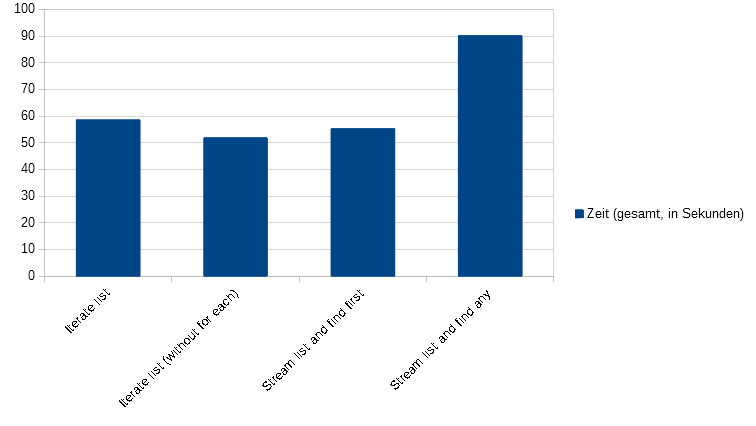
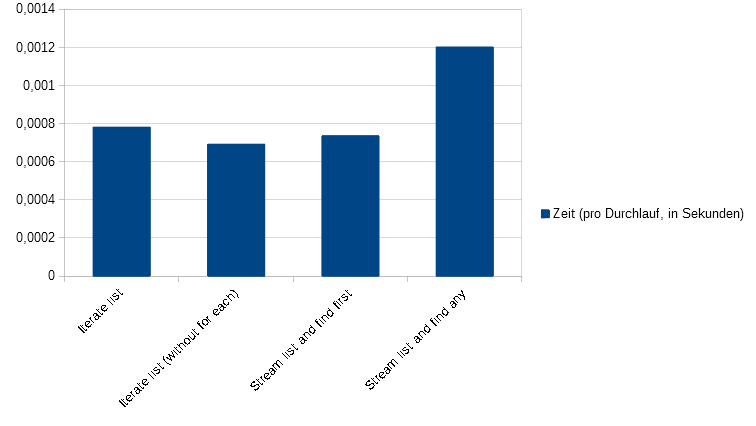
Benchmarking unter Java hat mit einigen Problemen zu kämpfen. So optimiert die Java-Laufzeitumgebung den Quellcode, je nachdem wie oft er benutzt wird. Wenn nun kleinere Dinge getestet werden sollen, wie z.B. ob Methode A oder B besser funktioniert so wird dies problematisch. Am Anfang würde besagte Methoden nur interpretiert werden, anschließend würden sie bei häufiger Benutzung kompiliert werden und bei noch häufigerer Benutzung weiter optimiert werden. Daneben kann es passieren dass der Benchmark komplett wegoptimiert wird, da die JVM unter Umständen erkennt, dass die genutzten Werte bzw. die Ergebnisse des Benchmarks später nicht mehr genutzt werden.

Die offizielle Seite des Java Microbenchmark Harness-Framework
Damit sich ein Entwickler nicht immer und immer wieder mit solchen Problemen beim Benchmarking herumschlagen muss, wird seit einigen Jahren im Rahmen des OpenJDK-Projektes an dem Java Microbenchmark Harness-Framework gearbeitet. Das JMH-Framework nimmt dem Entwickler viele Aufgaben ab, um diese Probleme zu lösen. So kann bzw. wird die JVM durch JMH aufgewärmt werden und auch die Messung der Zeiten übernimmt JMH. Um JMH zu nutzen, müssen die entsprechenden Abhängigkeiten (in diesem Fall über die Maven-POM-Datei) dem Projekt hinzugefügt werden:
<dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-core</artifactId> <version>1.21</version> </dependency> <dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-generator-annprocess</artifactId> <version>1.21</version> </dependency>
Sind die Abhängigkeiten eingebunden, kann mit dem eigentlichen Aufbau des Benchmarks begonnen werden. Jede Methode, welche ein Benchmark durchführen möchte, muss mit der @Benchmark-Annotation gekennzeichnet werden:
@Benchmark
public int addInts() {
return aInt + bInt;
}
Die Klasse, in welcher die Benchmarks definiert sind, muss mit einigen weiteren Annotationen ausgestattet werden:
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class AddingBenchmark {
...
Die @State(Scope.Benchmark)-Annotation in diesem Beispiel sorgt dafür das die Felder im Rahmen des Benchmarks für die Benchmark-Methoden zur Verfügung stehen. Mit der @BenchmarkMode-Annotation wird definiert, welche Art von Messung vorgenommen werden soll. In diesem Fall wird die durchschnittliche Zeit für eine einzelne Operation gemessen und ausgegeben. Über die @OutputTimeUnit-Annotation wird definiert wie die Zeiten für die Messungen ausgegeben werden. Werden für den Benchmark Daten benötigt so können sie über eine Methode, welche mit der @SetupAnnotation versehen wird, erzeugt werden:
@Setup
public void setup() {
...
}
Die setup-Methode wird damit vor dem eigentlichen Benchmark ausgeführt und somit können benötigte Daten dort erzeugt werden. Damit der Benchmark nun ausgeführt werden kann muss das Java Microbenchmark Harness-Framework angestartet werden. Dafür wird eine Klasse geschrieben und mit einer main-Methode versehen:
package net.seeseekey.JavaBenchmark;
import org.openjdk.jmh.runner.RunnerException;
import java.io.IOException;
public class Runner {
public static void main(String[] args) throws IOException, RunnerException {
org.openjdk.jmh.Main.main(args);
}
}
Über die main-Methode wird die main-Methode des Frameworks gestartet und damit wird das Benchmark durchgeführt. Alternativ kann die Methode org.openjdk.jmh.Main.main auch direkt in der Maven-POM-Datei als Startklasse definiert werden:
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<archive>
<manifest>
<mainClass>org.openjdk.jmh.Main.main</mainClass>
</manifest>
Nachdem der Benchmark implementiert ist, kann dieser natürlich über die IDE ausgeführt werden. Das würde allerdings nicht ganz der Intention von JMH entsprechen. Stattdessen sollte eine JAR aus dem Projekt erzeugt werden und diese, auf einem möglichst unbelastetem System, über die Konsole ausgeführt werden:
java -jar benchmark.jar
Damit wird der Benchmark über JMH ausgeführt. JMH beginnt mit einer Warmup-Phase und führt anschließend den eigentlichen Benchmark durch. Nach einigen Minuten erhält der Entwickler die Auswertung des Benchmark:
Benchmark Mode Cnt Score Error Units JavaBenchmark.AddingBenchmark.addDoubles avgt 25 ≈ 10⁻⁵ ms/op JavaBenchmark.AddingBenchmark.addInts avgt 25 ≈ 10⁻⁵ ms/op
In diesem Fall sieht der Entwickler bei der Ausgabe, dass die Ausgabeeinheit für die Zeit mit Millisekunden zu grob gewählt wurde und stattdessen besser Nanosekunden genutzt werden sollten.