Unter Mac OS X lässt sich vieles mit den vorhandenen Standardanwendungen lösen, wo man z.B. bei Windows zusätzliche Tools benötigt. So auch bei der Aufgabe PDF-Dateien in ihrer Dateigröße zu optimieren.
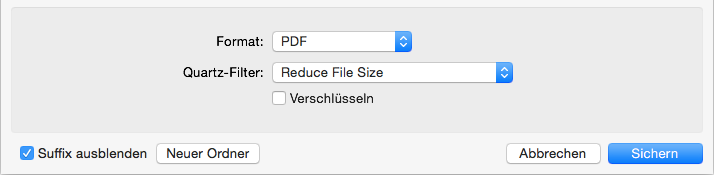
Die Optionen im Speichern-Dialog
Dazu muss die entsprechende PDF in der Vorschau geöffnet werden. Anschließend wird die Datei über Ablage -> Exportieren exportiert. Bevor dort der Sichern-Button betätigt wird, muss der Quartz-Filter Reduce File Size aktiviert werden. Damit landet die PDF anschließend in reduzierter Dateigröße auf der Festplatte.
Pingback: PDF-Dateien unter Mac OS X zusammenführen | seeseekey.net