netsh dns add encryption server=9.9.9.9 dothost=: autoupgrade=yes
netsh dns add encryption server=149.112.112.112 dothost=: autoupgrade=yes
eingegeben werden. Das Kommando:
netsh dns add encryption
muss hierbei für jeden DNS-Server für die IPv4- und IPv6-Adresse wiederholt werden. Abgeschlossen wird das Prozedere mittels:
ipconfig /flushdns
netsh dns show global
Der letztere Befehl zeigt an, ob die Einstellungen für DNS over TLS aktiviert wurden. DNS over QUIC wird unter Windows vom System selbst bisher noch nicht unterstützt.
Android
Während seit Android 9 (Pie) DNS over TLS bereits verfügbar ist, ist DNS over HTTPS ab Android 11 enthalten und teilweise auch auf einigen Geräten mit Android 10 verfügbar.
Die teilweise Verfügbarkeit unter Android 10 erklärt sich dadurch, dass das entsprechende DNS Resolver Modul unter Android 10 noch optional, aber unter Android 11 verpflichtend zum System dazu gehört. Installiert werden diese Änderungen über ein Google Play-Systemupdate.
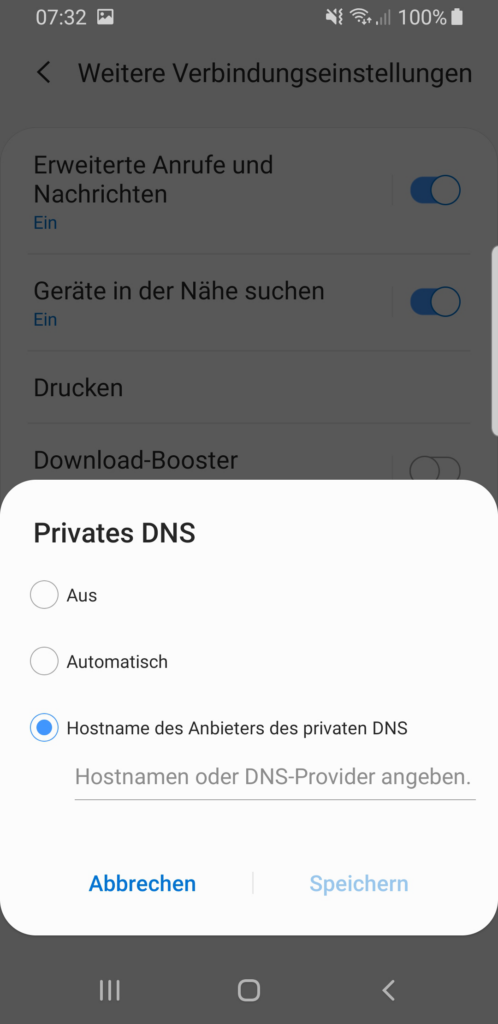
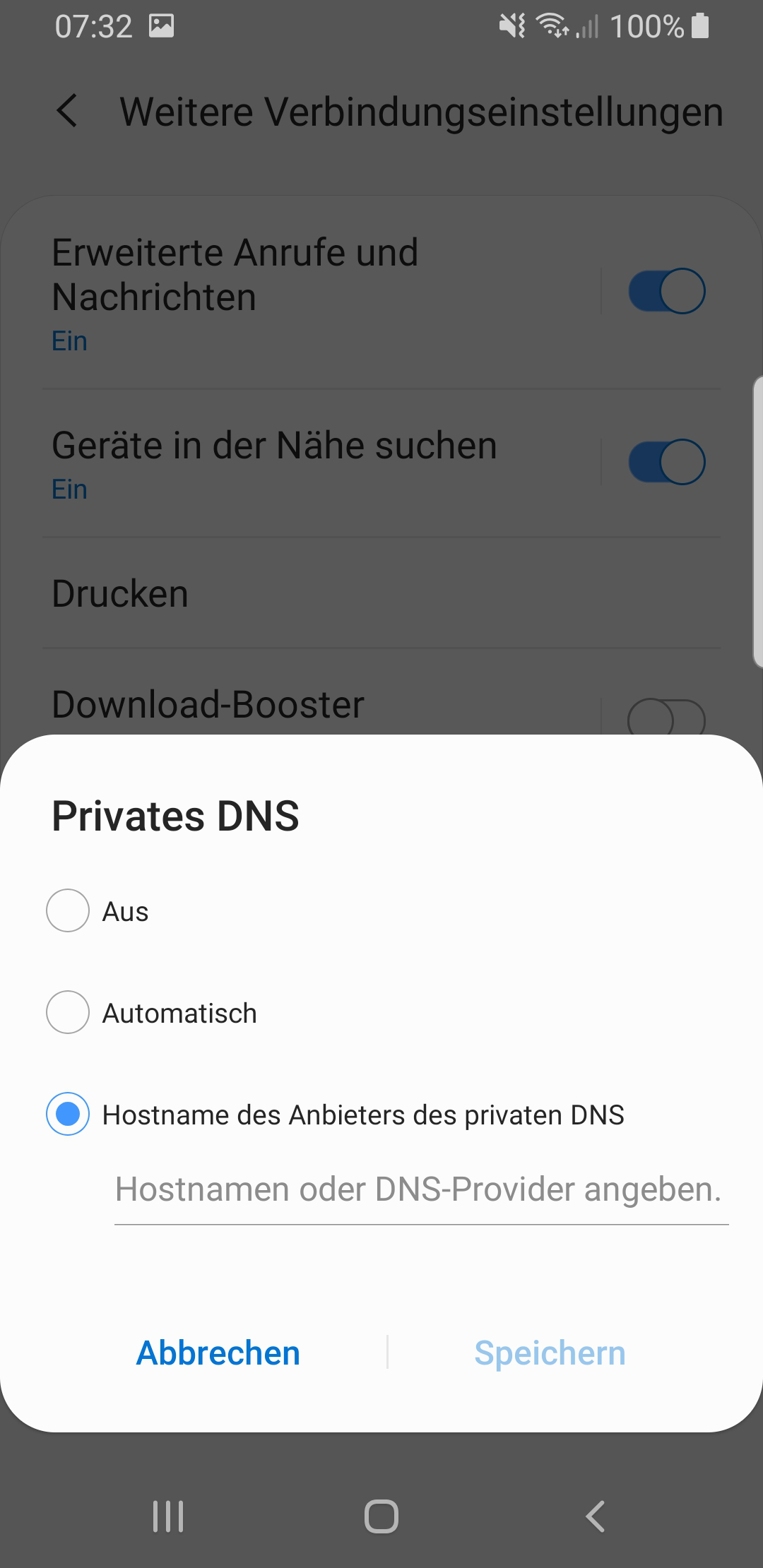
In den Einstellungen kann DoT bzw. DoH aktiviert werden
Zur Aktivierung unter Android genügt es in den Systemeinstellungen, die Netzwerkeinstellungen aufzurufen und dort im Punkt Privates DNS, die entsprechenden DNS-Server zu hinterlegen. Hierbei wird, je nach Android-Version, DNS over HTTPS (in der Variante DoH3) gegenüber DNS over TLS bevorzugt, zumindest bei den dem System bekannten DNS-Servern.
iOS
Seit iOS 14, also knapp 2 Jahre später als unter Android, zog in iOS die Unterstützung für DNS over TLS ein. Ebenfalls ab iOS 14 wird DNS over HTTPS unterstützt.
Wie unter macOS, kann die Einstellung über entsprechende Konfigurationsprofile vorgenommen werden. Dazu muss ein Profil auf dem iOS-Gerät heruntergeladen und installiert werden.
Die Installation des Profils erfolgt über die Einstellungen unter iOS
Nachdem das Profil bestätigt und installiert worden ist, wird der DNS-Server in der im Profil hinterlegten Konfiguration genutzt.
Unter iOS existiert die Besonderheit, dass DNS-Abfragen für den Appstore und die Terminalbefehle dig und nslookup per Design nicht über die im Profil hinterlegten DNS-Server abgefragt werden.
Das Profil kommt nicht immer zur Anwendung
Auch gelten die Einstellungen nicht, wenn z. B. iCloud Privat Relay oder eine VPN-Verbindung aktiv sind.
Browser
Neben der betriebssystemseitigen Unterstützung liefern auch die meisten Browser mittlerweile eine Unterstützung für DNS over HTTPS aus. Diese Unterstützung ist unabhängig vom darunterliegenden Betriebssystem.
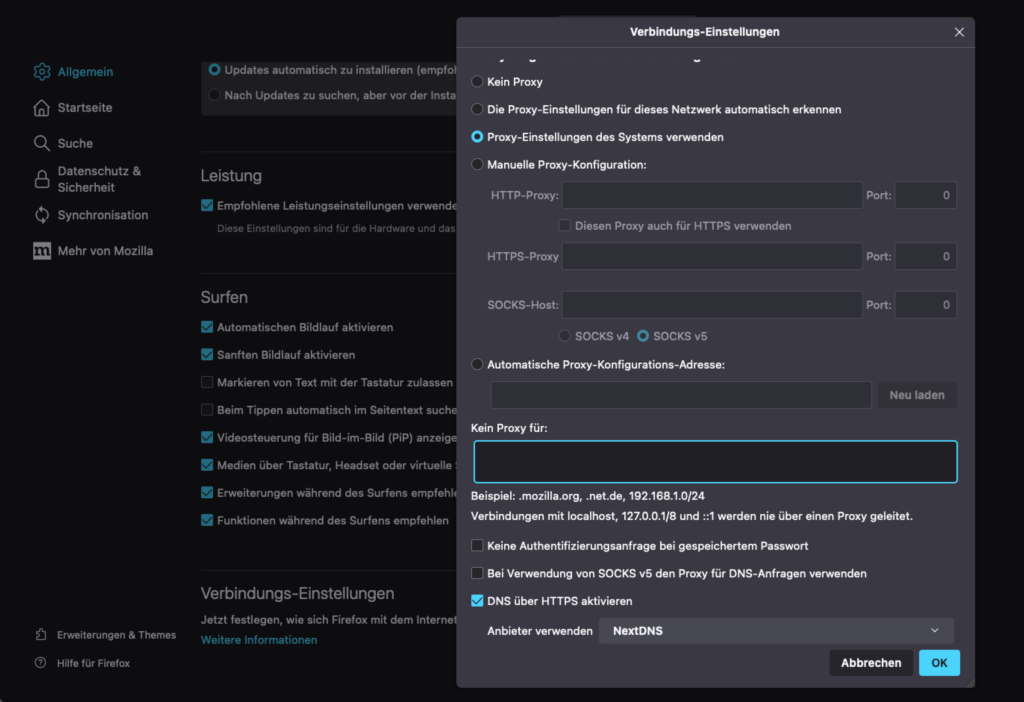
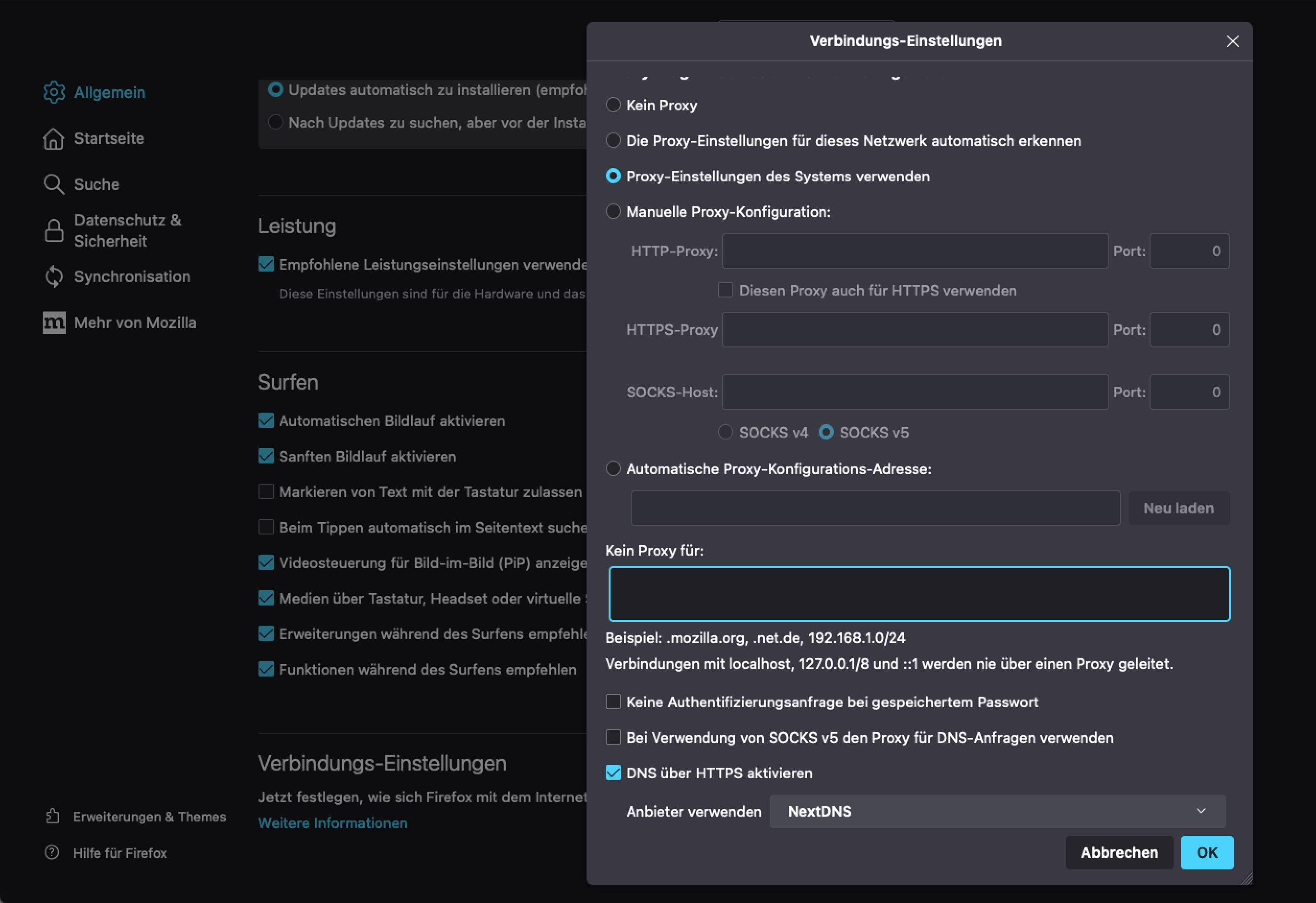
Die Einstellungen für DNS over HTTPS im Firefox
Im Firefox kann DNS over HTTPS in den Einstellungen unter Allgemein und dort in den Verbindungs-Einstellungen aktiviert werden. Dort kann dann der Punkt DNS über HTTPS aktiviert mitsamt eines Servers ausgewählt werden.
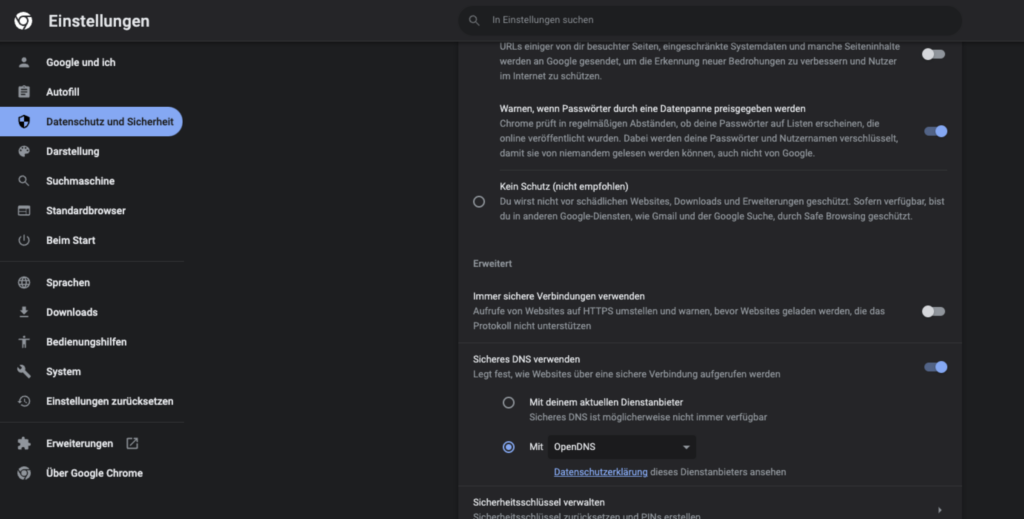
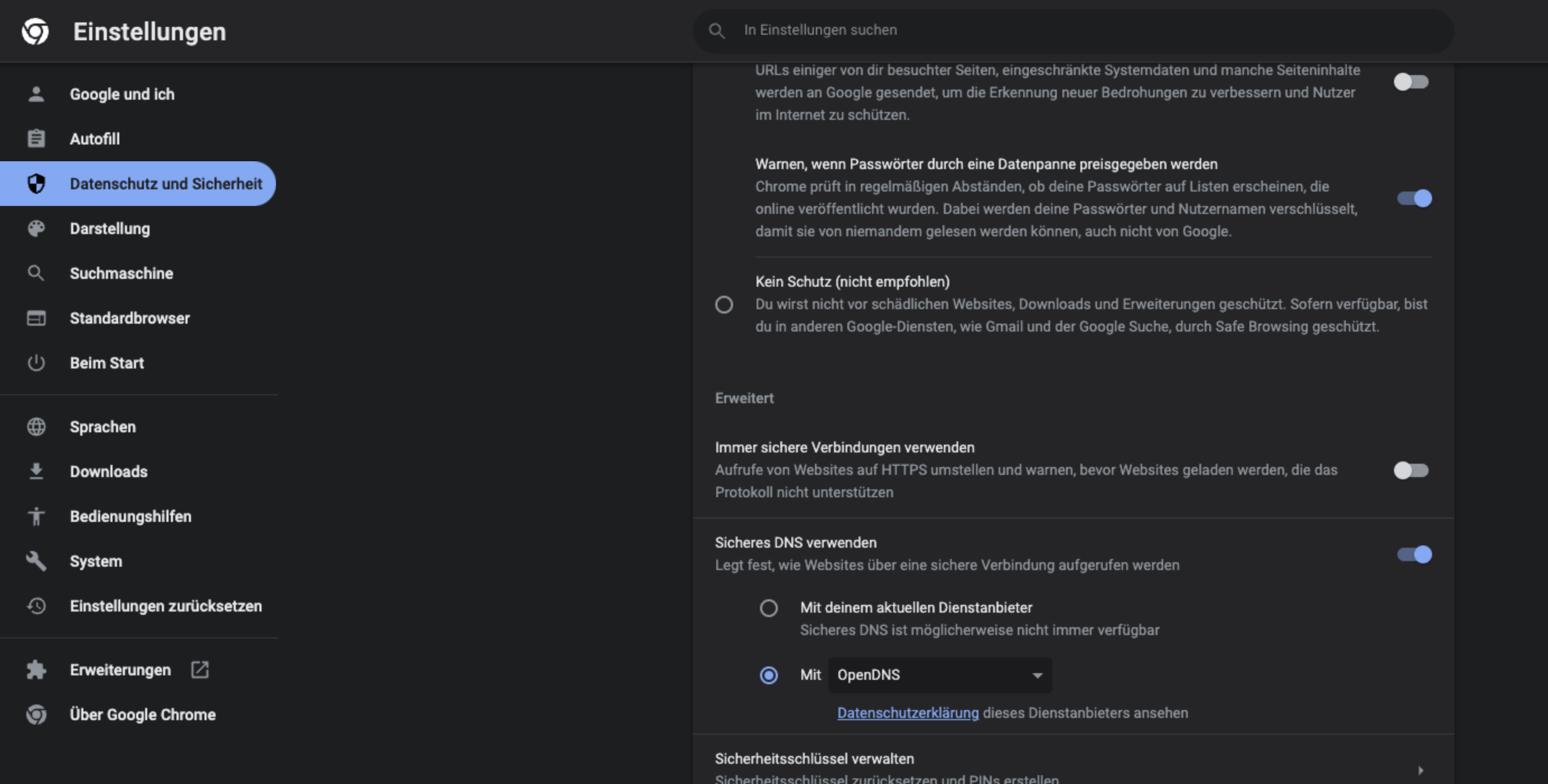
Die Einstellungen zu DoH unter Chrome
Unter Chrome kann DoH über die Einstellungen unter dem Punkt Datenschutz und Sicherheit aktiviert werden. Dort findet sich unter dem Unterpunkt Sicherheit der Punkt Sicheres DNS verwenden.
Router
Auch Router bieten in vielen Fällen Funktionalitäten zur besseren Absicherung von DNS-Abfragen.
So können in der FRITZ!Box entsprechende DNS-Server, welche DoT unterstützen hinterlegt werden. Auf Wunsch kann die FRITZ!Box auch einen Fallback auf unverschlüsseltes DNS durchführen, falls die entsprechenden DoT-Server nicht erreicht werden können. Dies kann zum Beispiel durch entsprechende Firewalls oder beim technischen Ausfall der Server passieren.
Andere Verfahren
Neben den oben beschriebenen Varianten existieren noch weitere DNS-Varianten wie Oblivious DNS bzw. Oblivious DoH, DNS over TOR und DNSCrypt, welche allerdings im weiträumigen Praxiseinsatz eher seltener zu finden sind.
Nachteile der neuen Lösungen
Bei den neuen Lösungen, wie DoT, DoH und DNS over QUIC, existieren eine Reihe von Problemen bzw. Kritikpunkten.
Viele beziehen sich dabei auf gewünschte Eigenschaften der Verfahren, wie die Verschlüsselung, welche es unter anderem erschwert, den DNS-Verkehr zu überwachen. Genutzt wird eine solche Überwachung z. B. in Kinderschutzsoftware, oder im geschäftlichen Umfeld, um den Netzwerkverkehr zu überwachen und entsprechende Policen durchzusetzen.
Je nach Lösung wird dann versucht, die neueren Verfahren zu deaktivieren bzw. dessen Nutzung nicht zuzulassen oder aber eigene Server für die entsprechenden Protokolle zu betreiben, welche wiederum die entsprechen Sperrmöglichkeiten anbieten.
Auch sind die, bei den Verfahren wie DoT oder DoH genutzten, meist zentralen DNS-Server von Google, Cloudflare oder Quad9 ein Problem, da sich dort ein Großteil des DNS-Verkehrs sammelt und dies Begehrlichkeiten wecken oder der Profilbildung dienen kann.
Daneben sollte beachtet werden, dass je nach Implementation bzw. Betriebssystem die Nutzung der verschlüsselten DNS-Varianten nicht immer garantiert ist. Sei es durch ungewollte Downgrades auf unverschlüsseltes DNS oder aber Applikationen wie der Appstore unter iOS, welcher von den DNS-Einstellungen des Systems unabhängig funktioniert. Daneben gibt es in bestimmten Versionen von Android den Fall, dass die Private-DNS-Einstellungen nach dem Aufwachen des Gerätes erst wieder nach einigen Sekunden angewendet werden.
Fazit
DNS-Abfragen müssen heute nicht mehr unverschlüsselt erfolgen, da es eine Reihe von neuen Ideen und Transportprotokollen gibt, welche neben der jeweiligen Vorteile teilweise auch spezifische Nachteile haben.
Mittlerweile findet sich für die Verfahren DNS over TLS und DNS over HTTPS eine breitere Unterstützung in den Betriebssystemen. Dort, wo diese noch nicht verfügbar ist, kann auf DNS-Proxies oder im Spezialfall Browser auf dessen Möglichkeiten zurückgegriffen werden.
|
DNS over TLS |
DNS over HTTPS |
DNS over QUIC |
| Linux |
über systemd-resolved (ab Version 239 bzw. 243) |
– |
– |
| macOS |
ab macOS 11 (Big Sur) |
ab macOS 11 (Big Sur) |
– |
| Windows |
ab Windows 11 (Build 25158) |
ab Windows 10 (Build 19628), Windows 11 |
– |
| Android |
ab Android 9 (Pie) |
ab Android 11 |
– |
| iOS |
ab iOS 14 |
ab iOS 14 |
– |
Neben der gewöhnlichen DNS Auflösung haben aktuell vorwiegend die Technologien DoT und DoH eine größere Verbreitung erlangt. Spannend wird in Zukunft auch die Entwicklung von DoQ, welches zumindest das Potenzial hat, bestehende Technologien rundum DNS-Abfragen abzulösen.
Allerdings stellt sich bei vielen dieser Protokolle die Frage, welchen DNS-Servern vertraut werden soll, denn das bestehende DNS-System ist ein dezentrales System ohne übermächtige Gatekeeper, während bei Diensten wie DoT und DoH eine Zentralisierung zu beobachten ist.
Dieser Artikel erschien ursprünglich auf Golem.de und ist hier in einer alternativen Variante zu finden.